https://docs.oracle.com/en/java/javase/11/docs/api/java.base/java/util/package-summary.html
Java Collections Framework
자바의 컬렉션 프레임워크는 데이터를 저장, 관리, 조작하기 위한 다양한 자료 구조와 알고리즘을 제공합니다. 이를 사용하면 데이터를 효율적으로 조작할 수 있으며, 반복문과 같은 일반적인 작업을 단순화할 수 있습니다.
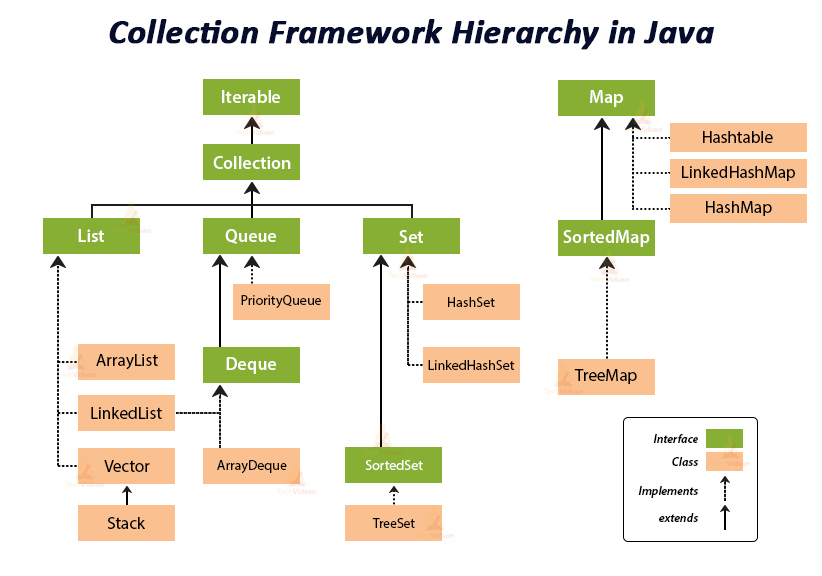
Java Collection Framework의 View
자바 컬렉션 프레임워크에서 view는 컬렉션을 특정한 방식으로 보여주는 개념을 의미합니다. View는 기존 컬렉션을 읽기 전용 또는 필터링된 형태로 제공하여 컬렉션을 제한하거나 변형할 수 있는 방법을 제공합니다. 기본 컬렉션과는 별개의 객체로써, 원본 컬렉션에 대한 변경이 해당 view에 반영됩니다.
컬렉션 프레임워크에서 제공하는 몇 가지 주요한 view 개념은 다음과 같습니다:
1. subList() : List 인터페이스의 메소드로, 원본 리스트의 일부분을 나타내는 새로운 List view를 반환합니다. 이 view는 원본 리스트와 연결되어 변경 사항이 상호 반영됩니다.
2. keySet(), values(), entrySet() : Map 인터페이스의 메소드로, 각각 키(key), 값(value), 키-값(entry) 쌍들을 나타내는 view를 반환합니다. 이러한 view는 Map의 원본 데이터를 참조하여 동작하므로, 원본 Map의 변경 사항이 반영됩니다.
3. Collections.unmodifiableXXX() : Collections 클래스에서 제공하는 메소드로, 읽기 전용 view를 생성합니다. unmodifiableXXX() 메소드를 사용하여 기존 컬렉션을 래핑하면 해당 컬렉션은 변경할 수 없는 읽기 전용 컬렉션으로 사용될 수 있습니다.
View는 기존 컬렉션의 일부분 또는 변형된 형태를 표현하기 때문에 메모리 사용량이 추가로 필요하지 않습니다. 이는 효율적인 데이터 처리를 가능하게 합니다. 또한, View는 원본 컬렉션의 변경 사항을 실시간으로 반영하므로, 데이터 일관성을 유지하고 중복 작업을 피할 수 있습니다.
View를 활용하여 원본 컬렉션을 제한하거나 변형하여 원하는 형태로 데이터를 조작할 수 있습니다. 이를 통해 컬렉션 프레임워크의 다양한 기능을 유연하게 활용할 수 있습니다.
뷰 컬렉션(View Collections)은 다양한 용도로 사용될 수 있습니다.
몇 가지 일반적인 사용 사례는 다음과 같습니다:
1. 읽기 전용 뷰 : Collections.unmodifiableXXX() 메소드를 사용하여 원본 컬렉션을 읽기 전용으로 래핑하는 뷰 컬렉션을 생성할 수 있습니다. 이를 통해 원본 컬렉션을 보호하고, 읽기 작업에 대한 안전성을 확보할 수 있습니다.
2. 동기화된 뷰 : Collections.synchronizedXXX() 메소드를 사용하여 원본 컬렉션을 동기화된 뷰 컬렉션으로 래핑할 수 있습니다. 이를 통해 멀티스레드 환경에서의 안전성을 보장하고, 동시 접근에 대한 동기화를 처리할 수 있습니다.
3. 부분 뷰 : List.subList(), NavigableSet.subSet(), Map.entrySet() 등의 메소드를 사용하여 원본 컬렉션의 일부분을 나타내는 뷰 컬렉션을 생성할 수 있습니다. 이를 활용하여 원본 컬렉션의 특정 범위 또는 부분에 집중하여 작업을 수행할 수 있습니다.
4. 필터링 뷰 : 람다식이나 특정 조건을 만족하는 요소들로 이루어진 뷰 컬렉션을 생성할 수 있습니다. 이를 활용하여 원본 컬렉션의 특정 요건에 맞는 요소들을 필터링하여 작업할 수 있습니다.
뷰 컬렉션은 원본 컬렉션을 보다 제한적인 형태로 표현하거나, 기능을 확장시킬 수 있는 방법을 제공합니다.
이를 통해 코드의 가독성, 유연성, 재사용성을 높일 수 있습니다. 또한, 메모리 사용량을 줄이고 작업을 효율적으로 수행할 수 있는 장점도 가지고 있습니다.
public static void testViewCollection() {
List<String> originalList = new ArrayList<>();
originalList.add("Apple");
originalList.add("Banana");
originalList.add("Cherry");
// Create an unmodifiable view collection
List<String> unmodifiableView = Collections.unmodifiableList(originalList);
// Trying to modify the view collection will throw an UnsupportedOperationException
// unmodifiableView.add("Durian"); // This will throw an exception
// Changes made to the original list are reflected in the view collection
originalList.add("Elderberry");
originalList.remove("Apple");
// Iterating over the view collection
for (String fruit : unmodifiableView) {
System.out.println(fruit);
}
}Java Collection Framework의 Bulk
Bulk 개념은 자바 컬렉션 프레임워크에서 대량의 요소를 한 번에 처리하는 개념을 말합니다. Bulk 연산은 컬렉션에 대해 한 번에 여러 개의 요소를 추가, 제거 또는 조작하는 작업을 수행할 수 있는 방법을 제공합니다. 이를 통해 코드의 가독성과 성능을 개선할 수 있습니다.
컬렉션 프레임워크에서 제공하는 주요 Bulk 연산은 다음과 같습니다:
1 . addAll(Collection<? extends E> c) : 주어진 컬렉션 c의 모든 요소를 현재 컬렉션에 추가합니다.
2 . removeAll(Collection<?> c) : 주어진 컬렉션 c와 현재 컬렉션의 공통 요소를 모두 제거합니다.
3 . retainAll(Collection<?> c) : 현재 컬렉션과 주어진 컬렉션 c의 교집합인 요소만을 남기고 나머지 요소를 제거합니다.
Bulk 연산은 반복문을 사용하여 하나씩 요소를 처리하는 것보다 더 효율적입니다. 내부적으로 최적화되어 있으며, 컬렉션의 크기와 상관없이 고속으로 작업을 수행할 수 있습니다. Bulk 연산을 사용하면 코드의 가독성이 향상되고, 중복 작업을 피할 수 있어 프로그램의 효율성을 높일 수 있습니다.
