computer vision에서 나오는 객체탐지 알고리즘에서 쓰이는 객체 검출에 대해 알아보자
-
객체 검출
- input
이미지 형태 - output
물체의 부류(class) 구별 : 분류 문제로 적용
이미지 상 물체의 위치 식별 : 회귀 문제로 적용
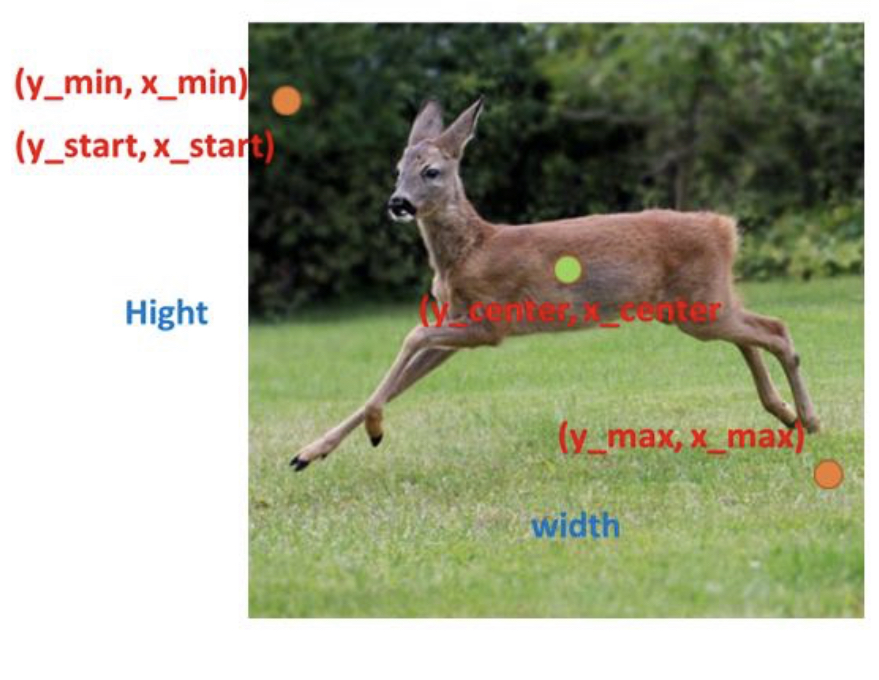
Bound Box의 표현 방식
아래 그림을 참고하면 다음과 같다.
- input
[y_min,x_min,y_max,x_max] : 이미지의 좌우측 대각선 끝지점으로 표현
[y_start, x_start,Hight,Weight] : 좌측 상단의 이미지 시작점 + 너비와 높이값으로 표현
[y_center, x_center,Hight, Weight] : 이미지 중앙 좌표 + 너비, 높이로 표현
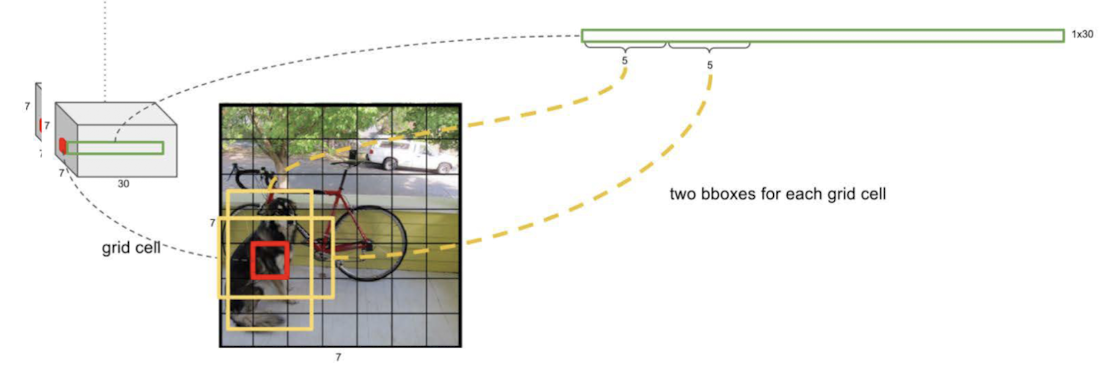
객체 검출 시스템
imagenet Bound Box 구축을 위한 시스템은 어떻게 구성이 되어있을까?
