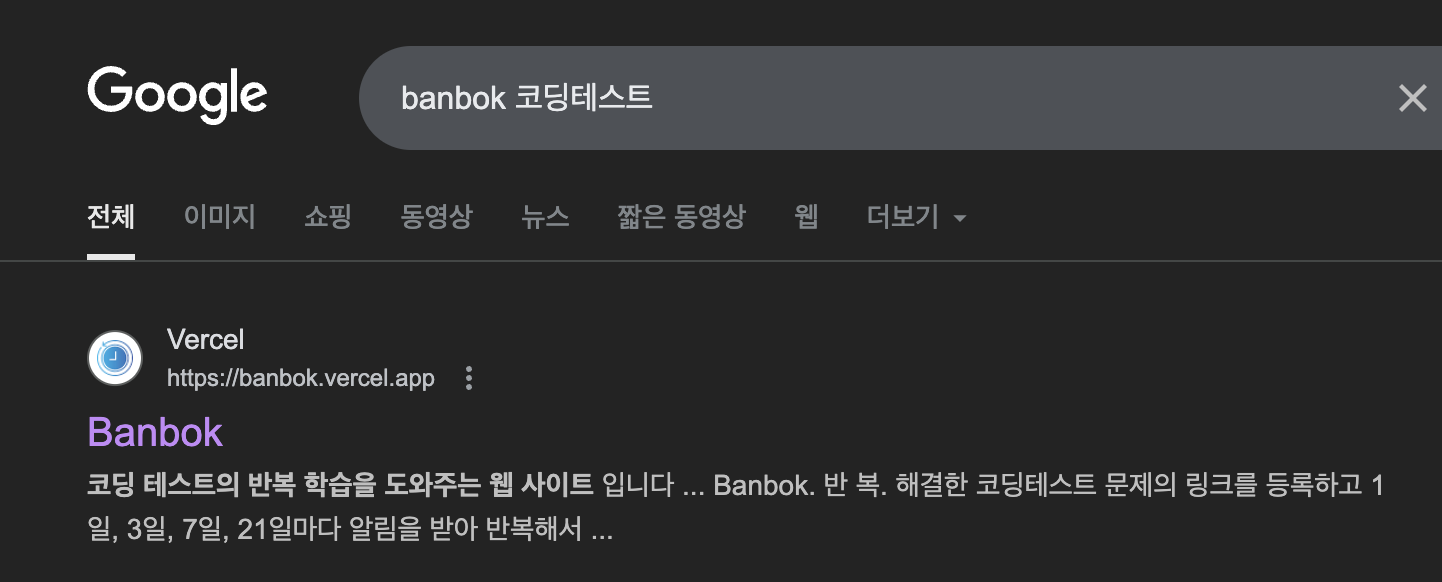
반복 프로젝트에는 Next를 적용해서 기술 역량을 확장해 나가는 중입니다.
하지만 제대로 Next를 활용하지 못했고 그 중 SEO가 제대로 적용이 안되고 있었습니다.
SEO 개선 경험은 React 프로젝트를 통해 진행해본 적은 있지만 Next는 이번이 처음이기 때문에 SSR만 적용하면 SEO가 바로 적용되는 줄 알았습니다.
이번에는 그렇기 때문에 SEO 적용 과정을 정리해볼려고 합니다.
1. 메타 태그 작성
export const metadata: Metadata = {
title: "Banbok",
description: "코딩 테스트의 반복 학습을 도와주는 웹 사이트 입니다.",
keywords: "코딩, 코테, 코딩테스트, 코딩테스트 학습",
openGraph: {
title: "Banbok",
description: "코딩 테스트의 반복 학습을 도와주는 웹 사이트 입니다.",
url: "https://banbok.vercel.app/",
images: [
{
url: "https://banbok.vercel.app/og-image.png",
width: 1200,
height: 630,
alt: "Banbok 대표 이미지",
},
],
siteName: "Banbok",
locale: "ko_KR",
type: "website",
},
};2. Robot.ts
검색 엔진 크롤러(로봇)에게 "크롤링을 허용하거나 제한"하는 규칙을 설정하는 역할을 합니다.
import type { MetadataRoute } from "next";
export default function robots(): MetadataRoute.Robots {
return {
rules: {
userAgent: "*",
allow: "/",
disallow: "/private/",
},
sitemap: "https://banbok.vercel.app/sitemap.xml",
};
}- Next.js App Router 방식으로 robot.txt 생성
- Next.js가 robots.ts를 HTML로 렌더링하지 않고, 정적 텍스트 파일(robots.txt)로 자동으로 변환합니다.
