
자료형
ex) 정수형, 실수형, 복소수형, 문자열, 리스트, 튜플, 사전 등
1. 수 자료형
1) 정수형 (Integer)
: 정수를 다루는 자료형 (양의 정수, 음의 정수, 0)
2) 실수형 (Real Number)
: 소수점 아래의 데이터를 포함하는 수 자료형
- 파이썬에서는 변수에 소수점을 붙인 수를 대입하면 실수형 변수로 처리된다.
- 소수부가 0이거나 정수부가 0인 소수는 0을 생략하고 작성할 수 있다.
ex) 0.7 -> .7 / 5.0 -> 5.
지수 표현 방식
: e나 E를 이용한 지수 표현 방식
- e나 E 다음에 오는 수는 10의 지수부를 의미
- 유효숫자e^지수 = 유효숫자x10^지수
ex) 1e9 = 10^9 - 임의의 큰 수(INF)를 표현하기 위해 자주 사용됨
- 실수형 데이터로 처리됨
print(1e9) => 100000000.0
print(int(1e9)) => 1000000000📏 실수값을 제대로 비교 📏하기 위해 반올림 함수인 round()를 이용할 수 있다.
a = 0.3 + 0.6
print(a)
if a == 0.9:
print(True)
else:
print(False)
"""
실행결과
0.8999999999999999
False
"""a = 0.3 + 0.6
print(round(a,4))
if round(a,4) == 0.9:
print(True)
else:
print(False)
"""
실행결과
0.9
True
"""3) 연산자
/ : 나누기 연산자 => 결과를 실수형으로 반환
% : 나머지 연산자
// : 몫 연산자
** : 거듭제곱 연산자
2. 리스트 자료형
: 여러개의 데이터를 연속적으로 담아 처리하기 위해 사용
a.k.a. 배열 or 테이블
1) 리스트 초기화
- 대괄호([]) 안에 원소를 넣어 초기화
- 쉼표로 원소 구분
- 비어 있는 리스트 선언 => list() 혹은 []
2) 리스트 인덱싱
- 대괄호([]) 안에 인덱스 값을 넣어 원소에 접근
- 인덱스는 0부터 시작
- 인덱스는 양의 정수와 음의 정수를 모두 사용할 수 있음 (음의정수=>거꾸로)
ex) a[-1] : 뒤에서 첫번째 원소
3) 리스트 슬라이싱
- 연속적인 위치를 갖는 원소들을 가져올 때 사용
- [시작인덱스:끝인덱스]
- 끝인덱스는 실제 인덱스보다 1 크게 설정
ex) a[1:4] : 2번째 원소부터 4번째 원소까지 (즉 1,2,3번째 원소)
4) 리스트 컴프리헨션
- 대괄호 안에 조건문과 반복문을 적용하여 리스트를 초기화할 수 있음
array = [i for i in range(10)]
print(array)
"""
실행결과
[0,1,2,3,4,5,6,7,8,9]
"""array = [i for i in range(20) if i % 2 == 1]
print(array)
"""
실행결과
[1,3,5,7,9,11,13,15,17,19]
"""array = [i * i for i in range(1,10)]
print(array)
"""
실행결과
[1,4,9,16,25,36,49,64,81]
"""- 2차원 리스트를 초기화할 때 효과적으로 사용됨
ex) N x M 크기의 2차원 리스트 초기화
=> 📌array = [[0] * m for _ in range(n)]📌
n = 4
m = 3
array = [[0] * m for _ in range(n)]
print(array)
"""
실행결과
[[0,0,0],[0,0,0],[0,0,0],[0,0,0]]
"""파이썬에서 반복을 수행하되 반복을 위한 변수의 값을 무시하고자 할 때 언더바( _ )를 사용한다.