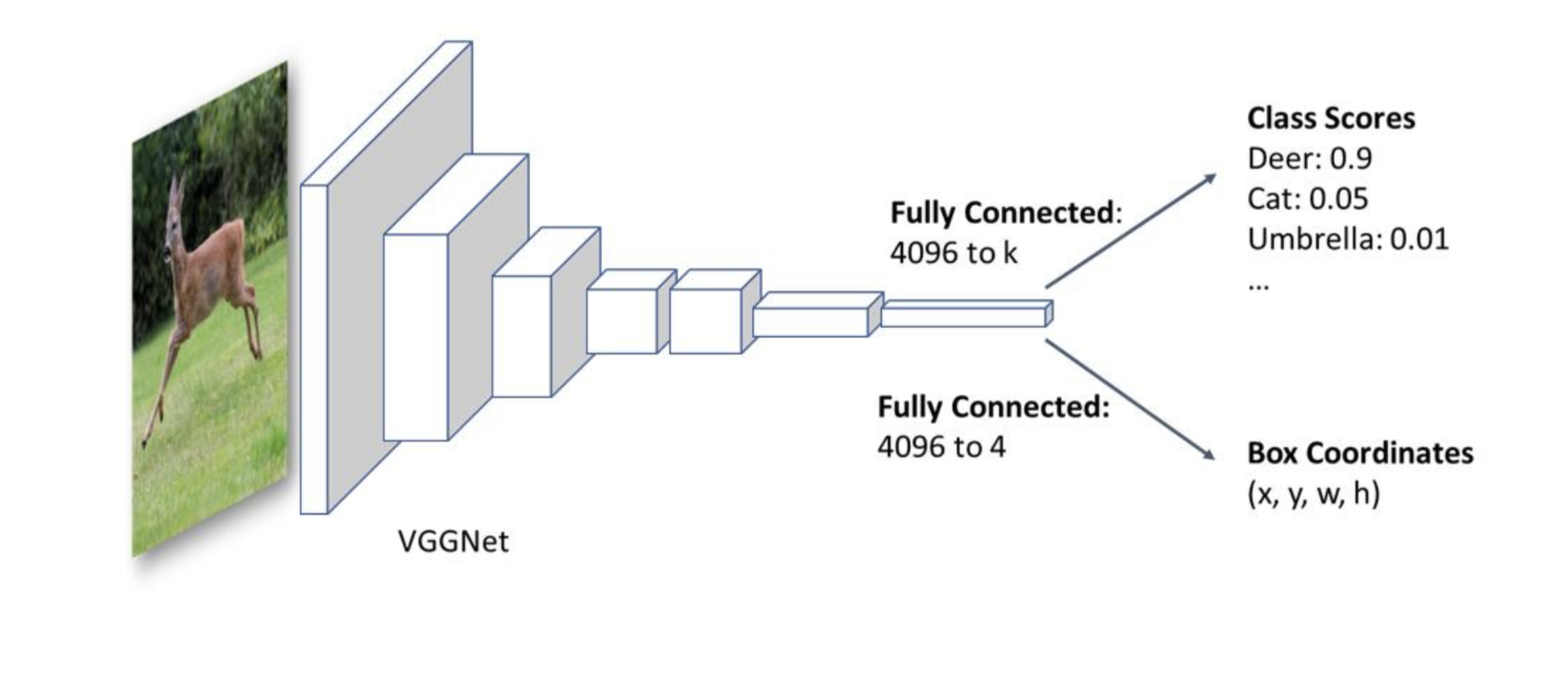
- class score
confidence score라고도 하며 각 이미지에 대한 class별 점수로 나타내어 class의 속할 확률값으로 나타낸다. - box Coordinates
객체가 위치한 위치에 대한 좌표도 검출해낸다.
