
VPS(Virtual Private Server): 물리적인 서버 한 대를 가상화 기술로 쪼개어, 마치 여러 대의 독립된 서버인 것처럼 사용자에게 빌려주는 서비스
| 단계 | 주제 | 목표 |
|---|---|---|
| 1단계 | 멀티 테넌트 네트워크 최적화 | 사용자별 네트워크 격리(VLAN/VXLAN) 및 외부 인터넷 통신(Floating IP) 환경 완벽 구축 |
| 2단계 | 클라우드 모니터링 시스템 구축 | 오픈스택 내부 자원(CPU, RAM, Traffic) 실시간 감시 및 Prometheus, Grafana 연동 |
| 3단계 | 리소스 제한 및 쿼터 관리 | 제한된 노트북 환경에서 특정 사용자의 자원 독점 방지를 위한 Quota 설정 |
- 오픈스택의 API를 활용하여 사용자에게 자원을 배포하고 관리하는 클라우드 서비스 포털을 제작한다. 이미 Kolla-Ansible로 구축된 오픈스택 환경이 있으므로, 해당 환경의 API 엔드포인트를 활용한다.
- 아래 표는 프라이빗 클라우드 직무에 맞춰, 단순 기능 구현을 넘어 엔지니어링 역량(네트워크, 자동화, 운영)을 보여줄 수 있는 프로젝트 계획
| 단계 | 주제 | 목표 |
|---|---|---|
| 1단계 | OpenStack API 연동 및 프로비저닝 자동화 | Python SDK를 이용한 인스턴스 생명주기 제어 및 커스텀 UI 연동 |
| 2단계 | 네트워크 아키텍처 및 접속 제어 구현 | 테넌트 격리, Floating IP 및 DNAT(포트포워딩) 자동화 로직 구현 |
| 3단계 | SLA 기반 운영 모니터링 고도화 | 가용성 및 성능 지표 정의, Grafana를 활용한 서비스 상태 시각화 |
- OpenStack SDK (Python) : openstacksdk 라이브러리를 사용하여 Keystone(인증), Nova(컴퓨팅), Neutron(네트워크) API를 호출한다.
- Keystone 연동 : 사용자별 프로젝트(Project)와 사용자(User)를 생성하고, 해당 권한 내에서만 자원을 조회하도록 구현한다.
- 리소스 쿼터(Quota) 관리 : Keystone/Nova의 Quota API를 통해 현재 사용량과 제한량을 가져와 계산한다.
- OpenStack API 연동 및 백엔드 아키텍처 설계
- Frontend (UI) : HTML/JS. 사용자에게 버튼과 상태 제공.
- Backend (API Server) : Python (Flask 또는 FastAPI). 오픈스택 SDK를 사용하여 로직 수행.
- Infrastructure (OpenStack) : 실제 자원이 생성되는 물리/가상 환경.
- Keystone 기반의 멀티 테넌시
- VPS 서비스의 핵심은 "A 사용자가 생성한 서버를 B 사용자가 볼 수 없어야 한다"는 점이다. 이를 위해 오픈스택의 인증 서비스인 Keystone에 대한 이해가 필요하다.
- Project (Tenant) : 자원의 격리 단위. A에게 'Project_A'를 할당하면, A는 그 안의 자원만 사용 가능.
- User / Role : 특정 프로젝트 내에서의 권한.
- 포인트 : "사용자별로 별도의 OpenStack Project를 동적으로 생성하여 자원을 완전 격리.
- OpenStack Python SDK : REST API를 직접 호출할 수도 있지만, OpenStack SDK를 사용
- API 버전 관리, 세션 유지, 에러 핸들링을 SDK가 추상화해 주어 코드의 안정성이 높다.
- UI에 보여줄 인스턴스 이름, 상태, IP 등의 데이터는 별도의 DB에 따로 저장하지 않고, 실시간 API 호출로만 처리한다.
- 사용자가 인스턴스 생성을 요청했을 때, API 서버(백엔드) 내부에서는 어떤 순서로 일이 벌어지는가?
- Keystone 인증 : API 서버가 관리자 권한으로 토큰을 발급받거나 사용자 자격 증명을 검증한다.
- Resource Check (Quota) : 해당 프로젝트의 CPU/RAM 잔여 할당량을 확인한다. (사용량 요약 기능)
- Nova API 호출 : 인스턴스 생성을 요청한다. 이때 가용 구역, 플레이버, 이미지 ID 등을 인자로 넘긴다.
- Async Response : 오픈스택은 요청을 즉시 수락하지만(202 Accepted), 실제 생성은 시간이 걸린다. 백엔드는 '생성 중(BUILDING)' 상태를 UI에 전달해야 한다.
과정
API 연결 및 기초 자원 조회
from openstack.connection import Connection
class OpenStackManager:
# clouds.yaml을 사용하여 인증 정보 외부화
# 보안 및 유지보수를 위해 SDK의 Connection 프로토콜 활용
def __init__(self, cloud_name='my-openstack'):
self.conn = openstack.connect(cloud=cloud_name)
def get_network_info(self):
# Neutron API를 호출해 현재 활성화된 네트워크와 서브넷 조회
networks = list(self.conn.network.networks())
return networks
def get_compute_quotas(self, project_name='admin'):
# Nova API를 호출해 프로젝트의 CPU/RAM 할당량 확인
# 사용량 요약 기능을 위한 데이터 소스
project = self.conn.identity.find_project(project_name)
limits = self.conn.compute.get_limits(project=project.id)
return limits.absolute
if __name__ == "__main__":
manager = OpenStackManager()
print("--- Networks ---")
for net in manager.get_network_info():
print(f"Network Name: {net.name}, ID: {net.id}")--- Networks ---
Network Name: shared_net, ID: 4d393aff-910e-44c6-9b2e-31a87ca3320e
Network Name: database_net, ID: 4f15933f-65f1-4d2c-99dd-885a91675985
Network Name: client_net, ID: 5fb54755-942e-4ebc-9823-4096b8c55243
Network Name: ext_net, ID: 68dcfc55-ed46-4462-85f9-6eee681702c8
Network Name: lb-mgmt-net, ID: 81fd0f08-0d82-4177-98f2-c3b792f59b50
Network Name: private_net, ID: 95096954-5810-40a1-9b3e-6870b1a09789
Network Name: application_net, ID: f71c1b5f-a229-4980-b188-fd1266b4411e네트워크 중심의 인스턴스 생성 자동화
- 인스턴스가 외부와 통신하기 위한 절차
- Fixed IP 할당 : 인스턴스 생성 시 내부 가상 네트워크(Tenant Network)로부터 사설 IP를 부여받는다.
- Security Group 적용 : 방화벽 규칙을 통해 특정 포트(SSH: 22, HTTP: 80 등)를 허용해야 한다.
- Floating IP 할당 및 매핑 : 외부 네트워크의 IP를 생성하여 인스턴스의 사설 IP와 1:1 NAT로 연결한다.
def create_vps_with_access(self, instance_name, network_name, image_name, flavor_name, key_name):
def create_vps_with_access(self, instance_name, network_name, image_name, flavor_name, key_name):
# 인스턴스 생성 후 접속용 Floating IP까지 자동 매핑
try:
image = self.conn.compute.find_image(image_name)
flavor = self.conn.compute.find_flavor(flavor_name)
networks = list(self.conn.network.networks(name=network_name))
if not networks:
raise Exception(f"Network '{network_name}'을 찾을 수 없습니다.")
network_id = networks[0].id
server = self.conn.compute.create_server(
name=instance_name,
image_id=image.id,
flavor_id=flavor.id,
networks=[{"uuid": network_id}],
key_name=key_name
)
# 인스턴스가 ACTIVE 상태가 될 때까지 대기
server = self.conn.compute.wait_for_server(server)
# Floating IP 할당 및 연결 (외부 네트워크에서 IP 하나를 가져옴)
ext_nets = list(self.conn.network.networks(name="ext_net"))
if ext_nets:
# 인스턴스에 연결된 포트(Port) ID 찾기
ports = list(self.conn.network.ports(device_id=server.id))
if not ports:
raise Exception("인스턴스에 연결된 네트워크 포트를 찾을 수 없습니다.")
port_id = ports[0].id
# floating IP 생성 및 포트 결합
fip = self.conn.network.create_ip(
floating_network_id=ext_nets[0].id,
port_id=port_id
)
fip_addr = fip.floating_ip_address
addresses = server.addresses.get(network_name, [])
fixed_ip = addresses[0]['addr'] if addresses else "N/A"
return {
"instance_id": server.id,
"fixed_ip": fixed_ip,
"floating_ip": fip_addr
}
except Exception as e:
print(f"[Internal Error] {e}")
raise e--- [테스트] portfolio-vps-01 생성 시작 ---
--- [성공] 인스턴스 정보 ---
ID: 044c7b8a-a001-4dc9-9165-5144c71b5da9
Fixed IP: 172.20.0.140
Floating IP: 192.168.35.215- 트러블 슈팅
- Before : Nova API 기반 : 컴퓨팅 서비스 nova에게 인스턴스 ID를 주며 IP를 붙여달라고 요청하는 방식
- After : Neutron API 기반 : 네트워크 서비스 neutron에서 인스턴스의 포트(vNIC)를 찾아 직접 결합하는 방식
- 차이점
- 서버 전체(
server.id)가 아니라, 서버에 꽂힌 랜카드(port_id)를 타겟팅한다. - API 엔드포인트 변경 :
conn.compute(Nova)에서conn.network(Neutron)로 명령의 주체가 바뀌었다. - 결합 시점 : IP를 만들고 나중에 붙이는 게 아니라, 생성과 동시에 특정 포트에 할당되도록 로직을 변경했다.
- 서버 전체(
add_floating_ip_to_server->create_ip(port_id=port_id)- Before 코드 에러 :
[실패] 에러 발생: NotFoundException: 404: Client Error for url: http://192.168.35.200:8774/v2.1/servers/cf991ee4-acc1-4faf-85d3-402230a1aacb/action, The resource could not be found. - 예전 버전에서는 Nova가 네트워크 기능 일부를 담당했으나, 현재는 모든 네트워크 제어권을 Neutron이 담당한다.
- 이전에는 Nova에게 이 서버에 IP 붙여달라고 요청하는 방식에서 Neutron에게 이 포트에 floating ip를 연결하라는 방식으로 변경.
- Port 객체 : 인스턴스에 할당된 가상 네트워크 인터페이스인 Port ID를 먼저 조회한다.
- 인스턴스는 하자지만, 그 안에 랜카드(Port)는 여러 개일 수 있다.
- floating IP는 인스턴스 자체가 아니라, 그 인스턴의 특정 port에 결합(binding)된다.
정리 : nova api v2.1에서는 add_floating_ip 메서드가 지원되지 않아 404 not found 에러가 발생했고, 이는 인프라 내에서 컴퓨팅과 네트워크 역할이 분리되어 있음을 알 수 있다. UUID를 기반으로 neutron port를 추적하고 neutron api를 호출하여 포트와 floating ip를 결합하는 방식으로 변경했다.
# Before 코드
# 외부 네트워크에서 IP 객체를 먼저 생성
fip = self.conn.network.create_ip(floating_network_id=ext_nets[0].id)
# Nova API를 호출하여 서버(인스턴스)에 IP 연결 시도 -> 404 에러 발생
self.conn.compute.add_floating_ip_to_server(server.id, fip.floating_ip_address)
##############################################################################
# After 코드
# 1. 인스턴스(server.id)와 연결된 실제 네트워크 '포트' ID를 조회
ports = list(self.conn.network.ports(device_id=server.id))
port_id = ports[0].id
# 2. Neutron API를 사용하여 IP 생성과 동시에 포트에 결합 (Atomic 작업)
fip = self.conn.network.create_ip(
floating_network_id=ext_nets[0].id,
port_id=port_id # 서버 ID 대신 포트 ID를 사용
)보안 그룹 자동화 및 프로메테우스 모니터링 데이터 연동 (Packer)
- Horizon 대시보드를 이용해서 수동으로 보안 그룹을 할당할 때 발생 가능한 실수를 줄이기 위해 보안 그룹 할당을 생성 로직에 추가
- 특정 인스턴스의 CPU 사용량 조회를 위해 프로메테우스 API와 연동
def create_security_group_with_rules(self, sg_name):
# 전용 보안 그룹 생성 및 필수 규칙(SSH, ICMP) 추가
# 기존 보안 그룹 확인
existing_sg = self.conn.network.find_security_group(sg_name)
if existing_sg:
return existing_sg
# 보안 그룹 생성 및 규칙 추가
print(f"--- 보안 그룹 {sg_name} 생성 중... ---")
sg = self.conn.network.create_security_group(name=sg_name)
self.conn.network.create_security_group_rule(
security_group_id=sg.id,
direction='ingress',
ethertype='IPv4',
protocol='tcp',
port_range_min=22,
port_range_max=22
)
self.conn.network.create_security_group_rule(
security_group_id=sg.id,
direction='ingress',
ethertype='IPv4',
protocol='icmp'
)
return sg
def get_instance_cpu_usage(prometheus_url, instance_ip):
# 프로메테우스 API를 호출해 특정 인스턴스의 CPU 사용량 조회
query = f'100 - (avg by (instance) (irate(node_cpu_seconds_total{{instance=~"{instance_ip}:.*", mode="idle"}}[5m])) * 100)'
try:
response = requests.get(f"{prometheus_url}/api/v1/query", params={'query': query})
result = response.json()
if result['data']['result']:
usage = result['data']['result'][0]['value'][1]
return round(float(usage), 2)
except Exception as e:
print(f"Monitoring Error : {e}")
return None# 테스트 코드 실행 결과
--- 보안 그룹 sg-test-vps-sg 생성 중... ---
생성 완료! Floating IP: 192.168.35.211
인스턴스(192.168.35.221) 현재 CPU 사용률: No Data%
-
문제 : 보안 그룹 생성 및 인스턴스에 할당은 정상적으로 되지만, 모니터링이 되지 않는다.
