
Traditional Architecture
전통적인 아키텍처는 상위계층에서 하위계층으로 구성되어 있어 같은 계층 혹은 아래에 있는 계층에만 접근이 가능한 구조입니다. 웹 어플리케이션을 만든다고 하면 일반적으로 아래와 같은 Layer로 구성됩니다.

Presentation Layer
- Web과 관련된 의존성 및 코드가 존재
Application Layer
- 어플리케이션의 business와 관련된 규칙 및 의존성과 관련된 코드
Data Layer
- Database에 CRUD 작업을 하거나 다른 외부 API를 호출하는 코드
Layer간 접근이 같은 계층 혹은 아래에 있는 계층에만 접근이 가능하기 때문에 해당 구조에서는 Presentation Layer는 Application Layer에 의존적이고 Application Layer는 Data Layer에 의존적입니다.
이렇기 때문에 Business 관련된 Layer인 Application Layer는 Data Layer에 의존적이기 때문에 일반적으로 데이터베이스 중심 설계를 하게 됩니다.
즉 데이터베이스와 관련된 작업들을 먼저하고 그다음 데이터베이스 설계를 기반으로 Business 로직을 작성하게 됩니다.
이렇게 되면 Database 구조가 변경되면 Business 로직에도 영향이 가게 되고 객체지향적으로 설계하기가 쉽지않습니다. 계층에 대한 제한이나 규칙이 거의 없기 때문에 계층을 건너 뛰는 작업을 아무렇지도 않게 할 수 있어 Business 관련된 로직들이 각 Layer에 파편화 될 가능성이 높습니다.
모든 전통적인 아키텍처가 그러진 않겠지만 이러한 문제는 도메인에 대해 파악하기 어렵게 만들어 지속적으로 유지보수 가능한 프로젝트에서 멀어지게 됩니다.
Clean Architecture
Clean Architecture는 모든 Architecture가 지향하는 관심사의 분리에 대해 초점이 맞추어져있고 특히 Business와 관련된 내용을 다른 세부사항이랑 완전히 분리하기 위해 아래와 같은 경계로 나누어 설명합니다.
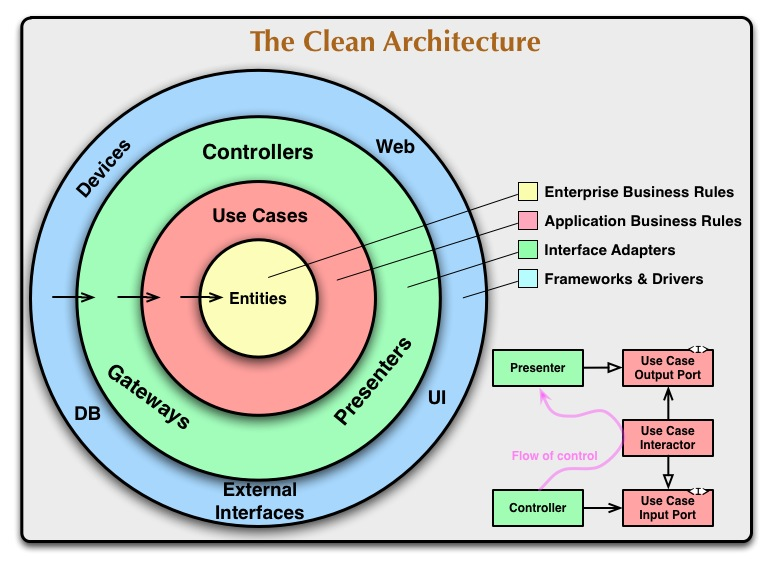
출처:https://blog.cleancoder.com/uncle-bob/2012/08/13/the-clean-architecture.html
경계를 원을 통해서 설명하고 있는데 원의 바깥쪽으로 갈수록 매커니즘 즉 Database, UI와 같은 기술들을 나타내고 원의 안쪽으로 갈 수록 추상적인 Business와 관련된 내용들을 나타냅니다.
일단 바깥쪽을 저수준 안쪽을 고수준이라고 정의하겠습니다.
Clean Architecture는 저수준의 영역이 변경된다고 하더라도 프로그램 설계에서 가장 중요한 더 추상적이고 비즈니스 적인 부분인 고수준의 영역에 영향이 없도록 저수준에서 고수준으로 의존하는 구조로 의존성 규칙을 엄격하게 설정합니다.