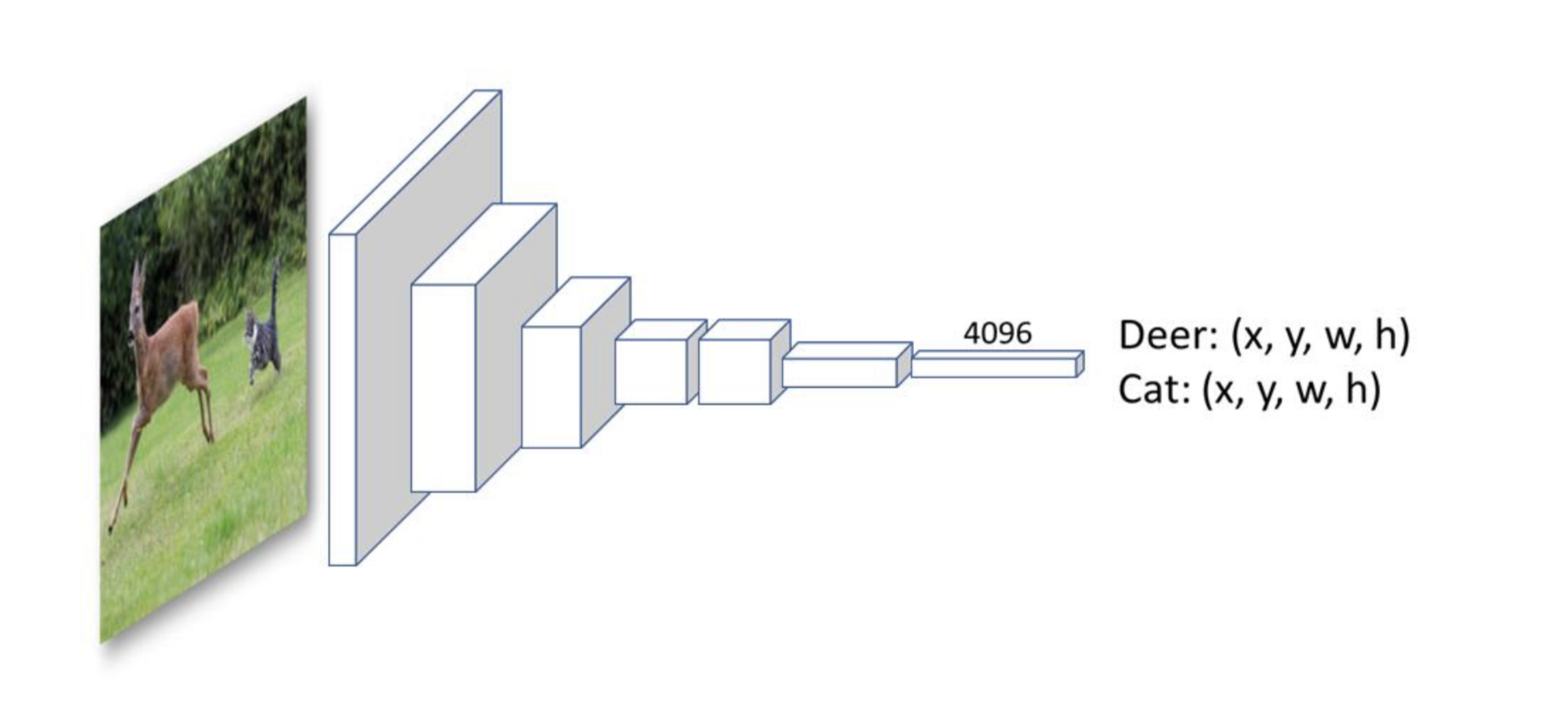
위처럼 서로 다른 객체가 존재할 때, 각 객체에 대한 class정보와 객체의 위치를 얻어낼 수 있다.
딥러닝 알고리즘 기반 객체 검출 : 전통적인 방식
분류 작업을 위해 Window Sliding을 적용해 region proposal이라는 후보 영역을 획득한다.
이렇게 되면 Window 크기에 따라 객체가 검출될 수도 있고 검출되지 않을 수도 있게된다
-> 따라서 다양한 크기의 region proposal을 얻기 위해 image Down-sampling이나 Up-sampling을 수행한다.

- 이미지 샘플링 이후

- Non - Maximum Suppression (비 최대 억제) 방식
- 객체 근처에 다양한 크기의 Region Proposal들을 생성한다.