# 현재 prometheus.yml 파일 내용 (수정 전) global: scrape_interval: 10s scrape_configs: - job_name: 'prometheus' static_configs: - targets: ['localhost:9090'] - job_name: 'node-exporter' static_configs: - targets: ['localhost:9100'] - job_name: 'openstack-exporter' scrape_interval: 60s scrape_timeout: 50s static_configs: - targets: ['localhost:9180']- 📌 원인 : 인스턴스 내부에 node-exporter가 없다.
prometheus.yml설정은 localhost(프로메테우스가 설치된 서버 본체)의 데이터만 수집하도록 되어 있어 있다.static_configs에 인스턴스의 IP가 등록되어 있어야 한다. 프로메테우스는 명시적으로 등록된 대상이 아니면 데이터를 가져오지 않는다.
- 조치
- 현재 Cirros로 테스트 중인데, 초경량 OS인 만큼 패키지 관리자가 없고, 라이브러리가 제한적이기 때문에 Ubuntu를 사용
- Prometheus의 OpenStack Service Discovery(SD) 기능을 통해 오픈스택 API로 인스턴스를 자동으로 찾아내도록 설정을 변경
- Packer를 이용해서 node_exporter가 설치된 Ubuntu 이미지를 만들고, 이 이미지로 VPS가 생성되도록 수정
- 📌 원인 : 인스턴스 내부에 node-exporter가 없다.
-
조치 전 테스트 (인스턴스 내부에 익스포터가 있을 때 메트릭 수집이 되는지 확인)
-
Ubuntu로 인스턴스 생성 후
9100번 포트 개방및create_security_group_with_rules메서드에서도 9100 포트 허용하는 규칙 추가 -
Ubuntu 인스턴스 내에서 node_exporter 실행
# 1. node_exporter 다운로드 wget https://github.com/prometheus/node_exporter/releases/download/v1.7.0/node_exporter-1.7.0.linux-amd64.tar.gz # 2. 압축 해제 tar xvfz node_exporter-1.7.0.linux-amd64.tar.gz cd node_exporter-1.7.0.linux-amd64 # 3. 익스포터 실행 ./node_exporter -
prometheus.yml파일 수정# ~/openstack-monitoring/prometheus.yml scrape_configs: # ... 기존 설정 유지 ... - job_name: 'vps-instances' static_configs: - targets: ['192.168.35.215:9100']# 192.168.35.215 IP를 가진 인스턴스의 CPU 사용량 확인 100 - (avg by (instance) (irate(node_cpu_seconds_total{instance="192.168.35.221:9100", mode="idle"}[1m])) * 100)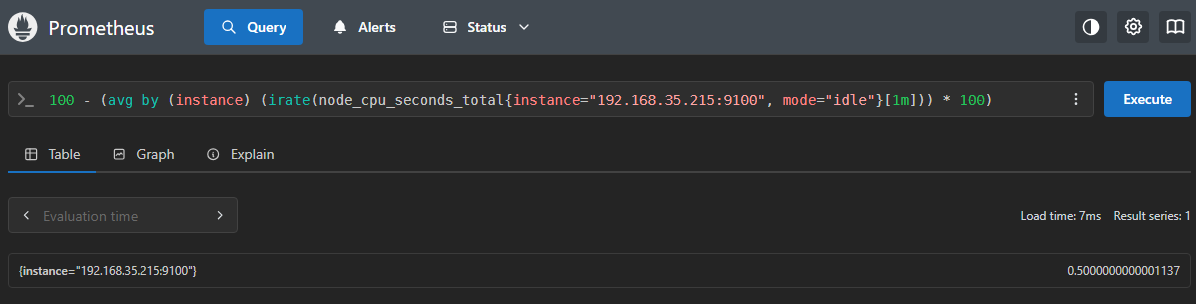
-
Packer를 이용한 모니터링 자동화 이미지 구성
- node_exporter가 설치되고, 인스턴스가 켜지자마자 자동으로 실행되는 골든 이미지를 구성
- 매번 인스턴스 생성 후 수동으로 설정하는 대신, Packer를 사용하여 필요한 환경이 설정된 이미지를 미리 빌드 => 배포 속도 증가 및 환경 일관성 확보
- systemd 서비스 유닛으로 등록해 인스턴스 재부팅 시에도 모니터링이 끊기지 않도록 설정
- CI/CD 파이프라인과 결합하여 인프라 변경 사항을 즉시 이미지에 반영할 수 있는 구조
packer-vps/
├── ubuntu-vps.pkr.hcl # Packer 메인 설정 파일
└── scripts/
└── setup-exporter.sh # node_exporter 설치 및 서비스 등록 스크립트
--------------------------------------------------------------------------
# setup-exporter.sh
#!/bin/bash
set -e
# 1. node_exporter 다운로드 및 배치
export VERSION="1.7.0"
wget https://github.com/prometheus/node_exporter/releases/download/v${VERSION}/node_exporter-${VERSION}.linux-amd64.tar.gz
tar xvfz node_exporter-${VERSION}.linux-amd64.tar.gz
sudo mv node_exporter-${VERSION}.linux-amd64/node_exporter /usr/local/bin/
# 2. systemd 서비스 파일 생성 (인스턴스 시작 시 자동 실행 설정)
sudo tee /etc/systemd/system/node_exporter.service <<EOF
[Unit]
Description=Node Exporter
After=network.target
[Service]
User=root
ExecStart=/usr/local/bin/node_exporter
[Install]
WantedBy=multi-user.target
EOF
# 3. 서비스 활성화
sudo systemctl daemon-reload
sudo systemctl enable node_exporter# ubuntu-vps.pkr.hcl
packer {
required_plugins {
openstack = {
version = ">= 1.0.0"
source = "github.com/hashicorp/openstack"
}
}
}
source "openstack" "ubuntu_vps" {
cloud = "my-openstack"
image_name = "ubuntu-22.04-monitoring-v1"
source_image = "57d47e9f-ff9a-42c9-ad77-2e268989fe9e"
flavor = "m1.small"
network_discovery_cidrs = ["10.0.0.0/24"]
floating_ip_network = "ext_net"
ssh_username = "ubuntu"
volume_size = 10
}
build {
sources = ["source.openstack.ubuntu_vps"]
# 스크립트 실행으로 환경 구성
provisioner "shell" {
script = "scripts/setup-exporter.sh"
}- 인스턴스 내부에 익스포터가 자동으로 설치 및 실행된다.
- 하지만 프로메테우스는 누구에게서 데이터를 가져와야 하는지 모른다.
- 인스턴스를 만들 때마다 prometheus.yml 파일을 열어 IP를 수동으로 등록할 수 없기 때문에
Service Discovery (SD) 설정을 통해 이 과정을 자동화한다.
- 프로메테우스가 주기적으로 오픈스택 API를 호출하여 현재 떠있는 인스턴스 목록을 가져오고, 각 인스턴스의 IP를 자동으로 타겟에 등록하게 한다.
role: instance: 오픈스택의 가상 머신(Nova) 정보를 가져오겠다는 설정identity_endpoint: Keystone API 주소를 입력하여 인증을 수행relabel_configs: 오픈스택 API가 넘겨주는 수많은 정보 중, 실제 접속해야 할 Floating IP(__meta_openstack_public_ip)를 프로메테우스의 수집 주소(__address__)로 변환
- 서버가 몇개로 늘어나든 설정 파일을 수동으로 수정할 필요 없다
- 클라우드의 핵심인 탄력성에 맞춰 인스턴스가 생성 및 삭제 될 때 모니터링 시스템이 즉각적으로 반응
- job_name: 'openstack-vps-sd'
openstack_sd_configs:
- role: instance
region: RegionOne
identity_endpoint: http://192.168.35.100:5000/v3
username: admin
password: WdWx1qAjoRyEUYOOa2XMxuCINHkgjzYjehNI7bmX
project_name: admin
domain_name: Default
relabel_configs:
- source_labels: [__meta_openstack_public_ip]
target_label: __address__
replacement: '${1}:9100'
- source_labels: [__meta_openstack_instance_name]
target_label: instance_name
$ docker restart prometheus - 트러블 슈팅
source_labels: [__meta_openstack_instance_public_ip] => [__meta_openstack_public_ip]
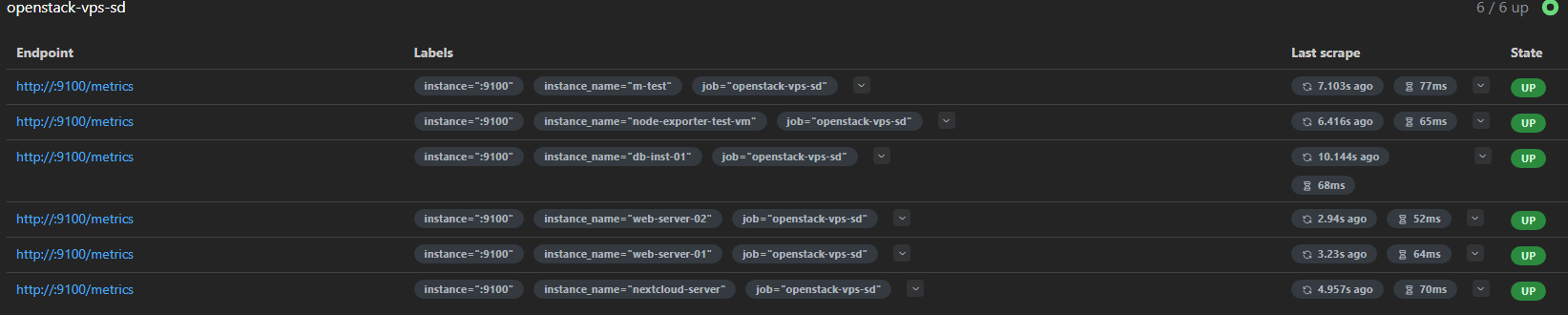
- 오픈스택 서비스 디스커버리 자체는 성공적으로 동작하고 있다.
- 총 6개의 타겟이 잡힌 것으로 보아 생성된 인스턴스 개수와 일치한다.
- 하지만 Endpoint에 각 인스턴스의 IP가 비어있다. =>
relabel_configs에서 참조한 오픈스택 메타데이터 라벨에 값이 비어 있기 때문이다.
