조원: 이태현, 김찬우, 김동석, 김성일, 김종욱
회의 내용:
동석님: 메타크리틱 점수 시각화
- 메타크리틱은 API는 미제공, 직접 크롤링.
- 전체 중에 1000개를 가져오는 방식으로.
- 네이버 금융. 나스닥 데이터. 차트 그리기.
- 업비트에서 차트 그리기.
찬우님: 리그오브레전드, 승률 API 분석
지표 같은 것을 시각화하는 프로그램.
- 네이버 크롤링을 정책적으로 막아놓고 있음.
아는 사람만 아는 지식.
태현님: 주제를 금융 도메인. 그쪽의 API가 잘 되어 있는 것 같음. 크롤링도 살짝.
종욱: 부동산 뉴스 키워드
성일님: 금융 도메인. 주식 데이터 수집. 전처리 경험 있음.
월 -> 금까지.
주식 도메인 쪽으로.
금융
세부사항 - 금융 관련 도메인
- 주식
- 나스닥
- 코스피
- 코스닥
- 부동산
뉴스 관련 데이터 - 가상화폐
뉴스 + 거래량
찬우님: 국내 주식 시각화로 보고 싶음.
API가 많이 제공.
성일님: 증권사별로 가격 데이터, REST API 한국투자증권.
한국거래소 데이터.
실제 주문같은 경우. 증권사
라이브러리가 있음.
재무 데이터는 긁어오면 됨.
찬일님
robot.txt에서 허락 안한다.
네이버증권 api로 긁어오면 편함.
- 한국거래소 -> Rest API로 가격 제공
- 기타 거래량 -> 직접 긁어와야함
- FinaceData -> 라이브러리
네이버. 나중에 면접시 안되는데 왜 했냐는 질문들어올 수 있음.
-
나스닥, 코스피, 코스닥, ETF 등
-
시각화 할만한거 2~3개 따오기
-
조회성, 시각화에 초점
-
일별지수를 API로 긁어오기?
-
나스닥 / 코스피를 긁어와 비교
도전적인 기능을 만드는게 필요. 실습도 중요하지만
성일님: 골드, 실버가격. 나스닥에서 줌. 달러가격으로. 원자재 가격. 기술적 분석. 차트보고 매수할지 매도할지. 그런것도 웹에 띄우면
기술적 분석 - 데이터를 수집해온걸로 가공 -> 다시 가공해줌
pandas 사용.
크론잡 - 스케줄러 같은거 배치도 제공하지 않을까
웹 형식 프로젝트.
웹에 띄울 때는 난이도가 있음. -> 관련 프로젝트를 한적 있는데 차트 띄우는사람이 어려워했었음.
- 파이썬 시각화 라이브러리 streamli + django
금, 은 가격.
세부 구현 사항
pigma, 시각화툴
1. API로 금/은 데이터 가져오기. 전처리
2. 테이블로 만들기. 새로운 필드를 만들고 -> Pandas에서 지원. 필드끼리 연산해서 지원. 파이썬에서 쓸 수 있는 엑셀 같은 것.
3. 화면에 띄우기
4. 테스트
MTV 형태?
파일 시스템.
웹으로 서비스하는 비즈니스라면
연속성이 있는 형태.
어떤 RDB를 사용할지 선택.
시각화는 렌더로
API gateway를 만들어서, 시각화 뿐만 아니라 데이터를 받기 (선택)
예시문서
API를 받아올 때 어떤 특정 일자를 넣어서 보내지 않나?
나스닥의 경우 데이터가 엄청 크기 때문에, 한꺼번에 보내주진 않을 것 같음. 세부적일 일정을 정해서 보냄
DB기술은 어떤 DB를 사용할 것인지.
DB에 집어 넣고, 과거 데이터는 쌓이는 게 맞음.
페이지 0,1,2,3,4 이런식으로 받았었음.