이로 인해 UI가 변경되던 Database가 변경되던 Business와 관련된 내용들은 최대한 영향이 없도록 설계할 수 있습니다. 즉 저수준에 의존적이지 않고 독립적으로 Business와 관련된 내용들을 안전하게 유지 한다 라는것이 Clean Architecture의 핵심 내용입니다.
위와같은 4가지(Entity, UseCase, Interface Adapter, Farmeworks and Drivers)로 경계를 나누지 않고 경우에 맞게 경계를 나누고 해당 의존성 규칙만 지키면됩니다.
Hexagonal Architecture
Hexagonal Architecture는 Clean Architecture의 구현체라고 볼 수 있습니다. Hexagonal Architecture도 Port와 Adapter라는 개념을 통해 외부 시스템으로 부터 비즈니스를 보호하는 구조입니다. 아래와 같이 구성 되어있습니다.
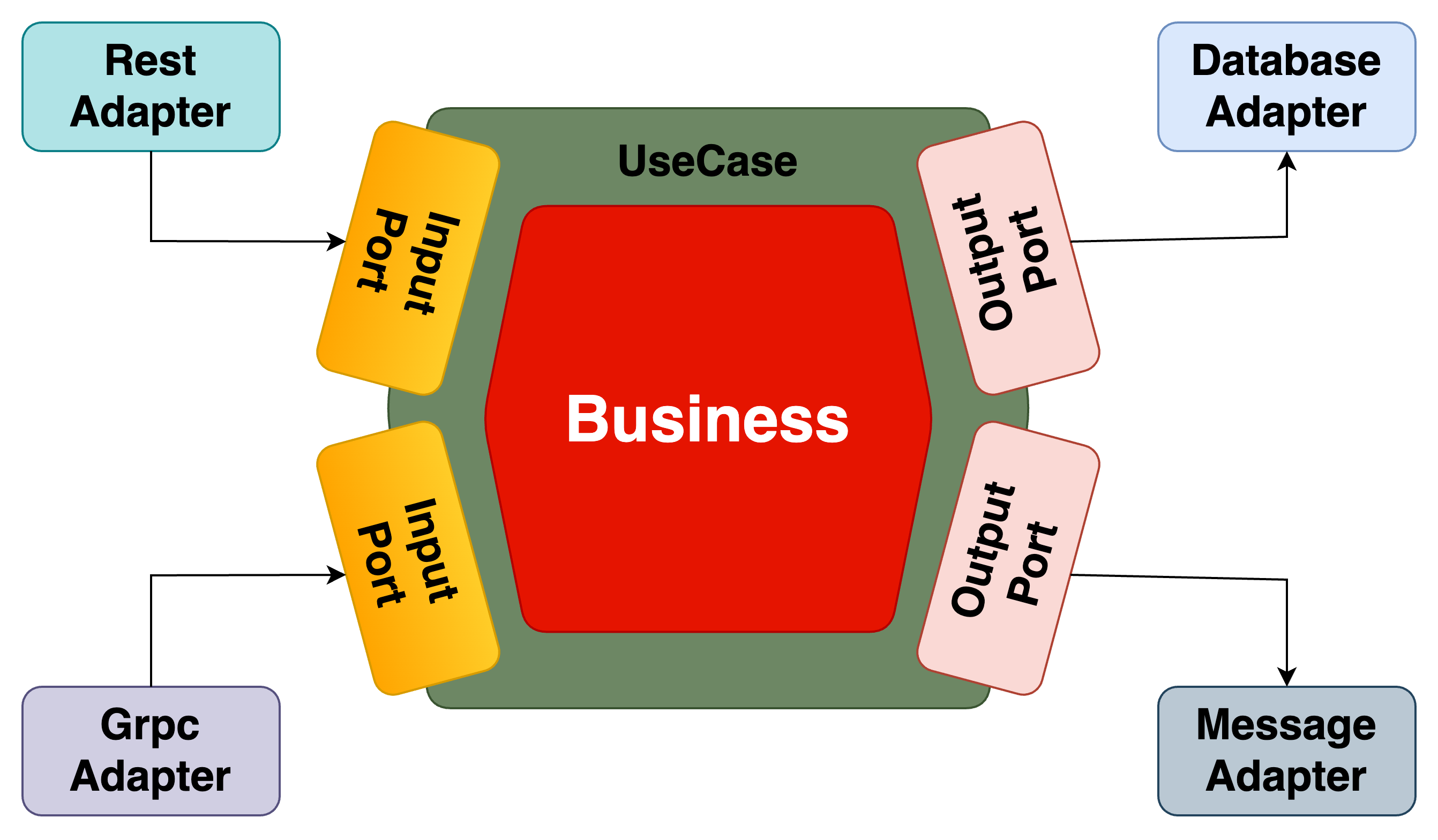
중심에 Business가 있고 Port라는 Interface로 다른 외부 시스템을 연결합니다.