- 해결
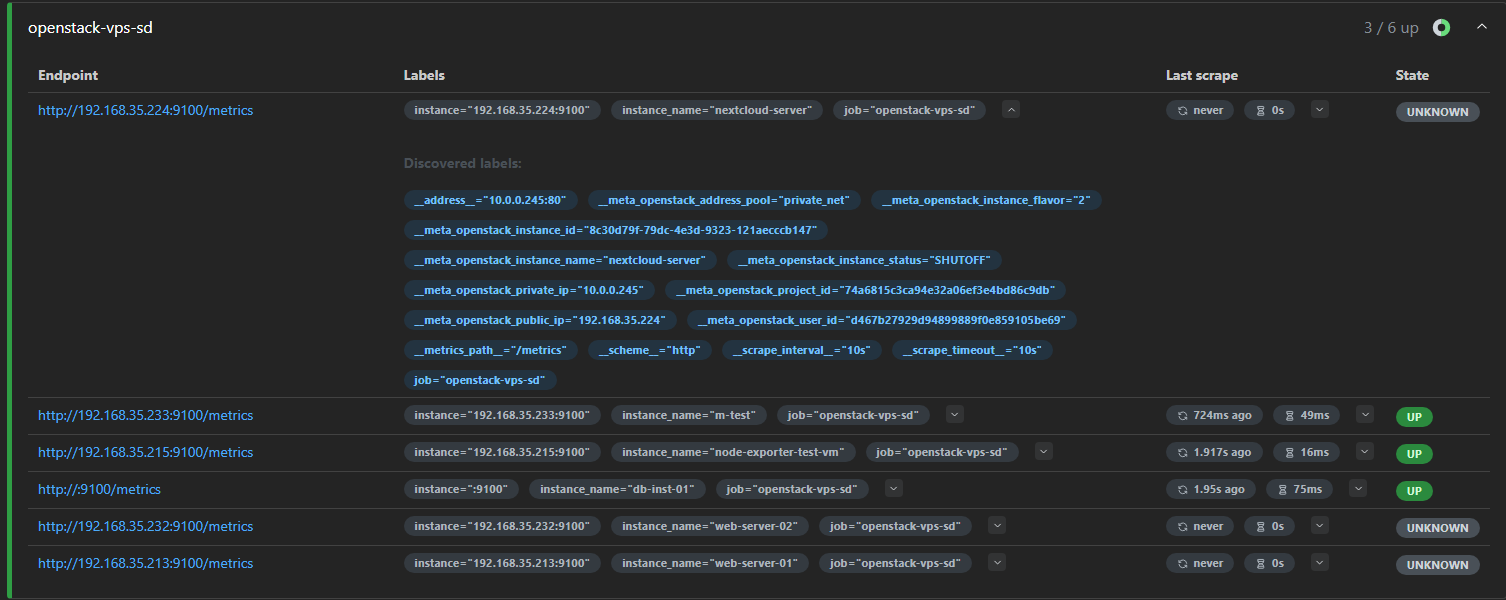
- 프로메테우스 웹UI에서 Status > Target health > openstack-vps-sd 항목에서 Labels 열을 열어 실제 인스턴스 IP가 적혀 있는 라벨을 찾는다.
- 인스턴스의 IP가 적힌 라벨이
__meta_openstack_public_ip임을 확인 및 코드 수정
- 오픈스택 서비스 디스커버리 자체는 성공적으로 동작하고 있다.

UI 대시보드
def get_unified_dashboard_data(self, prometheus_url):
# 오픈스택 인스턴스 정보와 프로메테우스 메트릭 통합
unified_data = []
servers = self.conn.compute.servers()
for server in servers:
fixed_ip = "N/A"
floating_ip = "N/A"
# 모든 네트워크 정보를 돌며 Fixed와 Floating IP를 구분해서 추출
for net_name, addr_list in server.addresses.items():
for addr in addr_list:
if addr.get('OS-EXT-IPS:type') == 'floating':
floating_ip = addr['addr']
elif addr.get('OS-EXT-IPS:type') == 'fixed':
fixed_ip = addr['addr']
cpu_usage = self.get_instance_cpu_usage(prometheus_url, floating_ip)
unified_data.append({
"id": server.id,
"name": server.name,
"status": server.status,
"fixed_ip": fixed_ip,
"floating_ip": floating_ip,
"cpu": cpu_usage,
"created_at": server.created_at
})
return unified_data# flask main.py
from fastapi import FastAPI, HTTPException
from fastapi.middleware.cors import CORSMiddleware
from openstack_driver import OpenStackManager
from fastapi.responses import FileResponse
app = FastAPI(title="KHS Private Cloud Portal")
app.add_middleware(
CORSMiddleware,
allow_origins=["*"],
allow_methods=["*"],
allow_headers=["*"],
)
manager = OpenStackManager()
PROM_URL = "http://192.168.35.100:9090"
@app.get("/")
async def read_index():
return FileResponse('index.html')
@app.get("/api/dashboard")
async def get_dashboard():
try:
data = manager.get_unified_dashboard_data(PROM_URL)
return data
except Exception as e:
raise HTTPException(status_code=500, detail=str(e))
@app.get("/api/instance")
async def create_instance(name: str):
try:
result = manager.create_vps_with_access(
instance_name=name,
network_name="shared_net",
image_name="ubuntu-22.04-monitoring-v1",
flavor_name="m1.small",
key_name="khs-main_keypair"
)
return {"message": "Success", "data": result}
except Exception as e:
raise HTTPException(status_code=500, detail=str(e))---------------------------------------------------------------
$ pip insatll fastapi uvicorn
# Python module 방식으로 서버 실행
$ python -m uvicorn main:app --reload- Data flow
- 프론트엔드에서 사용자가 페이지를 열면 JS가 백엔드 API 호출
- fastapi가 요청을 받으면 OpenstackManager를 통해 오픈스택과 프로메테우스에서 데이터를 가져와 결합
- 트러블 슈팅
# Before Code (get_unified_dashboard_data 함수)
for server in servers:
addresses = server.addresses.get('shared_net', [])
ip = addresses[0]['addr'] if addresses else "N/A"
cpu_usage = self.get_realtime_cpu_usage(prometheus_url, ip)
unified_data.append({
"id": server.id,
"name": server.name,
"status": server.status, # ACTIVE, ERROR, BUILD 등
"ip": ip,
"cpu": cpu_usage,
"created_at": server.created_at
})
# After Code
for net_name, addr_list in server.addresses.items():
for addr in addr_list:
if addr.get('OS-EXT-IPS:type') == 'floating':
floating_ip = addr['addr']
elif addr.get('OS-EXT-IPS:type') == 'fixed':
fixed_ip = addr['addr']addresses[0]['addr']은 네트워크 리스트의 첫 번째 항목인 Fixed IP(내부망)을 가져온다. 하지만 프로메테우스는 Floating IP(외부망)을 기준으로 데이터를 수집하고 있기 때문에 No Data가 뜨는 상황.- 해결 : 오픈스택 SDK의 서버 객체에서
OS-EXT-IPS:type속성을 검사하여 floating 타입의 IP만 골라낸다.
- 해결 : 오픈스택 SDK의 서버 객체에서
server.addresses.items(): 오픈스택 인스턴스에 할당된 모든 네트워크 정보를 담고 있는 딕셔너리.- .items()를 호출하면
{네트워크 이름: [주소 정보 리스트]}형태의 쌍을 반환 fixed (고정 IP): 인스턴스가 생성될 때 가상 네트워크(Neutron)로부터 할당받는 사설 IP. 인스턴스의 실제 vNIC(랜카드)에 설정되는 주소.floating (유동/플로팅 IP): 외부망(Public Network)에서 가져온 공인/외부 IP. 인스턴스에 직접 설정되는 것이 아니라, 오픈스택의 L3 가상 라우터에서 1:1 NAT 방식으로 Fixed IP와 매핑.
- .items()를 호출하면
{
"shared_net": [
{
"addr": "172.20.0.141",
"version": 4,
"OS-EXT-IPS-MAC:mac_addr": "fa:16:3e:xx:xx:xx",
"OS-EXT-IPS:type": "fixed"
},
{
"addr": "192.168.35.221",
"version": 4,
"OS-EXT-IPS-MAC:mac_addr": "fa:16:3e:xx:xx:xx",
"OS-EXT-IPS:type": "floating"
}
],
"another_net": [...]
}멀티 테넌시 구상
- 유저별 격리 및 대시보드 구성 전략 (멀티 테넌시 / 유저별로 자신만의 사용량만 볼 수 있도록)
- 오픈스택 테넌트(Project) 기반 격리
- 오픈스택 API 호출 시 project_id를 기준으로 필터링하면 사용자 1은 자신의 프로젝트에 속한 인스턴스 리스트만 가져오게 된다. get_unified_dashboard_data 함수에서 사용 중인 토큰의 권한에 따라 이 데이터 범위가 자동으로 결정된다.
- 프로메테우스 메트릭의 Label링
- Service Discovery 설정에서 relabel_configs를 조금 더 확장하면, 프로메테우스 수집 데이터에 project_id 혹은 user_id 라벨을 강제로 붙일 수 있다.
- 특정 유저의 데이터만 집어서 가져와 대시보드에 뿌려줄 수 있다.
- 오픈스택 테넌트(Project) 기반 격리
- 핵심 원리
- 사용자 인증 (Keystone) : 로그인 시 사용자별로 각기 다른 Project ID를 할당받는다.
- 데이터 필터링 : 백엔드 API에서 오픈스택 데이터를 가져올 때, 현재 로그인한 유저의 Project ID에 속한 자원만 조회하도록 쿼리한다.
- 네트워크 격리 : 사용자별로 별도의 가상 네트워크(VNI가 다름)를 생성해주면, 내부망 IP가 겹쳐도 물리적인 통신은 VXLAN 터널을 통해 분리된다.
멀티 테넌시 기반 인스턴스 생성 모달
# sqlite3를 사용해서 간단한 DB 구성
def init_db():
conn = sqlite3.connect('cloud_portal.db')
cursor = conn.cursor()
cursor.execute('''
CREATE TABLE IF NOT EXISTS users (
id INTEGER PRIMARY KEY AUTOINCREMENT,
username TEXT UNIQUE, # 로그인 ID
project_id TEXT, # 오픈스택 내 테넌트(Project)의 UUID, 자원 격리의 단위
network_id TEXT, # 해당 사용자가 사용할 VXLAN 기반 가상 네트워크의 ID
# 이 ID가 다르면 같은 IP 대역을 써도 패킷이 VNI로 격리된다
project_name TEXT
)
''')
conn.commit()
conn.close()-
오픈스택에서 네트워크를 생성할 때
--share옵션을 주면 모든 프로젝트가 해당 네트워크를 볼 수 있고 인스턴스를 연결할 수 있다. 옵션을 주지 않으면 해당 네트워크를 만든 프로젝트(default admin) 내부에서만 보이고 사용 가능하다. -
각 프로젝트의 네트워크가 같은 대역을 사용하더라도, 물리적인 전송 단계에서는 서로 다른 VNI(VXLAN Network Identifier) 태그가 붙어 캡슐화된다.
-
L3 물리 망에서는 충돌이 일어나지 않고, 각 프로젝트의 가상 라우터가 이를 독립적으로 처리한다.
-
멀티 테넌시 테스트를 위해 Project_A라는 별도의 프로젝트를 만들고, 프로젝트 내에서 네트워크와 서브넷을 생성
# 새로운 프로젝트 생성 openstack project create --domain Default Project_A # 프로젝트 전용 네트워크 생성 (--project 옵션 사용) openstack network create --project Project_A Net_A # 서브넷 생성 (IP 대역 설정) openstack subnet create --project Project_A --network Net_A --subnet-range 10.0.0.0/24 Subnet_A # 네트워크 확인 openstack network show Net_A
# 유저별 인스턴스 생성을 위한 유저 목록 반환 API
# main.py
@app.get("/api/users")
async def get_users():
try:
conn = sqlite3.connect(DB_PATH)
conn.row_factory = sqlite3.Row
cursor = conn.cursor()
users = cursor.execute('SELECT username, project_name FROM users').fetchall()
conn.close()
return [dict(u) for u in users]
except Exception as e:
raise HTTPException(status_code=500, detail=str(e))- 트러블 슈팅
배포 실패: OpenStackManager.create_vps_with_access() got an unexpected keyword argument 'network_id'- create_vps_with_access 메서드의 파라미터 이름을 network_id로 업데이트
- network_name 대신
network_id를 쓰는 이유- 중복 방지 : shared_net 같은 이름은 여러 프로젝트에서 중복해서 사용할 수 있다. 하지만 UUID(ID)는 유일하다.
- VXLAN 매핑 : DB에 저장한 network_id는 오픈스택 내부에서 특정 VNI(VXLAN Network ID)와 1:1로 매핑되어 있다. 이름을 쓰면 엉뚱한 네트워크에 붙을 수 있지만, ID를 쓰면 정확히 해당 사용자의 격리된 터널로 패킷을 보내게 된다.
- create_vps_with_access 함수 수정
self.conn.network.networks(name=network_name)에서 network_name 변수 사용- 불필요한 네트워크 검색 : 이미 network_id (UUID)를 파라미터로 받았으므로, 이름을 통해 다시 ID를 찾을 필요가 없다.
