그리드의 존제 의미
기존에 이미지를 13 x 13 그리드로 나누는 것은 일종의 제약 조건입니다. 이 제약조건 덕분에 학습하는 모델은 객체를 예측하는 방법을 더 쉽게 학습할 수 있습니다. 그리드는 특정 위치에서 전문적인 능력을 뽐내는 물체 탐지기를 학습시키게 합니다. 예를 들어 정 가운데 있는 셀에 있는 탐지기들은 중간 주변의 셀에 탐지된 객체만을 예측하게 됩니다.
Anchors(앵커)
그리드가 탐지기가 찾을 수 있는객체의 위치를 제한한다면, 객체의 모양을 제한하는 방법이 있습니다.
이미지 내 어디든지 있을 수 있는 객체를 탐지하기 어려워 그리드에 제한을 건 것처럼, 어떤 모양이나 크기가 될 수 있는 물체를 예측하는 방법을 배우는 것 또한 어려워 제한이 필요합니다.
따라서 우리는 다음과 같이 모양을 제한할 수 있습니다.

가장 일반적인 객체 모양 5개를 "앵커"라고 부릅니다. 결국 앵커란 상자의 너비와 높이의 목록입니다. 그리고 앵커는 기본적으로 사각형으로 작업됩니다.
5개의 앵커로 한 이유는 셀 내부의 탐지기가 각각 특정 물체의 모양에 전문적으로 되도록 강제합니다. 탐지기가 5개인 것처럼 앵커도 5개가 됩니다.
이렇게 정한 앵커는 미리 정해진값으로 훈련 중에 절대로 변해서는 안됩니다.
앵커의 크기가 정해지는 방식은 YOLO에선 k-평균 클러스터링을 사용해 각 부분마다 평균적인 크기의 상자를 선택합니다.
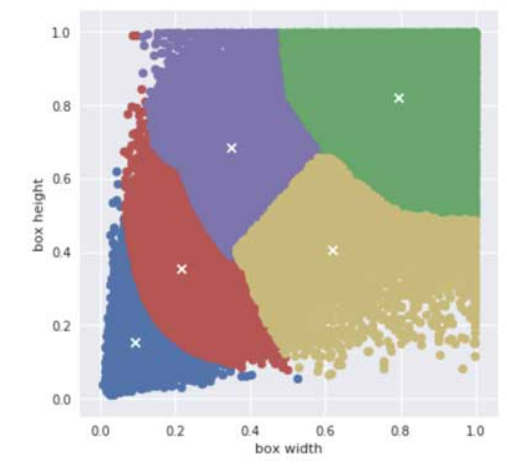
각 모델마다 정하는 방식이 다르니 참고하세요.

언제나 나 자신에게 되물어 보기. So What?