- 객체 크기에 맞는 Bounding Box만을 남기고 모두 지운다.

- 하지만 이와 같은 Window Sliding방식은 stride나 Up, down-sampling처럼 다양한 window를 만들기 때문에 연산량이 많아 시간도 오래걸리고, 실시간 처리가 불가하다..!
- 이러한 과정에서 수작업까지도 필요하기도 하다고한다..
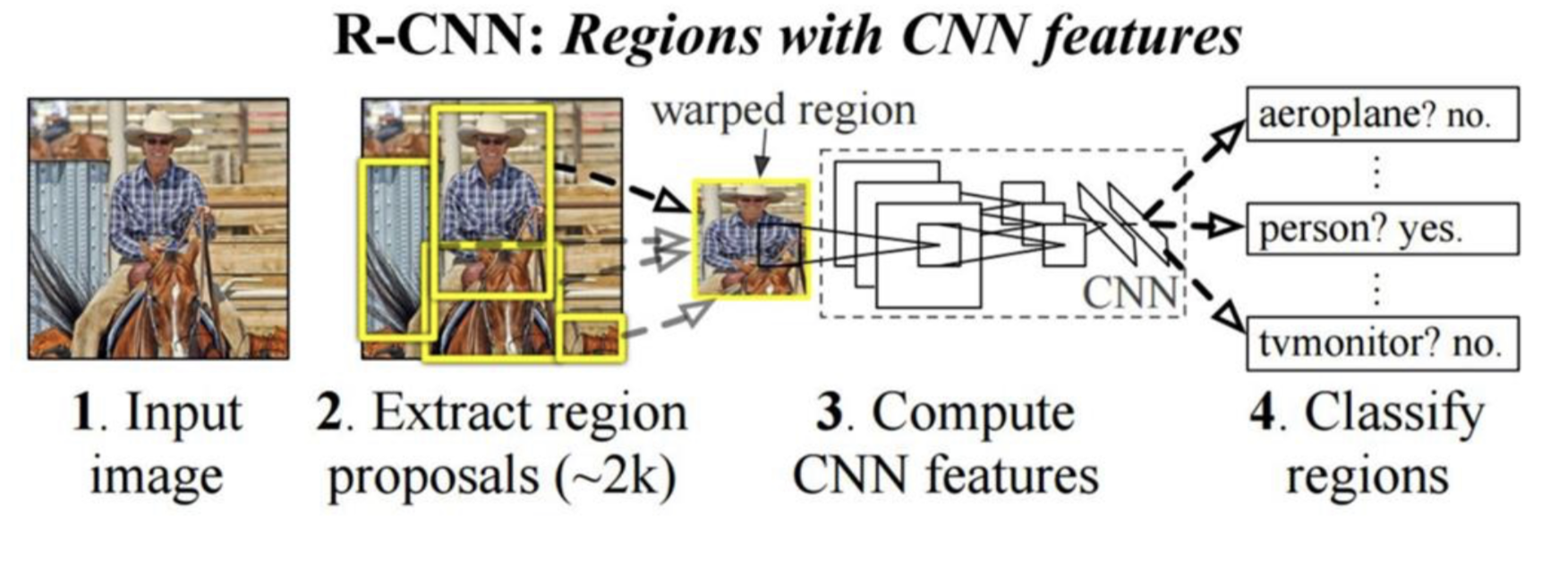
RCNN 알고리즘(2014)
출저
https://people.eecs.berkeley.edu/~rbg/papers/r-cnn-cvpr.pdf
Rich feature hierarchies for accurate object detection and semantic segmentation.
Girshick et al. CVPR 2014.
하나의 시스템 안에 region proposal과 분류기를 한번에 담았다.
입력 이미지가 주어지면, region proposal을 수행(후보 영역을 찾음)하는데, 이는 selective search 방식을 통해 region proposal을 제시한다.
이후, CNN feature들로 계산한다. CNN + MLP층을 통과하며 MLP층의 output으로 분류(classification)하고, region영역을 결정하게 된다.
