카프카(Kafka)는 아파치 소프트웨어 재단(Apache Software Foundation)에서 개발한 분산 스트리밍 플랫폼입니다.
카프카는 대용량의 데이터를 실시간으로 처리하고 저장하는 데 주로 사용되며, 이벤트 스트리밍 아키텍처를 구현하는 데 매우 유용한 도구입니다.
카프카는 다양한 애플리케이션 간에 데이터를 안전하게 전달하고 처리하기 위한 목적으로 설계되었습니다.
주요 개념과 기능
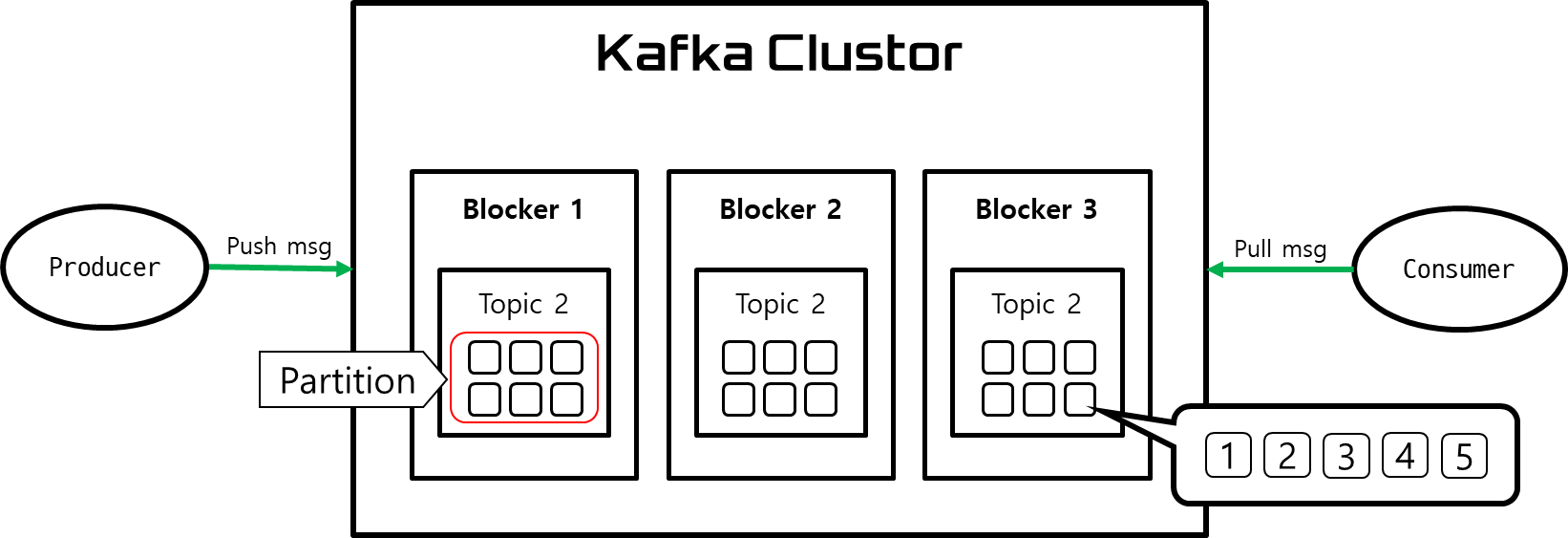
토픽(Topic) : 데이터 스트림은 토픽으로 구성됩니다. 토픽은 데이터 카테고리 또는 주제를 나타내며, 여러 프로듀서가 데이터를 쓰고 여러 컨슈머가 데이터를 읽을 수 있습니다.
프로듀서(Producer) : 데이터를 생성하고 토픽으로 보내는 역할을 합니다. 프로듀서는 실시간 이벤트 데이터를 카프카 클러스터로 보내는데 사용됩니다.
브로커(Broker) : 카프카 클러스터는 여러 개의 브로커로 구성됩니다. 각 브로커는 데이터를 저장하고 관리하며, 프로듀서로부터 데이터를 받아 토픽에 쓰고, 컨슈머에게 데이터를 전달합니다.
컨슈머(Consumer) : 데이터를 읽어오는 역할을 합니다. 여러 개의 컨슈머가 하나의 토픽에서 데이터를 동시에 읽을 수 있습니다.
파티션(Partition) : 각 토픽은 파티션으로 분할될 수 있습니다. 파티션은 데이터를 분산하여 저장하고 병렬로 처리할 수 있도록 도와줍니다.
오프셋(Offset) : 각 파티션 내에서 데이터의 위치를 나타내는 식별자입니다. 컨슈머는 오프셋을 사용하여 어디까지 데이터를 읽었는지 추적합니다.
브로커 및 토픽 관리 : 카프카 클러스터의 확장, 토픽의 생성 및 구성, 파티션의 관리 등을 위해 관리 도구를 제공합니다.
스키마 레지스트리(Schema Registry) : 데이터의 구조를 관리하고, 프로듀서와 컨슈머 간의 호환성을 유지하기 위해 사용됩니다. Avro나 JSON과 같은 스키마 형식을 지원합니다.
카프카의 주요 강점은 다음과 같습니다.
내구성 : 데이터는 브로커에 영속적으로 저장되므로 데이터 유실을 방지합니다.
확장성 : 클러스터를 확장하여 대량의 데이터를 처리할 수 있습니다.
실시간 처리 : 데이터를 실시간으로 처리하고 읽을 수 있어 실시간 분석이 가능합니다.
유연성 : 다양한 애플리케이션에서 데이터를 소비하고 생산할 수 있습니다.
이벤트 기반 아키텍처 : 이벤트 스트리밍 아키텍처를 구현하는 데 적합한 플랫폼입니다.
요약하면, 카프카는 대규모의 실시간 데이터 스트리밍을 위한 플랫폼으로, 이벤트 기반 아키텍처를 구현하거나 대용량 데이터를 처리하고 저장해야 하는 상황에서 유용한 도구입니다.
