학습주제
주제선정, 및 EDA
학습내용
내가생각한 것
데이터 대시보드 시각화
1. 주제 선정
2. 수집 방법
- 파이썬, xml, json, api (현재 공공데이터 까지만 생각해봄)
- 데이터 베이스 적재 방법
- 수집된 파일을 판다스의 데이터프레임 형식으로 변환
- S3에 업로드
- COPY 명령으로 redshift에 적재
- Superset으로 해당 데이터베이스 로드
- 적절한 시각화
상원님
축구선수 - 유료 API
우석님
스택오버플로우 - 기술분석
페이지를 크롤링해와서
키워드 추출해서
적재를 하자
어떤 언어가 - 기술과 연관이 있을까
스택오버플로우 API 있는지는 모르겠음.
질문과 답변에 대한 덤프를 제공.
비정형, 자연어 데이터로 이루어져 있을 것.
시각화를 떠나.
성일님
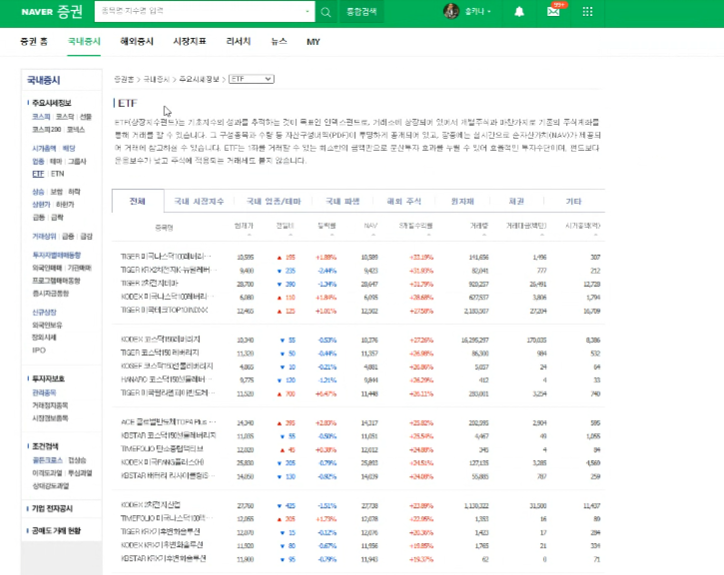
주식시장에 상장되어 있는 펀드
ETF들의 시가 총액, 오름차순 내림차순
Defi -> 코인. 코인을 기반으로 할 수 있는 금융활동.
이더리움. 코인 내부에서 금융활동.
예치를 해서 이자 수익을 낼 수 있었음.
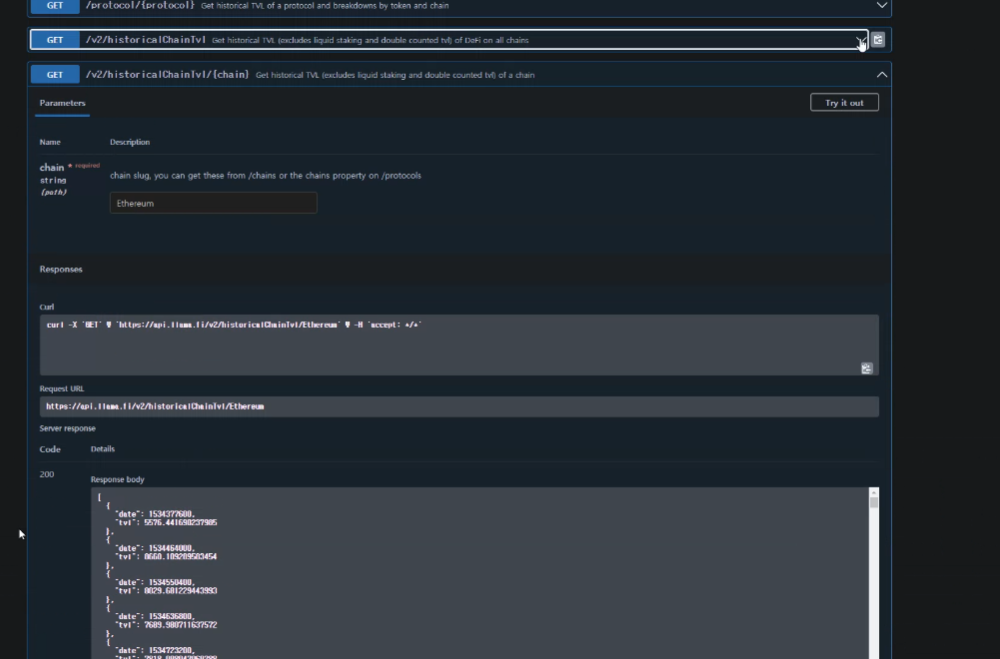
예치 잔고를 알수 있는 디파이리마
시계열로 볼 수 있음.