for _ in range(5): print("Hello World")
[[0] * m] * n으로 초기화하면 전체 리스트 안에 포함된 각 리스트가 모두 같은 객체로 인식되어 값을 하나만 바꿔도 모든 내부 리스트의 해당 위치의 값이 바뀜
5) 리스트 관련 메소드
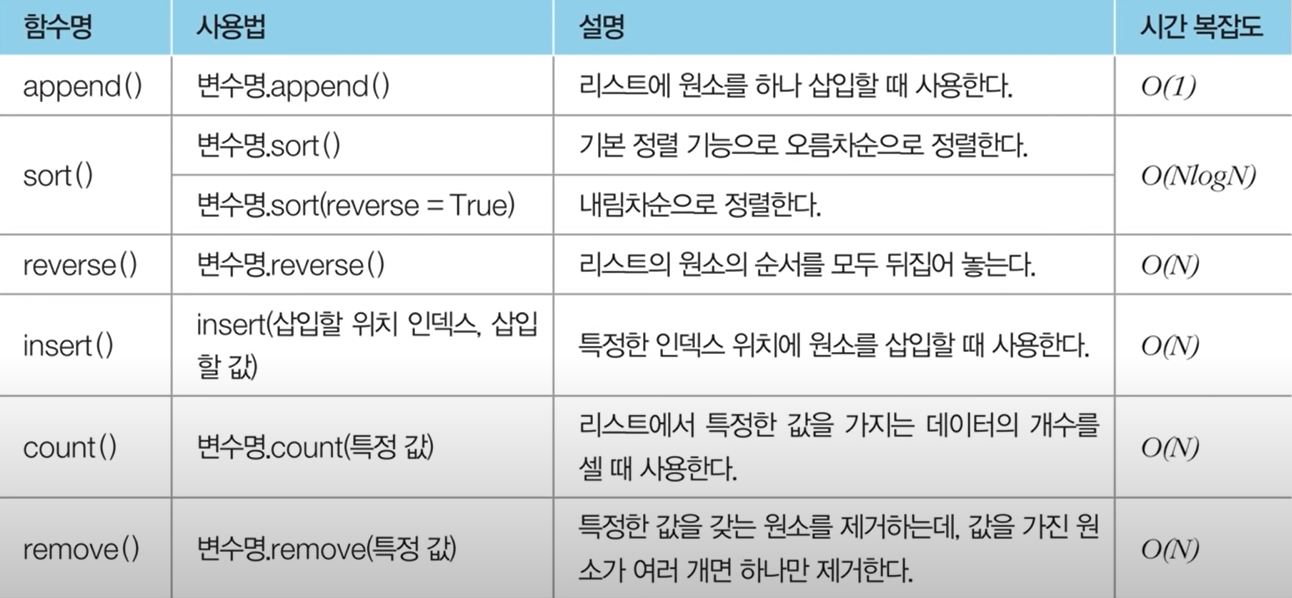
- 리스트에서 특정 값을 가지는 원소를 모두 제거하기
a = [1,2,3,4,5,5,5]
remove_set = {3,5}
result = [i for i in a if i not in remove_set]
print(result)
"""
실행결과
[1,2,4]
"""3. 문자열, 튜플 자료형
1) 문자열
- 문자열 초기화는 큰따옴표( " )나 작은따옴표( ' ) 사용
- 백슬래시( \ )로 큰따옴표/작은따옴표를 원하는 만큼 포함시킬 수 있음
- 덧셈(+)으로 문자열을 더해서 연결할 수 있음
- 문자열 변수를 특정한 양의 정수와 곱하는 경우, 문자열이 그만큼 더해짐
- 문자열에도 인덱싱과 슬라이싱 가능 (값 변경은 불가능)
2) 튜플
- 리스트와 유사함
- 한번 선언된 값을 변경할 수 없음
- 소괄호( () ) 이용
ex) a = (1,2,3,4,5) - 공간효율적
- 서로 다른 성질의 데이터를 묶어서 관리해야 할 때
- 최단 경로 알고리즘에서(비용, 노드번호)의 형태로 자주 사용함 - 데이터의 나열을 해싱의 키 값으로 사용해야 할 때
- 리스트보다 메모리를 효율적으로 사용해야 할 때
4. 사전, 집합 자료형
1) 사전
- 키(Key)와 값(Value)의 쌍을 데이터로 가지는 자료형
- 키와 값의 쌍을 데이터로 가지며, 원하는 '변경 불가능한 자료형'을 키로 사용할 수 있음
- 해시테이블을 이용하므로 데이터 조회 및 수정을 O(1) 시간에 처리 가능
- 초기화 :
data = dict() keys(): 키 데이터만 뽑아서 리스트로 이용values(): 값 데이터만 뽑아서 리스트로 이용
2) 집합
- 중복을 허용하지 않고 순서가 없음
- 리스트 혹은 문자열을 이용해서 초기화
- 이때set()함수를 이용 - 중괄호( {} ) 안에 각 원소를 콤마( , )를 기준으로 구분하여 삽입해 초기화할 수도 있음
- 데이터의 조회 및 수정에 있어서 O(1) 시간에 처리 가능
data = set([1,1,2,3,4,4,5])
print(data)
data = {1,1,2,3,4,4,5}
print(data)
"""
실행결과
{1,2,3,4,5}
{1,2,3,4,5}
"""|: 합집합 - 집합A에 속하거나 B에 속하는 원소로 이루어진 집합&: 교집합 - 집합A에도 속하고 B에도 속하는 원소로 이루어진 집합-: 차집합 - 집합A의 원소 중에서 B에 속하지 않는 원소들로 이루어진 집합add(): 새로운 원소 추가ex) data.add(4)update(): 새로운 원소 여러개 추가ex) data.update([5,6])remove(): 특정한 값을 갖는 원소 삭제ex) data.remove(3)

일기장같은 공부기록📝