- warped region
입력으로 주어지는 값이 고정적인 크기로 주어져야하기 때문에, 일정 크기의 입력으로 조정을 하다보니 이미지가 왜곡되는 현상이 발생하게된다. - SVM
MLP층 이후 분류작업을 SVM알고리즘으로 진행한다. - two stage processing 방식
Region Proposal 산정 작업과 분류 및 회귀를 수행하는 영역이 구별
다음에서 각 단계별로 어떤 방식으로 실행되는지 알아보자.
1단계, 2단계
- class에 독립적인 Region Proposal들을 생성한다. 이미지 마다 2천개의 Region Proposal을 만든다.
- selective search(선택 탐색)을 수행
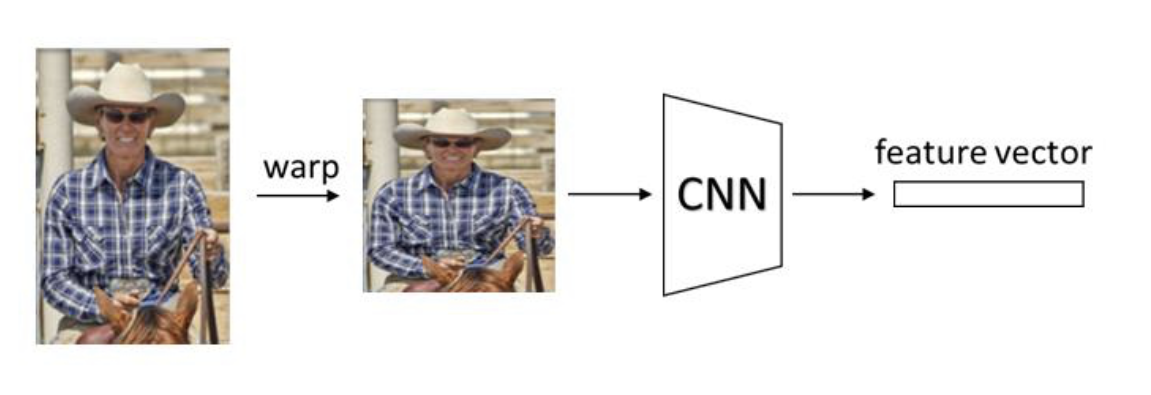
Region Proposal을 얻기 위해 화소의 color, texture, size, shape에 따라 유사한 region을 단계적으로 병합한다. - Region Proposal에 주어지는 Bounding Box를 Warping기술을 적용(warped region)해 CNN층의 입력으로 사용한다.
아래는 227x227크기로 warping 이후 CNN층의 입력으로 넣는 모습이다.
3단계, 4단계
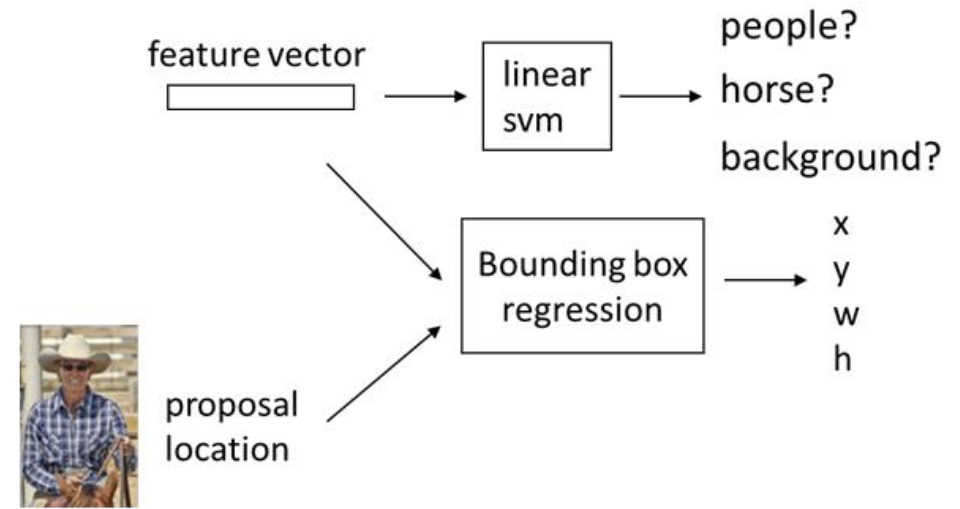
- 선형 SVM알고리즘을 이용하여 분류작업을 수행한다. 이로서 객체 부류 및 위치를 결정한다.
