공부순서는 내마음대로...
옵티마이저와 실행계획
옵티마이저: 다양한 실행방법들 중에서 최적의 실행방법을 결정하는 것이 옵티마이저의 역할
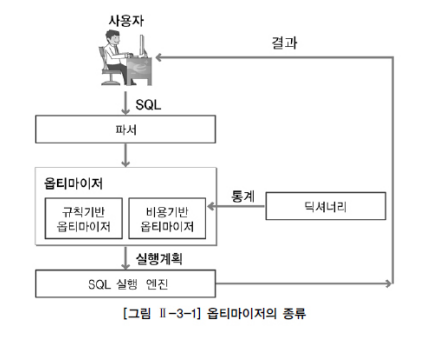
규칙기반 옵티마이저: 규칙(우선순위)를 가지고 실행계획을 생성한다
비용기반 옵티마이저: sql문을 처리하는데 필요한 비용이 가정 적은 실행계획을 선택하는 방식
옵티마이저 실행계획
-SQL 에서 요구한 사항을 처리하기위한 절차와 방법
실행계획을 구성하는 요소에는 조인순서, ㅈ인기법,액세스기법,최적화정보,연산
-동일한 SQL에 대해 결과를 낼 수 있는 다양한 처리 방법(실행계획)이 존재할 수 있지만 각 처리 방법마다 실행 시간(성능)은 서로 다를수 있다.
-옵티마이저는 다양한 처리 방법들 중에서 가장 효율적인 방법을 찾아준다
인덱스 기본
인덱스 특징과 종류
-원하는 데이터를 쉽게 찾을 수 있도록 돕는 책의 찾아보기와 유사한 기능
DML작업은 테이블과 인덱스를 함께 변경해야하기 때문에 느려질수 있음
트리기반 인덱스
-DBMS에서 가장 일반적인 인덱스는 B-트리인덱스
-리프블록은 인덱스를 구성하는 칼럼의 데이터와 해당데이터를 가지고 있는 행위
위치를 가리키는 레코드식별자 RID 구성되어있음
=로 검색하는 일치검색과 BETWEEN등의 범위 검색 모두 적합함
SQL Server의 클러스터형 인덱스
클러스터형인덱스, 비클러스터형인덱스
클러스터형인덱스의 2가지 중요성
:인덱스의 리프페이지가 곧 데이터페이지
:리프페이지의 모든 로우는 인덱스키칼럼순으로 물리적으로 정렬되어 저장됨
전체 테이블 스캔과 인덱스 스캔
1. 전체 테이블스캔
2. 인덱스 스캔
조인 수행원리
NL Join
NL Join은 프로그래밍에서 사용하는 중첩된 반복문과 유사한 방식으로 조인을 수행한다
반복문의 외부에 있는 테이블을 선행 테이블 또는 외부테이블이라고 하고 반복문의 내부에 있는 테이블을 후행테이블 또는 내부 테이블이라고 한다
선행테이블,외부테이블-> 후행테이블,내부테이블
결과 행의 수가 적은 테이블을 조인 순서상 선행 테이블로 선택하는 것이 전체 일량을 줄임
조인이 성공하면 바로 조인 결과를 사용자에게 보여줌으로 온라인 프로그램에 적당
Sort Merge Join
주로 스캔하는 방식으로 데이터를 읽음 , 조인 칼럼 인덱스 없어도 사용가능-> 단, 성능이 떨어질 수 있음
조인 칼럼을 기준으로 데이터를 정렬하여 조인을 수행한다
NL Join은 주로 댄덤 액세스 방식으로 데이터를 읽는 반면
sort merge join은 주로 스캔 방식으로 데이터를 읽는다
sort merge join은 랜덤 액세스로 nl join에서 부담이 되던
넓은 범위의 데이터를 처리할 때 이용되는 조인 기법
Hash Join
조인을 수행할 테이블의 조인 칼럼을 기준으로 해쉬 함수를 수행하여 서로 동일한 해쉬 값을 갖는 것들 사이에서 실제 값이 같은지를 비교하면서 조인을 수행한다.
Hash Join은 NL 조인의 랜덤 액세스 문제점과 sort merge join의 문제점인 정렬 작업의 부담을 해결 위한 대안으로 등장
'='로 수행하는 동등 조인에서만 사용할 수 있따
결과 행의 수가 적은 테이블을 선행테이블로 사용하는 것이 좋다.
