
Alert-service의 Kafka컨슈머는 다른 MSA서비스에서 온 이벤트를 받아서 Slack메시지 알림을 전송하는 역할을 한다.
jmeter로 부하테스트를 하는데 메세지 전송 실패가 많이 발생했다.
Slack API HTTP 429 Too Many Requests
 그 이유가 Slack API에서
그 이유가 Slack API에서 HTTP 429 Too Many Requests가 발생했기 때문이다.
| Web API Special Tier | Varies | Rate limiting conditions are unique for methods with this tier. For example, chat.postMessage generally allows posting one message per second per channel, while also maintaining a workspace-wide limit. Consult the method's documentation to better understand its rate limiting conditions. |
|---|
이 등급의 메서드에는 고유한 속도 제한 조건이 있습니다. 예를 들어, chat.postMessage 메서드는 일반적으로 채널당 초당 1개의 메시지 전송을 허용하며, 워크스페이스 전체에 대한 제한도 유지됩니다. 보다 자세한 속도 제한 조건은 해당 메서드의 문서를 참고하세요.
나는 테스트를 위해 Slack메세지 전송을 하나의 채널ID만 사용했는데, Slack자체 서버에서 처리율을 초당 1개로 제한해서 에러가 발생한 것이다. 그리고 위에 워크스페이스 전체에 대한 제한도 유지된다고 써있었다.
이것을 보고 메시지 전송 메서드에 대해서는 슬랙 자체에서 처리율을 초당 1개로 막아놔서, 컨슈머를 최적화 하더라도 슬랙에서 병목이 생길것이라고 생각했다.
그래서 toekn bucket으로 우리 서버 자체의 처리율을 슬랙서버에 맞추자고 생각했다.
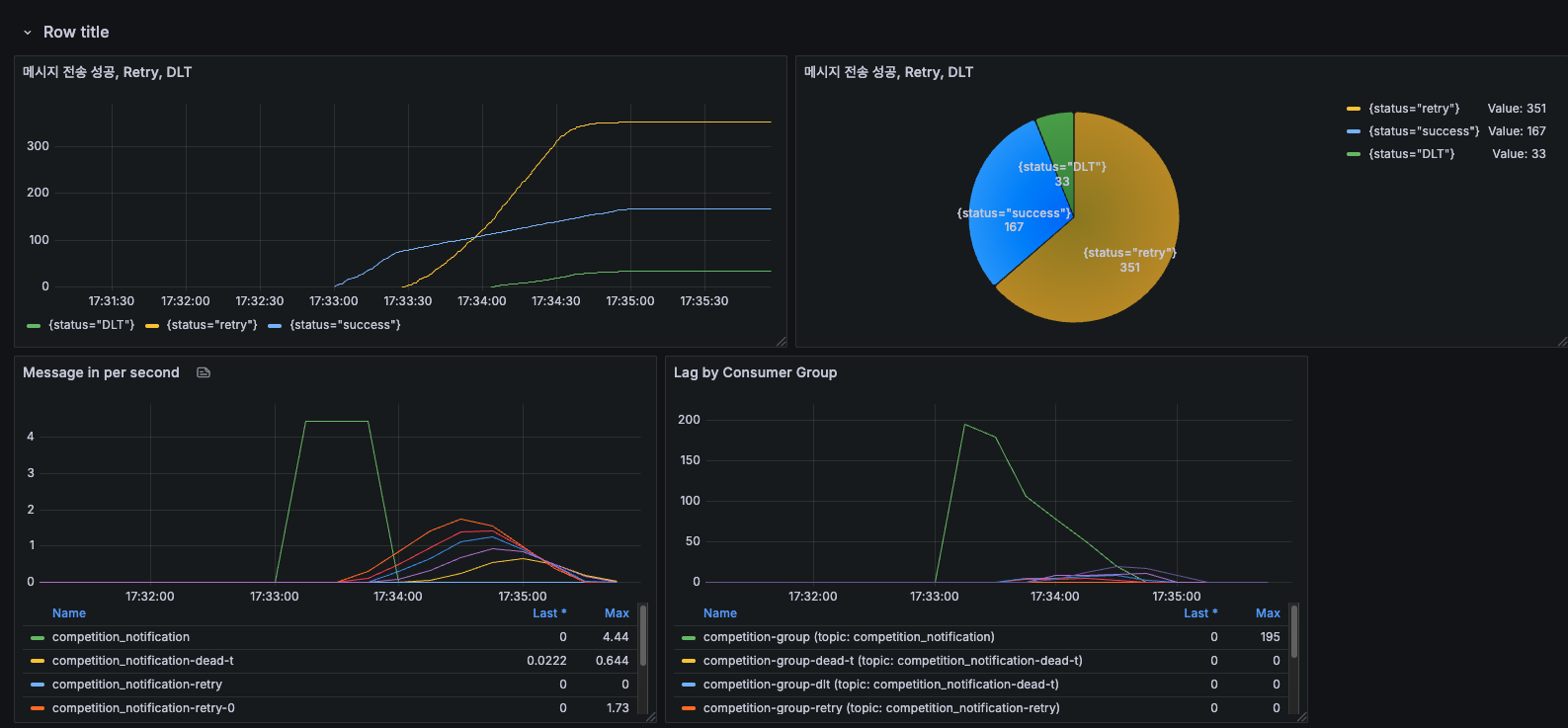
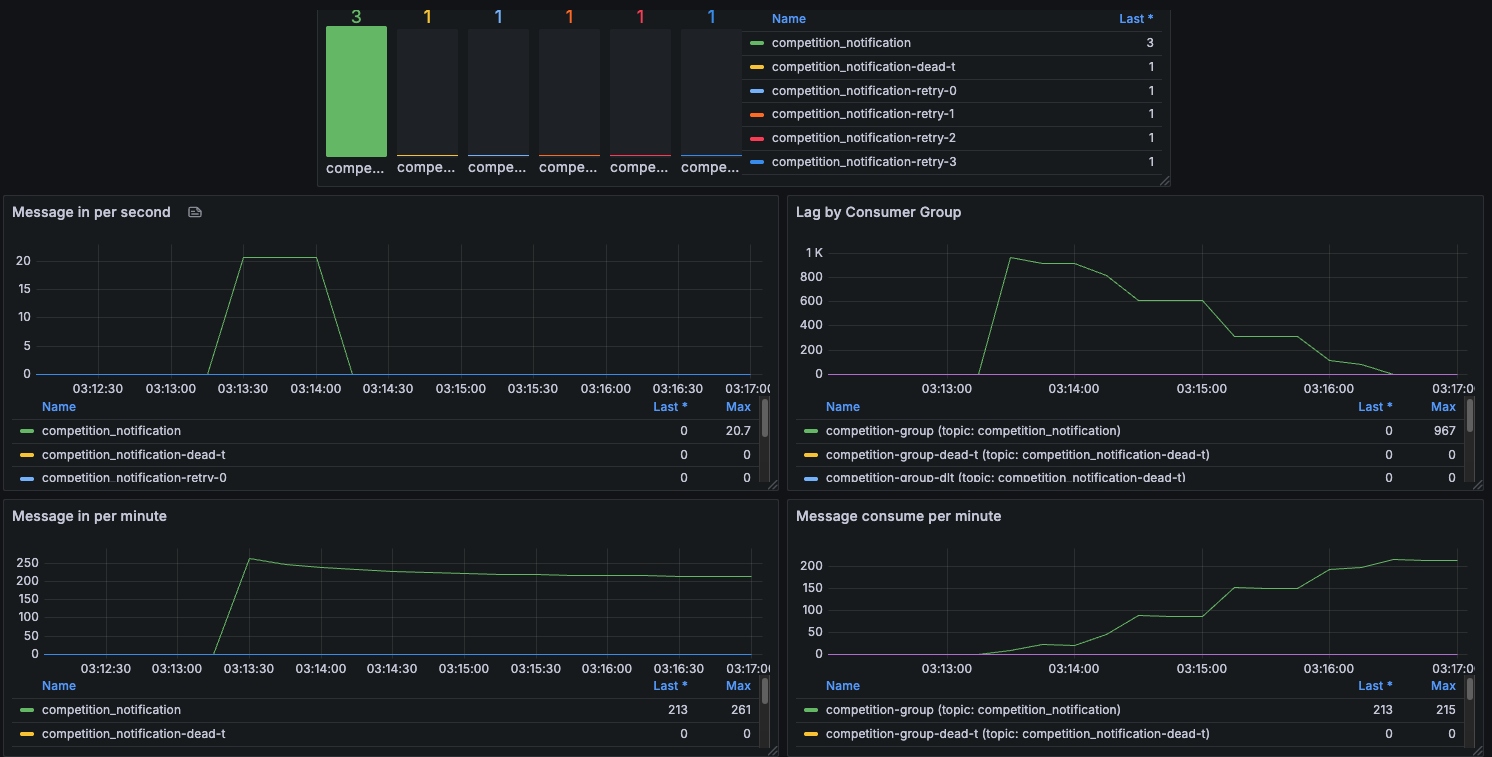
 token을 초당 한개씩 리필해서 1초에 한 건씩 메시지를 보내려고 했지만 오히려 메시지 전송 성공률이 더 떨어졌다. (위 사진 결과)
token을 초당 한개씩 리필해서 1초에 한 건씩 메시지를 보내려고 했지만 오히려 메시지 전송 성공률이 더 떨어졌다. (위 사진 결과)
Slack Rate limiting
방법을 찾아보다가 "보다 자세한 속도 제한 조건은 해당 메서드의 문서를 참고하세요."라고 나와있어 슬랙API 문서를 다시 살펴봤다.
chat.postMessage has special rate limiting conditions. It will generally allow an app to post 1 message per second