
JPA소개
JPA를 사용하면 애플리케이션을 SQL이 아닌 객체 중심으로 개발하여 생산성과 유지보수가 좋아진다.
데이터베이스를 바꿔도 코드를 거의 수정하지 않고 손쉽게 변경가능.
SQL 중심적인 개발의 문제
클래스에 새로운 필드가 추가되면
CRUD하는 SQL에도 새로운 필드를 다 추가해줘야 한다.
→ SQL에 의존적인 개발
패러다임의 불일치
객체 VS 관계형DB
객체를 관계형DB에 넣으려면 SQL로 바꿔서 DB에 넣어야한다.
중간에 SQL로 변환하는 것은 개발자가 한다.
상속
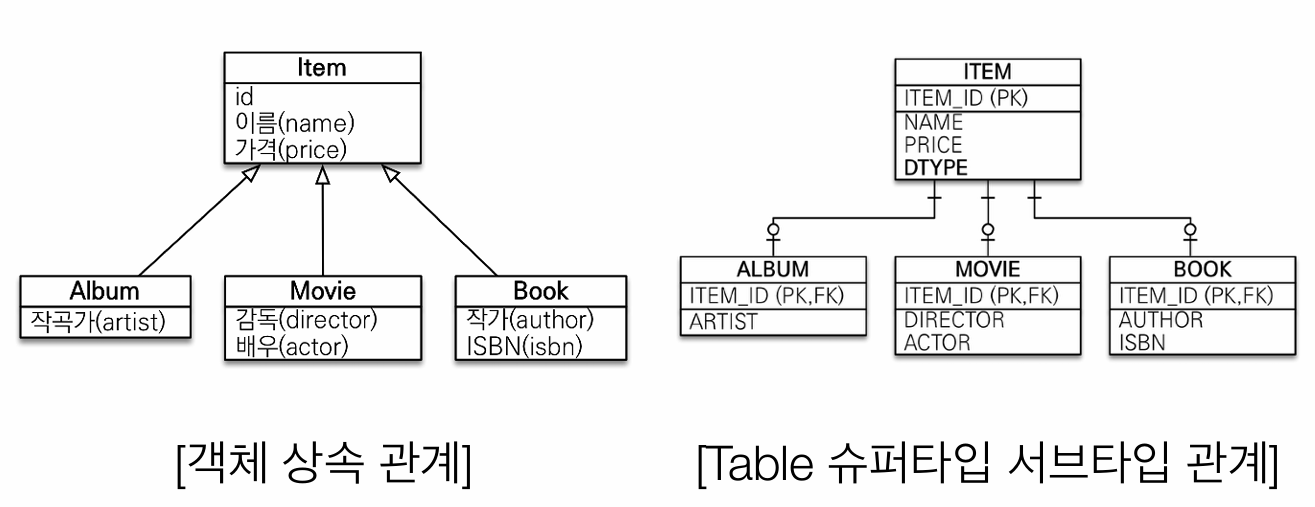
객체는 상속의 개념이 있고,
테이블은 슈퍼타입 서브타입 관계가 있지만 이것이 상속은 아니다.
객체에서 자식 객체에 데이터를 넣으려면
DB에서는 상위 타입과 하위 타입에 INSERT 쿼리를 작성해야하고,
조회 한다고 해도 테이블을 Join해야 한다.
→ 패러다임의 불일치를 해결하려는데 소모하는 비용이 크다.
JPA를 이용해 Album객체를 저장한다면
jpa.persist(album);을 이용해서 ITEM과 ALBUM에 저장하는 쿼리를 만들어 두테이블에 저장한다.
조회하면 두 테이블을 JOIN해서 결과를 반환 한다.
연관관계
객체는 참조를 이용해서 연관된 객체를 조회하고 테이블은 외래키를 이용해 연관된 테이블과 JOIN하여 조회한다.
객체를 테이블에 맞추어 모델링
class Member{
String id; //MEMBER_ID 컬럼 사용
Long teamId; //TEAM_ID FK컬럼 사용
String username; //USERNAME컬럼 사용
}
class Team{
Long id; //TEAM_ID PK사용
String name; //NAME 컬럼 사용
}
객체다운 모델링
class Member{
String id; //MEMBER_ID 컬럼 사용
Team team; //참조로 연관관계를 맺음
String username; //USERNAME컬럼 사용
Team getTeam(){
return team;
}
}
class Team{
Long id; //TEAM_ID PK사용
String name; //NAME 컬럼 사용
}
객체는 참조만 있으면 되고 , 반면 테이블은 참조가 필요없고 외래키만 있으면 된다.
결국 meber.getTeam().getId() 처럼 개발자가 중간에 변환역할을 해야함.
즉 패러다임의 불일치를 해결하는데 드는 비용이 든다.
JPA를 사용하면
member.setTeam(team) //회원과 팀 연관관계 설정
jpa.persist(member) //회원과 연관관계 함께 저장회원과 팀 연관 관계를 설정하고 회원객체를 저장하면됨.
객체 그래프 탐색
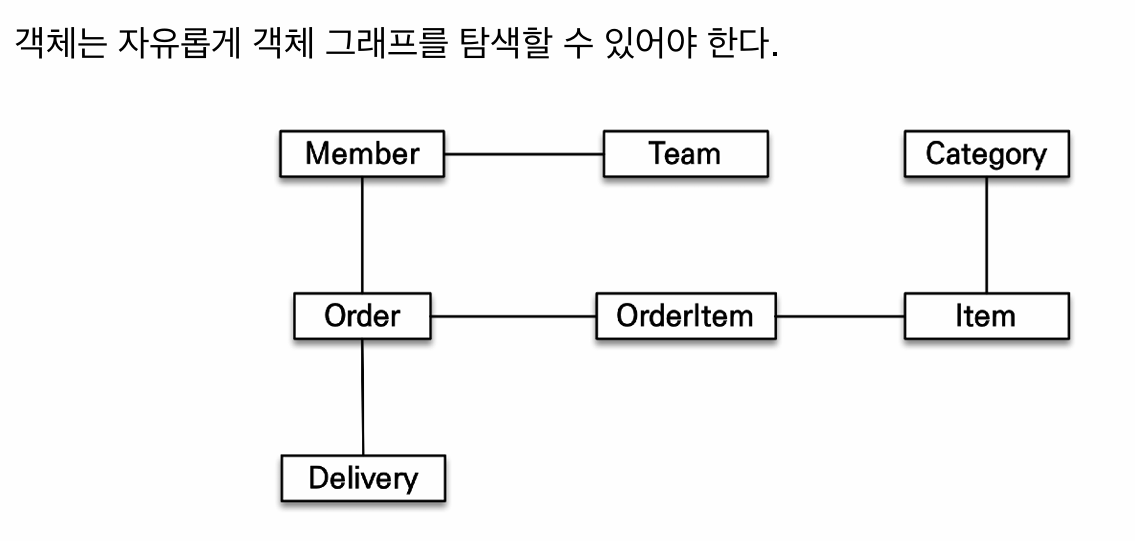

