Unicode Scalar Value
Any Unicode code point except high-surrogate and low-surrogate code points.
대리 코드 포인트를 제외한 모든 유니코드 코드 포인트이다.
💡 surrogate code point란, UTF-16 에서 코드 유닛 쌍의 선행 및 후행 값으로 사용하기 위해 예약된 유니코드 값 범위에 포함된 코드 포인트이다. (라고 하는데 뭔진 모르겠다.) (대충 유니코드와 1:1 대응이 안되는 값이라고 생각하면 될 듯..)
더 많은 정의는 The Unicode Standard - 3.9 Unicode Encoding Form을 보자.
UTF
Unicode transformation format (UTF) is an algorithmic mapping from every Unicode code point (except surrogate code points) to a unique byte sequence.
유니코드 전송을 위한 가변 길이 문자 인코딩 알고리즘이다. 이름에서 알 수 있듯이, 유니코드를 전송하기 위해 만들어졌다. (유니코드를 이진 데이터로 변환 후 전송한다.)
모든 UTF는 모든 유니코드를 유일한 바이트로 매핑해야 하며, 가역적이여야 한다. 이를 위해 손실 없는 라운드 트리핑을 지원해야 한다. 손실 없는 라운드 트리핑을 지원하기 위해, 대리 코드 포인트를 제외한 모든 유니코드는 유일한 바이트로 매핑되어야 한다.
만약 전송 혹은 번역 도중 잘못된 형식(malformed)의 바이트 시퀀스가 발견된다면(ex 110xxxxx 0xxxxxxx), 에러 신호를 보내서 프로세스를 종료시키거나, 해당 바이트를 제거하거나, 대체 문자(U+FFFD �)로 치환한다. 여기서 마지막 두 방법은 다음 바이트(0xxxxxxx)부터 정상적으로 프로세스를 이어나갈 수 있다.
💡 MDN에 따르면, Web API 또한 USVString을 번역할 때 surrogate code points를 U+FFFD로 대체한다고 한다.
준수한 인터프리터는 잘못 인코딩된 바이트 시퀀스를 번역하면 안되지만, 에러 복구 동작을 행할 수 있다. (물론 이 동작은 구현체마다 제각각..)
UTF-8
Universal Coded Character Set + Transformation Format – 8-bit
유니코드 문자를 이진 데이터로 변환하기 위한, 가변 길이 문자 인코딩 방식 중 하나이다. (물론 가역적이기 때문에 디코딩해서 파일을 유니코드 문자열로 변환할 수도 있다.)
const c = '위'; // U+C704
const encoder = new TextEncoder();
const encoded = encoder.encode(c);
encoded
// Uint8Array(3) [236, 156, 132, buffer: ArrayBuffer(3), byteLength: 3, byteOffset: 0, length: 3]
Array.from(encoded).map(n => n.toString(16));
// ['ec', '9c', '84']UTF-8의 인코딩 방식은
- 000000~00007F(아스키 코드 포인트 영역) 까지의 유니코드 코드 포인트는
0xxxxxxx에 맞춰 저장하며, - 000080~0007FF 까지의 유니코드 코드 포인트는
110xxxxx10xxxxxx에 맞춰 저장하며 - 000800-00FFFF 까지의 유니코드 코드 포인트는
1110xxxx10xxxxxx10xxxxxx에 맞춰 저장하며 - 010000-10FFFF 까지의 유니코드 코드 포인트는
11110zzz10zzxxxx10xxxxxx10xxxxxx에 맞춰 저장한다. (z는 서로게이트 쌍 영역) - 더 자세한 내용은 UTF-8 구조를 참고하자.
코드 포인트의 범위에 따라 1~4 바이트의 이진 데이터로 변환이 이루어진다. 그래서 가변 길이 문자 인코딩 방식이다.
base64
8비트 이진 데이터를 인코딩에 영향을 받지 않는 공통 ASCII 영역의 문자들로만 이루어진 일련의 문자열로 바꾸는 인코딩 방식을 가리키는 개념이다.
말그대로 64진법(2^6)을 이용해 인코딩을 하기 때문에, 임의의 바이트 스트림을 ASCII 문자(2^7개)로만 표현이 가능하다. 이러한 특성 덕에, 이진 데이터를 전송하는데 사용한다.