to a specific channel. There are limits governing your app's relationship with the entire workspace above that, limiting posting to several hundred messages per minute. Generous burst behavior is also granted.
chat.postMessage는 특별한 속도 제한 조건이 있습니다. 일반적으로 앱은 특정 채널에 초당 1개의 메시지를 보낼 수 있습니다. 이 외에도 앱과 워크스페이스 전체의 관계에 따라 분당 수백 개의 메시지 전송에 대한 제한이 적용됩니다. 또한, 일시적으로 많은 메시지를 전송할 수 있는 버스트(burst) 허용 범위도 제공됩니다.
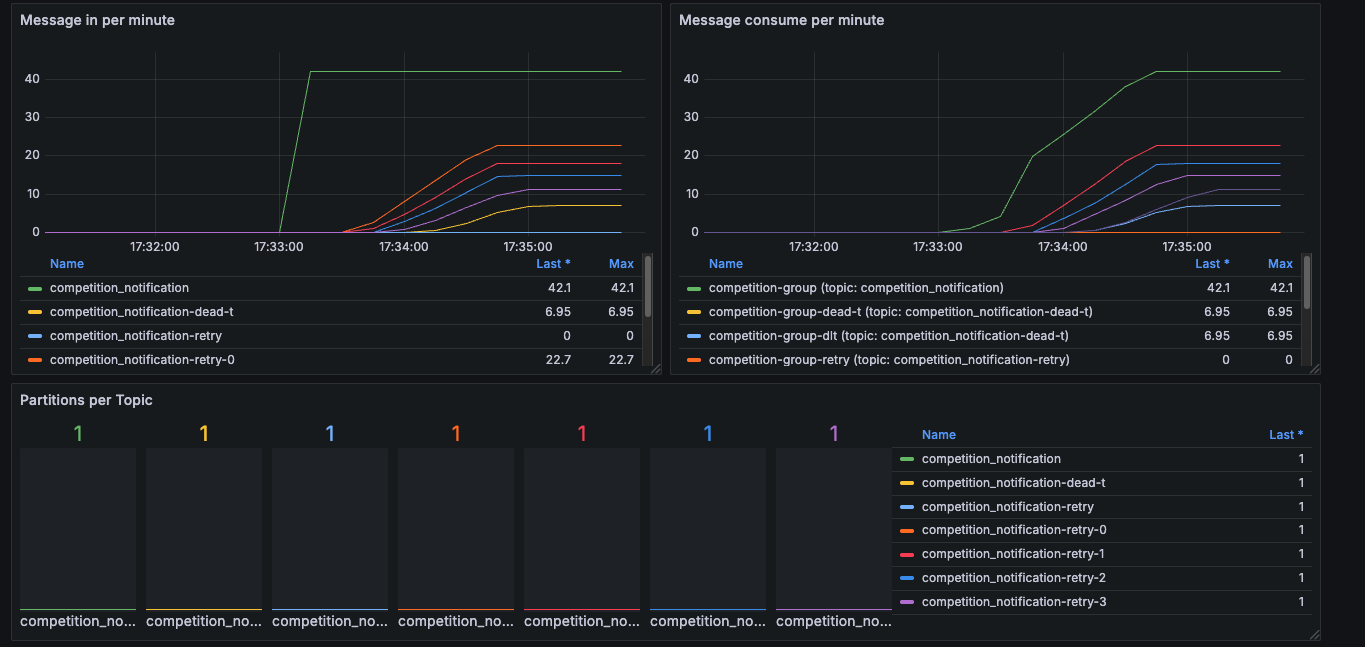
그래서 채널 여러개를 만들고 각 랜덤채널로 메세지를 보내도록 다시 테스트했다.
chat.postMessage메서드는 워크스페이스 전체에서 분당 수백개를 보낼 수 있다니까 채널ID를 20개 정도 추가해서 테스트 해보자.
Kafka Consuemr 성능 개선
 메세지를 채널ID 여러개로 설정하고 테스트하니 429에러는 발생하지 않았다.
메세지를 채널ID 여러개로 설정하고 테스트하니 429에러는 발생하지 않았다.
Kafka컨슈머 Lag도 우하향 하면서 정상적으로 감소하고있다.
그런데 시간이 너무 오래 걸렸다.(1000개 보내는데 7분 정도 걸림)
파티션 늘리기
먼저 파티션을 늘려보았다.
docker exec -it kafka kafka-topics.sh --bootstrap-server kafka:29092 --alter --topic competition_notification --partitions 3 @Bean
public ConcurrentKafkaListenerContainerFactory<String, Object> kafkaListenerContainerFactory() {
ConcurrentKafkaListenerContainerFactory<String, Object> factory =
new ConcurrentKafkaListenerContainerFactory<>();
factory.setConsumerFactory(consumerFactory());
// 동시에 처리할 수 있는 스레드 수 (파티션 수에 맞게 조정)
factory.setConcurrency(3);
return factory;
}현재 테스트하고 있는 Topic의 파티션을 3개로 늘리고, spring에서도 Kafka설정을 통해 Consumer를 3개로 늘렸다.
파티션 수만큼 컨슈머를 늘려야한다. 파티션 하나당 하나의 컨슈머가 맞아 처리한다.
컨슈머를 파티션 수 이상으로 하면 나머지 컨슈머들은 유휴상태가 되어 자원이 낭비가 된다.