Bulk 연산은 주로 Collection 인터페이스의 구현체들에서 제공됩니다. 다양한 컬렉션 클래스들은 Bulk 연산을 지원하므로, 프로그램의 요구사항에 맞게 선택하여 활용할 수 있습니다. Bulk 연산을 사용하여 컬렉션을 효율적으로 처리하고 관리하는 것은 컬렉션 프레임워크의 장점 중 하나입니다.
Iterable
자바의 Iterable 인터페이스는 컬렉션 객체가 반복 가능한(iterable) 객체임을 나타내는 인터페이스입니다. 이 인터페이스를 구현하는 클래스는 Iterator 객체를 반환할 수 있어야 합니다. Iterator 객체는 컬렉션 내의 요소를 하나씩 반복적으로 접근할 수 있는 메서드를 제공합니다.
Iterable 인터페이스를 설계한 이유는 다음과 같습니다
1. 향상된 for 루프 지원 : Iterable 인터페이스를 구현하는 클래스는 향상된 for 루프(for-each loop)를 사용하여 컬렉션의 요소에 접근할 수 있습니다. 이를 통해 반복 작업을 더 간단하고 직관적으로 처리할 수 있습니다.
2. 일관성 있는 반복 인터페이스 제공 : Iterable 인터페이스는 컬렉션 프레임워크의 핵심 인터페이스 중 하나입니다. 이를 구현함으로써 다양한 컬렉션 클래스들이 일관성 있는 반복 작업 인터페이스를 제공할 수 있습니다. 이는 다양한 컬렉션 객체에 대해 통일된 방식으로 반복 작업을 수행할 수 있게 해주며, 코드의 가독성과 유지 보수성을 향상시킵니다.
3. 다형성과 호환성 확보 : Iterable 인터페이스를 구현하는 클래스는 다형성을 활용할 수 있습니다. 즉, 컬렉션을 다루는 다양한 메서드나 알고리즘에서 Iterable 인터페이스를 Argument로 전달 받아서 동작할 수 있습니다. 이를 통해 호환성이 확보되며, 유연하고 재사용 가능한 코드를 작성할 수 있습니다.
4. 내부 반복을 위한 Iterator 패턴 : Iterable 인터페이스는 Iterator 패턴을 지원하기 위해 설계되었습니다. Iterator 객체를 반환하는 iterator() 메서드를 제공하여 컬렉션의 요소에 접근하는 데 사용됩니다. Iterator 패턴은 컬렉션의 내부 구현과 반복 작업을 분리시키고, 컬렉션의 내부 구조를 노출시키지 않고도 안전하게 반복 작업을 수행할 수 있게 해줍니다.
따라서, Iterable 인터페이스는 자바 컬렉션 프레임워크의 일관성과 유연성을 높이고, 반복 작업을 보다 쉽고 효율적으로 처리하기 위해 설계되었습니다.
Iterator 패턴은 객체의 컬렉션에서 순차적으로 요소에 접근하는 데 사용되는 디자인 패턴입니다. 이 패턴은 컬렉션의 내부 구조와 구체적인 요소에 대한 정보를 노출시키지 않고 반복 작업을 수행할 수 있도록 합니다.
Iterator 패턴은 다음과 같은 구성 요소로 이루어져 있습니다
-
Iterator (반복자): 컬렉션의 요소를 순차적으로 접근하기 위한 인터페이스입니다. 주요 메서드로는 다음 요소의 존재 여부를 확인하는 hasNext() 메서드와 현재 요소를 반환하고 다음 요소로 이동하는 next() 메서드가 있습니다.
-
ConcreteIterator (구체적인 반복자): Iterator 인터페이스를 구현한 실제 반복자입니다. 컬렉션 내부의 요소에 접근하고 반복 작업을 수행하는 역할을 합니다.
-
Aggregate (집합체): 객체의 컬렉션을 나타내는 인터페이스입니다. 이 인터페이스를 구현한 클래스는 Iterator 객체를 생성하는 메서드인 iterator()를 제공해야 합니다.
-
ConcreteAggregate (구체적인 집합체): Aggregate 인터페이스를 구현한 실제 컬렉션 클래스입니다. Iterator 객체를 생성하는 iterator() 메서드를 구현하여 구체적인 반복자를 반환합니다.
Iterator 패턴을 사용하면 다음과 같은 이점이 있습니다
-
컬렉션의 내부 구조를 알 필요 없이 컬렉션의 모든 요소에 접근할 수 있습니다.
-
컬렉션의 구현과 반복 작업이 분리되어 컬렉션의 내부 구조가 변경되어도 반복 작업에 영향을 주지 않습니다.
-
다양한 종류의 컬렉션에 대해 일관된 반복 인터페이스를 제공하여 코드의 가독성과 재사용성을 향상시킵니다.
Iterator 패턴은 자바의 Iterable 인터페이스와 Iterator 인터페이스를 구현하여 사용됩니다.
Iterable 인터페이스는 iterator() 메서드를 제공하여 Iterator 객체를 반환하고, Iterator 객체는 컬렉션의 요소에 접근하는 데 사용됩니다.
Iterable 인터페이스는 다음과 같이 정의됩니다.
/*
* Copyright (c) 2003, 2013, Oracle and/or its affiliates. All rights reserved.
* DO NOT ALTER OR REMOVE COPYRIGHT NOTICES OR THIS FILE HEADER.
*
* This code is free software; you can redistribute it and/or modify it
* under the terms of the GNU General Public License version 2 only, as
* published by the Free Software Foundation. Oracle designates this
* particular file as subject to the "Classpath" exception as provided
* by Oracle in the LICENSE file that accompanied this code.
*
* This code is distributed in the hope that it will be useful, but WITHOUT
* ANY WARRANTY; without even the implied warranty of MERCHANTABILITY or
* FITNESS FOR A PARTICULAR PURPOSE. See the GNU General Public License
* version 2 for more details (a copy is included in the LICENSE file that
* accompanied this code).
*
* You should have received a copy of the GNU General Public License version
* 2 along with this work; if not, write to the Free Software Foundation,
* Inc., 51 Franklin St, Fifth Floor, Boston, MA 02110-1301 USA.
*
* Please contact Oracle, 500 Oracle Parkway, Redwood Shores, CA 94065 USA
* or visit www.oracle.com if you need additional information or have any
* questions.
*/package java.lang;
import java.util.Iterator;
import java.util.Objects;
import java.util.Spliterator;
import java.util.Spliterators;
import java.util.function.Consumer;
/**
* Implementing this interface allows an object to be the target of the enhanced
* {@code for} statement (sometimes called the "for-each loop" statement).
*
* @param <T> the type of elements returned by the iterator
*
* @since 1.5
* @jls 14.14.2 The enhanced {@code for} statement
*/
public interface Iterable<T> {
/**
* Returns an iterator over elements of type {@code T}.
*
* @return an Iterator.
*/
Iterator<T> iterator();
/**
* Performs the given action for each element of the {@code Iterable}
* until all elements have been processed or the action throws an
* exception. Actions are performed in the order of iteration, if that
* order is specified. Exceptions thrown by the action are relayed to the
* caller.
* <p>
* The behavior of this method is unspecified if the action performs
* side-effects that modify the underlying source of elements, unless an
* overriding class has specified a concurrent modification policy.
*
* @implSpec
* <p>The default implementation behaves as if:
* <pre>{@code
* for (T t : this)
* action.accept(t);
* }</pre>
*
* @param action The action to be performed for each element
* @throws NullPointerException if the specified action is null
* @since 1.8
*/
default void forEach(Consumer<? super T> action) {
Objects.requireNonNull(action);
for (T t : this) {
action.accept(t);
}
}
/**
* Creates a {@link Spliterator} over the elements described by this
* {@code Iterable}.
*
* @implSpec
* The default implementation creates an
* <em><a href="../util/Spliterator.html#binding">early-binding</a></em>
* spliterator from the iterable's {@code Iterator}. The spliterator
* inherits the <em>fail-fast</em> properties of the iterable's iterator.
*
* @implNote
* The default implementation should usually be overridden. The
* spliterator returned by the default implementation has poor splitting
* capabilities, is unsized, and does not report any spliterator
* characteristics. Implementing classes can nearly always provide a
* better implementation.
