KcELECTRA Multi-Label Classification-(3) 데이터셋 구축
데이터셋 리서치
저희 상황은 유저들이 웹상에서 이루어지는 신조어, 줄임말, 지켜지지 않는 문법, 띄워쓰기 노상관 등 훈민정음의 위대함을 담고 있는 문장들을 분류해야하기 때문에 이러한 웹상 한국 문장 특성이 일부라도 반영이 되어 있는 데이터셋을 활용하는 편이 모델 성능 측면에서 이로울 것 같습니다. 또한 인상을 찌푸리는 문장을 분류하기 위함이 목적이니 데이터셋도 이에 맞추어 비속어, 욕설, 성적발언 등을 분류하기 위해 만들어진 데이터셋을 찾아보는 것이 좋을 것 같습니다.
데이터셋들을 좀 찾아본 결과 꽤 많은 연구단체, 연구자, 기업 등에서 대규모의 질 좋은 데이터들을 공유를 많이 해주셨습니다! 이렇게 저는 조금 더 꿀을 빨 수 있게 되었구요..:)
제가 찾아본 목록을 공유드리면, 아래와 같습니다.
- 욕설 감지 데이터셋
- Korean Hate Speech Detection 데이터셋
- Smilegate AI-Korean UnSmile 데이터셋
- HateScore 데이터셋
- Kakao-혐오표현 데이터셋(APEACH)
- 한국어 악성 댓글 데이터셋
- A Multi-label Hate Speech Detection 데이터셋(K-MHaS)
잠깐 찾은건데도 꽤 많은 오픈 데이터셋이 있었어요. 진짜...너무 고마우신 분들이죠.
다시 한번 마음 깊이 감사드립니다.🙏
태스크 선정
처음에 Multi-Class Classification vs Multi-Label Classification 중 어떤 Task로 가야할지 고민을 많이 했습니다. 데이터셋의 경우 Multi-Label Classification Task에 적합한 데이터셋이기도 했구요. 근데 가장 중요한 포인트는 해결하고자 하는 저희의 상황을 고려하는 것이 더 중요하다는 생각을 했어요.
저희 상황의 경우 사실은 제재를 가해야할 정도의 문장인지 아닌지를 알고 싶은 것이 중요한 상황입니다. 그리고 운영자분들이 해야할 일을 대신해서 '없애자'가 아닌 노고를 '줄이자'로 시작을 했기 때문에 정말 100% 완벽하게 문장들을 잘 분류하는 모델 만들어져도 세세한 검토를 하고 유저에게 제재를 가하는 등의 처리는 사람이 꼭 필요하기 때문에 휴먼 리소스 투입을 감안해야하는 상황이었습니다.
사실 문제를 조금 더 단순화 시킨다면, 문장에 제재 대상 여부를 결정하는 이진 분류로 접근해 볼 수 있지만, 이는 각 서비스별로 정책이 다를 수 있기 때문에 범용적이지 못할 것 같다는 생각이 들었어요. 가령 특정 커뮤니티의 경우 "씨발"이 포함된 단어를 어느 정도 수준에서는 허용하기도 하잖아요? 그래서 크게는 이게 클린한 문장인지 아닌지를 알려주되 문장의 성격이 어떤지 추가적인 정보 수준의 느낌으로 제공하자는 방향으로 가는 것이 좋겠다라고 생각했습니다.
상기와 같은 이유로 결과적으로는 Multi-Label Classification Task로 진행을 하는 방향이 좋을 것 같다고 판단했습니다.
데이터셋 선정
활용할 데이터셋을 선정하기 앞서 저는 아래와 같은 항목들을 고려해서 선정하려고 합니다.
- 한국어인지 ?
- 웹상에서 유저가 발화한 문장들이 수집된 것인지 ?
- Multi-Label Classification Task에 적합한지 ?
- 데이터의 양은 많은지 ?
- 조금 더 범용적으로 사용할 수 있는 라벨을 지녔는지 ?
상기 항목에 적합하다고 생각되는 데이터셋은 총 3개였어요!
- Smilegate AI-Korean UnSmile 데이터셋
- 개수: 18,742건
- 클래스: 여성/가족, 남성, 성소수자, 인종/국적, 연령, 지역, 종교, 기타혐오, 악플/욕설, clean(총 10개) - HateScore 데이터셋
- 개수: 11,108건
- 클래스: 여성/가족, 남성, 성소수자, 인종/국적, 연령, 지역, 종교, 기타혐오, 악플/욕설, clean(총 10개) - A Multi-label Hate Speech Detection 데이터셋(K-MHaS)
- 개수: 109,692건
- 클래스: 정치성향차별, 출신차별, 외모차별, 연령차별, 성차별, 인종차별, 혐오욕설, 종교차별, clean(총 9개)
세 데이터셋 모두 한국어이고, 웹상에서 수집한 데이터들입니다. 구체적으로는 UnSmile 데이터셋과 HateScore 데이터셋의 경우 동일한 특정 연구에서 각각 메인, 보조 데이터셋으로 활용되었기 때문에 동일한 라벨 구조를 가지고 있어요. 그래서 병합해서 데이터를 뿔리기 좋겠다고 생각이 들었습니다. 그리고 K-MHaS의 경우도 UnSmile/HateScore 데이터셋과 유사한 라벨 구조를 가지고 있어 UnSmile/HateScore 데이터셋과 합쳐서 사용하기 용이할 것 같다고 생각이 됬구요. 무엇보다 데이터가 10만건 수준이라서 데이터의 양도 마음에 들었어요.