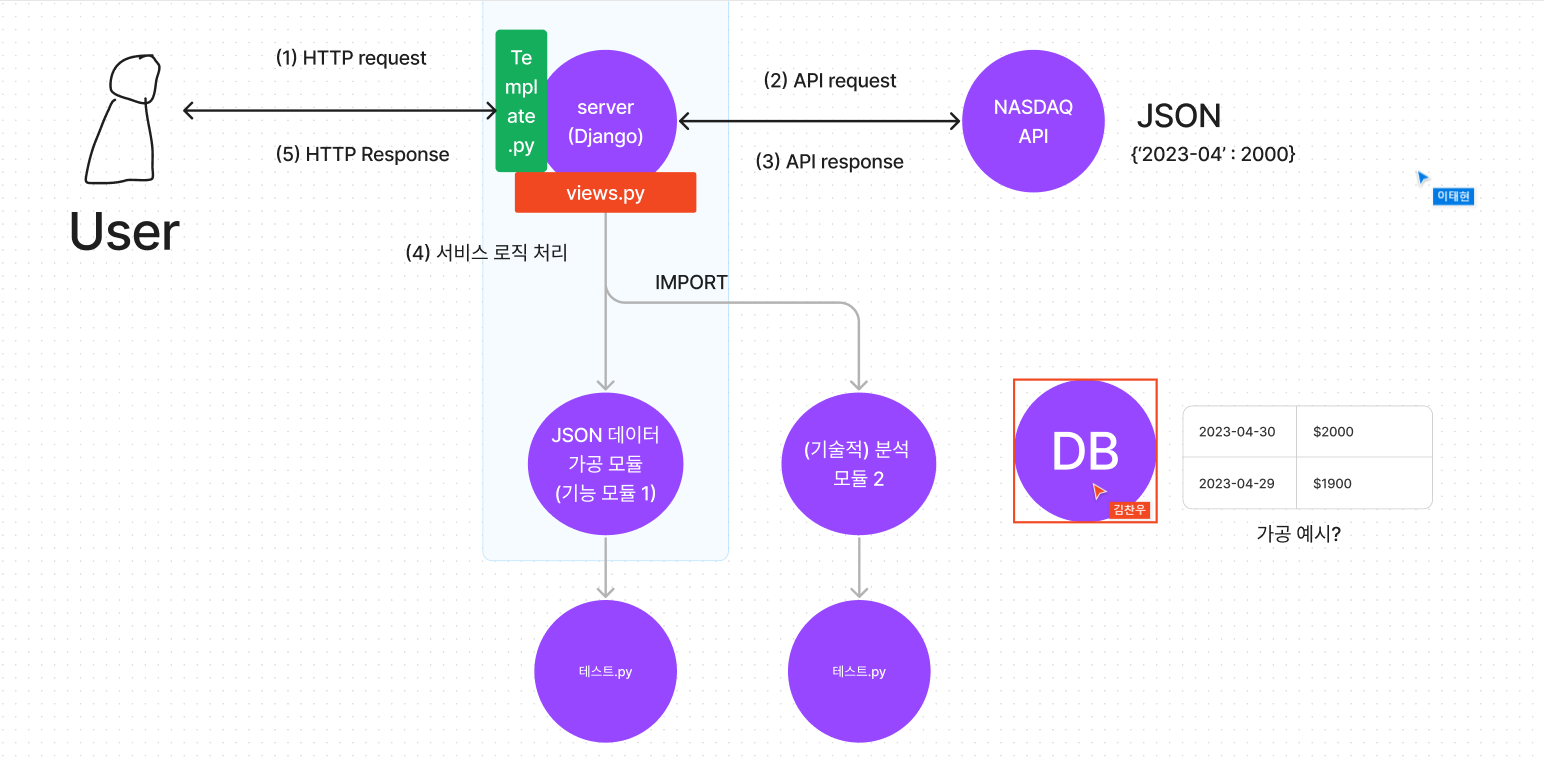
시리얼라이저는 필수는 아닌거 같음.