- 해당 파일의 위치는
/app/robot.ts에 위치해야합니다. - 만약 수동 설정으로
robot.txt를 작성한다면public폴더에 추가해주면 됩니다. - public/robots.txt
Allow: 크롤링을 허용할 경로
Disallow: 크롤링을 차단할 경로
3. 사이트 노출 시키기
Google Search Console를 통해 노출 시킬려고 합니다.
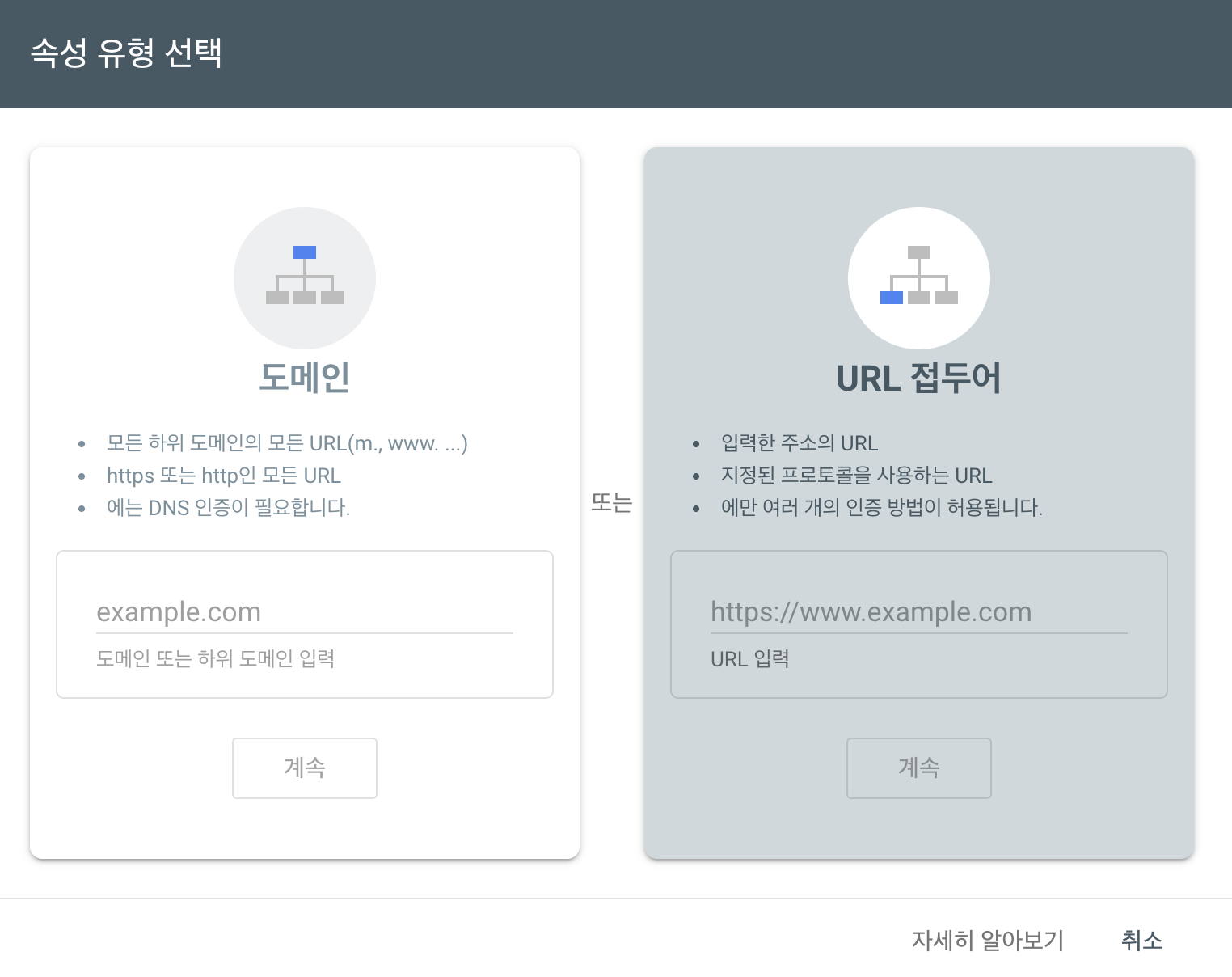
- URL 접두어 선택
소유권 확인
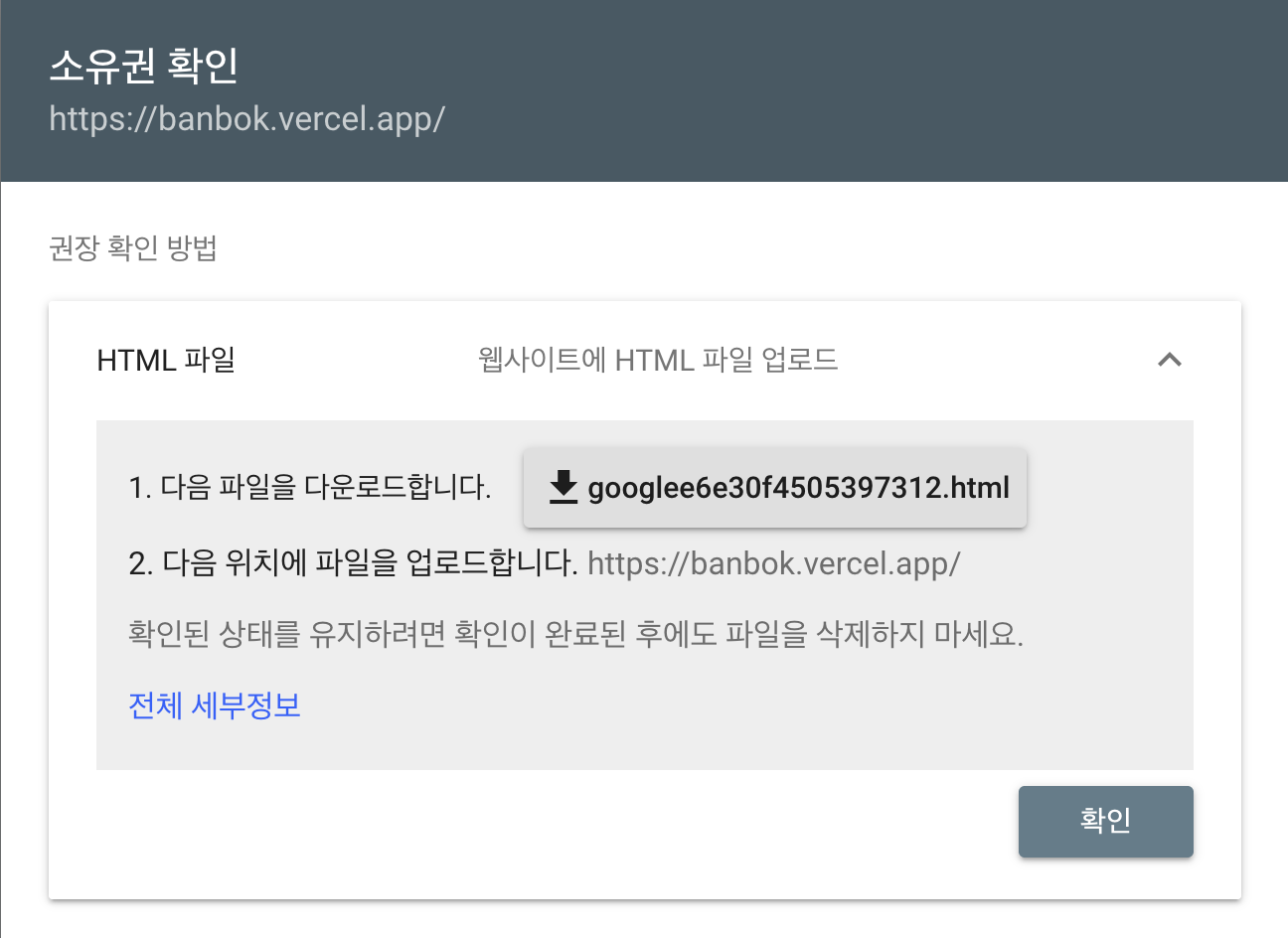
- html 파일은
public폴더에 넣고 배포를 해준 뒤https://banbok.vercel.app/파일명.html를 통해 정상적으로 파일이 보이는지 확인하면 됩니다.