MEMBER와 TEAM을 JOIN해서 조회하면 팀은 조회되지만 order는 데이터가 없으므로 탐색할 수 없다.

멤버를 조회했지만 이것만으로 order와 delivery 데이터가 있는지 모른다. 결국 SQL 살펴봐야한다.
모든 데이터를 조회해서 미리 로딩하는 것은 현실성이 없다.
결국 상황에 맞게 조회하는 메소드를 여러개 만들어야한다.

JPA를 사용하면 객체 그래프를 마음껏 탐색할 수 있다.
JPA는 연관된 객체를 사용하는 시점에 적절한 SELEC문을 실행한다. (지연로딩)
비교

주소를 비교하는 동일성에서 다르다.
같은 회원을 두번 조회했지만 새로운 객체를 만들어서 동일성 비교에서 실패
JPA를 사용하면 같은 트랜잭션일 때 같은 객체가 조회되는 것을 보장해서 동일성비교에서 성공
- JPA는 객체를 자바 컬렉션에 저장하듯이 ORM프레임워크에 저장한다. 반복적인 코드와 CRUD용 SQL을 개발자가 직접하지 않아 생산성 증가
- SQL을 직접 다루면 필드 하나만 추가해도 CRUD SQL을 변경해줘야하지만 JPA는 이런 과정ㅇ을 대신 처리해줘 유지보수에 좋다
- 패러다임의 불일치 해결
- 같은 데이터를 두번 조회할 때 마다 DB와 통신을 하지만, JPA는 한번만 DB와 통신하고 두번째는 조회한 데이터를 재사용해 성능에 좋다