TVL - 특정 디파이에 얼마가 들어가 있는지
JSON으로 리턴해줌
이원진
교통사고 시군구 별로 제시
데이터가 너무 많으면
redshift - 클라우드 써야함
우석님
-프로젝트 목표: 타임라인이 중요!
오늘: 주제 정하고, 베이스 라인
화~목: full time 개발. (목요일 자정 전까지 마무리, 디버깅까지)
금요일: 마무리, 보고서 작성.
밤새서 하는 것에 기쁨을 느낀다.
프로젝트가 맘에 들어서 하게된다면
-
팀원 별 주제 제시
- 종욱 님
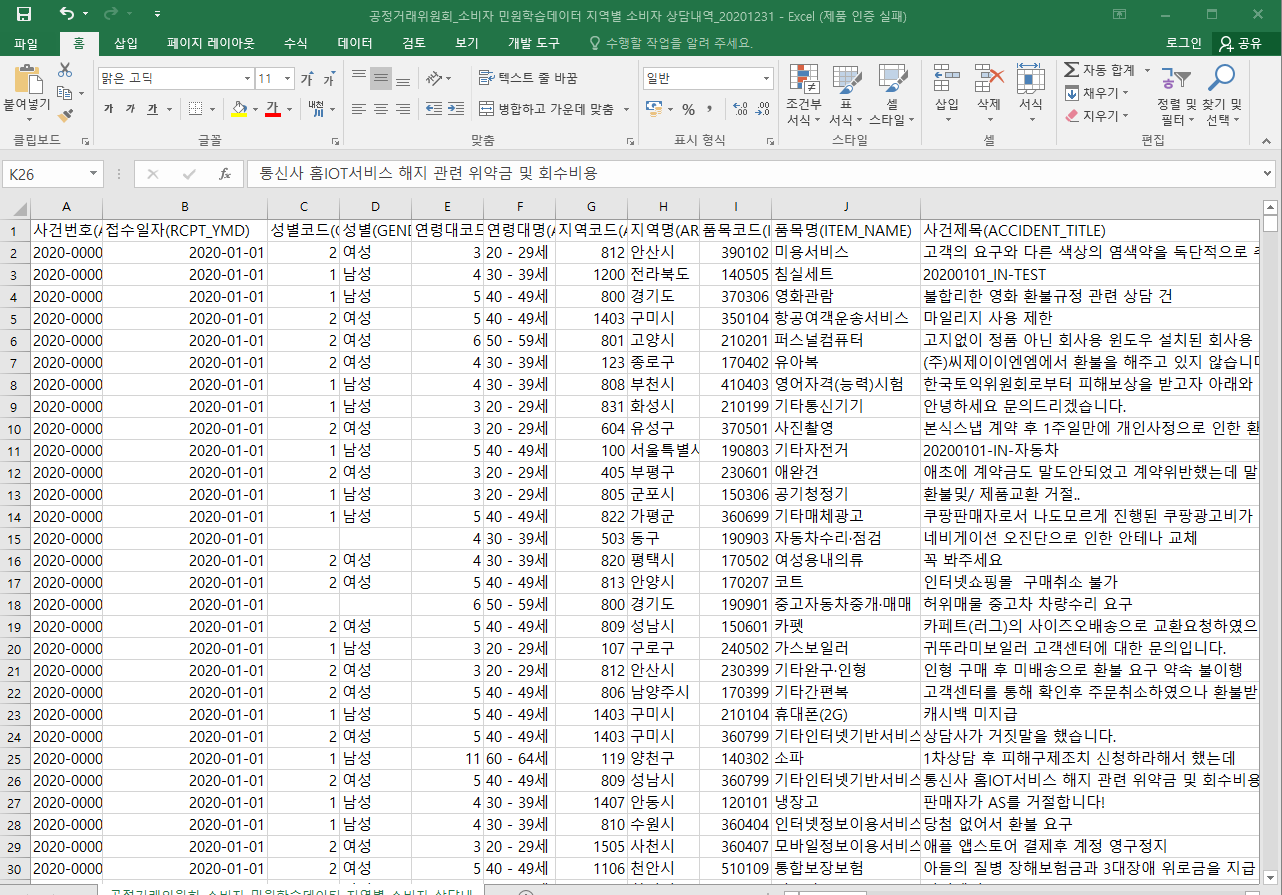
- 민원 관련 공공데이터(CSV)를 활용해 연령 별, 업종 별 민원 분석
- 프로젝트 시각화 목적 상, 숫자 데이터를 활용하는 것이 나아보임.
- 민원 관련 공공데이터(CSV)를 활용해 연령 별, 업종 별 민원 분석
- 우석 님
- Stackoverflow의 데이터를 분석해서 기술 스택 트렌드? 분석
- 질문, 답변 덤프 제공 → 비정형, 자연어 데이터 → 프로젝트 목표와 맞지 않는 것 같음
- Stackoverflow의 데이터를 분석해서 기술 스택 트렌드? 분석
- 원진 님
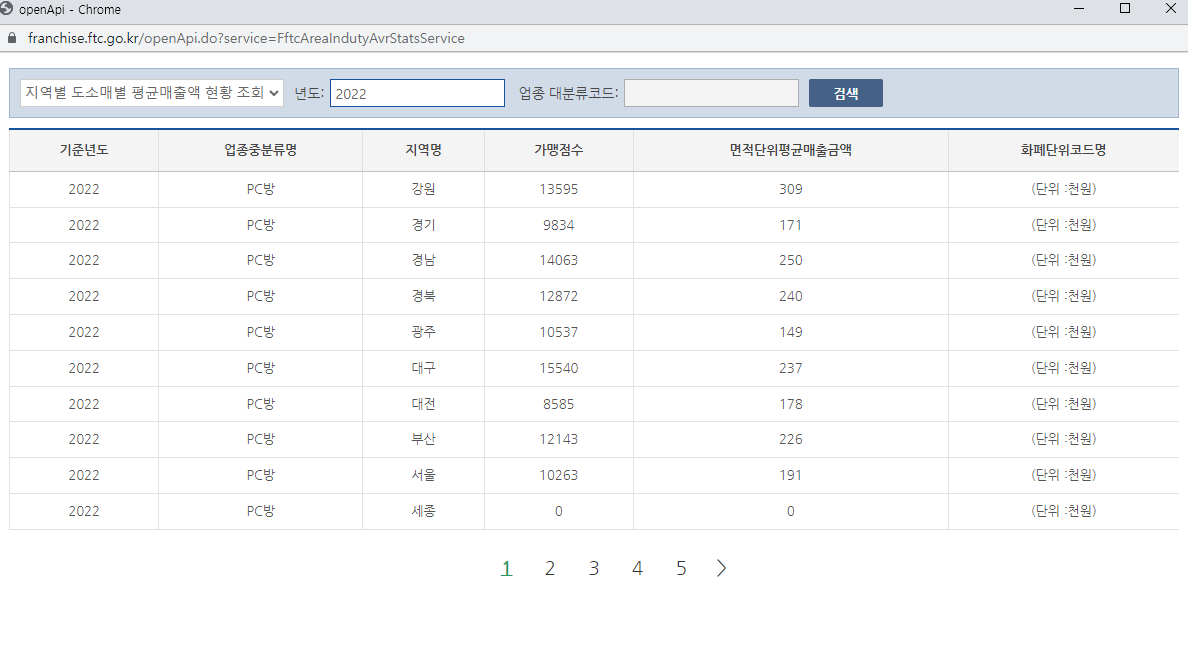
