
함수
함수(또는 프로시저나 서브루틴)은 엔지니어,개발자들이 똑같은 코드를 반복작성하는일을 피하고자 만든 코드를 재사용하는 주요 수단이다.
cube라는 이름의 함수
function cube(x) { return x; }
x는 cube함수의 파라미터 값이다.
함수의 멋진점은 cube를 여러번 작성하지 않아도 여러번 호출할수 있다는 점이다.
함수는 주소값을 가진다. 함수가 호출되었을때 값을 출력(또는 반환) 해줄 반환주소를 가지고 있어야 한다.
이러한 주소값들이 있기 때문에 컴퓨터적으로는 많은 작업이 필요한데, 이를 위해 ARM프로세서에서 '링크 레지스터를 사용해 분기'(Branch with Link) 명령어를 활용해 함수를 호출하는 명령어와 현재명령어의 다음위치를 저장해 하나로 합친다.
스택
함수가 다른함수를 호출할수도 있고 자기자신을 호출할 수도 있다.
자기자신을 호출하는 경우 '재귀'라고 한다.
아래는 '재귀적 분할'을 활용한 압축 예
function subdivide(x, y, size){
if( size 가 1이 아니고 AND 이 모두 같은색이 아님) {
half = size / 2
subdivide(x, y, half)
subdivide(x, y+half, half)
subdivide(x+half, y+half, half)
subdivide(x+half, y, half)
}else{
정보 저장
}
}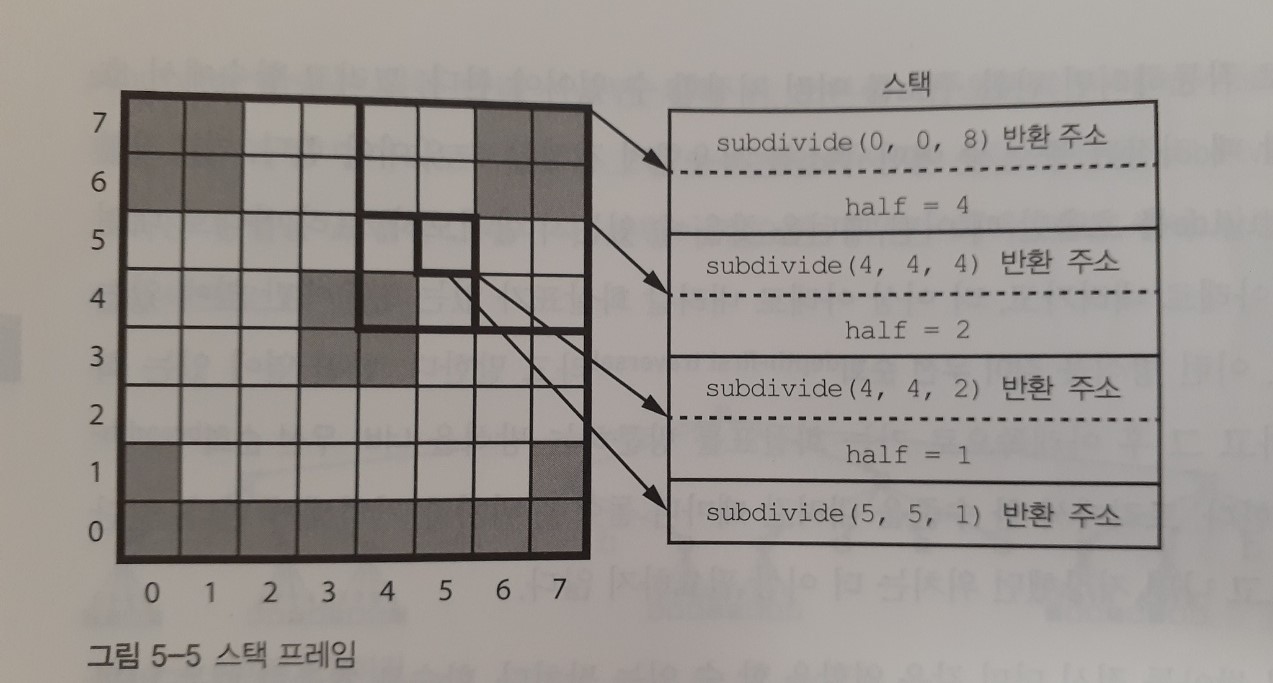
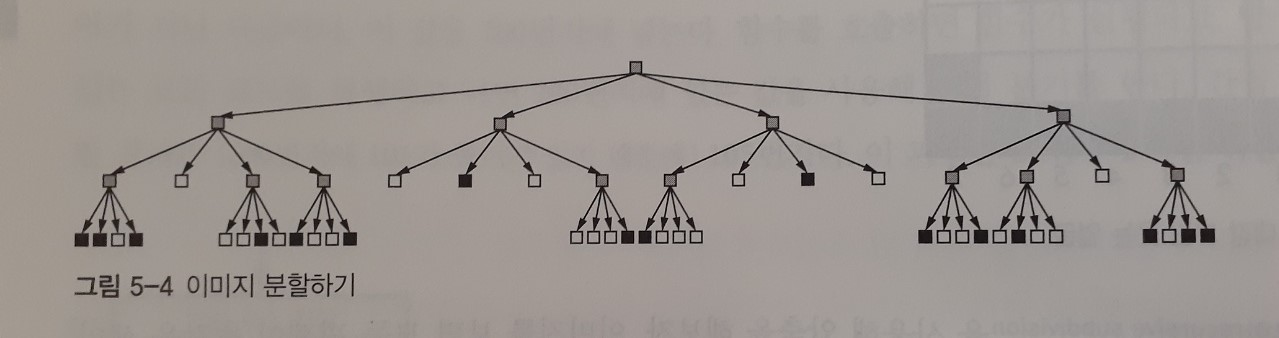
그림 5-4는 '트리'라고 불린다. 뿌리가 위에있는 뒤집어진 트리이다. 항상 각 노드에서 4개의 가지가 뻗어나가기 때문에 쿼드트리 이다.