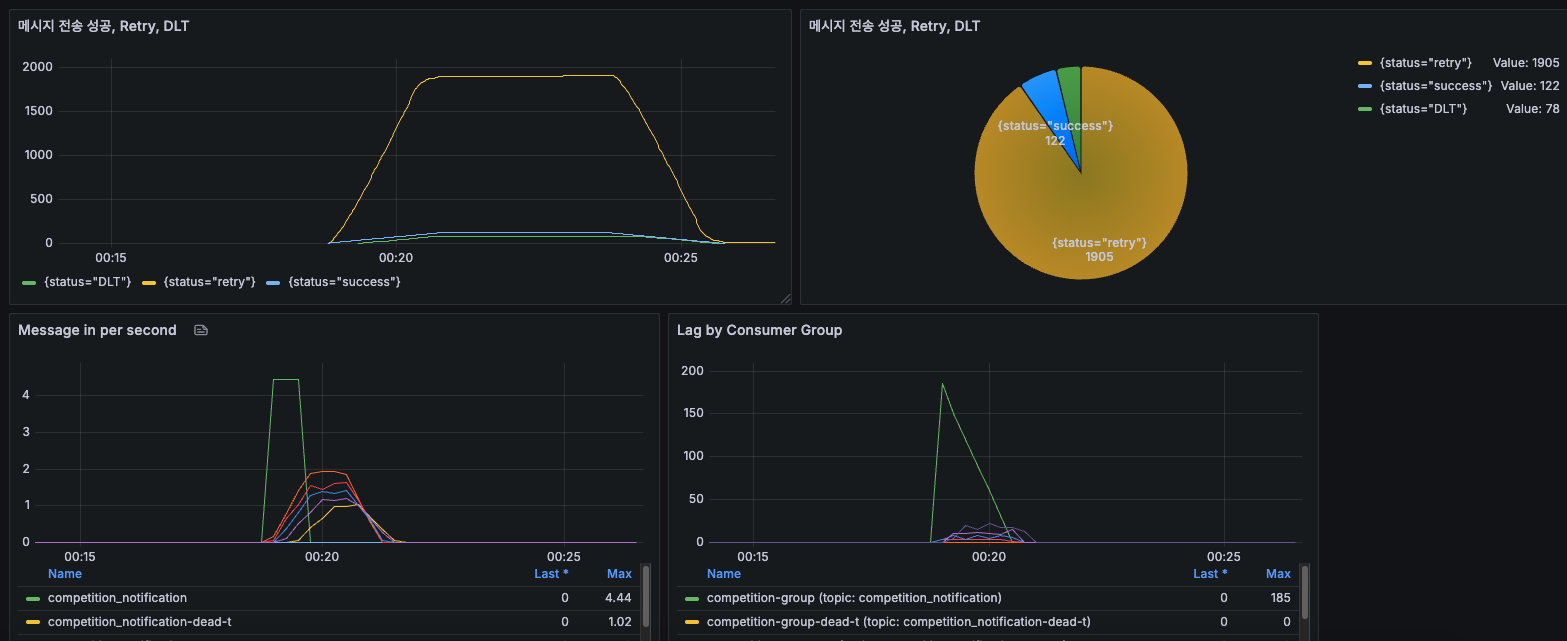
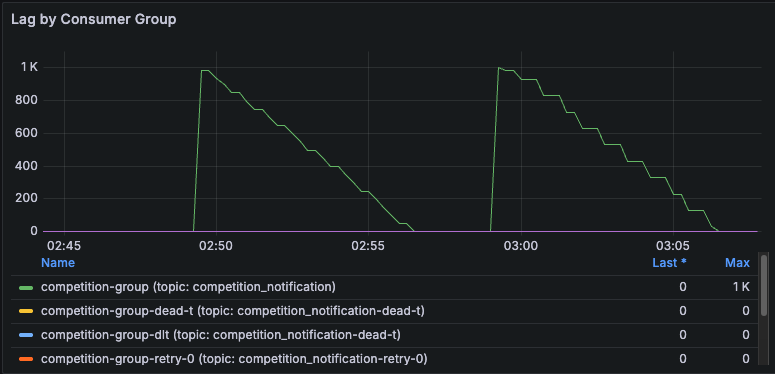
 1000개 요청 파티션 3개로 테스트 결과 Lag도 잘 감소하고 시간도 3분정도 걸렸다.
1000개 요청 파티션 3개로 테스트 결과 Lag도 잘 감소하고 시간도 3분정도 걸렸다.