- fip_addr 변수가 if ext_nets: 블록 안에서만 생성되는데, 마지막 return에서 사용되고 있어 조건이 맞지 않을 경우 UnboundLocalError가 발생할 수 있다.
def create_vps_with_access(self, instance_name, network_id, image_name, flavor_name, key_name):
# 인스턴스 생성 후 접속용 Floating IP까지 자동 매핑
try:
# 자원 찾기
image = self.conn.compute.find_image(image_name)
flavor = self.conn.compute.find_flavor(flavor_name)
# network_name 검색 제거 (이미 network_id를 파라미터로 받음)
# 보안 그룹 생성
sg_name = f"{instance_name}-sg"
sg = self.create_security_group_with_rules(sg_name)
# 서버 생성
server = self.conn.compute.create_server(
name=instance_name,
image_id=image.id,
flavor_id=flavor.id,
networks=[{"uuid": network_id}], # 전달받은 network_id 사용
key_name=key_name,
security_groups=[{"name": sg.name}]
)
# ACTIVE 상태 대기
server = self.conn.compute.wait_for_server(server)
# Floating IP 처리 초기화
fip_addr = "N/A"
ext_nets = list(self.conn.network.networks(name="ext_net"))
if ext_nets:
ports = list(self.conn.network.ports(device_id=server.id))
if ports:
port_id = ports[0].id
fip = self.conn.network.create_ip(
floating_network_id=ext_nets[0].id,
port_id=port_id
)
fip_addr = fip.floating_ip_address
# Fixed IP 추출 (네트워크 이름을 몰라도 첫 번째 사설 IP를 가져옴)
fixed_ip = "N/A"
for net_addresses in server.addresses.values():
for addr in net_addresses:
if addr.get('OS-EXT-IPS:type') == 'fixed':
fixed_ip = addr['addr']
break
return {
"instance_id": server.id,
"fixed_ip": fixed_ip,
"floating_ip": fip_addr
}
except Exception as e:
print(f"[Internal Error] {e}")
raise e배포 실패: NotFoundException: 404: Client Error for url: http://192.168.35.200:9696/v2.0/floatingips, External network 68dcfc55-ed46-4462-85f9-6eee681702c8 is not reachable from subnet 3449ea8c-0cb2-49a3-86a5-ff25e85cc433. Therefore, cannot associate Port 7a7958f0-68f2-4d52-80ac-87d38770d614 with a Floating IP.- 해석 : Private subnet은 잘 만들어졌으나 외부로 나가는 External Network까지 가는 Router가 연결되어 있지 않아 Floating IP를 연결할 수 없다.
- => 오픈스택 내부의 가상 라우터가 사설망과 외부망 사이을 연결하지 못하고 있다.
- Project_A라는 별도의 프로젝트 생성 후, 프로젝트 내에서 네트워크와 서브넷은 생성했지만 라우터는 만들지 않았었다.
- 해결
# Router 생성 및 외부망을 게이트웨이로 설정하고, 사설 서브넷을 인터페이스로 추가 openstack router create khs-router # 라우터 생성 openstack router set --external-gateway ext_net khs-router # 외부망 연결 openstack router add subnet khs-router 3449ea8c-0cb2-49a3-86a5-ff25e85cc433 # 인터페이스 추가- 오픈스택의 Neutron 아키텍처에서 사설망과 외부망은 완전히 격리되어 있다.
- Fixed IP : 내부 통신용으로 br-int 브릿지 내에서만 유효
- Floating IP : 외부 통신용으로 br-ex 브릿지를 통해 나간다
- L3 Agent (Router) : 두 브릿지 사이에서 NAT를 수행하며 패킷을 전달
- 해석 : Private subnet은 잘 만들어졌으나 외부로 나가는 External Network까지 가는 Router가 연결되어 있지 않아 Floating IP를 연결할 수 없다.
- 인스턴스가 생성되기는 하나, admin 프로젝트에서만 생성된다.
- 원인 : 현재 OpenStackManager의 연결(self.conn)이 admin 권한의 세션으로 고정되어 있기 때문이다. 오픈스택 SDK에서 자원을 생성할 때 별도의 프로젝트 설정을 하지 않으면, 현재 로그인 되어 있는 프로젝트(Default admin)에 자원이 할당된다.
- 해결 : 멀티 테넌시 구현을 위해 admin 권한을 사용하되 인스턴스 생성 요청을 대상 프로젝트의 ID(
project_id)로 명시하거나 해당 프로젝트의 스코프를 변경한 연결을 사용
# main.py
@app.post("/api/instances")
async def create_instance(name: str, username: str):
...
try:
result = manager.create_vps_with_access(
instance_name=name,
project_id=user['project_id'], # DB에서 가져온 project_id 추가
network_id=user['network_id'],
image_name="ubuntu-22.04-monitoring-v1",
flavor_name="m1.small",
key_name="khs-main-keypair"
)
'''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''
# openstack_driver.py
# self.conn 부분을 target_conn. 으로 변경하여 자원 생성의 주체를 해당 프로젝트로 명시
def create_vps_with_access(self, instance_name, project_id, network_id, image_name, flavor_name, key_name):
try:
target_conn = self.conn.connect_as(project_id=project_id)
print(f"[*] 프로젝트 스코핑 완료: {project_id}")
image = target_conn.compute.find_image(image_name)
flavor = target_conn.compute.find_flavor(flavor_name)
if not image or not flavor:
raise Exception("이미지 또는 플래버를 찾을 수 없습니다.")
sg_name = f"{instance_name}-sg"
sg = self.create_security_group_with_rules_in_project(target_conn, sg_name)
print(f"[*] 인스턴스 생성 시작: {instance_name} (Network: {network_id})")
server = target_conn.compute.create_server(
name=instance_name,
image_id=image.id,
flavor_id=flavor.id,
networks=[{"uuid": network_id}],
key_name=key_name,
security_groups=[{"name": sg.name}]
)
...
def create_security_group_with_rules_in_project(self, target_conn, sg_name):
...- Keystone Scope :
target_conn은 내부적으로 "이 프로젝트의 자격으로 일하겠다"는 토큰을 발급받는다. 이 토큰을 사용하면 생성되는 모든 객체의 project_id 필드가 자동으로 채워진다. - admin 프로젝트가 아닌 각 유저의 프로젝트가 인스턴스와 보안 그룹의 소유주(Owner)가 된다.
- Floating IP Quota : 각 테넌트별로 할당된 Floating IP 쿼터가 개별적으로 적용된다. 만약 admin에 몰아서 만든다면 admin 쿼터가 부족해졌겠지만, 사용자별로 분산 관리된다.
- OVS Flow : 인스턴스가 생성될 때, target_conn을 통해 지정된 network_id에 연결되므로 Open vSwitch(OVS)는 해당 VM의 패킷을 처리할 때 해당 프로젝트 전용의 VNI(VXLAN Network ID)를 사용하게 된다.
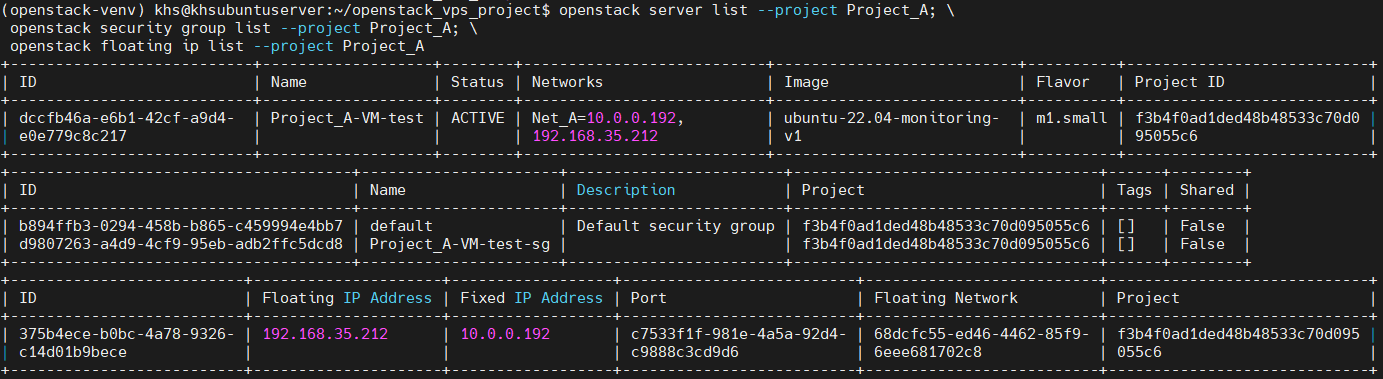
대시보드에서 프로젝트(유저)별로 사용중인 인스턴스 확인할 수 있도록 수정
- 관리 효율성 : 특정 프로젝트에서 이상 트래픽 및 높은 리소스 사용량이 발생했을 때, 어떤 유저의 소유인지 파악 가능
- 사용자 A가 만든 인스턴스는 사용자 A의 프로젝트 ID를 가지고 있어야 하며, 이를 UI에서 확인해 멀티 테넌시가 잘 작동하고 있음을 확인
get_dashboard함수 수정 : 오픈스택에서 가져온 인스턴스의project_id를 DB에 등록된username으로 치환하여 프론트엔드에 전달
# main.py
@app.get("/api/dashboard")
async def get_dashboard():
try:
# DB에서 모든 유저 정보 가져오기 (매핑용)
conn = sqlite3.connect(DB_PATH)
conn.row_factory = sqlite3.Row
db_users = conn.execute('SELECT username, project_id, project_name FROM users').fetchall()
conn.close()
user_map = {u['project_id']: u['username'] for u in db_users}
project_name_map = {u['project_id']: u['project_name'] for u in db_users}
# 오픈스택에서 모든 프로젝트의 인스턴스 가져오기
all_instances = manager.get_unified_dashboard_data(PROM_URL)
# 인스턴스 데이터에 유저 정보 입히기
for inst in all_instances:
p_id = inst.get('project_id')
inst['owner'] = user_map.get(p_id, "Unknown")
inst['project_display_name'] = project_name_map.get(p_id, "Admin/Other")
return all_instances
except Exception as e:
raise HTTPException(status_code=500, detail=str(e))# openstack_driver.py
def get_unified_dashboard_data(self, prometheus_url):
try:
# all_projects=True 옵션을 주어야 다른 프로젝트의 인스턴스가 보인다.
instances = list(self.conn.compute.servers(all_projects=True))
...
# 반환 데이터에 project_id가 포함되어야 함
dashboard_data = []
for server in instances:
dashboard_data.append({
"instance_id": server.id,
"name": server.name,
"status": server.status,
"project_id": server.project_id, #
"fixed_ip": self._get_fixed_ip(server),
"floating_ip": self._get_floating_ip(server),
"cpu": self._get_cpu_metric(server.id, prometheus_url)
...인스턴스 삭제 기능
- 인스턴스 ID를 받아 해당 인스턴스가 속한 프로젝트를 찾아가 삭제
- connect_as를 사용하여 해당 프로젝트의 컨텍스트에서 작업을 수행
- 클라우드 자원 간의 의존성을 고려해 floating ip -> 인스턴스 -> 대기 -> 보안그룹 순으로 삭제
# openstack_driver.py
def delete_instance(self, instance_id):
try:
server = self.conn.compute.get_server(instance_id)
project_id = server.project_id
instance_name = server.name
sg_name = f"{instance_name}-sg"
target_conn = self.conn.connect_as(project_id=project_id)
# floating IP 정리
ports = list(target_conn.network.ports(device_id=instance_id))
for port in ports:
fips = list(target_conn.network.ips(port_id=port.id))
for fip in fips:
print(f"Floating IP 제거 중 : {fip.floating_ip_address}")
target_conn.network.delete_ip(fip.id)
# 인스턴스 삭제
print(f"인스턴스 삭제 요청 : {instance_id}")
target_conn.compute.delete_server(instance_id)
# 보안그룹 삭제 전 인스턴스 삭제 대기
target_conn.compute.wait_for_delete(server, wait=25)
# 보안그룹 삭제
sg = target_conn.network.find_security_group(sg_name)
if sg:
print(f"인스턴스와 연결된 보안그룹 삭제 중 : {sg_name}")
target_conn.network.delete_security_group(sg.id)
print("[ 모든 자원 정리 완료] ")
return True
except Exception as e:
print(f"인스턴스 삭제 오류 : {e}")
raise e
''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''
# main.py
@app.delete("/api/instances/destroy/{instance_id}")
async def delete_instance(instance_id: str):
try:
manager.delete_instance(instance_id)
return {"status": "success", "message": "Instance deletion complete"}
except Exception as e:
raise HTTPException(status_code=500, detail=str(e))
신규 유저 등록에 필요한 프로젝트/네트워크/라우터/키페어 설정 자동화
- Project -> Network -> Subnet -> Router -> Interface & Gateway 설정
setup_tenant_infrastructure함수- 각 유저에게 동일한 10.0.0.0/24 대역을 주더라도, VXLAN VNI와 Project ID로 격리되어 충돌이 발생하지 않음을 보여준다.
- 트러블 슈팅: admin 외의 프로젝트에서 생성된 인스턴스는 프로메테우스 메트릭 수집이 되지 않는다.
- 원인 : 프로메테우스는 admin 프로젝트를 기준으로 메트릭을 수집하고 있기 때문에 다른 프로젝트는 존재하지 않는 것으로 간주한다.
- 해결 : prometheus.yml 파일을 수정해 오픈스택의 모든 프로젝트 내의 인스턴스를 자동으로 타겟에 등록하도록 설정
- public_ip를 쓰는 이유 : VXLAN은 프로젝트 간의 트래픽을 차단한다. Private IP를 수집할 경우 프로메테우스 서버가 각 프로젝트의 가상 네트워크 안으로 일일이 들어갈 수 없으므로 불가능하다.