위에서 함수에서처럼 subdivide함수를 구현하면 문제가 생긴다. 반환값을 저장할 위치가 한군데 이기때문에 재귀적함수는 이미 들어 있던 반환값을 덮어써서 되돌아갈 위치를 잃어버리기 때문에 자기 자신을 호출할 수 없다.
재귀함수가 제대로 작동하려면 반환주소를 여럿 저장할수 있어야 하고, 함수 호출시 저장된 주소중 어떤 주소를 사용할지 결정할 수 있어야 한다.
위의 이미지분할 에서는 '깊이우선순회' 방식이 사용되었다. 아래로 내려갈일이 없을 경우에만 위로 돌아와서 옆으로 가서 다시 아래로 내려가고 반복하는 방식이다.
옆을 먼저 방문하는것은 '너비우선순회' 방식이다.
트리에서 한 수준을 내려갈 때마다 돌아올 위치를 기억해야한다. 그리고 원래 위치로 돌아오고나면 저장했던 위치는 더 이상 필요하지 않다.
스택을 식당의 접시 쌓기에 비유할수 있다 (LIFO)
스택에 물건을 '푸시' 하고, 스택에서 물건을 '팝'해서 제거한다. 스택에 물건을 푸시하는데 공간이 없으면 '스택오버플로'라고 말한다. 빈 스택에서 물건을 가져오려하는것은 '스택언더플로' 라고 한다.
스택을 사용할때 오버플로와 언더플로를 검사해야하는데 검사를 아래와 같이 한다.(폴링)
인터럽트
어떤 작업을 하는데 중간중간 검사하는것을 '폴링'이라고 한다.
폴링은 중간중간 멈추고 검사하기에 비효율적이다. 이를 위해서 나온게 '인터럽트'이다.(하드웨어적 장치)
인터럽트는 적절한 신호가 들어오면 cpu실행을 잠시 중단시킬수 있는 핀이나 전기 열결을 포함한다.
작동방식은 주변장치에서 인터럽트요청을 생성한다.
프로세서는 현재 싱행중인 명령어를 끝까지 싱행하고, 후에 프로그램을 중단하고 인터럽트 핸들러를 실행한다. 그리고 핸들러를 마치고 다시 프로그램을 실행한다.
인터럽트를 만들때 고려할 점은 응답시간과 현재 상태이다.
다시말해 현재 작업을 마치고 인터럽트를 하는게 유리한지, 아니면 응답시간이 짧고 가벼워 인터럽트를 먼저 대응하고 하는게 좋은지를 고려하는 것이다.