*
* @return a {@code Spliterator} over the elements described by this
* {@code Iterable}.
* @since 1.8
*/
default Spliterator<T> spliterator() {
return Spliterators.spliteratorUnknownSize(iterator(), 0);
}
}위의 코드에서 T는 컬렉션에 저장된 Element의 타입을 나타냅니다.
Spliterator 인터페이스Spliterator(분할자)는 자바 8부터 추가된 인터페이스로, 병렬 처리를 위한 컬렉션의 분할과 반복 작업을 지원합니다.
Spliterator는 "split"과 "iterator"를 합친 용어로, 컬렉션을 분할하고 각 부분에서 요소를 반복 처리하는 기능을 제공합니다.
Spliterator는 컬렉션을 분할하여 병렬 처리를 가능하게 하며, 내부적으로 분할된 부분을 동기화하거나 정렬하는 등의 기능을 제공합니다.
Spliterator를 사용하여 컬렉션을 병렬로 처리하면 멀티스레드 환경에서 성능을 향상시킬 수 있습니다.
Iterator 인터페이스는 다음과 같이 정의됩니다
/*
* Copyright (c) 1997, 2018, Oracle and/or its affiliates. All rights reserved.
* DO NOT ALTER OR REMOVE COPYRIGHT NOTICES OR THIS FILE HEADER.
*
* This code is free software; you can redistribute it and/or modify it
* under the terms of the GNU General Public License version 2 only, as
* published by the Free Software Foundation. Oracle designates this
* particular file as subject to the "Classpath" exception as provided
* by Oracle in the LICENSE file that accompanied this code.
*
* This code is distributed in the hope that it will be useful, but WITHOUT
* ANY WARRANTY; without even the implied warranty of MERCHANTABILITY or
* FITNESS FOR A PARTICULAR PURPOSE. See the GNU General Public License
* version 2 for more details (a copy is included in the LICENSE file that
* accompanied this code).
*
* You should have received a copy of the GNU General Public License version
* 2 along with this work; if not, write to the Free Software Foundation,
* Inc., 51 Franklin St, Fifth Floor, Boston, MA 02110-1301 USA.
*
* Please contact Oracle, 500 Oracle Parkway, Redwood Shores, CA 94065 USA
* or visit www.oracle.com if you need additional information or have any
* questions.
*/
package java.util;
import java.util.function.Consumer;
/**
* An iterator over a collection. {@code Iterator} takes the place of
* {@link Enumeration} in the Java Collections Framework. Iterators
* differ from enumerations in two ways:
*
* <ul>
* <li> Iterators allow the caller to remove elements from the
* underlying collection during the iteration with well-defined
* semantics.
* <li> Method names have been improved.
* </ul>
*
* <p>This interface is a member of the
* <a href="{@docRoot}/java.base/java/util/package-summary.html#CollectionsFramework">
* Java Collections Framework</a>.
*
* @apiNote
* An {@link Enumeration} can be converted into an {@code Iterator} by
* using the {@link Enumeration#asIterator} method.
*
* @param <E> the type of elements returned by this iterator
*
* @author Josh Bloch
* @see Collection
* @see ListIterator
* @see Iterable
* @since 1.2
*/
public interface Iterator<E> {
/**
* Returns {@code true} if the iteration has more elements.
* (In other words, returns {@code true} if {@link #next} would
* return an element rather than throwing an exception.)
*
* @return {@code true} if the iteration has more elements
*/
boolean hasNext();
/**
* Returns the next element in the iteration.
*
* @return the next element in the iteration
* @throws NoSuchElementException if the iteration has no more elements
*/
E next();
/**
* Removes from the underlying collection the last element returned
* by this iterator (optional operation). This method can be called
* only once per call to {@link #next}.
* <p>
* The behavior of an iterator is unspecified if the underlying collection
* is modified while the iteration is in progress in any way other than by
* calling this method, unless an overriding class has specified a
* concurrent modification policy.
* <p>
* The behavior of an iterator is unspecified if this method is called
* after a call to the {@link #forEachRemaining forEachRemaining} method.
*
* @implSpec
* The default implementation throws an instance of
* {@link UnsupportedOperationException} and performs no other action.
*
* @throws UnsupportedOperationException if the {@code remove}
* operation is not supported by this iterator
*
* @throws IllegalStateException if the {@code next} method has not
* yet been called, or the {@code remove} method has already
* been called after the last call to the {@code next}
* method
*/
default void remove() {
throw new UnsupportedOperationException("remove");
}
/**
* Performs the given action for each remaining element until all elements
* have been processed or the action throws an exception. Actions are
* performed in the order of iteration, if that order is specified.
* Exceptions thrown by the action are relayed to the caller.
* <p>
* The behavior of an iterator is unspecified if the action modifies the
* collection in any way (even by calling the {@link #remove remove} method
* or other mutator methods of {@code Iterator} subtypes),
* unless an overriding class has specified a concurrent modification policy.
* <p>
* Subsequent behavior of an iterator is unspecified if the action throws an
* exception.
*
* @implSpec
* <p>The default implementation behaves as if:
* <pre>{@code
* while (hasNext())
* action.accept(next());
* }</pre>
*
* @param action The action to be performed for each element
* @throws NullPointerException if the specified action is null
* @since 1.8
*/
default void forEachRemaining(Consumer<? super E> action) {
Objects.requireNonNull(action);
while (hasNext())
action.accept(next());
}
}Iterable 인터페이스를 구현하는 예제 클래스를 살펴보겠습니다.
아래의 코드는 정수를 저장하는 간단한 컬렉션 클래스인 MyCollection을 구현한 예제입니다.
import java.util.Iterator;
public class MyCollection implements Iterable<Integer> {
private int[] elements;
private int size;
public MyCollection(int[] elements) {
this.elements = elements;
this.size = elements.length;
}
@Override
public Iterator<Integer> iterator() {
return new MyIterator();
}
private class MyIterator implements Iterator<Integer> {
private int currentIndex;
public MyIterator() {
this.currentIndex = 0;
}
@Override
public boolean hasNext() {
return currentIndex < size;
}
@Override
public Integer next() {
if (hasNext()) {
return elements[currentIndex++];
} else {
throw new NoSuchElementException();
}
}
}
public static void main(String[] args) {
int[] elements = {1, 2, 3, 4, 5};
MyCollection collection = new MyCollection(elements);
for (int num : collection) {
System.out.println(num);
}
}
}위의 코드에서 MyCollection 클래스는 Iterable 인터페이스를 구현합니다. 따라서 iterator() 메서드를 구현해야 합니다. 이 메서드는 MyIterator 클래스의 객체를 반환합니다.
MyIterator 클래스는 Iterator 인터페이스를 구현하며, hasNext() 메서드와 next() 메서드를 구현합니다. 이를 통해 컬렉션의 요소에 접근할 수 있습니다.
마지막으로 main() 메서드에서는 MyCollection 객체를 생성하고 for-each 문을 사용하여 컬렉션의 요소에 접근합니다. 이를 통해 컬렉션의 요소를 반복적으로 출력합니다.
Collection Interface
Collection 인터페이스는 자바의 컬렉션 프레임워크에서 가장 기본이 되는 인터페이스 중 하나입니다. Collection 인터페이스는 객체들의 그룹을 나타내는 컬렉션을 표현하기 위한 공통 동작을 정의합니다.
Collection 인터페이스는 다음과 같은 주요 메소드들을 정의하고 있습니다

Collection 인터페이스는 순서가 없는 요소들의 그룹을 표현하며, 중복된 요소를 허용할 수 있습니다. Collection 인터페이스는 List, Set, Queue 등의 다양한 구현체를 가질 수 있으며, 각각은 특정한 동작과 특성을 가지고 있습니다. 이를 통해 데이터를 효율적으로 저장, 관리, 조작할 수 있습니다.