4. 사이트 맵 제출
사이트 맵이란?
사이트맵(Sitemap)은 웹사이트의 구조를 검색 엔진에게 알려주는 XML 파일입니다.
- 어떤 페이지들이 있는지
- 각 페이지의 URL
- 마지막 수정 날짜
- 페이지의 중요도 (우선순위)
생성 방법
Next에서는 npm install next-sitemap를 통해 자동 생성이 가능합니다.
- 루트 폴더에
next-sitemap.config.js생성
module.exports = {
siteUrl: "https://banbok.vercel.app",
generateRobotsTxt: true, // 자동으로 robots.txt도 생성이지만 이미 robot.ts를 작성한 상태이기 때문에 추후에 사용
generateRobotsTxt: false,
exclude: ["/login", "/profile"], // 크롤링을 금지 시켰지만 사이트 맵에 url이 들어가기 때문에 추가해주기 때문에 이를 통해 사이트 맵에서 제외해줍니다.
};- robot.txt 자동 생성은 npm build를 진행하면 됩니다.
- package.json 내용 추가
"scripts": {
"postbuild": "next-sitemap"
}next build후 /public/sitemap.xml 생성됨
sitemap.xml: 메인 인덱스 사이트맵 (여러 sitemap들을 포함)
sitemap-0.xml: 실제 경로 정보를 담은 세부 사이트맵
사이트 맵 제출

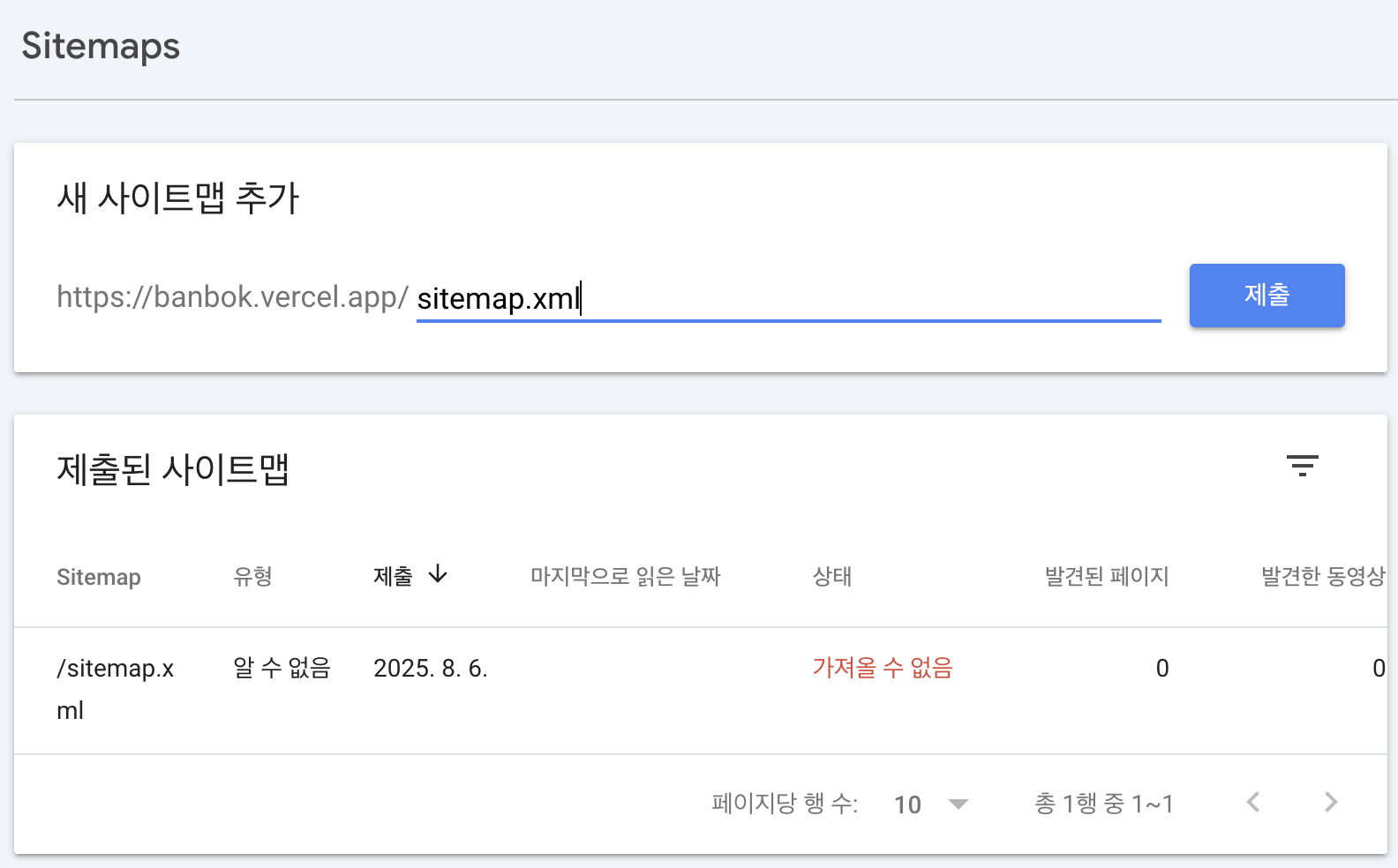
구글 서치 콘솔에서 사이트맵 메뉴로 들어가서 제출해주면 됩니다.
성공
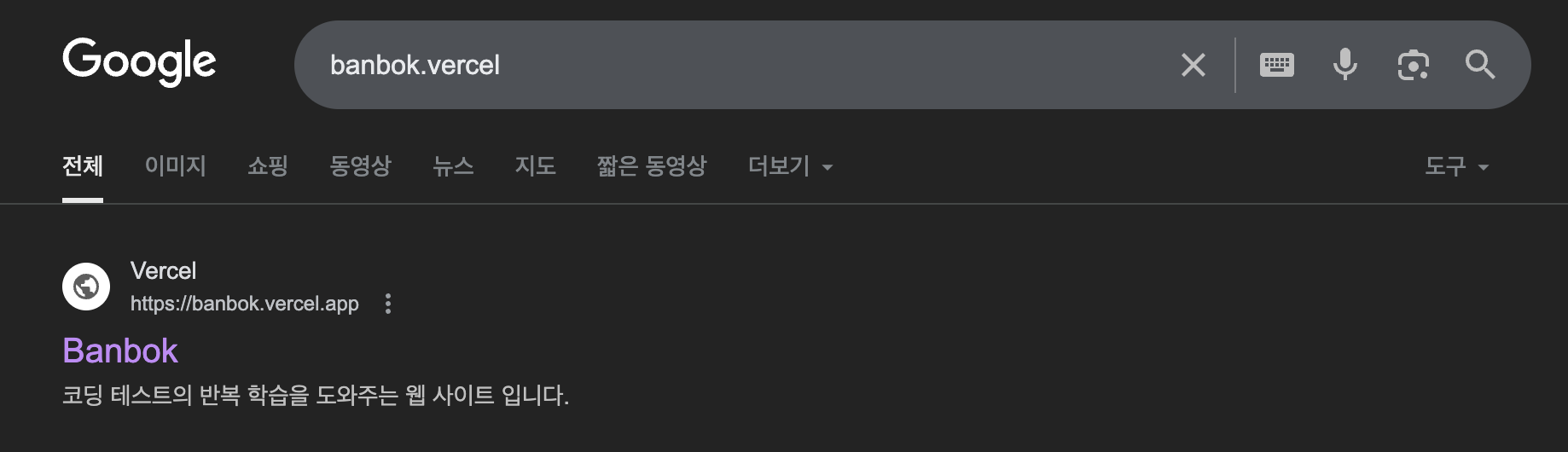
하루 뒤 검색되는 것을 확인할 수 있었습니다.
(작년 경험으로는 일주일 걸렸는데 이번에는 빠르게 해결한 것을 확인할 수 있었습니다.)
(좀 더 디테일한 검색 노출을 위해 개선해보겠습니다.)

차곡차곡 그만 쌓아올리고 취업해서 부딪쳐보고 싶은