멀티 테넌시 환경에서의 메트릭 수집은 프로메테우스 서버가 외부 네트워크에 할당된 인스턴스의 Floating IP 주소를 수집 엔드포인트로 식별하여 요청을 전송하는 방식으로 이루어진다.
해당 트래픽은 각 테넌트 프로젝트 가상 라우터의 목적지 네트워크 주소 변환(DNAT)를 거쳐 인스턴스의 Fixed IP로 라우팅된다. 이는 L3 계층에서 네트워크 격리를 유지하며 외부 관제 시스템과 통신을 보장한다.
# prometheus.yml
- job_name: 'openstack-vps-sd'
openstack_sd_configs:
- role: instance
region: RegionOne
identity_endpoint: http://192.168.35.100:5000/v3
username: admin
password:
project_name: admin
all_tenants: true # <------------
domain_name: Default
relabel_configs:
- source_labels: [__meta_openstack_public_ip]
target_label: __address__
replacement: '${1}:9100'
- source_labels: [__meta_openstack_instance_name]
target_label: instance_name
- source_labels: [__meta_openstack_instance_id]
target_label: openstack_instance_id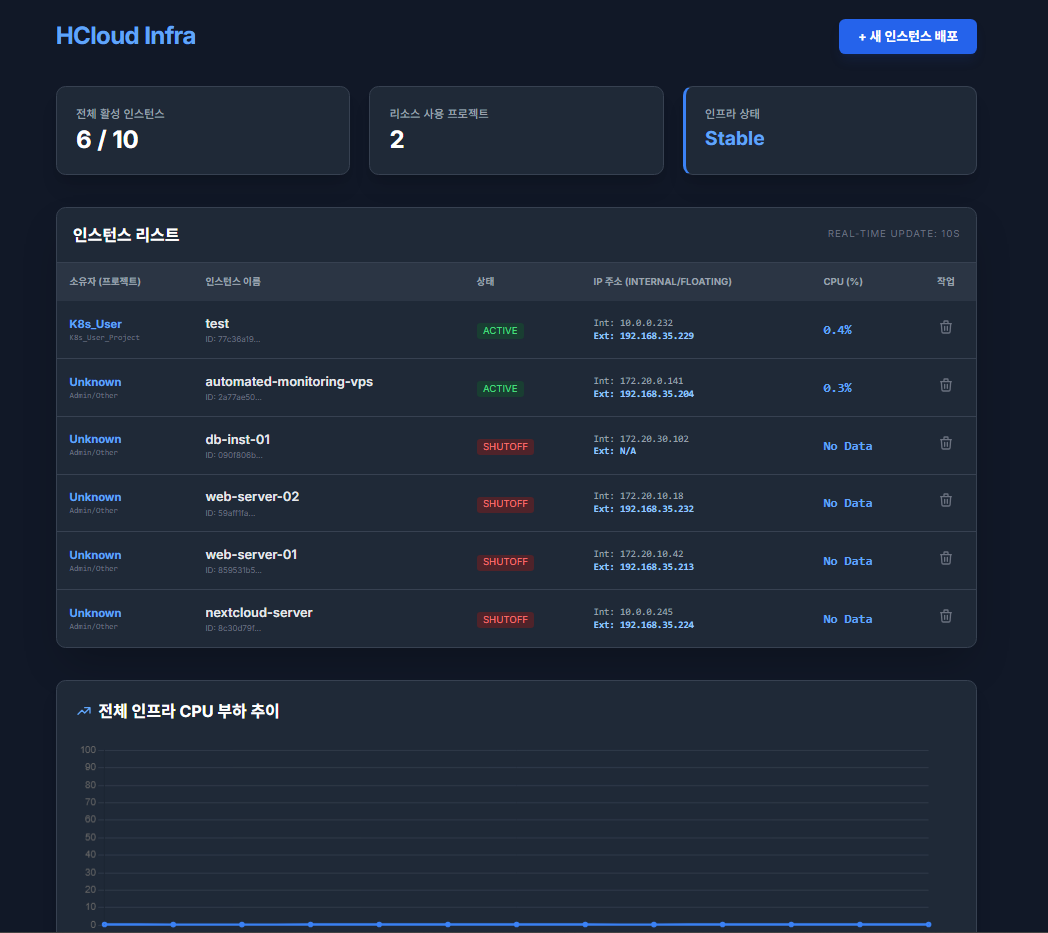
외부에서 대시보드 접속 [Cloudflare Tunnel 연동]
-
이미 노트북에 설치되어 있는 Cloudflare Tunnel을 사용하여 외부에서도 대시보드에 접속할 수 있게 한다.
- 프로젝트 도커 컨테이너화
# main.py 수정 # *.khs-server.cloud 외부 도메인을 통해 접속한 브라우저가 대시보드 안의 API를 호출할 때, # 보안상의 이유로 브라우저가 차단하는 것을 방지하기 위해 CORS 설정 업데이트 app.add_middleware( CORSMiddleware, allow_origins=[ "https://hcloud.khs-server.cloud", "http://localhost:8000", # 로컬 테스트용 "http://localhost:8070", "http://192.168.35.100:8070" ], allow_credentials=True, allow_methods=["*"], allow_headers=["*"], )# dockerfile FROM python:3.10-slim WORKDIR /app RUN apt-get update && apt-get install -y sqlite3 && rm -rf /var/lib/apt/lists/* COPY requirements.txt . RUN pip install --no-cache-dir -r requirements.txt COPY . . CMD ["python", "-m", "uvicorn", "main:app", "--host", "0.0.0.0", "--port", "8070", "--proxy-headers"]# docker-compose.yaml services: hcloud-dashboard: image: hcloud-dashboard:latest container_name: hcloud-portal network_mode: "host" volumes: - ./cloud_portal.db:/app/cloud_portal.db # 로컬 DB 파일 컨테이너와 동기화 - ~/.config/openstack:/root/.config/openstack:ro # Openstack 인증 파일 마운트 environment: - TZ=Asia/Seoul restart: always -
트러블 슈팅
docker compose up -d --build Dockerfile:5 -------------------- 3 | WORKDIR /app 4 | 5 | >>> RUN apt-get update && apt-get install -y sqlite3 && rm -rf /var/lib/apt/lists/* 6 | 7 | COPY requirements.txt . -------------------- failed to solve: process "/bin/sh -c apt-get update && apt-get install -y sqlite3 && rm -rf /var/lib/apt/lists/*" did not complete successfully: network bridge not found- 원인 : RUN apt-get update 단계에서 빌드 컨테이너가 외부 저장소 서버와 통신하지 못했기 때문에 발생
- 기본적으로 Docker 빌드는 독립된 Bridge Network 환경에서 진행된다.
- Docker 데몬이 컨테이너를 빌드할 때 사용할 가상 네트워크 브릿지(docker0)를 찾지 못해서 발생
- 이 환경에서는 Docker가 자체적인 가상 네트워크 인터페이스와 호스트의 통신을 중계(NAT)하며, 별도의 DNS 설정을 가진다.
- 기본 빌드 모드에서는 호스트이 네트워크 설정(ex. /etc/resolv.conf의 DNS 설정 등)이 컨테이너 내부로 완벽하게 전송되지 않을 수 있다. 특히 호스트가 복잡한 네트워크 구성을 사용할 경우, Docker 브리지 망의 MTU 값 차이나 라우팅 규칙 충돌로 인해 패킷이 유실되어 인터넷이 끊길 수 있다.
- 해결
docker build --network=host -t hcloud-dashboard . docker compose up -d --build- 빌드 시
--network=host를 사용하면 빌드 컨테이너가 Docker의 가상 네트워크 브리지를 생성하지 않고, 호스트의 네트워크 스택(Network Stack)을 그대로 공유한다. - 컨텐이너가 호스트와 동일한 IP 주소와 네트워크 환경을 직접 사용하게 되므로 호스트에서 인터넷이 된다면 빌드 과정에서도 물리적인 네트워크 제약 없이 인터넷 연결이 가능해진다.
- 빌드 시
- docker compose에서 network_mode: "host"가 필요한 이유
- Docker Compose가 컨테이너를 실행하기 위해 새로운 가상 네트워크(브릿지)를 만들려고 시도하는데,
network_mode: "host"를 설정하면 컨테이너 내부 프로세스가 호스트의 네트워크 네임스페이스에서 실행된다. 즉, 컨테이너 내의 FastAPI가 localhost:9090(Prometheus)을 호출하면 별도의 포트 포워딩 없이 호스트의 9090 포트로 직접 연결된다.
- Docker Compose가 컨테이너를 실행하기 위해 새로운 가상 네트워크(브릿지)를 만들려고 시도하는데,
- 원인 : RUN apt-get update 단계에서 빌드 컨테이너가 외부 저장소 서버와 통신하지 못했기 때문에 발생
외부에서 인스턴스에 SSH로 연결할 수 있도록 구성 (방법 2 사용)
방법 1 :
Apache Guacamole를 이용해서 외부 사용자가 별도의 설정없이 브라우저에서 SSH 접속
=> 외부 사용자 -> ssh.khs-server.cloud(HTTPS) -> Guacamole -> 인스턴스(SSH)
=> 원리 : Guacamole 웹 페이지 접속 -> 웹 브라우저와 Guacamole 서버는 WebSocket으로 통신 -> 서버 내부의 guacd라는 프로세스가 실제로 인스턴스에 SSH 접속을 수행 -> guacd가 받은 터미널 화면 정보를 Guacamole 웹 서버가 랜더링
=> 장점 : 사용자가 SSH 클라이언트 없고, 인스턴스의 IP를 직접 노출하지 않아도 된다.
방법 2 :Cloudflare Tunnel (Zero Trust / Warp)
=> 장점 : 이미 호스트 노트북에 컨테이너로 떠있는 터널을 활용할 수 있다. / L4 트래픽 터널링 기술 이해
=> 단점 : 외부 사용자도 cloudflare warp를 설치해야 한다.
방법 3 :Tailscale을 설치하고, Subnet Router 기능을 활성화
=> 외부 사용자가 Tailscale 망에 초대되어 접속하고 인스턴스 floating IP로 직접 SSH 접속
=> 장점 : 네트워크 복잡도가 낮고, 모든 포트를 한 번에 개방할 수 있다.
- 외부 사용자가 인스턴스에 SSH 연결을 할 수 있도록 유저마다 전용 키페어를 생성 후 DB에 저장
- 해당 키페어를 인스턴스 생성 시 적용
- 키페어를 로컬에 저장하고 다운받을 수 있도록 대시보드 변경
- Cloudflare Warp를 이용해 외부에서 인스턴스에 SSH로 연결할 수 있도록 구성
- 외부에서 인스턴스 연결 테스트는 스마트폰 핫스팟에 연결된 노트북으로 진행
- 집 와이파이 사용 시 내부망으로 가기 때문에 당연히 인스턴스에 SSH로 연결 가능
- 집 와이파이 사용 시 내부망으로 가기 때문에 당연히 인스턴스에 SSH로 연결 가능
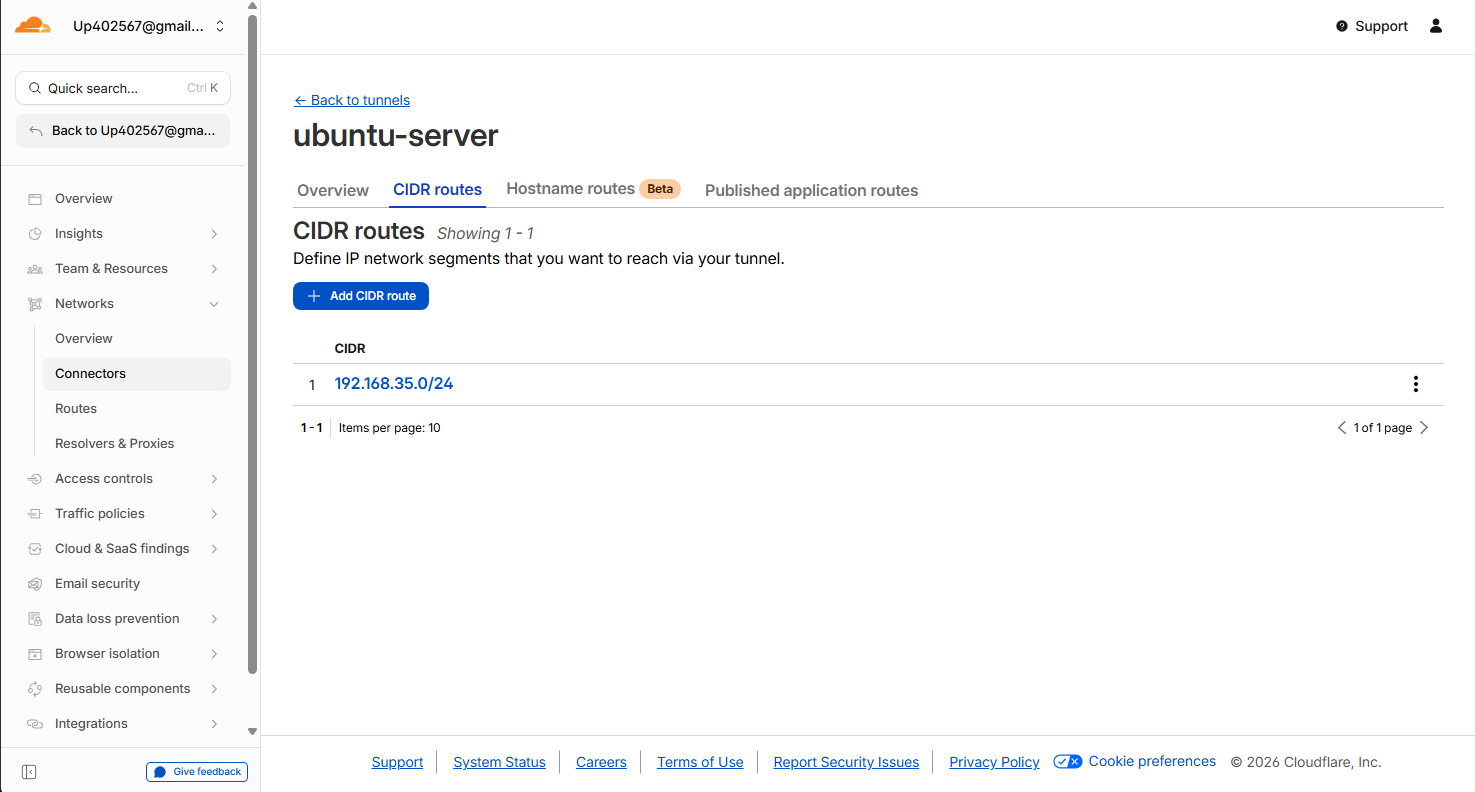
- cloudflare Zero Trust > Networks > Connectors > 생성해 놓은 터널 > CIDR routes에 IP 대역 등록
- =>
Private Network Routing기능 활성화- Layer 3 가상 라우팅 : 기본적으로 Cloudflare Tunnel은 특정 도메인(L7)을 연결하는 용도이다. 하지만 사용자가 WARP를 통해 IP 주소(192.168.35.x)로 직접 SSH 접속을 하려면 Cloudflare 인프라가 이 사설 IP 주소로 가는 트래픽을 어떤 터널로 보내야 하는가?를 알아야 한다.