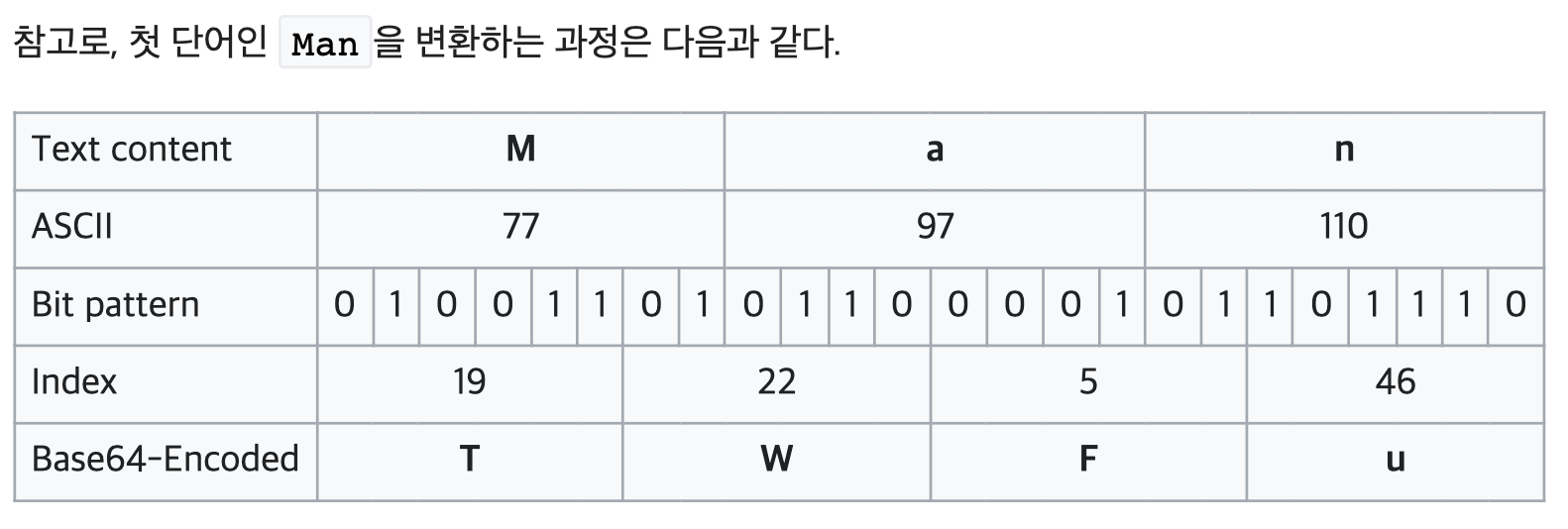
8비트 단위로 입력을 받아 6비트 단위로 출력을 하기 때문에, 인코딩을 거치면 크기가 4/3 정도로 늘어나며, 나머지 비트는 패딩 값(=)으로 채워진다. 따라서 인코딩된 문자열 끝에 = 혹은 == 가 붙을 수 있다.
UTF-8과 base64
앞서 말한 것 처럼, UTF는 가역적이기 때문에 UTF-8로 인코딩 된 이진 데이터는 UTF-8로 디코딩했을 때 정상적으로 번역이 된다.
하지만 UTF-8로 인코딩 되지 않은 이진 데이터를 UTF-8로 디코딩하려고 한다면 어떻게 될까?
예를 들어 128(2) 10000000 이 있다고 가정해보자. 이 데이터를 UTF-8로 디코딩할 때, 첫 바이트가 110xxxxx 형식을 가지고 있지 않기 때문에 잘못된 형식으로 판단한다. 따라서 대체 문자로 교체를 해버린다.
결국, 아스키 코드 포인터 영역을 벗어난 이진 데이터를 UTF-8로 디코딩 한다면 데이터가 손실 될 위험이 있다. 따라서 다음과 같은 말들이 통용되는 것이다.
재미있는 사실The UTF-8 format refers to the UTF-8 character encoding for Unicode. Unlike hex and base64, which are binary-to-text encodings, UTF-8 is a text-to-binary encoding. This means that conversion from string to binary always succeeds, but conversion from binary to string can fail.
This format is convenient for performing one-to-one conversion between binary and string, for reinterpreting the underlying data as one type or the other rather than actually encoding and decoding.
구글링 후 실험 결과를 보다보니, 재밌는 사실을 알게 되었다. 각 인코딩 문자열의 Uint8Array 값을 보면 다음과 같다.
- UTF-8 문자열 : 239, 191, 189, 80, 78, 71, ...
- base64 문자열 → UTF-8 인코딩(`TextEncoder`) : 137, 80, 78, 71,
여기서 239, 191, 189는 유니코드로 변환하면 FFFD, 즉 대체 문자가 된다. 따라서 80, 78, 71, ... 부분은 문자열 “PNG”를 나타낸다. base64에서는 80, 78, 71, ... 앞에 있는 값이 137이다.
137은 아스키 코드 범위(2^7)을 벗어난 값이다. 😎
Byte Array와 Blob
byte array : 이진 데이터를 인간이 이해할 수 있는 “숫자”로 표현한 것?
blob: 불변하는 미가공 데이터. 텍스트와 이진 데이터의 형태로 읽을 수 있다?
TextEncoder, atob, btoa, ...
몰루
참고
General questions, relating to UTF or Encoding Form
