🖥 빵형의 개발도상국 : 영화 추천 인공지능 만들기 - Python
가장 먼저 필요한 것은 영화 데이터!
데이터 수집을 위해 kaggle 에서 'The Movies Dataset' 을 다운로드 받는다.
👉 kaggle
데이터 분석 및 머신러닝에 대한 플랫폼이다. 한 번쯤 들어봤을 '타이타닉 생존자 예측' 과 같은 문제가 올라오기도하고, 위에서와 같이 다양한 주제의 dataset 이 공유되기도한다.
pandas 를 이용하여 다운받은 csv 형태의 파일의 데이터를 읽어온다.
특정 필드만 읽어오거나 필드명을 다른 것으로 바꾸는 것, 그리고 조건에 따라 데이터를 필터링하는 것이 가능하다.
간단한 실습이니 영상에서 가이드하듯 영화 메타정보가 담긴 movies_metadata.csv 와 평점 ratings_small.csv 파일만으로도 충분하다.
🐼 pandas
데이터 분석을 위한 파이썬 라이브러리로 Numpy, Matplotlib 와 함께 데이터 분석을 위한 필수 패키지 삼대장이라 불린다. 행과 열로 이루어진 데이터 객체를 만들어 다룰 수 있게 해준다. (이번에는 삼대장 중 판다스와 넘파이만 사용한다)
문자를 숫자로 변환하거나 json 데이터 중 특정 필드만 추출하여 배열로 변환하는 등 데이터를 가공하는 단계를 거친 후, 메타데이터와 평점데이터를 합친다. 합치는 형태는 RDB 의 INNER JOIN 과 유사하다.
👉 데이터 전처리의 주요 기법
Data Cleaning 데이터 정제: (내가 진행한 것과 같이) 데이터의 잡음을 제거하는 작업
Data Integration 데이터 통합: 여러 데이터베이스, 데이터 파일을 통합하는 작업
Data Reduction 데이터 축소: 데이터 볼륨을 줄이거나 분석 대상을 줄이는 작업, 샘플링 등
Data Transformation 데이터 변환: 정규화, 집단화
Data Discretization 데이터 이산화: 축소의 일종이지만 아예 배재하는 것이 아닌 변환을 통한 구간화 (예: 25세를 20대로 변환)
피어슨 상관계수를 이용하여 추천 엔진의 핵심 알고리즘을 구현한다.
영상에서 피어슨 상관계수 공식의 기본 개념을 정-말 이해하기 쉽게 설명해주고 있는데, 요약하자면
- 영화 A와 영화 B 각각의 평균 평점을 계산한다.
- 유저 1이 영화 A에 준 평점에서 평균 평점을 뺀다. 유저 2, 3, 4...에 반복한다.
- 유저 1이 영화 B에 준 평점에서 평균 평점을 뺀다. 유저 2, 3, 4...에 반복한다.
- 뺀 결과값은 양수일 수도, 음수일 수도 있다.
- 영화 A와 영화 B의 상관관계를 파악하기 위해 유저 1의 영화 A 뺀 결과값과 영화 B 뺀 결과값을 곱한다.
- 유저 2, 3, 4...에 반복한다.
- 곱한 결과값은 양수일 수도 있고, 음수일 수도 있다.
- 곱한 결과값의 전체 합을 구한다.
- 합이 크다면 상관있을 확률이 높다, 반대로 작다면 상관있을 확률이 낮다고 볼 수 있다.
(피어슨 상관계수에 대한 내용은 조금 더 깊이 찾아본 후 다시 정리해봐야겠다.)
구현한 알고리즘 함수에 특정 영화를 입력하여 상관관계가 높은 영화들을 추천 받아보자!
여담으로,
얼마나 그럴싸한 결과가 나오는지 확인해보기 위해 The River Wild 라는 영화를 입력해보았다.
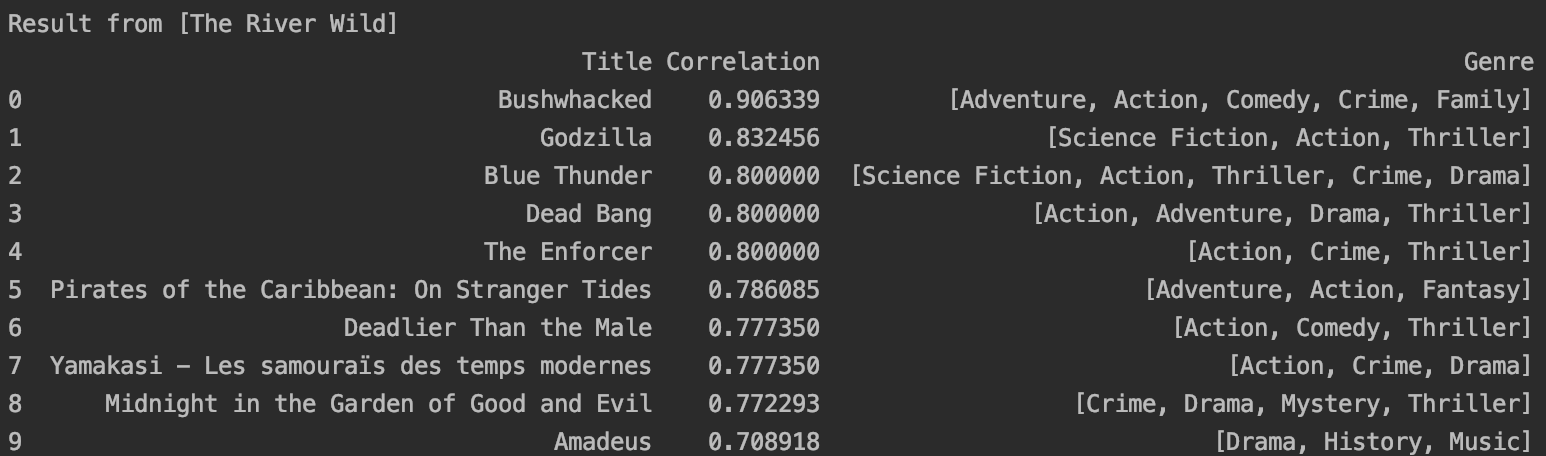
무려 0.9 로 나온 영화가 처음 보는 영화라 검색해보니
(왼쪽이 River Wild, 오른쪽이 Bushwhacked)

상당히 믿을만한 ㅋㅋㅋ 추천인 것 같다!