- Gateway 알림 : CIDR routes에 해당 대역을 등록하면, Cloudflare Gateway는 전 세계 어디서든 WARP 사용자가 192.168.35.0/24 주소로 패킷을 보내면 이를 내 팀에 등록된 특정 cloudflared 커넥터(사용자의 노트북)로 전달하라는 라우팅 정보를 갖게 된다.
- CIDR routes 등록이 없으면 안 되는 이유
- 경로 부재 : 이 설정이 없으면 외부 사용자가 WARP를 켜고 192.168.35.207로 SSH 접속을 시도할 때 패킷은 Cloudflare Edge에서 길을 잃는다. 해당 IP가 어느 터널에 연결된 것인지 정보가 없기 때문이다.
- WARP Split Tunnel 동작 : WARP 클라이언트는 대시보드에 등록된 CIDR 정보를 기반으로, 특정 트래픽을 가로채서 터널로 보낼지 결정한다. 등록되지 않은 대역은 로컬 네트워크로 판단하여 터널을 타지 않는다.
- 외부에서 인스턴스 연결 테스트는 스마트폰 핫스팟에 연결된 노트북으로 진행
-
외부 사용자 세팅
- 1.1.1.1에서 Cloudflare WARP 설치 및 실행
- 설정 > 계정 > Cloudflare Zero Trust로 로그인 > 팀 이름 입력
- 자동으로 열린 웹 페이지에서 관리자가 등록해 놓은 이메일 입력 후 6자리 PIN 번호 입력
- 성공시 Success가 뜨고 스위치가 사진과 같이 파란색으로 뜨면 연결 성공

-
트러블 슈팅 (=관리자 세팅 과정)
-
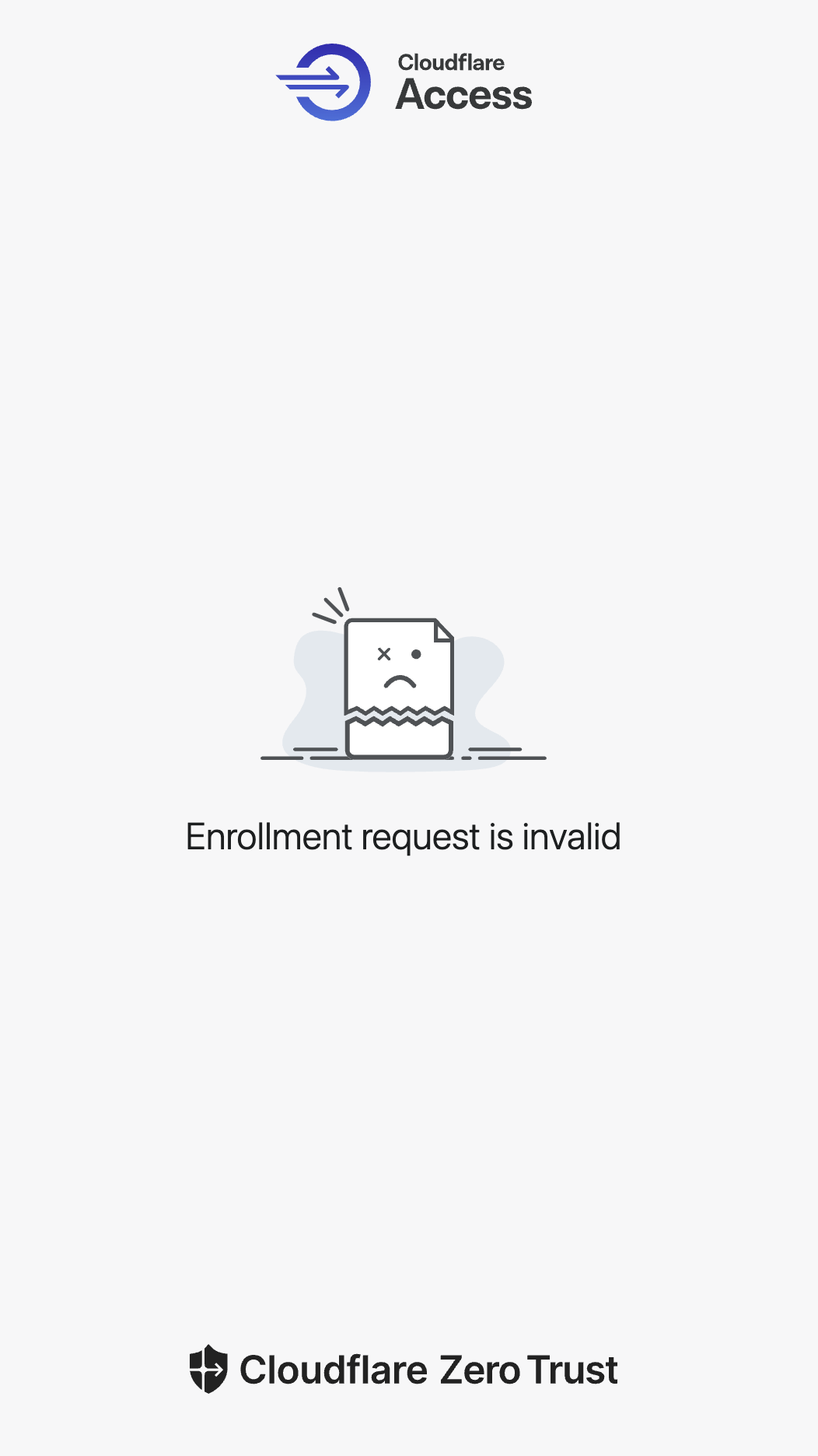
외부 사용자가 cloudflare Warp에 팀 이름을 입력했을 때 이메일 입력 폼이 뜨지 않고, 사진처럼
enrollment request is invalid에러 페이지가 뜬다.- 원인 : 누가 이 팀에 가입할 수 있는지에 대한 규칙이 설정되지 않았기 때문에 발생
- 아래에 해결하는 과정을 작성
- 아래에 해결하는 과정을 작성
- 원인 : 누가 이 팀에 가입할 수 있는지에 대한 규칙이 설정되지 않았기 때문에 발생
