큰 흐름
1. JVM은 OS로부터 메모리를 할당한다.
2. 자바 컴파일러가 자바 소스코드를 자바 바이트코드로 컴파일한다
--- 이 바이트코드 파일을 실행 하는 순간 JVM이 동작된다. ----
3. Class Loader를 통해 JVM Runtime Data Area로 로딩한다.
.class(바이트)파일을 묶어서 운영체제로부터 할당 받은 메모리(JVM Runtime Data Area)의 Method Area에 적재한다.
4. Runtime Data Area에 로딩 된 .class들은 Execution Engine을 통해 해석한다.
- 자바 바이트 코드를 JVM이 컴퓨터가 실행할 수 있는 형태로 변경함.
- 바이트 코드는 JVM이 이해할 수 있는 언어이고 이를 컴퓨터에서 실행시키기 위해서는 Native code로 변환해야 하기 때문.
- Execution Engine에는 JIT 컴파일러와 인터프리터가 있다.
- 인터프리터 - 바이트 코드를 한줄한줄 읽으면서 OS가 실행할 수 있도록 기계어로 번역, 실행속도가 느린 단점
- JIT 컴파일러 - 자주 반복되는 코드를 기계어로 변환해서 캐싱 함, 실행속도가 빨라지지만 nativecode로 변환하는데 비용이 발생
- 변환 비용 때문에 jvm은 모든 코드를 JIT Compiler방식으로 실행하지 않고 인터프리터 방식을 사용하다 자주 사용되는 코드만 캐싱 함.
- JIT 컴파일러와 인터프리터는 동시에 런타임 영역에서 다른스레드에서 실행됨
5. 해석된 바이트 코드는 Runtime Data Area의 각 영역에 배치되어 수행하며 이 과정에서 Execution Engine에 의해 GC의 작동과 스레드 동기화가 이루어진다.
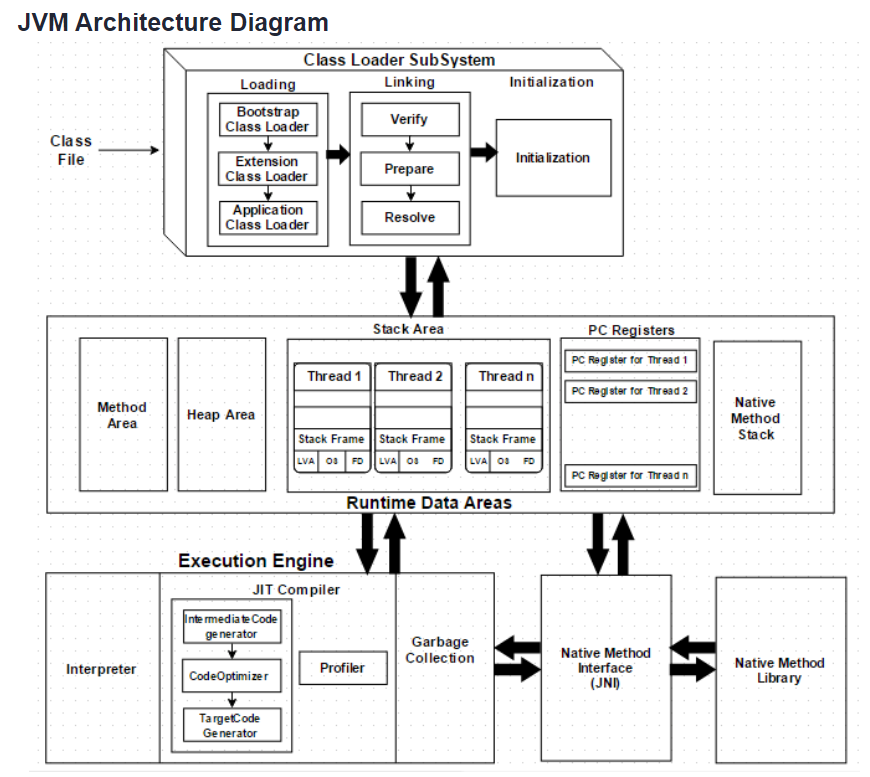
Class Loader
바이트코드를 런타임 데이터 영역에 배치시키는 역할을 한다. 시작 바이트코드에서 다른 클래스 파일의 메서드를 호출할 경우 해당 클래스 파일이 있는지 찾아 (JRE 라이브러리 또는 CLASSPATH 환경변수에 지정된 폴더 등) 해당 바이트코드가 올바른지 확인하고 메서드 영역에 배치한다.
이렇게 클래스 파일들이 로딩되면 JVM이 종료할 때까지 유지된다.