Collection 인터페이스의 정의는 다음과 같습니다.
package java.util;
import java.util.function.IntFunction;
import java.util.function.Predicate;
import java.util.stream.Stream;
import java.util.stream.StreamSupport;
public interface Collection<E> extends Iterable<E> {
// Query Operations
int size();
boolean isEmpty();
boolean contains(Object o);
Iterator<E> iterator();
Object[] toArray();
<T> T[] toArray(T[] a);
default <T> T[] toArray(IntFunction<T[]> generator) {
return toArray(generator.apply(0));
}
// Modification Operations
boolean add(E e);
boolean remove(Object o);
// Bulk Operations
boolean containsAll(Collection<?> c);
boolean addAll(Collection<? extends E> c);
boolean removeAll(Collection<?> c);
default boolean removeIf(Predicate<? super E> filter) {
Objects.requireNonNull(filter);
boolean removed = false;
final Iterator<E> each = iterator();
while (each.hasNext()) {
if (filter.test(each.next())) {
each.remove();
removed = true;
}
}
return removed;
}
boolean retainAll(Collection<?> c);
void clear();
// Comparison and hashing
boolean equals(Object o);
int hashCode();
@Override
default Spliterator<E> spliterator() {
return Spliterators.spliterator(this, 0);
}
default Stream<E> stream() {
return StreamSupport.stream(spliterator(), false);
}
default Stream<E> parallelStream() {
return StreamSupport.stream(spliterator(), true);
}
}Collection 인터페이스를 구현한 구체 클래스를 다음과 같이 정의할 수 있습니다.
import java.util.Arrays;
import java.util.Iterator;
public class MyCollection<T> implements Collection<T> {
private static final int DEFAULT_CAPACITY = 10;
private T[] elements;
private int size;
public MyCollection() {
elements = (T[]) new Object[DEFAULT_CAPACITY];
//배열은 클래스 객체라 Object 가능.
size = 0;
}
@Override
public int size() {
return size;
}
@Override
public boolean isEmpty() {
return size == 0;
}
@Override
public boolean contains(Object o) {
for (T element : elements) {
if (element != null && element.equals(o)) {
return true;
}
}
return false;
}
@Override
public Iterator<T> iterator() {
return new MyIterator();
}
@Override
public Object[] toArray() {
return Arrays.copyOf(elements, size);
}
@Override
public <E> E[] toArray(E[] a) {
if (a.length < size) {
return (E[]) Arrays.copyOf(elements, size, a.getClass());
}
System.arraycopy(elements, 0, a, 0, size);
if (a.length > size) {
a[size] = null;
}
return a;
}
@Override
public boolean add(T e) {
if (size == elements.length) {
expandCapacity();
}
elements[size++] = e;
return true;
}
@Override
public boolean remove(Object o) {
for (int i = 0; i < size; i++) {
if (elements[i] != null && elements[i].equals(o)) {
removeElementAtIndex(i);
return true;
}
}
return false;
}
@Override
public boolean containsAll(Collection<?> c) {
for (Object element : c) {
if (!contains(element)) {
return false;
}
}
return true;
}
@Override
public boolean addAll(Collection<? extends T> c) {
boolean modified = false;
for (T element : c) {
if (add(element)) {
modified = true;
}
}
return modified;
}
@Override
public boolean removeAll(Collection<?> c) {
boolean modified = false;
for (Object element : c) {
modified |= remove(element);
}
return modified;
}
@Override
public boolean retainAll(Collection<?> c) {
boolean modified = false;
for (int i = 0; i < size; i++) {
if (!c.contains(elements[i])) {
removeElementAtIndex(i);
modified = true;
i--;
}
}
return modified;
}
@Override
public void clear() {
Arrays.fill(elements, null);
size = 0;
}
// Helper method to remove an element at the specified index
private void removeElementAtIndex(int index) {
System.arraycopy(elements, index + 1, elements, index, size - index - 1);
elements[--size] = null;
}
// Helper method to expand the capacity of the internal array
private void expandCapacity() {
int newCapacity = elements.length * 2;
elements = Arrays.copyOf(elements, newCapacity);
}
// Custom iterator implementation
private class MyIterator implements Iterator<T> {
private int currentIndex = 0;
@Override
public boolean hasNext() {
return currentIndex < size;
}
@Override
public T next() {
if (!hasNext()) {
throw new NoSuchElementException();
}
return elements[currentIndex++];
}
@Override
public void remove() {
throw new UnsupportedOperationException();
}
}
}그리고 이 구체 클래스를 사용하는 클라이언트인 Main 클래스를 다음과 같이 정의합니다.
public class Main {
public static void main(String[] args) {
MyCollection<Integer> collection = new MyCollection<>();
collection.add(10);
collection.add(20);
collection.add(30);
for (int num : collection) {
System.out.println(num);
}
collection.remove(20);
System.out.println("Size: " + collection.size());
System.out.println("Contains 20: " + collection.contains(20));
}
}List Interface
List 인터페이스는 자바 프로그래밍 언어에서 제공하는 인터페이스 중 하나입니다. 이 인터페이스는 순서가 있는 요소의 컬렉션을 나타내며, 중복된 요소를 포함할 수 있습니다. List 인터페이스는 자바의 컬렉션 프레임워크에 속하며, 배열과 유사한 동작을 수행하는 동적인 크기의 리스트를 제공합니다.
List 인터페이스는 java.util 패키지에 정의되어 있으며, java.util.Collection 인터페이스를 확장하고 있습니다. 따라서 List는 Collection 인터페이스에서 정의된 모든 메서드를 상속받습니다. 또한 List 인터페이스는 자체적으로 인덱스를 사용하여 요소에 접근하는 메서드를 추가로 정의하고 있습니다.
List 인터페이스의 주요 특징은 다음과 같습니다:
1. 순서 : List의 요소는 순서를 가지고 있으며, 요소의 삽입 순서를 유지합니다. 따라서 요소를 추가한 순서대로 접근할 수 있습니다.
2. 중복 요소 : List는 중복된 요소를 포함할 수 있습니다. 즉, 동일한 값을 가진 요소를 여러 개 가질 수 있습니다.
3. 인덱스 기반 접근 : List는 인덱스를 사용하여 요소에 접근할 수 있습니다. 인덱스는 0부터 시작하며, 요소의 위치를 지정하는 정수값으로 사용됩니다. 따라서 List에서는 인덱스를 통해 요소를 검색하거나 수정할 수 있습니다.