나머지는 이진 분류에 대한 라벨링이기도 했고, 제가 직접 문장을 보면서 라벨링을 다시 해주어야하는데..그러면 어노테이션 가이드라인도 작성해야하고...인형 눈도 붙혀야하고...성능이 안좋다 싶고, 데이터의 문제라고 생각이들면 그때 하기로...
데이터셋 전처리
기본적으로는 UnSmile의 경우에는 여성가족, 남성 등으로 조금 더 구체적인 범주로 라벨링이 된 것 같은데, K-MHaS의 클래스 구성이 인상을 찌푸리게 만드는 문장에 대한 라벨 범주로 적당하다고 생각해요. 그리고 양 자체도 K-MHaS가 많다보니까 K-MHaS 데이터셋을 기준이 되는 메인 데이터셋으로 삼으려해요.
K-MHaS
각 라벨별 개수와 비중을 한번 살펴보겠습니다.
total_len = len(df)
for l in range(9):
labels_num = df.label.str.contains(str(l)).sum()
print(f'label {l}: {labels_num}개, {labels_num/total_len*100:.1f}% 차지')label 0: 10197개, 9.3% 차지
label 1: 8807개, 8.0% 차지
label 2: 11892개, 10.8% 차지
label 3: 16304개, 14.9% 차지
label 4: 7370개, 6.7% 차지
label 5: 8044개, 7.3% 차지
label 6: 323개, 0.3% 차지
label 7: 2375개, 2.2% 차지
label 8: 59615개, 54.3% 차지인종차별(6)에 해당하는 개수가 매우 적고, 제 생각에는 인종차별에 해당하는 부분은 조금 더 큰 범주에서 묶는다면 출신차별에 해당할 것 같습니다. 그리고 추후 UnSmile 데이터셋과 병합을 할껀데요. 라벨 일관성을 위해서 출신차별(0)로 치환해주겠습니다.
이제 인종차별(6) 라벨은 출신차별(0) 모두 흡수되었으므로 7, 8번 클래스를 각각 6, 7번으로 한칸씩 땡겨주도록 할게요.
K-MHas의 최종 라벨은 총 8개이며, 아래와 같게 됩니다.
label2kor = {0: '출신',
1: '외모',
2: '정치성향',
3: '혐오욕설',
4: '연령',
5: '성/가족',
6: '종교',
7: '해당사항없음'
}
label2en = {0: 'Origin',
1: 'Physical',
2: 'Politics',
3: 'Profanity',
4: 'Age',
5: 'Gender/Family',
6: 'Religion',
7: 'Not Hate Speech'
}이렇게 병합하고, 다중 라벨을 제거한 K-MHaS 데이터셋은 .csv 파일로 저장을 해두겠습니다.
UnSmile
UnSmile 데이터도 마찬가지로 Multi-Label Classification Task를 위한 라벨의 구성을 지니고 있습니다. 그리고 라벨 자체가 K-MHaS와 비슷한 구석이 많습니다. 그래서 데이터가 많은 K-MHaS의 데이터와 병합을 해서 사용해주려고해요. 저는 아래와 같이 변경해서 합쳐주도록 하겠습니다. 괄호 안 숫자는 K-MHaS 데이터셋의 클래스를 의미해요.
- 인종/국적+지역 -> 출신차별(0)
- 기타혐오+악플/욕설 -> 혐오욕설(3)
- 연령 -> 연령차별(4)
- 여성/가족+남성+성소수자 -> 성차별(5)
- 종교 -> 종교차별(7)
개인지칭 -> 개인정보보호법 관련 미사용clean -> 클래스 비중 밸런스 확인 후 필요시 삽입
UnSmile도 마찬가지로 2가지 이상의 라벨이 들어간 경우가 있습니다. 이를 제거하고, 1개씩만 가지는 라벨만 취하도록 하겠습니다.
HateScore
HateScore 데이터셋의 경우 문장의 출처 또한 라벨링이 되어 있습니다. 온라인 댓글, 위키피디아, 규칙 기반 생성 총 3개의 출처가 있는데, 저희의 상황과 가장 잘 맞는 출처는 웹상에 존재하는 온라인 댓글이기 때문에 저는 온라인 댓글의 출처 문장만을 취하도록 하겠습니다.