- regression(회귀) 과정을 통해 바운딩 박스의 정확한 위치를 찾아가고자 한다.
Pros & Cons
- 개선된 점
단순한 구조이며, 다양한 크기의 이미지 처리가 가능해졌다.
성능면에서 개선이 이루어졌다.(mAP : mean Accuracy Precision 개선) - 단점
다단계 처리 방식이다.
학습 과정 (warping 후 input으로 넣음)에 많은 메모리나 시간이 소비되게 됨.
객체 검출 과정도 느려서 실시간 처리가 불가능하다.(실시간 처리는 two stage processing 때문)
오바야..
해서 RCNN을 개선하고자 만들어진 다음 알고리즘을 살펴보자!
Fast RCNN 알고리즘
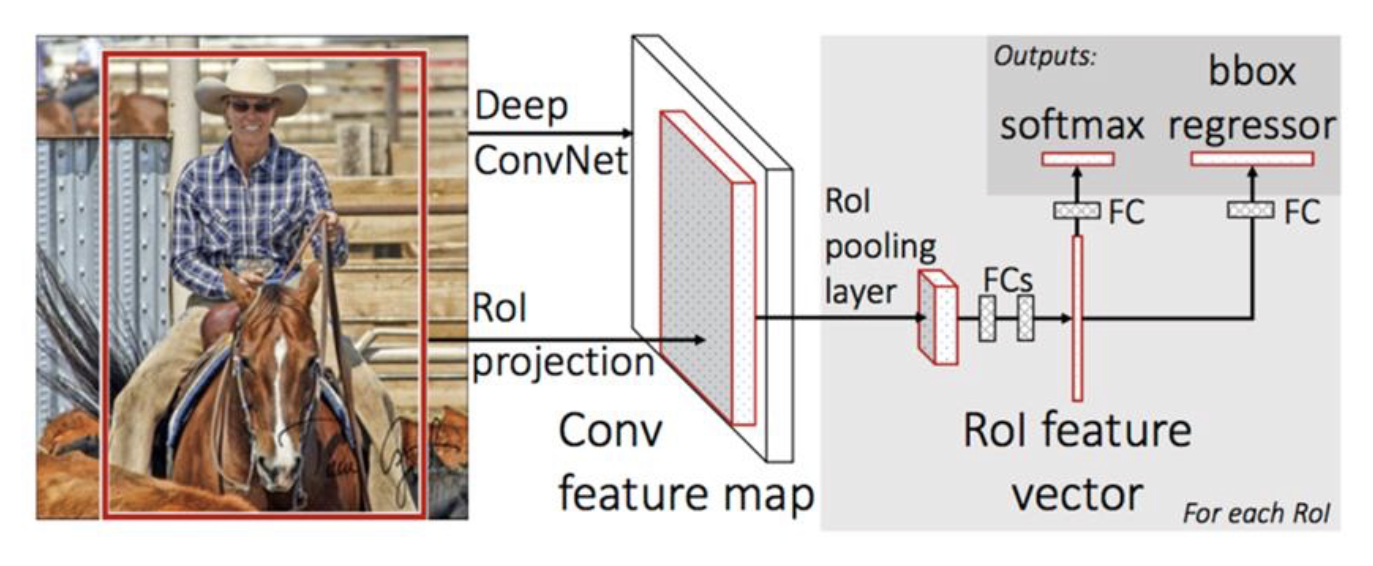
모든 BBox(Bounding Box)에 관해 특징의 재추출 과정을 제거했다.
- 이미지에 대해서 CNN층에서 feature map을 만들어 낸다.
- 이를 통해 마지막 출력으로 두개의 FC(Fully connected layer)에서 클래스 부류출력(-> softmax)과 BBox위치값(regressor)의 추정값을 얻어낸다.
output에 대한 정보 :

- FC를 쌓아 MLP구조로 만들어 각각을 분류기와 회귀로 활용한다.
여기서 warping문제는 어떻게 해결했을까?