저같은 경우에는 Port는 Input Port와 Output Port로 분리해서 생각하는데
Input Port
- Business에 관한 것(UseCase)을 외부 시스템이 사용하기 위한 Interface
Output Port
Business(UseCase)가 외부 시스템을 사용하기 위한 Interface
Port는 각 외부시스템이 Adapter로 구현하고있습니다. 이렇게 설계 함으로서 Business 외부 시스템의 구현체에 의존적이지 않기 때문에 외부 시스템 즉 Adapter인 구현체가 변경되어도 Business를 안전하게 보호할 수 있습니다.
Architecture Layer
크게 외부 영역과 내부 영역으로 나뉘는데 내부영역은 특정 Application에 종속적이지 않은 Business 로직 및 규칙에 대한 Pure한 내용들이 담긴 Domain Layer가 가장 안쪽에 존재하고 특정 Application에 종속적인 Business 로직인 UseCase를 포함하는 Application Layer가 다음에 존재하고 Port의 구현체인 Adapter가 담긴 External Layer가 존재합니다.
저수준 → 고수준
- External Layer
- Application Layer
- Domain Layer
UseCase
UseCase는 Application Layer에 존재하고 특정 Application에 종속적인 Business 로직을 나타냅니다. 일반적으로 UseCase는 SOLID 원칙의 SRP 원칙을 지켜야합니다. SRP 원칙에 대해 간단하게 이야기하면 "한 클래스는 변경되는 이유가 단 하나여야 한다"라는 원칙을 가지고 있기 때문에 단 한가지의 책임만을 가지고 있어야합니다. 만약 유저에 대해 생성을 한다면 아래와 같이 UseCase를 구성할 수 있습니다.
public class UserRegisterService implements UserRegisterUseCase {
private final UserRegisterPort port;
public RegisterUserUseCase(RegisterUserPort port){
this.port = port;
}
@Override
public void registerUser(UserCommand command) {
User user = new User(command.getNickname(), command.getEmail());
user.validateRegister();
port.registerUser(user);
}
}UseCase Parameter Data
UseCase에 전달되는 Parameter Data는 Side Effect가 발생하지 않도록 비즈니스 관련된 로직이 없고 Immutable하게 유지해야합니다. 그렇기 때문에 자바를 사용한다면 record를 사용하거나 class에 getter 메서드만 설정하도록 합니다.
Naming Convention
저 같은 경우에는 UseCase에서 Parameter 대한 Naming Convention을 아래와 같이 정의합니다.
- Command (명령) - UseCase의 Input Port Parameter
- 명령은 시스템의 상태를 변경하는데 사용됩니다. 즉, 데이터를 업데이트하거나 변경하는 작업을 수행합니다.
- UseCase의 입력은 시스템에 어떤 변화를 일으키기 위한 명령을 나타내므로 Command로 지칭합니다.
- 일반적으로 "명령"의 의미에 맞게 어떤 작업을 수행하는 메서드의 이름에 해당합니다.
- Query (조회) - UseCase의 Output Port Parameter
- 조회는 시스템의 상태를 읽는데 사용됩니다. 데이터를 읽고 조회하는 작업을 수행합니다.
- UseCase의 출력은 시스템의 현재 상태를 반환하므로 Query로 지칭합니다.
- 일반적으로 "조회"의 의미에 맞게 어떤 정보를 반환하는 메서드의 이름에 해당합니다.
Validate
Parameter의 검증은 내부에서 하진 않고 일반적으로 외부 시스템(Adapter)에서 해야한다고 생각합니다. 물론 도메인과 관련이 있다면 내부에서 해주는게 맞지만 일반적으로 도메인과 관련이 없는 검증이 많기 때문에 검증의 책임을 외부 시스템(Adapter)에 위임합니다. 하지만 Parameter의 검증이 도메인쪽에서도 중요하다면 안전을 위해 UseCase 내부에서도 검증을 해야합니다. 그렇기 때문에 해당 부분은 상황에 맞게 하는게 가장 좋은 솔루션 인것 같습니다.