배치 처리
@Bean
public ConsumerFactory<String, Object> consumerFactory() {
Map<String, Object> configProps = new HashMap<>();
configProps.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, kafkaBootstrapServers);
configProps.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
configProps.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, CustomDeserializer.class);
// 모든 패키지의 클래스 역직렬화 허용 (보안에 주의)
configProps.put(JsonDeserializer.TRUSTED_PACKAGES, "*");
// 타입 정보가 없는 경우 Map으로 변환
// configProps.put(JsonDeserializer.VALUE_DEFAULT_TYPE, "java.util.Map");
// 성능 최적화 설정
configProps.put(ConsumerConfig.FETCH_MIN_BYTES_CONFIG, 1024);// 최소 1KB 데이터를 가져올 때까지 대기
configProps.put(ConsumerConfig.FETCH_MAX_WAIT_MS_CONFIG, 500);// 최대 500ms 대기
configProps.put(ConsumerConfig.MAX_POLL_RECORDS_CONFIG, 50);// 한 번에 최대 500개 레코드 가져오기
// 리밸런싱 최적화
configProps.put(ConsumerConfig.SESSION_TIMEOUT_MS_CONFIG, 30000);// 세션 타임아웃 (30초)
configProps.put(ConsumerConfig.HEARTBEAT_INTERVAL_MS_CONFIG, 10000);// 하트비트 간격 (10초)
configProps.put(ConsumerConfig.MAX_POLL_INTERVAL_MS_CONFIG, 300000);// 최대 폴링 간격 (5분)
return new DefaultKafkaConsumerFactory<>(configProps);
}
/**
* 공통 kafka listener container factory
* @return
*/
@Bean
public ConcurrentKafkaListenerContainerFactory<String, Object> kafkaListenerContainerFactory() {
ConcurrentKafkaListenerContainerFactory<String, Object> factory =
new ConcurrentKafkaListenerContainerFactory<>();
factory.setConsumerFactory(consumerFactory());
// 배치 리스너 비활성화 (개별 메시지 처리)
factory.setBatchListener(true);
// DLT 설정
DeadLetterPublishingRecoverer recoverer = new DeadLetterPublishingRecoverer(
kafkaTemplate(), // DLT로 보낼 때 사용할 KafkaTemplate
(record, ex) -> {
log.error("메시지 처리 실패: {}", ex.getMessage());
log.error("실패한 메시지: {}", record);
// 실패한 메시지를 보낼 토픽을 지정. 기본은 "<원본토픽>.-dead-t"
String dltTopic = record.topic() + "-dead-t";
return new TopicPartition(dltTopic, record.partition());
}
);
// 에러 핸들러 수정 - 재시도 없이 로깅만 하도록 설정
DefaultErrorHandler errorHandler = new DefaultErrorHandler(recoverer, new FixedBackOff(1000L, 3L)); // 재시도 3회 반복
// SerializationException도 처리하도록 설정
errorHandler.addNotRetryableExceptions(org.apache.kafka.common.errors.SerializationException.class);
factory.setCommonErrorHandler(errorHandler);
return factory;
}BatchLinster를 활성화 하고 ConsumerConfig.MAX_POLL_RECORDS_CONFIG 를 통해 한번에 이벤트를 몇개 가져올지 설정한다.