Fast RCNN에서는 convolutoin feature map을 얻기 위해 3~4단계의 conV층과 maxpooling층을 갖는 딥러닝 알고리즘이 수행되는데, 이 때 고정된 크기의 feature map을 얻기위해 Roi pooling을 수행한다.
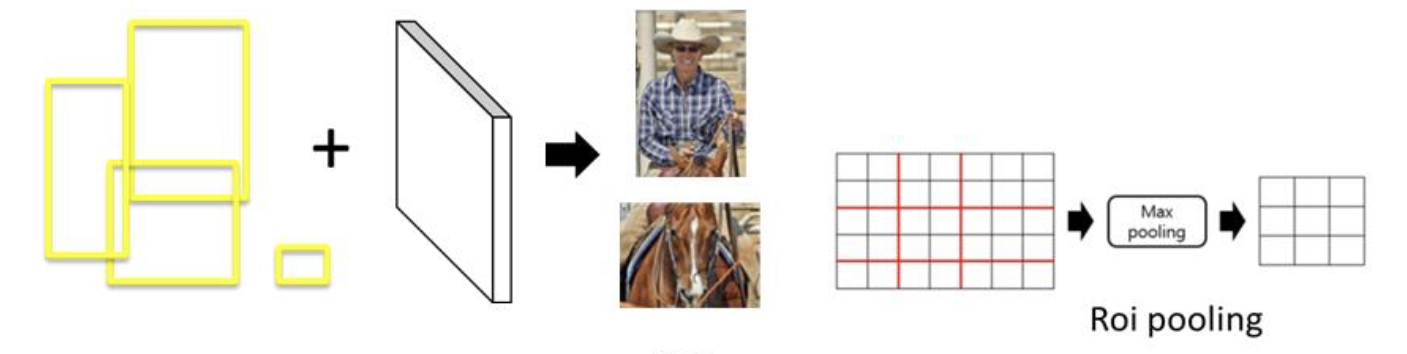
이미지 크기가 다양하다 하더라도, 이미지 셀에 대한 max pooling(stride=2)를 진행하여 warping시 발생하는 이미지 왜곡 문제를 어느정도 해결한다.
Pros & Cons
-
개선된 점
mAP성능과 연산속도가 개선됐다.
입력이 주어지면 출력까지 사람의 개입이 없어졌다. -
문제점
여전히, 후보영역(Region Proposal)산정을 Selective Search로 수행하다보니, 아직도 후보영역을 결정하는데 느리고, CPU나 GPU에 Bottleneck 현상을 유발한다.
이를 개선하기위해 Faster-RCNN이 등장한다.
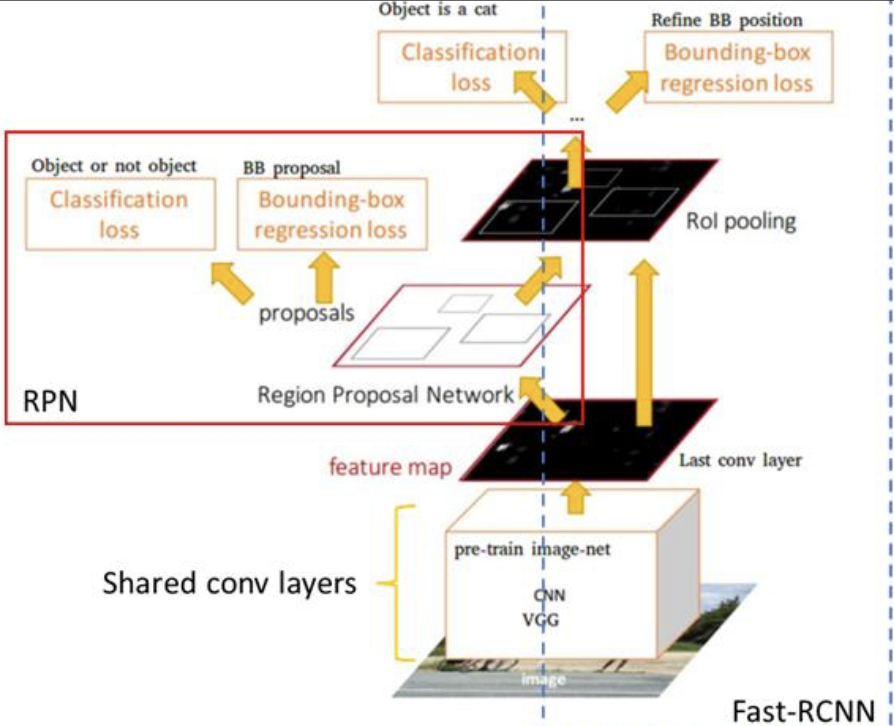
Fater-RCNN 알고리즘
CNN예측기의 일부로 Region Proposal을 통합시켰다.