package java.util;
import java.util.function.UnaryOperator;
public interface List<E> extends Collection<E> {
// Query Operations
int size();
boolean isEmpty();
boolean contains(Object o);
Iterator<E> iterator();
Object[] toArray();
<T> T[] toArray(T[] a);
// Modification Operations
boolean add(E e);
boolean remove(Object o);
// Bulk Modification Operations
boolean containsAll(Collection<?> c);
boolean addAll(Collection<? extends E> c);
boolean addAll(int index, Collection<? extends E> c);
boolean removeAll(Collection<?> c);
boolean retainAll(Collection<?> c);
default void replaceAll(UnaryOperator<E> operator) {
Objects.requireNonNull(operator);
final ListIterator<E> li = this.listIterator();
while (li.hasNext()) {
li.set(operator.apply(li.next()));
}
}
@SuppressWarnings({"unchecked", "rawtypes"})
default void sort(Comparator<? super E> c) {
Object[] a = this.toArray();
Arrays.sort(a, (Comparator) c);
ListIterator<E> i = this.listIterator();
for (Object e : a) {
i.next();
i.set((E) e);
}
}
void clear();
// Comparison and hashing
boolean equals(Object o);
int hashCode();
// Positional Access Operations
E get(int index);
E set(int index, E element);
void add(int index, E element);
E remove(int index);
// Search Operations
int indexOf(Object o);
int lastIndexOf(Object o);
// List Iterators
ListIterator<E> listIterator();
ListIterator<E> listIterator(int index);
// View
List<E> subList(int fromIndex, int toIndex);
@Override
default Spliterator<E> spliterator() {
if (this instanceof RandomAccess) {
return new AbstractList.RandomAccessSpliterator<>(this);
} else {
return Spliterators.spliterator(this, Spliterator.ORDERED);
}
}
@SuppressWarnings("unchecked")
static <E> List<E> of() {
return (List<E>) ImmutableCollections.EMPTY_LIST;
}
static <E> List<E> of(E e1) {
return new ImmutableCollections.List12<>(e1);
}
static <E> List<E> of(E e1, E e2) {
return new ImmutableCollections.List12<>(e1, e2);
}
static <E> List<E> of(E e1, E e2, E e3) {
return ImmutableCollections.listFromTrustedArray(e1, e2, e3);
}
static <E> List<E> of(E e1, E e2, E e3, E e4) {
return ImmutableCollections.listFromTrustedArray(e1, e2, e3, e4);
}
static <E> List<E> of(E e1, E e2, E e3, E e4, E e5) {
return ImmutableCollections.listFromTrustedArray(e1, e2, e3, e4, e5);
}
static <E> List<E> of(E e1, E e2, E e3, E e4, E e5, E e6) {
return ImmutableCollections.listFromTrustedArray(e1, e2, e3, e4, e5,
e6);
}
static <E> List<E> of(E e1, E e2, E e3, E e4, E e5, E e6, E e7) {
return ImmutableCollections.listFromTrustedArray(e1, e2, e3, e4, e5,
e6, e7);
}
static <E> List<E> of(E e1, E e2, E e3, E e4, E e5, E e6, E e7, E e8) {
return ImmutableCollections.listFromTrustedArray(e1, e2, e3, e4, e5,
e6, e7, e8);
}
static <E> List<E> of(E e1, E e2, E e3, E e4, E e5, E e6, E e7, E e8, E e9) {
return ImmutableCollections.listFromTrustedArray(e1, e2, e3, e4, e5,
e6, e7, e8, e9);
}
static <E> List<E> of(E e1, E e2, E e3, E e4, E e5, E e6, E e7, E e8, E e9, E e10) {
return ImmutableCollections.listFromTrustedArray(e1, e2, e3, e4, e5,
e6, e7, e8, e9, e10);
}
@SafeVarargs
@SuppressWarnings("varargs")
static <E> List<E> of(E... elements) {
switch (elements.length) { // implicit null check of elements
case 0:
@SuppressWarnings("unchecked")
var list = (List<E>) ImmutableCollections.EMPTY_LIST;
return list;
case 1:
return new ImmutableCollections.List12<>(elements[0]);
case 2:
return new ImmutableCollections.List12<>(elements[0], elements[1]);
default:
return ImmutableCollections.listFromArray(elements);
}
}
static <E> List<E> copyOf(Collection<? extends E> coll) {
return ImmutableCollections.listCopy(coll);
}
}List 인터페이스에서 자주 사용되는 메서드는 다음과 같습니다:
-
add(element): 지정된 요소를 List에 추가합니다.
-
remove(element): 지정된 요소를 List에서 제거합니다.
-
remove(element): 지정된 요소를 List에서 제거합니다.
-
get(index): 지정된 인덱스에 위치한 요소를 반환합니다.
-
set(index, element): 지정된 인덱스에 위치한 요소를 새로운 값으로 대체합니다.
-
size(): List에 포함된 요소의 개수를 반환합니다.
-
contains(element): List에 지정된 요소가 포함되어 있는지 여부를 확인합니다.
-
of() : List 인터페이스의 of 메서드는 자바 9부터 추가된 정적 메서드로, 인자로 전달된 요소들로 구성된 변경 불가능한(List) 리스트를 생성하는 간편한 방법을 제공합니다.
List.of 메서드는 가변 인자(varargs)를 허용하며, 전달된 요소들을 순서대로 포함하는 변경 불가능한 리스트를 반환합니다. 이 리스트는 크기가 고정되어 있고, 요소들은 수정할 수 없습니다.
따라서 add, remove와 같은 변경 작업은 지원되지 않습니다.
List 인터페이스는 자바에서 다양한 구현 클래스를 가지고 있습니다. 대표적으로 ArrayList, LinkedList, Vector 등이 있으며, 각각의 구현 클래스는 내부적으로 다른 방식으로 데이터를 저장하고 처리합니다. 이러한 구현 클래스는 List 인터페이스를 구현하고 있으므로, List 인터페이스의 메서드를 모두 사용할 수 있습니다.
RandomAccess
RandomAccess 마커 인터페이스는 JVM에게 컬렉션의 특성에 대한 힌트를 제공합니다. JVM은 이 힌트를 활용하여 컬렉션에 대한 최적화를 수행할 수 있습니다. RandomAccess 인터페이스를 구현한 컬렉션은 빠른 무작위 접근을 지원한다는 힌트를 제공합니다.
이를 통해 JVM은 해당 컬렉션에 대한 반복, 검색, 접근 작업 등을 최적화할 수 있습니다. 예를 들어, JVM은 RandomAccess 인터페이스를 구현한 ArrayList와 같은 배열 기반의 리스트에 대해 내부적으로 빠른 인덱스 기반 접근 방식을 사용할 수 있습니다.
반면, RandomAccess 인터페이스를 구현하지 않은 컬렉션은 순차적인 접근을 가정하고 처리할 수 있습니다.
예를 들어, LinkedList와 같은 연결 리스트는 요소에 접근하기 위해 순차적으로 노드를 따라가야 하기 때문에, JVM은 내부적으로 노드를 탐색하는 방식을 사용할 수 있습니다.
JVM은 RandomAccess 인터페이스를 사용하여 컬렉션의 특성을 확인하고, 이를 기반으로 최적화된 알고리즘 및 접근 방식을 선택합니다. 이러한 최적화는 컬렉션을 사용하는 애플리케이션의 성능 향상에 기여할 수 있습니다.
ArrayList
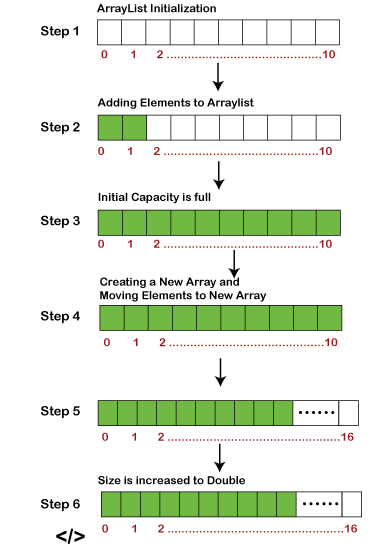
ArrayList를 사용하는 다양한 샘플 코드입니다.