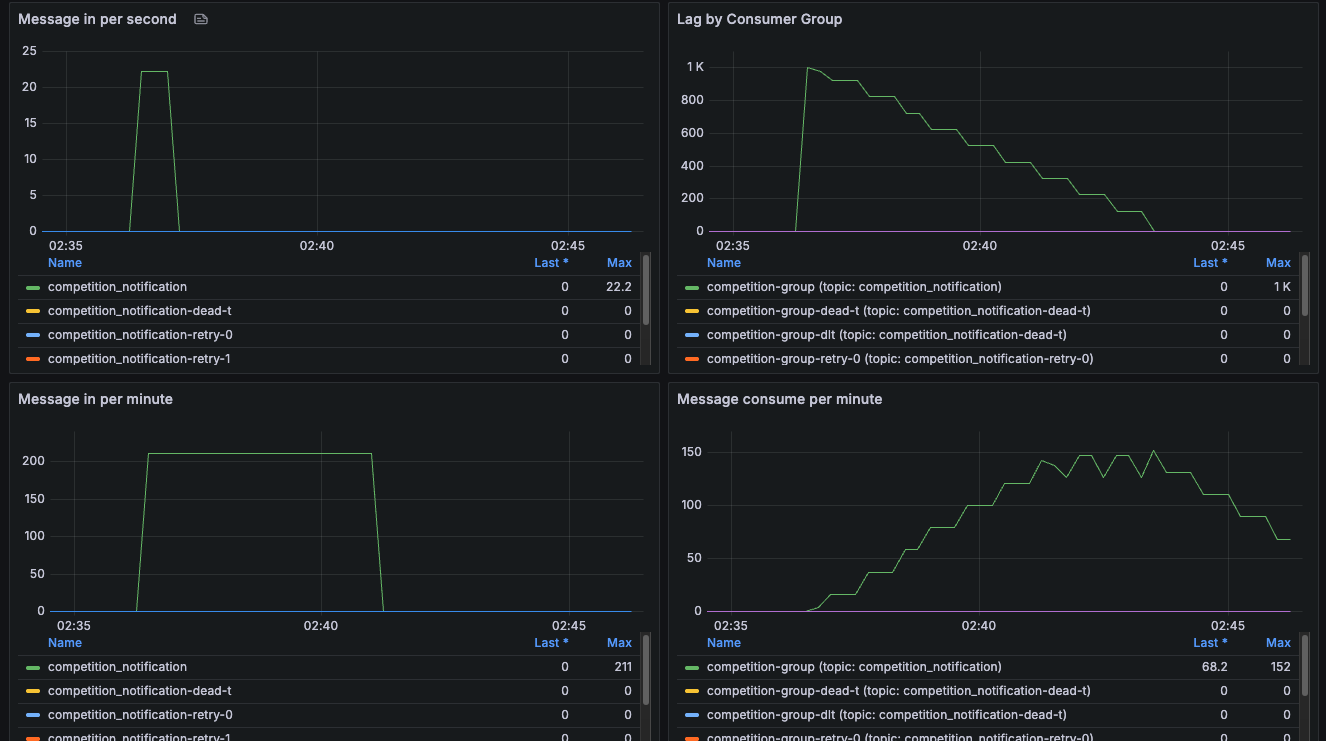
 왼쪽이 배치사이즈 50, 오른쪽이 100 Lag감소가 더 느렸다.
왼쪽이 배치사이즈 50, 오른쪽이 100 Lag감소가 더 느렸다.
배치 사이즈가 무조건 크다고 좋은게 아님
배치사이즈가 너무 크면 처리 지연이 발생
배치 사이즈 설정만큼 이벤트를 가져오고 순차적으로 Slack메세지 발송을 하고 있었다.
그래서 배치를 적용해도 적용안한것과 시간차이가 별로 없었다.
이를 해결하기 위해 순차적으로 하지 말고 병렬로 처리하는 방법을 찾아봤다.
테스트 정리
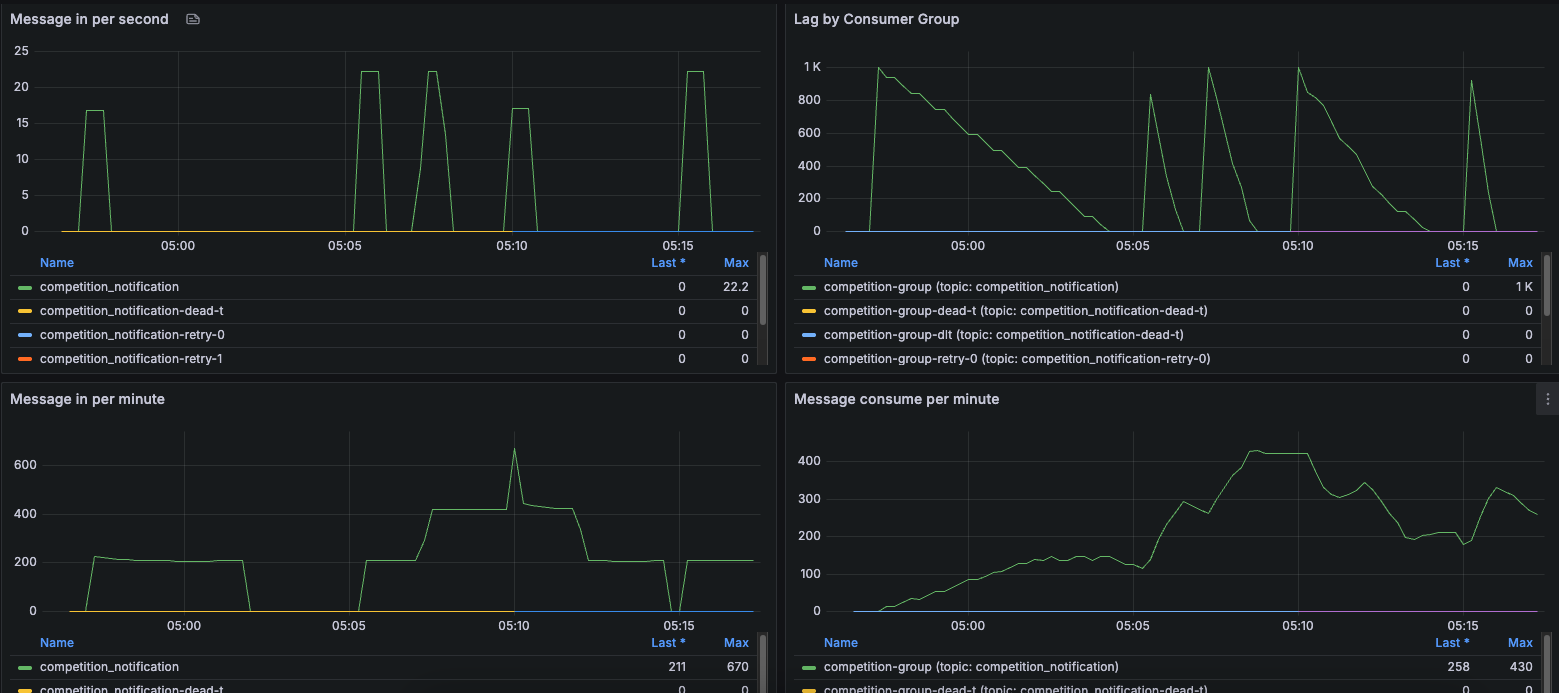 Consumer Lag지표의 1번 부터 순서대로 정리해봤다.
Consumer Lag지표의 1번 부터 순서대로 정리해봤다.
병렬로 처리하니 배치를 적용한것이 효과가 있었다.
1. 배치 순차처리 (7분)
배치로 받아서 순차적으로 처리한다. (아무 설정도 안한 것과 별 차이가 없었다.)
for (Map<String, Object> eventMap : eventMaps) {
context.sendMessage(eventMap, competitionStrategy, CompetitionEventDto.class);
}2. parallelStream()
배치로 받아서 parallelStream()으로 병렬 처리한다.(1분 15초)
eventMaps.parallelStream().forEach(eventMap -> {
context.sendMessage(eventMap, competitionStrategy, CompetitionEventDto.class);
});
3. CompletableFuture
배치로 받아서 CompletableFuture으로 병렬 처리한다.(1분 45초)
List<CompletableFuture<Void>> futures = eventMaps.stream()
.map(eventMap -> CompletableFuture.runAsync(() -> {
log.info(eventMap.toString());
context.sendMessage(eventMap, competitionStrategy, CompetitionEventDto.class);
}))
.collect(Collectors.toList());
CompletableFuture.allOf(futures.toArray(new CompletableFuture[0])).join();4. 배치처리X 파티션3 (4분)
5. 파티션3개+ 배치처리 parallelStream() (1분)
정리
parallelStream()을 사용할 때는 각 요소가 병렬로 처리되기 때문에 예외가 발생하더라도 흐름 제어가 어렵고, 예외가 한 쓰레드에서 발생하면 전체 스트림을 멈추거나, 다른 작업 결과에도 영향을 줄 수 있다고 하여
결론적으로 CompletableFuture를 사용했다.