장고 - 모델정의 마이그레이션.
전처리 단에서 .save 함수만 만들면 됨.
어떤 데이터를 보여줄 것인가. -> 구체화 필요
금, 은
일자별 가격테이터, 거래량 데이터,
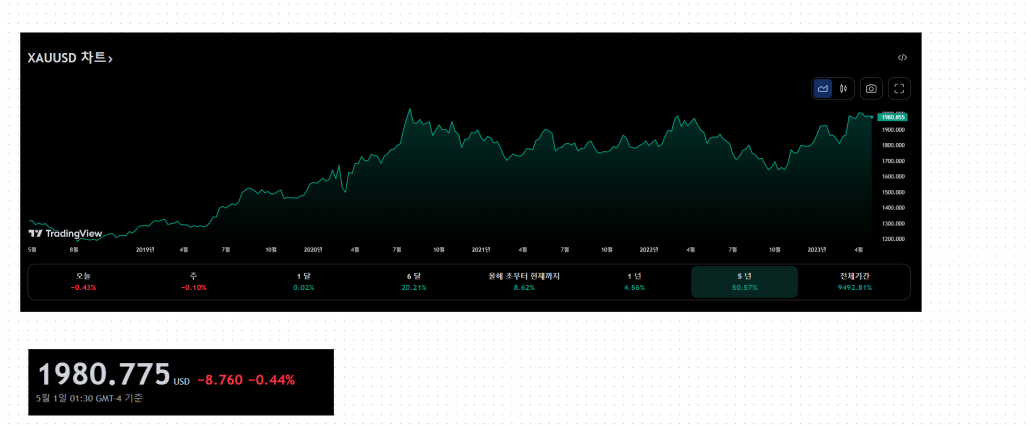

에버리지는 만드는 코드 공식.
피쳐 엔지니어링?
1 날짜: 가격 데이터
2. pd.dataframe()
3. 가격 데이터를 비반으로 수학 산식 적용
4. 새로운 컬럼 날짜별로
5. 공식이 있음.
장고도
ORM을 쓰는게 표준인 거 같음.
모델링을 바탕을 DB 테이블이 만들어질 예정.
영속성을 유지하는 것이 목적.
실시간이 아닌, 고정된 데이터. 요청
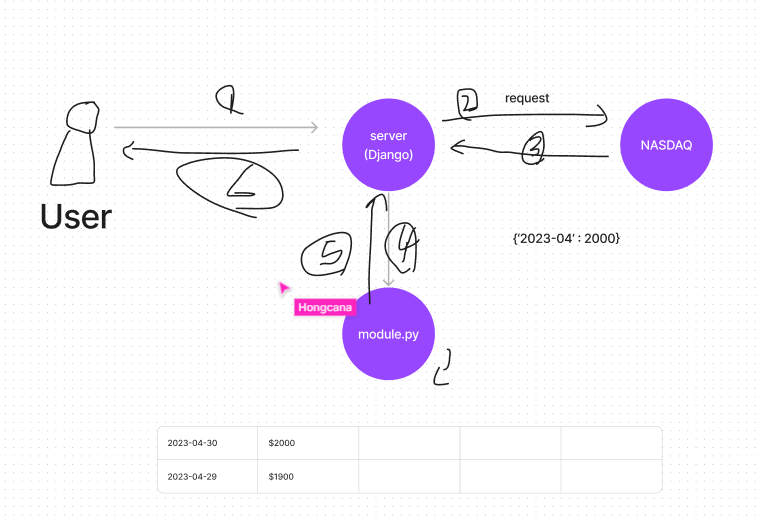
server -> NASDAQ 기준으로 API 요청
날짜를 정해서 -> 한꺼번에 가져와서 적재 -> 이후는 스케줄러로 적재.
자정 시간이 좋음. 원자재는 장 마감이 없음.