1. ArrayList에 요소 추가하기
import java.util.ArrayList;
public class ArrayListExample {
public static void main(String[] args) {
ArrayList<String> fruits = new ArrayList<>();
// 요소 추가
fruits.add("Apple");
fruits.add("Banana");
fruits.add("Orange");
// 결과 출력
System.out.println(fruits); // [Apple, Banana, Orange]
}
}2. ArrayList에서 요소 제거하기
import java.util.ArrayList;
public class ArrayListExample {
public static void main(String[] args) {
ArrayList<String> fruits = new ArrayList<>();
// 요소 추가
fruits.add("Apple");
fruits.add("Banana");
fruits.add("Orange");
// 요소 제거
fruits.remove("Banana");
// 결과 출력
System.out.println(fruits); // [Apple, Orange]
}
}3. ArrayList의 크기 확인하기
import java.util.ArrayList;
public class ArrayListExample {
public static void main(String[] args) {
ArrayList<String> fruits = new ArrayList<>();
// 요소 추가
fruits.add("Apple");
fruits.add("Banana");
fruits.add("Orange");
// 크기 확인
int size = fruits.size();
// 결과 출력
System.out.println("크기: " + size); // 크기: 3
}
}4. ArrayList에서 요소 접근하기
import java.util.ArrayList;
public class ArrayListExample {
public static void main(String[] args) {
ArrayList<String> fruits = new ArrayList<>();
// 요소 추가
fruits.add("Apple");
fruits.add("Banana");
fruits.add("Orange");
// 인덱스를 이용한 요소 접근
String firstFruit = fruits.get(0);
String lastFruit = fruits.get(fruits.size() - 1);
// 결과 출력
System.out.println("첫 번째 과일: " + firstFruit); // 첫 번째 과일: Apple
System.out.println("마지막 과일: " + lastFruit); // 마지막 과일: Orange
}
}5. ArrayList의 요소 순회하기
import java.util.ArrayList;
public class ArrayListExample {
public static void main(String[] args) {
ArrayList<String> fruits = new ArrayList<>();
// 요소 추가
fruits.add("Apple");
fruits.add("Banana");
fruits.add("Orange");
// 요소 순회
for (String fruit : fruits) {
System.out.println(fruit);
}
}
}6. ArrayList에서 특정 요소의 인덱스 찾기
import java.util.ArrayList;
public class ArrayListExample {
public static void main(String[] args) {
ArrayList<String> fruits = new ArrayList<>();
// 요소 추가
fruits.add("Apple");
fruits.add("Banana");
fruits.add("Orange");
// 특정 요소의 인덱스 찾기
int index = fruits.indexOf("Banana");
// 결과 출력
System.out.println("Banana의 인덱스: " + index); // Banana의 인덱스: 1
}
}7. ArrayList의 모든 요소 제거
import java.util.ArrayList;
public class ArrayListExample {
public static void main(String[] args) {
ArrayList<String> fruits = new ArrayList<>();
// 요소 추가
fruits.add("Apple");
fruits.add("Banana");
fruits.add("Orange");
// 모든 요소 제거
fruits.clear();
// 결과 출력
System.out.println(fruits); // []
}
}8. ArrayList에서 요소의 존재 여부 확인
import java.util.ArrayList;
public class ArrayListExample {
public static void main(String[] args) {
ArrayList<String> fruits = new ArrayList<>();
// 요소 추가
fruits.add("Apple");
fruits.add("Banana");
fruits.add("Orange");
// 요소의 존재 여부 확인
boolean containsBanana = fruits.contains("Banana");
boolean containsGrape = fruits.contains("Grape");
// 결과 출력
System.out.println("Banana의 존재 여부: " + containsBanana); // Banana의 존재 여부: true
System.out.println("Grape의 존재 여부: " + containsGrape); // Grape의 존재 여부: false
}
}9. ArrayList의 요소를 배열로 반환하기
import java.util.ArrayList;
public class ArrayListExample {
public static void main(String[] args) {
ArrayList<String> fruits = new ArrayList<>();
// 요소 추가
fruits.add("Apple");
fruits.add("Banana");
fruits.add("Orange");
// 배열로 변환
String[] fruitArray = fruits.toArray(new String[0]);
// 결과 출력
for (String fruit : fruitArray) {
System.out.println(fruit);
}
}
}10. ArrayList의 요소를 정렬하기
import java.util.ArrayList;
import java.util.Collections;
public class ArrayListExample {
public static void main(String[] args) {
ArrayList<String> fruits = new ArrayList<>();
// 요소 추가
fruits.add("Apple");
fruits.add("Banana");
fruits.add("Orange");
// 정렬
Collections.sort(fruits);
// 결과 출력
System.out.println(fruits); // [Apple, Banana, Orange]
}
}11. ArrayList의 요소를 역순으로 정렬하기
import java.util.ArrayList;
import java.util.Collections;
public class ArrayListExample {
public static void main(String[] args) {
ArrayList<String> fruits = new ArrayList<>();
// 요소 추가
fruits.add("Apple");
fruits.add("Banana");
fruits.add("Orange");
// 역순으로 정렬
Collections.reverse(fruits);
// 결과 출력
System.out.println(fruits); // [Orange, Banana, Apple]
}
}12. ArrayList의 일부 요소 추출하기
import java.util.ArrayList;
import java.util.List;
public class ArrayListExample {
public static void main(String[] args) {
ArrayList<String> fruits = new ArrayList<>();
// 요소 추가
fruits.add("Apple");
fruits.add("Banana");
fruits.add("Orange");
fruits.add("Grape");
fruits.add("Watermelon");
// 일부 요소 추출
List<String> selectedFruits = fruits.subList(1, 4);
// 결과 출력
System.out.println(selectedFruits); // [Banana, Orange, Grape]
}
}13. ArrayList의 요소 복사하기
import java.util.ArrayList;
import java.util.Collections;
public class ArrayListExample {
public static void main(String[] args) {
ArrayList<String> fruits = new ArrayList<>();
// 요소 추가
fruits.add("Apple");
fruits.add("Banana");
fruits.add("Orange");
// 요소 복사
ArrayList<String> copiedFruits = new ArrayList<>(fruits);
// 결과 출력
System.out.println(copiedFruits); // [Apple, Banana, Orange]
}
}14. ArrayList의 요소를 다른 ArrayList에 추가하기
import java.util.ArrayList;
import java.util.Collections;
public class ArrayListExample {
public static void main(String[] args) {
ArrayList<String> fruits = new ArrayList<>();
// 요소 추가
fruits.add("Apple");
fruits.add("Banana");
// 다른 ArrayList에 요소 추가
ArrayList<String> moreFruits = new ArrayList<>();
moreFruits.add("Orange");
moreFruits.addAll(fruits);
// 결과 출력
System.out.println(moreFruits); // [Orange, Apple, Banana]
}
}LinkedList
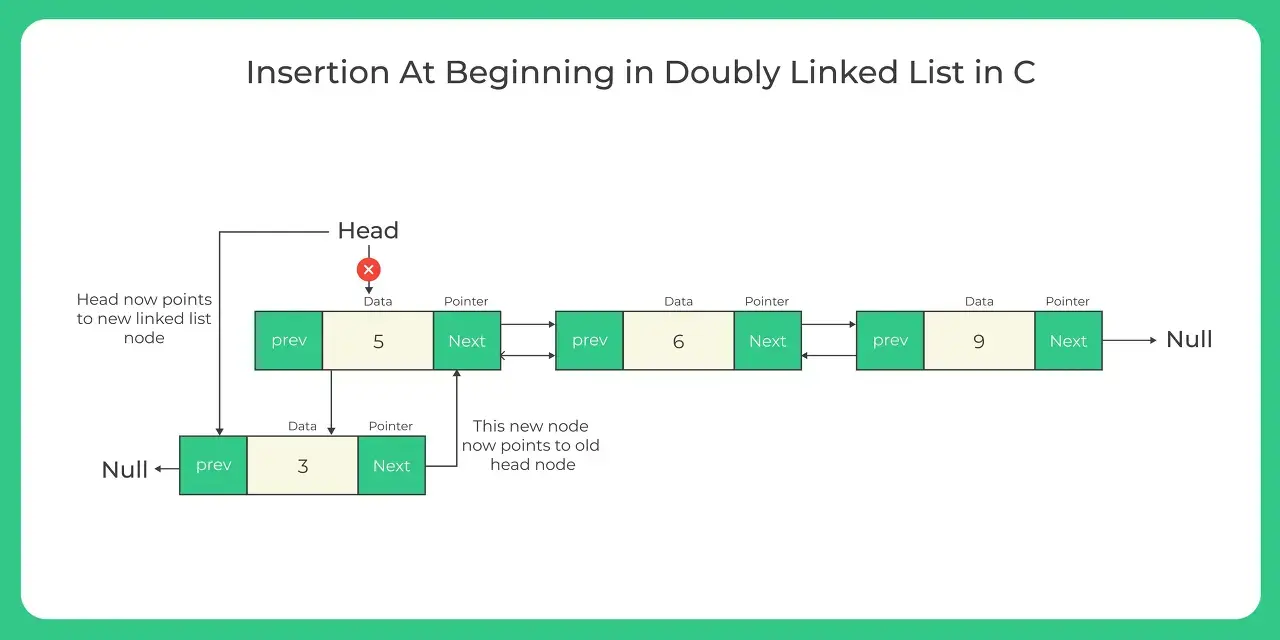
링크드 리스트는 컴퓨터 과학과 프로그래밍에서 데이터를 저장하고 조직화하는 데 사용되는 데이터 구조입니다. 링크드 리스트는 각각의 노드로 구성되며, 각 노드에는 데이터 요소와 다음 노드를 가리키는 참조(또는 링크)가 포함됩니다.
링크드 리스트의 기본 구성 요소는 노드입니다. 각 노드에는 일반적으로 데이터 부분과 다음 노드를 가리키는 포인터(또는 참조) 부분이 있습니다. 데이터 부분은 실제 값이나 정보를 저장하고, 다음 포인터는 시퀀스에서 다음 노드를 가리킵니다.