그리고 그 중에서 단순 악플 라벨의 경우엔 여러번 샘플링해서 확인해 봤을 때 정치성차별, 지역차별, 성차별 등으로 판단되는 문장들이 많이 섞여 있어서 다시 라벨링을 해주지 않는한은 모델에게 오히려 혼동을 줄 수 있을 것 같아서 제외하도록 하겠습니다.
정리하면, 아래와 같이 전처리해서 활용하도록 할 예정이에요.
- 온라인 댓글 출처 외 제외
- UnSmile 전처리와 동일한 규칙으로 K-MHaS 라벨로 치환
병합
전처리가 완료되었으니, 이제 모든 데이터들을 병합해주도록 하고 클래스별 비중을 한번 살펴보겠습니다. 각 라벨별 비중을 현실 세계와 비슷하게 최대한 맞춰주는게 좋으니까요!
기존에 K-MHaS 데이터셋의 5번 클래스는 성차별이지만, 이제 가족에 관련된 내용도 포함되었으니 성/가족차별 정도로 라벨명을 변경하도록 하겠습니다.
최종적으로 병합된 데이터셋의 클래스는 아래와 같게되네요.
- 출신차별, Origin(0)
- 외모차별, Physical(1)
- 정치성향차별, Politics(2)
- 혐오욕설, Profanity(3)
- 연령차별, Age(4)
- 성/가족차별, Gender/Family(5)
- 종교차별, Religion(6)
- 해당사항없음, Not Hate Speech(7)
각 클래스의 비중을 한번 살펴보겠습니다.
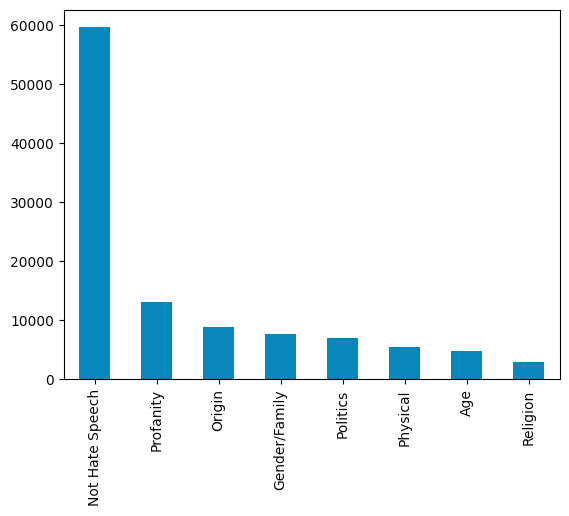

음..일단 인상을 찌푸리지 않는 깨끗한 문장들이 차지하는 비율이 많고, 인상을 찌푸리는 문장들 중에서는 혐오욕설이 가장 많네요. 게시하는 게시글, 댓글에 대한 규율이 있는 커뮤니티의 경우 현실에서도 인상을 찌푸리는 문장보다는 인상을 찌푸리지 않는 문장의 비중이 더 클 것 같다는 킹리적갓심이 들기는 합니다.
Train, Test, Val 데이터셋 구성
병합된 전체 데이터셋에서 학습시에는 복수 개의 라벨이 입력으로 들어가야 추후 모델이 하나의 문장에 포함된 여러 성격을 예측할 수 있겠죠? 그래서 저는 과감히 학습 데이터셋에 복수 개 라벨의 데이터를 모두 밀어 넣고, 나머지 하나의 문장에 단일 성격만 지닌 데이터만을 나눠서 검증(Val), 테스트(Test) 데이터셋으로 사용하겠습니다. 왜냐면, 복수 개 라벨의 데이터가 그리 많지 않습니다.
multi_label_num = df.label.str.contains(',').sum()
ratio = multi_label_num / len(df) * 100
print(f'복수 라벨 개수: {multi_label_num}/{len(df)}({ratio:.1f}%)')복수 라벨 개수: 14706/129214(11.4%)그래서 이러한 선택을 했습니다. 사실 이러면 안되는데...토이 프로젝트니까..
그리고 Test, Val은 복수 개의 라벨를 지닌 행을 전부 Train 데이터셋으로 밀어 넣고, 나머지 단일 성격을 지닌 데이터에서 Stratify를 적용 후 10%를 떼어서 Val 데이터셋으로, 그 나머지에서 다시 10%를 떼어서 Test 데이터셋을 구성했습니다. 그리고 최종 남은건 전부 Train 데이터셋으로 병합했습니다.
최종적으로 구성된 Train, Test, Val 데이터셋의 개수는 아래와 같습니다.
print(f'Train dataset 개수: {len(train_dataset)}개')
print(f'Test dataset 개수: {len(test_dataset)}개')
print(f'Val dataset 개수: {len(val_dataset)}개')Train dataset 개수: 106734개
Test dataset 개수: 10248개
Val dataset 개수: 11387개이제 Train, Test, Val 데이터셋 구성까지 완료되었으니 잘 저장해서 모델링으로 넘어가보도록 하겠습니다.
끝.


우아..대단해요╚(•⌂•)╝