-
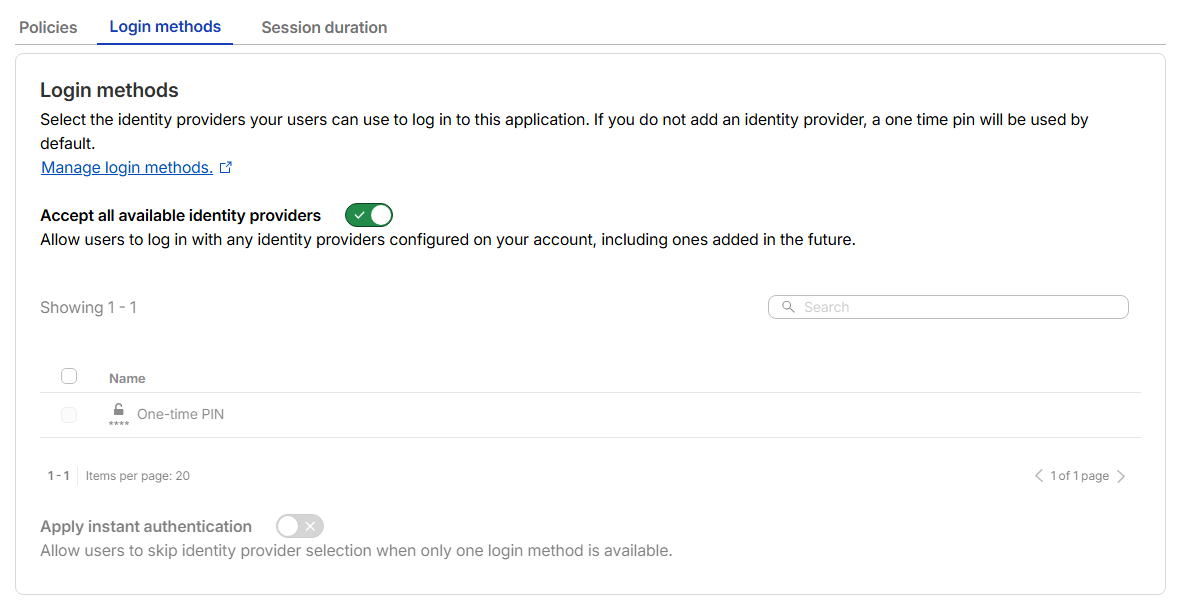
로그인 방식 확인 (사용자들이 어떤 방식으로 인증할지 결정 : 이메일 OTP 방식 사용)
Zero Trust - Access controls - Access settings - Login methodsOne-time PIN(이메일 OTP) 등록 후 선택
-
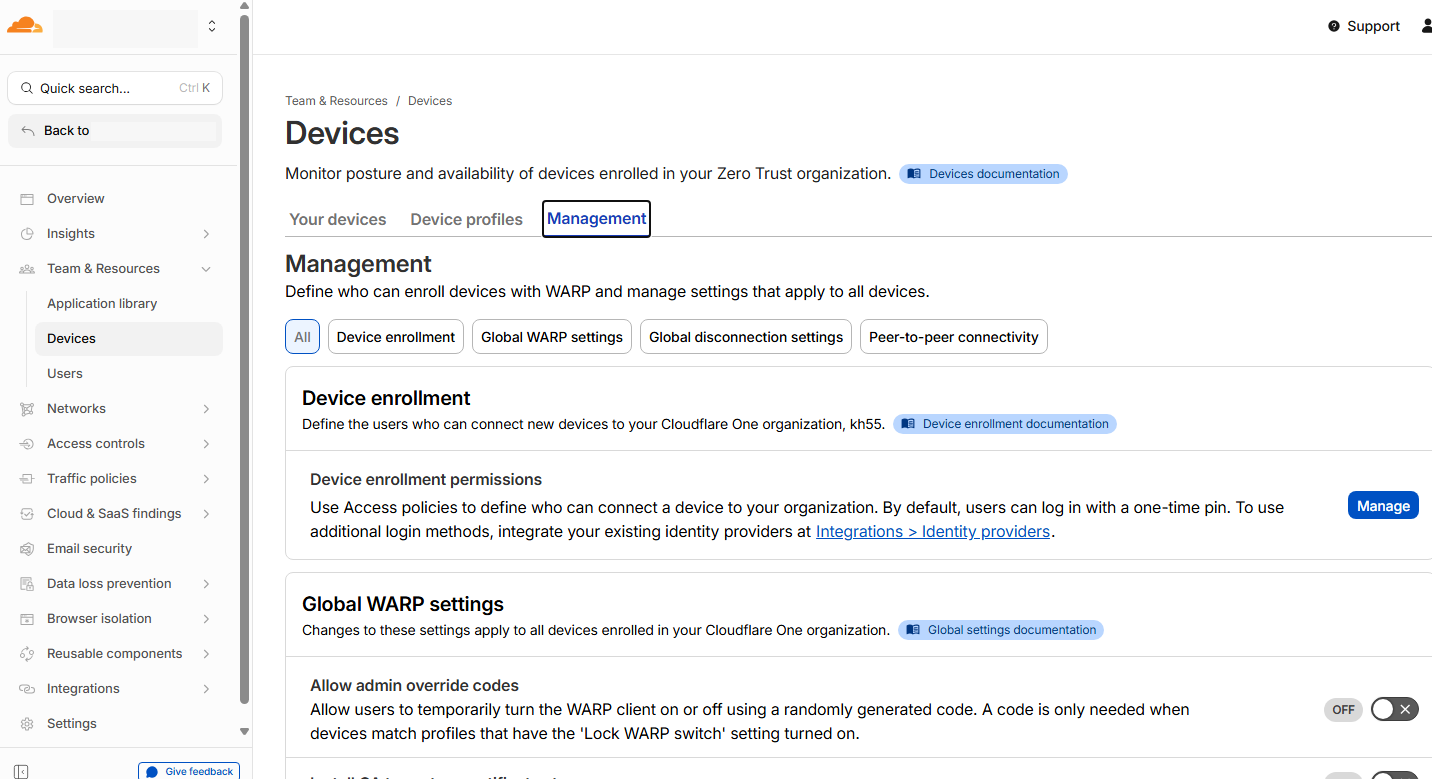
기기 등록 정책(Device Enrollment) 생성
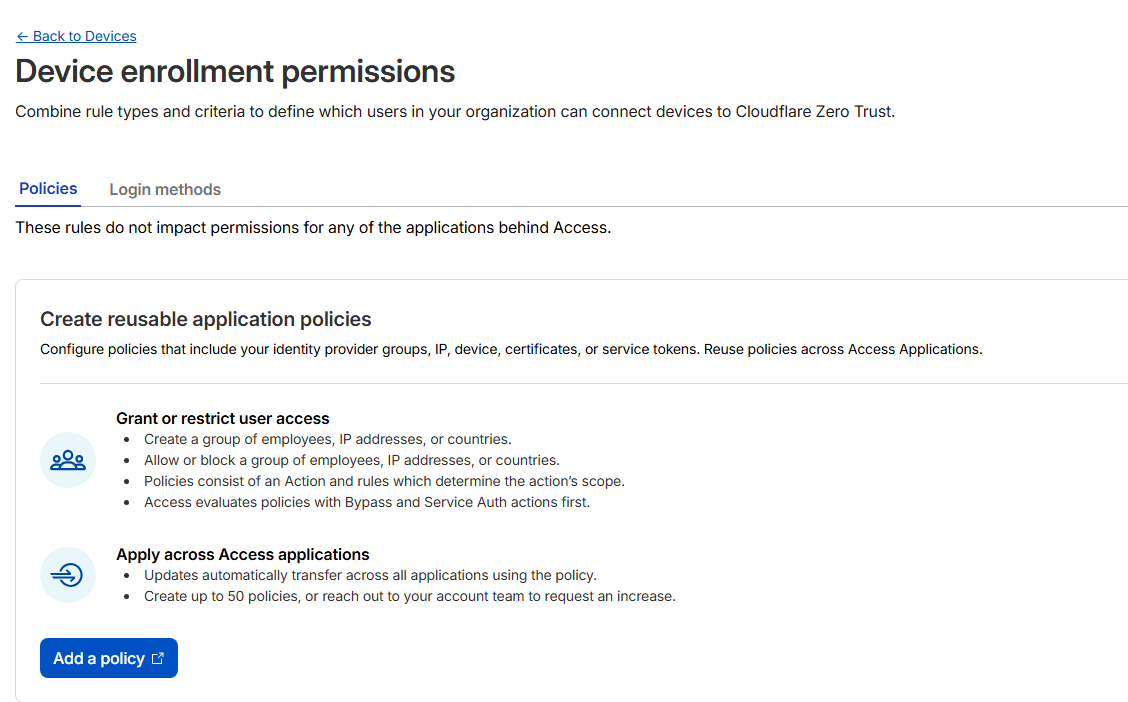
- 팀에 등록할 수 있는 규칙을 정하는 단계
Zero Trust - Team & Resources - Devices - Management - Device enrollment permissions (Manage) - Policies (Add a policy) - Select existing policies (생성한 Policy 선택)- Add rule > Selector : Emails / Value : 이메일
- Email ending in으로 @gmail.com 같은 전체 허용도 가능
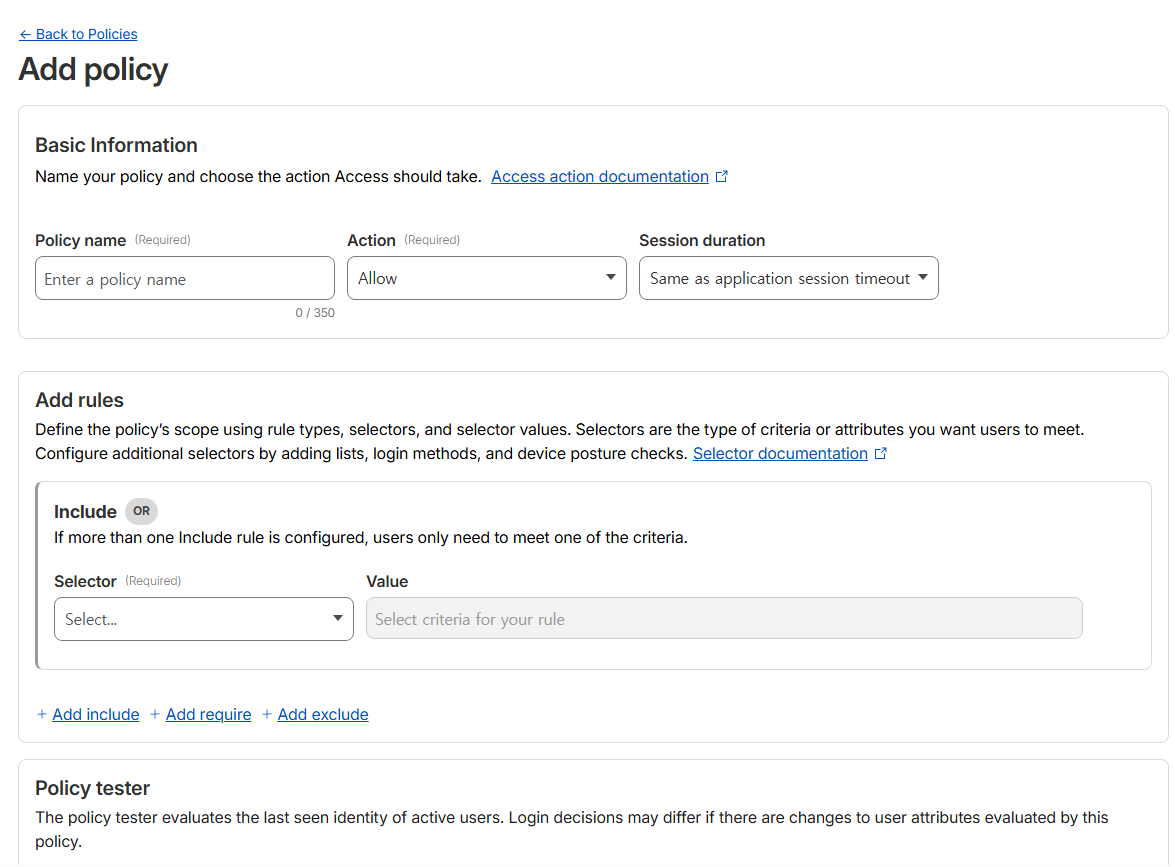
- Email ending in으로 @gmail.com 같은 전체 허용도 가능
-
이메일 확인 후 Warp 연결은 됐으나 SSH 연결이 안 되는 상황
- 원인 : 192.168.x.x 같은 사설 IP 대역은 WARP가 기본적으로 터널로 보내지 않고 제외(Exclude)하도록 설정되어 있기 때문이다.
- 해결 :
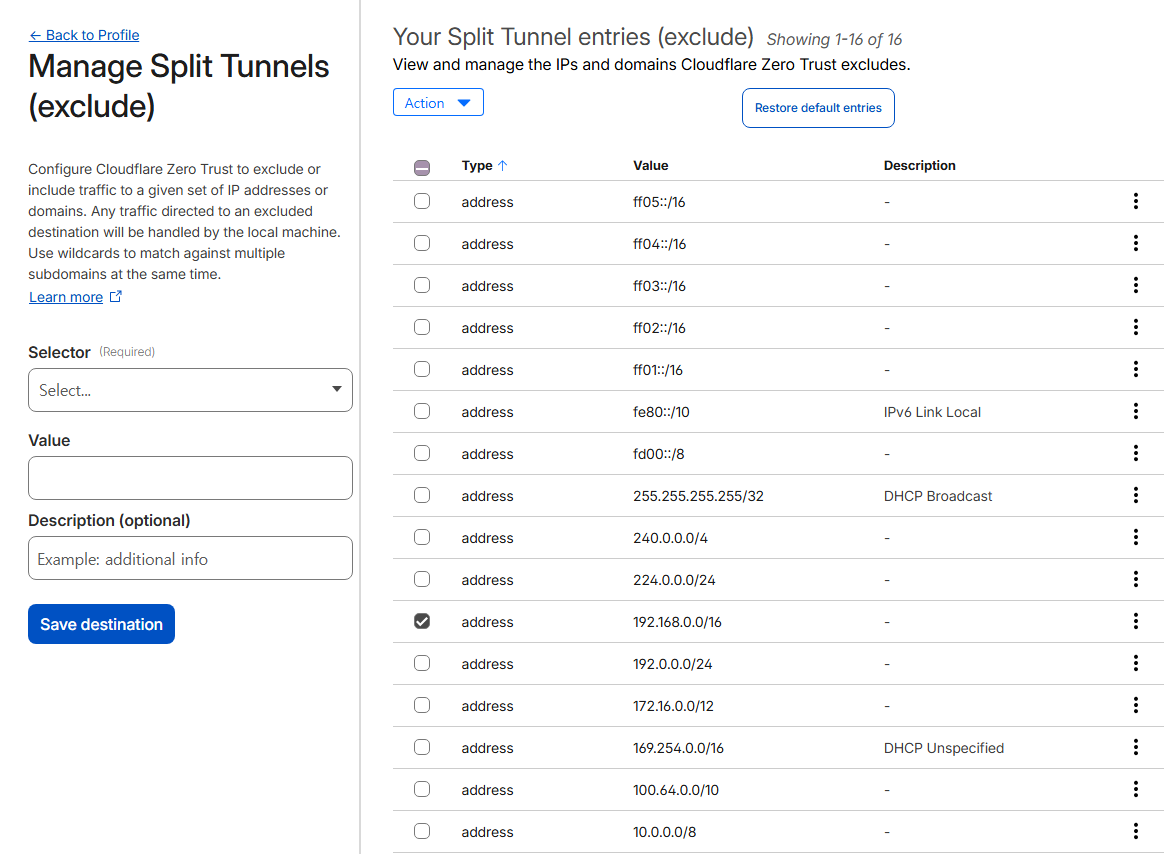
Zero Trust - Team & Resources - Devices - Device profiles - Default (Edit) - Split Tunnels (Manage) - 192.168.0.0/16 삭제
- 외부 사용자가 팀에 정상적으로 들어오면 아래처럼 등록된 디바이스에 뜬다.