- 시군구별 교통사고 공공데이터(CSV)를 활용해 교통사고가 많이 발생하는 지역은 어디인지 파악
- 이전 년도(2019, 2020) 데이터를 같이 분석해 증감율 계산
- 시군구별 교통사고 공공데이터(CSV)를 활용해 교통사고가 많이 발생하는 지역은 어디인지 파악
- 성일 님
- 네이버 증권 ETF 데이터 (Scraping)
- 크롤링해야하는 단점
- DefiLIama의 DeFi 데이터 (API)
- 시각화 목적과 결과를 명확히 하기 어려움
- 제주도 관광객 공공데이터를 활용해 관광객 추이 분석 및 시각화
- GROUP BY로 행태 별, 목적 별, 연도 별로 묶어서 여러 가지 방법으로 활용
- 네이버 증권 ETF 데이터 (Scraping)
- 상원 님
- 축구 선수 별 기록 데이터
- 마땅한 API 찾기가 힘듦(유료임)
- 축구 선수 별 기록 데이터
- 종욱 님
-
팀원 별 의견
- 종욱 님
- 적은 양의 데이터로 시각화를 먼저 진행하고, 시간 여유가 되면 AI 모델 관련 기능 도입하는 의견이 좋은 것 같음
- 우석 님
- 처음에 주제를 작게 잡고 조금씩 완성하면서 확장하는 것이 좋다고 생각
- 이번 프로젝트 자체가 복잡하지는 않아서 학습한 내용을 복습하는 주제가 좋을 것 같음
- 숫자로 되어있는 테뷸러 데이터를 사용하는게 시각화하기 용이하다고 생각