나스닥 - 글로벌 기준. - 개장시간을 기준으로 가져온다. - 장고 배치
클라이언트 요청 X
깃허브 생성.
아키텍처.
sqlite3은 인메모리 기반. 설치형 어플리케이션 외에 사용하지 않음. RDB Mysql. ORM이 자동으로 만들어 줄 예정.
mySQL 사용.
써드파트.
시각화. 웹.
streamlib. 로컬에 저장 안하는식.

기술 스택
- Django
- mySQL
- 시각화: matplotlib + seaborn
- 템플릿: html + chatgpt로 요소 추가
역할 분담
https://developer-doreen.tistory.com/38
통합 개발 환경 개발 컨벤션.
전처리, 모델링, 시각화
- 통합 개발 환경
python: 3.10.9
Django: 4.2 -> 4.1로 낮추기
Djagno rest framework 3.14.0
DB: MySQL 8.0.0- AWS RDS 생성
판다스는 최신으로 해도 될꺼같음.
장고 -> 최신버전에서 mySQL 오류 발생함.
로컬에서 테스트 할꺼면 csv 파일로 관리. AWS 무료버전?
RDS 중에 어떤거 선택할수 있게 함.
- 모델링 적재가 되어야지
다 같이 - 전처리 작업
null 값 처리
템플릿으로 뱉는거까지
함수 적용
뷰에 보내는 것. - 시각화/view
설계
모델링: 장고 ORM을 사용 모델을 만드는 것이 -> DB로 직결.
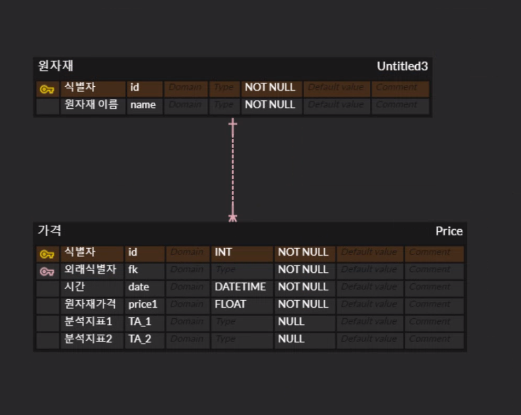
가역 데이터 USD만 들고올 것인데, 테이블 관계를 맺을 필요가 없을 꺼 같음.
데이터팀.
가역데이터, 금, 은 테이블 나누고.
데이터 크기. 갯수. 2년치, 3년치
금은, 가격데이터, 파생정보 데이터
하루치를 가져왔는데.
분석지표의 경우 1달
많은 요청이 있을 경우, O(n) 회수가 들어난게 아닌가.
분석지표 1 과거 30일동안의 데이터가 필요.
분석지표 2 120일이다.
DB 모델링

public을 열어두면 계속 접근이 가능함.
조를 나눠보게 되면 -> 같은 도메인을 다뤄야하기 때문에 곤란.
같이 작업해봐야함. -> 실제로 작업하는게 아니다보니. 어떤 사람은 물러나 있게함.
깃허브
참고 url
https://sunshower99.tistory.com/26
https://docs.google.com/document/d/1NcISK2H1mSIj9DoL-K9ZSlsrNug5XnHpk0lcd1iM61E/edit#
https://ultrakain.gitbooks.io/python/content/chapter1/coding-style-pep8.html
https://velog.io/@bgshin13/GoogleAngular-Commit-Convention
https://terrific-cactus-458.notion.site/1d2d046fb99b4988a0d1566ddd035339
https://techblog.woowahan.com/2553/
https://www.erdcloud.com/d/a9PBcq8YS4BWA8f7M
https://terrific-cactus-458.notion.site/682d56234ea4425692595c12bc0d03f3
https://www.erdcloud.com/d/CCizSc5Kgp9NGzs9e
장고 기초설정
setting.py
앱 이름. -> 난리남.
PULL로 가져와서 같이 작업해보기.
remote -> 원본으로 걸기.