- 입력에 대해, VGGnet을 이용해 feature map을 얻는다.
- RPN(Region Proposal Network)을 통해 selective search가 하는 일을 대신한다. 즉, 후보 영역을 여기서 산정을 하게 된다.
- Roi pooling을 통해 마지막 네트워크의 입력값으로 변환을 한 후, 분류와 회귀의 작업을 통해 최종 출력값으로 출력하게 된다.
- Region Proposal 네트워크와 분류 및 회귀를 수행하는 영역이 구별되어 있으므로, 이 역시도 two stage processing 방식이다. (실시간 처리 불가능)
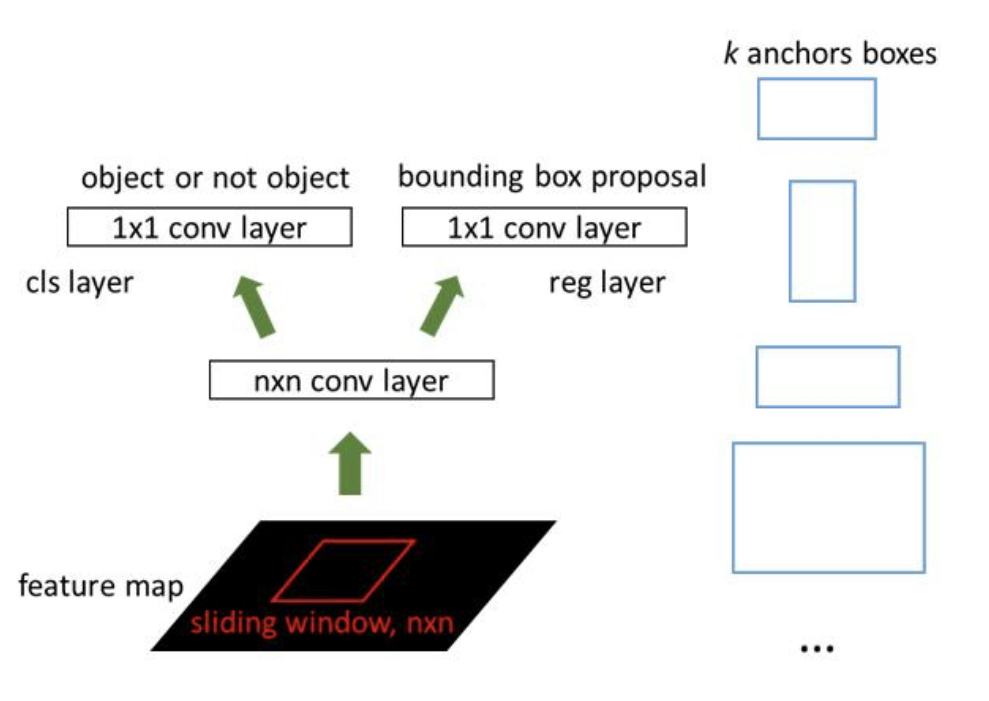
anchor Box
이 알고리즘에선 anchor(닻) Box를 갖고있다.
- region proposal을 찾는데 기준이 된다.
- 적합한 BBox를 찾기 위한 해를 정해놨다고 생각할 수 있다.
Pros & Cons
- 개선된 점
CNN구조로 후보영역(Region Proposal)을 계산한다
RPN과 Fast R-CNN을 단일 네트워크로 통합했다. - 단점
단일 네트워크를 통해 end-to-end구조를 가지나 2단계 수행방식으로 실시간 처리가 어렵다.
이를 개선한 YOLO 알고리즘이 제시되었다.
다음 포스트에서... !