링크드 리스트는 특히 리스트의 시작 또는 끝에서 요소를 효율적으로 삽입하고 삭제할 수 있습니다. 그러나 리스트의 중간에 있는 요소에 접근하는 것은 배열과 같은 다른 데이터 구조에 비해 느릴 수 있습니다.
링크드 리스트에는 단일 링크드 리스트, 이중 링크드 리스트, 순환 링크드 리스트 등 여러 종류가 있습니다. 단일 링크드 리스트는 각 노드가 다음 노드를 가리키는 참조만 가지고 있습니다.
이중 링크드 리스트는 각 노드가 다음과 이전 노드를 가리키는 참조를 모두 가지고 있어 양방향으로 더 쉬운 순회가 가능합니다. 순환 링크드 리스트는 마지막 노드가 첫 번째 노드를 가리키는 루프를 형성합니다.
링크드 리스트는 스택, 큐, 해시 테이블과 같은 다른 데이터 구조를 구현하는 데 자주 사용됩니다. 동적으로 메모리를 관리하는 데 유연성을 제공하며, 요소 수가 알려지지 않거나 계속 변하는 경우에 특히 유용합니다.
Java LinkedList
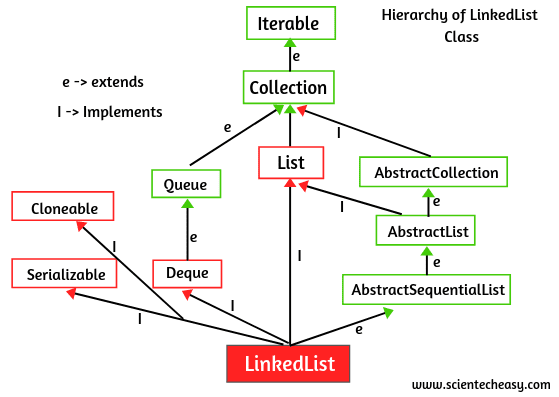
자바 LinkedList는 자바 컬렉션 프레임워크의 하나로, 더블 링크드 리스트(doubly linked list)로 구현된 데이터 구조입니다. 각 요소는 이전 요소와 다음 요소를 가리키는 링크(참조)를 가지고 있습니다. LinkedList는 동적인 크기 조정이 가능하며, 요소의 삽입, 삭제, 검색에 효율적입니다.
LinkedList의 주요 특징은 다음과 같습니다
더블 링크드 리스트 구조 : LinkedList의 각 노드는 데이터 요소와 이전 노드와 다음 노드를 가리키는 두 개의 링크로 구성됩니다. 이 링크를 통해 순차적인 탐색, 요소의 삽입 및 삭제 작업을 수행할 수 있습니다.
동적 크기 조정 : LinkedList는 내부적으로 연결된 노드들로 구성되어 있으며, 요소의 추가나 삭제 시 필요에 따라 크기를 동적으로 조정할 수 있습니다. 이는 배열(Array)과 달리 크기 제한에 대한 걱정 없이 요소를 추가하거나 삭제할 수 있다는 장점을 가지고 있습니다.
느린 접근 시간 : LinkedList는 인덱스를 기반으로 한 빠른 랜덤 액세스를 제공하지 않습니다. 원하는 위치의 요소에 접근하기 위해서는 첫 번째 노드부터 순차적으로 탐색해야 합니다. 따라서 요소를 검색할 때는 LinkedList보다 배열(ArrayList 등)을 사용하는 것이 더 효율적입니다.
중간 삽입 및 삭제의 효율성 : LinkedList는 중간에 요소를 삽입하거나 삭제하는 작업에 용이합니다. 이 작업은 해당 위치의 이전 노드와 다음 노드의 링크만 변경하면 되기 때문에 배열에 비해 효율적입니다.
Java의 LinkedList는 이중 링크드 리스트는 리스트에서 시퀀스를 나타내는 노드 그룹으로 구성됩니다. 노드 그룹은 노드의 시퀀스에 요소를 저장합니다.
각 노드에는 데이터가 저장된 데이터 필드와 이전 노드와 다음 노드를 가리키는 참조 또는 포인터인 왼쪽(left)과 오른쪽(right) 필드가 세 개의 필드가 있습니다.
포인터는 다음 노드와 이전 노드의 주소를 나타냅니다. 링크드 리스트의 요소를 Node라고 합니다.
첫 번째 노드의 이전 필드와 마지막 노드의 다음 필드는 아무것도 가리키지 않으므로 null 값으로 설정해야 합니다.
Java의 LinkedList에 새로운 요소를 저장할 때마다 자동으로 새로운 노드가 생성됩니다.
요소가 추가될 때마다 크기가 증가하며, 초기 용량은 0입니다. 요소가 제거되면 크기가 자동으로 줄어듭니다.
LinkedList에 요소를 추가하거나 제거하는 작업은 빠르게 수행되며 동일한 시간(즉, 상수 시간)이 소요됩니다.
따라서, 요소가 리스트의 중간에 삽입되거나 제거되는 상황에서 특히 유용합니다.
링크드 리스트에서 요소는 연속적인 메모리 위치에 저장되지 않습니다. 요소(일반적으로 노드라고 함)는 노드 부분의 왼쪽과 오른쪽을 이용하여 서로 연결하여 메모리의 여유 공간 어디에든 위치할 수 있습니다.
Java에서 선형 이중 링크드 리스트의 배열 표현은 아래 그림에 나와 있습니다.
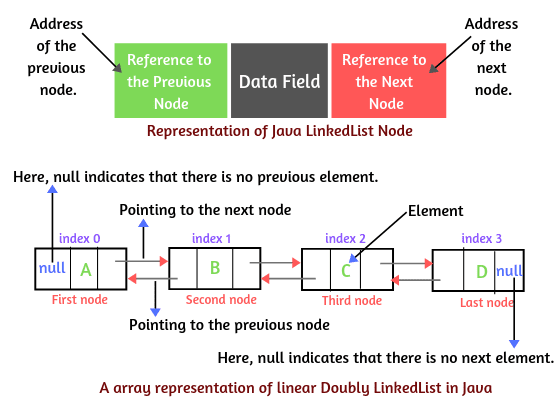
이로써, LinkedList는 요소의 재배치를 필요로 하지 않지만 각 요소가 링크에 의해 다음과 이전 요소와 연결되어야 한다는 점이 필요합니다.
노드의 오른쪽에는 다음 요소의 주소가 포함되어 있고, 노드의 왼쪽에는 리스트 내의 이전 요소의 주소가 포함되어 있습니다.
Java의 LinkedList 클래스는 List, Deque, Queue 인터페이스를 구현합니다.
AbstractSequentialList를 상속하였습니다. 또한 serializable과 cloneable과 같은 마커 인터페이스를 구현하지만 random access 인터페이스는 구현하지 않습니다.
주요 기능
Java LinkedList 클래스의 주요 기능은 다음과 같습니다
-
LinkedList의 내부 데이터 구조는 이중 링크드 리스트입니다. 이는 배열 리스트와 마찬가지로 List 인터페이스의 다른 구체적인 구현체입니다.
-
Java LinkedList 클래스는 중복 요소를 저장할 수 있습니다.
-
LinkedList에는 null 요소를 추가할 수 있습니다.
-
LinkedList에는 다른 타입의 요소를 저장할 수 있습니다.
-
Java LinkedList는 동기화되지 않았습니다. 따라서 여러 스레드가 동시에 동일한 LinkedList 객체에 접근할 수 있습니다. 따라서 스레드 동기화가 지원되지 않습니다. 그러나 LinkedList는 동기화되지 않았으므로 작업이 더 빠릅니다.
-
LinkedList에서 요소의 삽입과 제거는 빠릅니다. 각 요소의 추가 및 제거를 위한 요소들을 이동시킬 필요가 없기 때문입니다. Next와 Prev 요소에 대한 참조만 변경됩니다.
-
LinkedList는 중간에 삽입이나 삭제가 빈번한 경우 가장 좋은 선택입니다.