- 종욱 님이 제시해주신 테뷸러 데이터는 시각화하기 좋을 것 같음
- 성일 님이 제시해주신 DeFi 코인 관련 주제는 시간 여유가 있으면 SageMaker로 상승/하락 예측할 수 있을 것 같음
- 처음에 주제를 작게 잡고 조금씩 완성하면서 확장하는 것이 좋다고 생각
- 원진 님
- 이번 기간 동안 Redshift에 대해 주로 배웠으니 AWS를 사용할 것 같은데, 크레딧을 지원하지 않기 때문에 데이터 양이 많은 것보다는 적당한 양을 활용해 시각화하기 좋은 데이터셋이 좋은 것 같음
- 데이터 양이 많다고 해도 빅데이터 처리 능력이나 경험을 쌓기에는 어려움이 있을 것 같음
- 이번 기간 동안 Redshift에 대해 주로 배웠으니 AWS를 사용할 것 같은데, 크레딧을 지원하지 않기 때문에 데이터 양이 많은 것보다는 적당한 양을 활용해 시각화하기 좋은 데이터셋이 좋은 것 같음
- 성일 님
- 상원 님
- numeric data를 사용하는 것이 프로젝트를 진행함에 있어 수월할 수 있다고 생각합니다.
- 종욱 님
s3에 파일 업로드는 쉬움. csv형태로 이미 가공이 되어있음.
Redshift에 ETL 해와서
superset에 대시보드 구성
협업 방법

반갑습니다 햄스터 좋아합니다