동적 클래스 로드 기능은 ClassLoader 서브시스템에서 담당
클래스 파일이 컴파일 타임이 아닌 런타임에 처음으로 클래스를 참조할 때 로드하고 링크하며 초기화
Loading
클래스를 로드하며, BootStrap ClassLoader > Extension ClassLoader > Application ClassLoader 순서로 우선권을 가지고 로드한다.
Linking
- Verify – 로드된 바이트코드들의 에러를 확인
- Prepare – static 변수들의 메모리를 할당하고, default value들로 저장.
- Resolve – 모든 symbolic memory references가 메서드 영역의 original reference로 대체됨.
참고 : Symbolic Reference
자바에서는 특정 객체를 참조할 때 Memory Address를 직접 참조하는게 아니라, 객체의 이름으로 참조합니다. 이렇게 객체의 이름으로 참조하는 것은 Symbolic Reference라고 합니다Symbolic Reference는 Constant Pool에 저장되며 객체에 접근할 필요가 있으면 Constant Pool에서 Symbolic Reference를 통해 해당 객체의 Memory Address를 찾아 동적으로 연결합니다.
Initialization
최종 단계로 모든 정적 변수는 원래 값으로 할당되고 정적 블록이 실행됨. static block은 실행됨.
Runtime Data Area
다섯가지의 주요 구성
- Method Area – 정적 변수를 포함한 모든 클래스 수준의 데이터가 저장, JVM당 하나의 Method Area만 존재하며, 이는 공유 자원
- Heap Area – 모든 개체와 해당 인스턴스 변수 및 배열이 여기에 저장됨. JVM 당 하나의 힙 영역. 메서드 영역과 힙 영역은 여러 스레드의 메모리를 공유하므로 저장된 데이터는 스레드에서 안전하지 않음.
- Stack Area – 모든 스레드에 대해 별도의 런타임 스택이 생성된다. 모든 메서드 호출에 대해 스택 메모리에 하나의 엔트리(entry)가 생성되며 이를 스택 프레임(Stack Frame)이라 한다. 스택 프레임은 세 개의 하위 엔티티로 나뉜다
- Local Variable Array – 얼마나 많은 로컬 변수가 관련되어 있는지와 관련된 값이 여기에 저장됨
- Operand stack – 수행하기 위해 중간 작업이 필요한 경우, 작업을 수행하기 위한 런타임 작업 공간의 역할
- Frame data – 메소드에 대응하는 모든 심볼들이 여기에 저장됨. 예외의 경우, 캐치 블록 정보 저장.
- PC Registers – 각 스레드에는 별도의 PC 레지스터가 있으며, 명령이 실행되면 현재 실행 명령의 주소를 유지. 다음 실행할 명령으로 업데이트됨
- Native Method stacks – Native Method 정보를 보유한다. 모든 스레드에 대해 별도의 Native Method stack이 생성됨.
Execution Engine
런타임 데이터 영역에 할당된 바이트 코드를 실행
실행 엔진은 바이트 코드를 읽어내고 이를 하나씩 실행
- Interpreter – 바이트코드를 한줄 씩 읽어가며 더 빠르게 해석하지만 실행은 천천히 한다. 인터프리터의 단점은 하나의 방식이 여러 번 호출될 때 매번 새로운 해석이 필요하다는 것
- JIT Compiler – 실행 엔진은 바이트 코드를 변환할 때 인터프리터의 도움을 받지만 반복되는 코드를 찾으면 JIT 컴파일러를 사용하여 전체 바이트 코드를 컴파일하여 네이티브 코드로 변경
반복되는 메서드 호출에 직접 사용되므로 시스템의 성능이 향상- Intermediate Code Generator – 중간 코드 생성
- Code Optimizer – 생성된 중간 코드를 최적화
- Target Code Generator – 기계 코드 또는 기본 코드 생성 담당
- Profiler – 메서드를 여러 번 호출하는지 여부(핫스팟)를 찾음.
- Garbage Collector: 참조되지 않는 개체를 수집하고 제거합니다. Garbage Collection은
System.gc()를 호출하여 트리거할 수 있지만 실행이 보장되지 않습니다. JVM의 Garbage Collection은 생성된 개체를 수집
- 변환 비용 때문에 JVM은 모든 코드를 JIT Compiler방식으로 실행하지 않고 인터프리터 방식을 사용하다 자주 사용되는 코드만 캐싱해서 사용.
- JIT 컴파일러와 인터프리터는 동시에 런타임 영역에서 다른스레드에서 실행됨
Java Native Interface (JNI): JNI는 네이티브 메소드 라이브러리들과 상호작용할 것. 실행 엔진에 필요한 네이티브 라이브러리들을 제공
Native Method Libraries: This is a collection of the Native Libraries, which is required for the Execution Engine.
https://honbabzone.com/java/java-jvm/
https://dzone.com/articles/jvm-architecture-explained
https://imbf.github.io/interview/2021/03/02/NAVER-Practical-Interview-Preparation-4.html