-
LinkedList에서 요소를 검색하는 것은 매우 느립니다. 요소에 도달하기 위해 시작점이나 끝점부터 순회해야 하기 때문입니다.
-
LinkedList는 "스택"으로 사용할 수 있습니다. pop() 및 push() 메서드를 사용하여 스택으로 동작할 수 있습니다.
-
Java LinkedList는 무작위 액세스 인터페이스를 구현하지 않습니다. 따라서 요소에 임의로 액세스(검색)할 수 없습니다. 주어진 요소에 액세스하려면 LinkedList에서 시작점이나 끝점부터 순회해야 합니다.
-
ListIterator를 사용하여 LinkedList 요소를 Iterable 할 수 있습니다.
-
Java LinkedList에서는 이미 리스트에 저장된 데이터 항목에 영향을 주지 않고 삽입(추가) 작업을 수행할 수 있습니다.
위 개념을 이해하기 위해 예를 살펴보겠습니다.
- 초기 LinkedList에는 다음과 같은 데이터가 있다고 가정해 봅시다. 아래 그림과 같습니다.
LinkedList<Integer> linkedlist = new LinkedList<>();
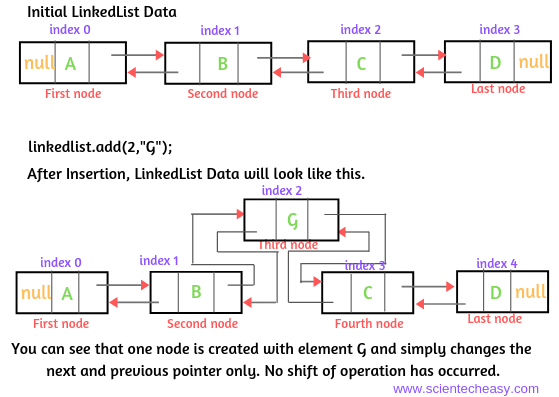
- 이제 이 링크드 리스트에 삽입 작업을 수행해보겠습니다. add() 메서드를 사용하여 인덱스 위치 2에 요소 G를 추가합니다. 요소 G를 추가하는 구문은 다음과 같습니다:
linkedlist.add(2,"G");
링크드 리스트에서 삽입 작업이 발생할 때, 내부적으로 LinkedList는 메모리의 가용한 어떤 공간이든 G 요소를 가진 노드를 생성하고, 리스트 내의 어떤 요소도 이동하지 않고 Next와 Prev 포인터만 변경합니다. 위의 그림에서 업데이트된 LinkedList를 확인할 수 있습니다.
Java LinkedList에서 삭제 작업이 어떻게 수행되는지 알아보겠습니다.
이전 섹션에서 이미 링크드 리스트가 내부적으로 삽입 작업을 수행하는 방법을 살펴보았습니다. 이제 Java 링크드 리스트가 내부적으로 삭제 작업을 수행하는 방법에 대해 설명하겠습니다.
- 초기 LinkedList에 다음과 같은 데이터가 있다고 가정해 봅시다.
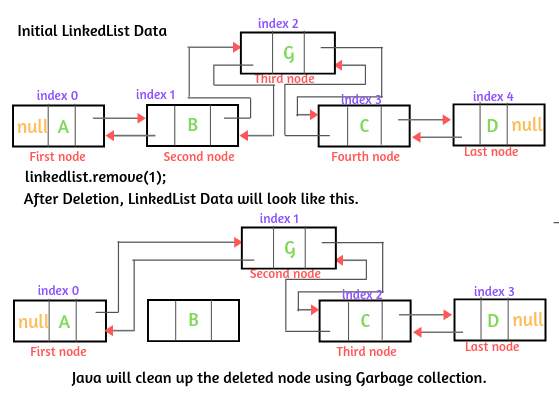
- 인덱스 1에 위치한 요소 B를 제거하려고 합니다. 요소 B를 삭제하는 구문은 다음과 같습니다:
linkedlist.remove(1);
삭제 작업이 발생하면 요소 B가 있는 노드가 삭제되고 다음과 이전 포인터가 변경됩니다. 삭제된 노드는 사용되지 않는 메모리가 됩니다.
따라서 Java는 가비지 컬렉션을 사용하여 사용되지 않는 메모리 공간을 정리합니다.
LinkedList Methods
List 인터페이스를 구현하는 것 외에도, Java LinkedList 클래스는 리스트의 양쪽 끝에서 요소를 검색, 삽입 및 제거하기 위한 메서드를 제공합니다.
LinkedList의 메서드는 아래 표에 나열되어 있습니다

LinkedList Deque Methods
Java LinkedList 클래스는 Deque 인터페이스에서 상속받은 다양한 특정 메서드도 가지고 있습니다. 이들은 아래 표에 나열되어 있습니다:

이러한 메서드를 사용하여 LinkedList에서 큐나 덱의 기능을 수행할 수 있습니다.
Java 애플리케이션에서 LinkedList를 사용하는 가장 좋은 경우는 리스트의 중간에 요소를 추가하거나 제거하는 작업이 빈번한 경우입니다. 링크드 리스트에서의 요소 추가와 제거는 ArrayList와 비교했을 때 더 빠르기 때문에 이러한 경우에는 Java LinkedList가 가장 적합한 선택입니다.
이 개념을 이해하기 위해 실제 시나리오를 살펴보겠습니다. 예를 들어 ArrayList에 100개의 요소가 있다고 가정해 봅시다. ArrayList에서 50번째 요소를 제거한다면, 51번째 요소는 50번째 위치로 이동하고, 52번째 요소는 51번째 위치로 이동하며, 다른 요소들에 대해서도 이러한 작업이 이루어져야 합니다. 이렇게 되면 요소의 이동에 많은 시간이 소요되어 ArrayList에서의 조작이 느려집니다.
그러나 링크드 리스트의 경우, 링크드 리스트에서 50번째 요소를 제거한다면, 제거 후에 요소의 이동은 발생하지 않습니다. 오직 다음 노드와 이전 노드의 참조만 변경됩니다.
또한 LinkedList는 스택(LIFO) 또는 큐(FIFO) 데이터 구조가 필요한 경우에도 중복을 허용하여 사용할 수 있습니다.
LinkedList를 사용하는 최악의 경우는 링크드 리스트에서 요소를 검색(조회)하는 작업이 빈번한 경우입니다. ArrayList와 비교하여 링크드 리스트에서 요소를 검색하는 것은 매우 느리기 때문에 LinkedList는 최악의 선택입니다.
LinkedList는 무작위 액세스 인터페이스를 구현하지 않습니다. 따라서 요소에 임의로 액세스(조회)할 수 없습니다. 시작점이나 끝점부터 순회하여 링크드 리스트의 요소에 도달해야 합니다.
이 개념을 이해하기 위해 실제 시나리오를 고려해 보겠습니다.
리스트에 10개의 요소가 있다고 가정해 봅시다. 링크드 리스트가 첫 번째 요소에 액세스하여 요소를 가져오는 데 1초가 걸린다고 가정해 봅시다.
첫 번째 노드에서 두 번째 요소의 주소가 사용 가능하므로, 두 번째 요소에 액세스하고 가져오기 위해서는 2초가 걸릴 것입니다.
마찬가지로, 리스트에서 9번째 요소를 가져오려면 LinkedList는 9초가 걸릴 것입니다. 왜냐하면 9번째 요소의 주소는 8번째 노드에 있고, 8번째 노드의 주소는 7번째 노드에 있기 때문입니다.
그러나 리스트에 100만 개의 요소가 있고, 리스트에서 50만 번째 요소를 가져오려고 한다면 링크드 리스트는 50만 번째 요소를 액세스하고 가져오는 데 1년이 걸릴 수도 있습니다.
따라서 링크드 리스트는 링크드 리스트에서 요소를 검색하거나 탐색하는 경우에는 최악의 선택입니다.
이 경우에는 ArrayList가 리스트에서 요소를 가져오는 데 가장 적합한 선택입니다. 왜냐하면 ArrayList는 무작위 액세스 인터페이스를 구현하기 때문에 임의의 위치에서 배열 리스트에서 요소를 매우 빠르게 가져올 수 있기 때문입니다.