# 인스턴스에 SSH 연결
$ ssh -i test_user_key.pem ubuntu@192.168.35.207인스턴스 모니터링 확장 및 호스트 모니터링
- CPU 위주 모니터링에서 메모리와 디스크 지표를 추가 => 인스턴스의 자원 고갈 상태(OOM 등)와 저장소 성능 병목을 진단하기 위한 목적
- CPU 메트락만 가져오던 get_instance_cpu_usage 함수를 get_instance_metrics로 수정
def get_instance_metrics(...):
queries = {
"cpu": f'100 - (avg by (instance) (irate(node_cpu_seconds_total{{instance=~"{instance_ip}:.*", mode="idle"}}[1m])) * 100)',
"memory": f'(1 - (node_memory_MemAvailable_bytes{{instance=~"{instance_ip}:.*"}} / node_memory_MemTotal_bytes{{instance=~"{instance_ip}:.*"}})) * 100',
"disk_read": f'sum(rate(node_disk_read_bytes_total{{instance=~"{instance_ip}:.*"}}[1m]))',
"disk_write": f'sum(rate(node_disk_written_bytes_total{{instance=~"{instance_ip}:.*"}}[1m]))'
}
for key, q in queries.items():
try:
response = requests.get(f"{prometheus_url}/api/v1/query", params={'query': q}, timeout=2)
data = response.json()
if data['status'] == 'success' and data['data']['result']:
val = float(data['data']['result'][0]['value'][1])
# 디스크 I/O는 KB/s 단위로 변환, 나머지는 소수점 둘째자리 반올림
results[key] = round(val / 1024, 2) if "disk" in key else round(val, 2)
else:
results[key] = "No Data" if "disk" not in key else 0
def get_unified_dashboard_data(...):
unified_data.append({
...
"cpu": metrics["cpu"],
"memory": metrics["memory"],
"disk_read": metrics["disk_read"],
"disk_write": metrics["disk_write"],
...
})- 호스트(노트북) 리소스 모니터링 설계
- 오픈스택은 수많은 마이크로서비스가 컨테이너 기반으로 동작하므로, 호스트의 물리적인 자원 임계치를 넘어서면 클라우드 전체 서비스가 중단될 수 있다.
- 호스트 모니터링은 프라이빗 클라우드 운영에서 Control Plane의 안정성을 위한 핵심 요소이다.
- 호스트 모니터링 페이지에 포함될 지표
- 컴퓨트 및 부하 : 실제 프로세스가 CPU 자원을 할당받기 위해 얼마나 대기하고 있는지 파악하는 것이 중요
시스템 부하 (Load): 1분간 평균 부하, 코어 수 대비 Load가 높다면 VM 스케줄링 지연 발생 가능성이 높다.CPU 사용률(%): 전체 CPU 중 idle 상태를 제외한 비중을 확인해 80~90%가 지속되면 물리 노드의 확장(Scale-out)이나 VM 재배치가 필요한 시점이다.
- 메모리 관리 : 오픈스택 환경에서 OS, RabbitMQ, MariaDB 등 제어부 서비스와 VM이 메모리를 공유하므로, 실제 물리적 압박을 측정하는 것이 중요
메모리 가용률(%): 단순 캐시를 제외하고 OS와 애플리케이션이 즉시 할당 가능한 메모리 비중을 확인한다. 10% 미만일 경우 OOM Killer 작동하여 핵심 프로세스를 죽일 수 있다.
- 스토리지 상태 : 루트 파티션이 가득 차면 로그 기록이 중단되고 서비스가 멈춘다.
스토리지 병목: 초당 읽기/쓰기 횟수를 합산하여 디스크 하드웨어가 감당할 수 있는 한계치(IOPS)에 도달했는지 확인한다. 특정 VM의 비정상적인 로그 쓰기나 DB 부하를 잡을 수 있다.시스템 파티션 안정성: /etc/hosts가 위치한 마운트 포인트(보통 루프 파티션 /)의 여유 공간을 확인한다. 로그 파일이나 이미지 임시 파일로 인해 디스크가 100% 차버리면 노드 전체가 Read-only 상태가 되거나 멈춘다.
- 네트워크
대역폭 포화 및 트래픽 이상 감지: lo(로컬), veth(컨테이너 가상 인터페이스) 등을 제외한 실제 물리 NIC의 트래픽만 합산한다. VM 간의 대규모 데이터 이동이나 외부 공격(DDoS)으로 인한 대역폭 포화를 감시한다.
- 컴퓨트 및 부하 : 실제 프로세스가 CPU 자원을 할당받기 위해 얼마나 대기하고 있는지 파악하는 것이 중요
def get_host_resource_usage(self, prometheus_url):
host_label = 'instance=~"localhost:9100.*"'
queries = {
"cpu_load": f"node_load1{{{host_label}}}",
"cpu_usage": f"100 - (avg by (instance) (irate(node_cpu_seconds_total{{{host_label}, mode='idle'}}[1m])) * 100)",
"mem_usage": f"(1 - (avg by (instance) (node_memory_MemAvailable_bytes{{{host_label}}}) / avg by (instance) (node_memory_MemTotal_bytes{{{host_label}}}))) * 100",
"disk_usage": f"100 - (sum by (instance) (node_filesystem_avail_bytes{{{host_label}, mountpoint='/etc/hosts'}}) / sum by (instance) (node_filesystem_size_bytes{{{host_label}, mountpoint='/etc/hosts'}}) * 100)",
"net_throughput": f"(sum(rate(node_network_receive_bytes_total{{{host_label}, device!~'lo|veth.*|docker.*|br.*|tap.*'}}[1m])) + sum(rate(node_network_transmit_bytes_total{{{host_label}, device!~'lo|veth.*|docker.*|br.*|tap.*'}}[1m]))) * 8 / 1024 / 1024",
"disk_iops": f"sum(rate(node_disk_reads_completed_total{{{host_label}}}[1m])) + sum(rate(node_disk_writes_completed_total{{{host_label}}}[1m]))"
}
...| 지표명 | 모니터링 필요성 (Why) | 활용 시나리오 (When) |
|---|---|---|
| Host OS Load | 시스템이 처리할 수 있는 양보다 많은 작업이 대기 중인지 확인한다. | 수치가 CPU 코어 수보다 높으면 새로운 VM 생성을 제한하거나 배포 정책을 수정해야 한다. |
| Total CPU Usage | 실제 연산 자원이 얼마나 쓰이는지 측정하여 'Noisy Neighbor' 현상을 감지한다. | 특정 VM이 CPU를 독점하여 다른 VM의 성능을 저하시키는지 확인하고 할당량(Quota)을 조정한다. |
| Total RAM Usage | 메모리는 고갈 시 OOM(Out of Memory) Killer가 중요 프로세스를 강제 종료시킬 수 있는 치명적 자원이다. | 메모리 점유율이 90%를 넘으면 기존 VM을 최적화하거나 물리 메모리를 증설해야 하는 신호로 본다. |
| Root Disk Usage | 로그 파일, 이미지 캐시 등으로 인해 디스크가 꽉 차면 전체 클라우드 서비스가 중단된다. | 80% 도달 시 오래된 인스턴스 스냅샷이나 사용하지 않는 볼륨을 정리하는 관리 작업을 수행한다. |
| Network Throughput | 물리 랜카드의 대역폭 한계치에 도달했는지 감시하여 네트워크 지연을 방지한다. | 백업이나 대용량 데이터 전송 시 인스턴스들의 통신 속도가 느려지는 원인을 파악할 때 활용한다. |
| Disk IOPS | 디스크의 데이터 읽기/쓰기 횟수를 감시하여 성능 저하(I/O Wait)를 찾아낸다. | CPU 사용량은 낮은데 시스템이 버벅거릴 경우, 디스크의 물리적 한계를 확인하는 핵심 지표이다. |
앤서블 인프라 자동화
- (계획)
- 1_ 앤서블 동적 인벤토리 및 인스턴스 초기 설정 cloud_portal.db를 읽어 신규 서버에 접속하고 아래 작업을 수행한다.
- 호스트네임 동기화 : 오픈스택 대시보드에 표시되는 인스턴스 이름을 OS 내부의 /etc/hostname과 /etc/hosts에 적용
- 터미널 접속시 어떤 서버에 있는 즉시 식별해 운영 실수를 방지한다.
- 패키지 최신화 : packer로 이미지를 만든 시점 이후에 배포된 패치를 자동 적용한다.
- 방식 : Python 스크립트가 DB 정보를 바탕으로 임시 JSON 인벤토리 생성 => ansible-playbook이 해당 인벤토리를 타겟으로 초기 설정 실행
- 호스트네임 동기화 : 오픈스택 대시보드에 표시되는 인스턴스 이름을 OS 내부의 /etc/hostname과 /etc/hosts에 적용
- 2_ 리소스 정리 자동화
- 부족한 노트북 자원을 보호하기 사용하지 않는 리소스를 자동으로 삭제한다.
- 필요한 리소스가 삭제는 되는 것을 방지하기 위해 삭제 예정 리스트를 보여주고 승인 후 처리
- 스캔 대상 및 조건
- 인스턴스에 할당되지 않은 채 점유만 된 Floating IP
- 생성된지 12시간 경과한 미사용 인스턴스
- 부족한 노트북 자원을 보호하기 사용하지 않는 리소스를 자동으로 삭제한다.
- DB의 인스턴스 ID를 기반으로 오픈스택에서 IP를 받아오기 위해 instances 테이블을 새로 만들고 instance_id 컬럼 추가 및 인스턴트 생성 후 DB에 Insert 하도록 수정
- 앤서블 기반 인스턴스 초기 설정
- 인스턴스가 생성되면 생성된 인스턴스의 UUID와 이름을 instances 테이블에 저장
- FastAPI의 BackgroundTasks를 통해 앤서블 실행 함수를 백그라운드에서 실행
- inventory.py를 통해 DB와 오픈스택 API를 대조하고 접속 가능한 호스트 정보를 JSON 형태로 생성 (동적 인벤토리)
- SSH 접속이 가능하질 때까지 10초 대기 후, init_setup.yaml을 실행해 패키지 업데이트 및 호스트네임 설정 (플레이북)
# main.py
def run_ansible_setup(instance_name: str):
# 인스턴스가 ACTIVE여도 SSH 서비스가 뜰 수 있도록 대기
time.sleep(10)
try:
# --limit 옵션으로 생성된 인스턴스만 타겟
cmd = [
"ansible-playbook",
"-i", "inventory.py",
"init_setup.yaml",
"--limit", instance_name
]
result = subprocess.run(cmd, capture_output=True, text=True)
if result.returncode == 0:
print(f" Ansible Success : [{instance_name}] 초기 설정 완료")
else:
print(f"Ansible Fail : [{instance_name}] 초기 설정 실패 : {result.stderr}")- 앤서블은 대상 서버에 별도의 프로그램을 설치하지 않고 SSH 접속만으로 제어한다.
- 앤서블이 실행될 때 어디로 접속해야 하는지를 먼저 묻는다. 보통은 정적 파일(host.ini)을 보지만, IP가 계속 변하는 클라우드 환경에서는 실행 가능한 스크립트를 인벤토리로 사용한다. 앤서블이 이 파일을 실행하면 규격에 맞는 JSON을 반환하고 앤서블이 읽어 SSH 접속을 시도한다.
# inventory.py
#!/usr/bin/env python3
def get_inventory():
# 소스 데이터 확보 : 앤서블이 관리해야 할 대상을 DB에서 가져온다.
BASE_DIR = os.path.dirname(os.path.abspath(__file__))
DB_PATH = os.path.join(BASE_DIR, "cloud_portal.db")
conn = sqlite3.connect(DB_PATH)
conn.row_factory = sqlite3.Row
cursor = conn.cursor()
# instance_name을 hostname으로 사용하기 위해 조회
db_instances = cursor.execute("SELECT instance_id, username, instance_name FROM instances").fetchall()
conn.close()
manager = OpenStackManager()
# 앤서블 표준 포맷 생성 : 앤서블이 이해할 수 있는 JSON 구조의 틀
# '_meta' : 호스트별 변수(IP, 키 경로 등)를 저장
# 'openstack_nodes' : 그룹 이름. 앤서블 플레이북의 'hosts: openstack_nodes'와 매칭됨
inventory = {
'_meta': {'hostvars': {}},
'all': {'children': ['openstack_nodes']},
'openstack_nodes': {'hosts': []}
}
for row in db_instances:
try:
# 실시간 상태 확인 : DB에는 있지만 오픈스택에서 삭제되었을 수도 있으므로 API로 실시간 조회
servers = list(manager.conn.compute.servers(all_projects=True, uuid=row['instance_id']))
# 리스트가 비어있다면 앤서블에 알려줄 필요가 없으므로 스킵
if not servers: continue
server = servers[0]
# IP 추출 : 앤서블이 SSH 접속에 필요한 외부 IP(Floating IP) 추출
floating_ip = "N/A"
for net_name, addr_list in server.addresses.items():
for addr in addr_list:
if addr.get("OS-EXT-IPS:type") == "floating":
floating_ip = addr['addr']
if floating_ip == "N/A": continue
# 5. 호스트 변수 설정 : 앤서블이 대상 서버에 어떻게 접속할지 상세 정보를 넘겨줌
hostname = row['instance_name']
inventory['openstack_nodes']['hosts'].append(hostname)
inventory['_meta']['hostvars'][hostname] = {
'ansible_host': floating_ip, # 실제 접속할 IP 주소
'ansible_user': 'ubuntu', # 접속 계정 (Ubuntu 이미지 기본값)
# SSH 키 경로 : 절대 경로를 사용하여 도커 컨테이너 환경에서도 파일을 찾도록 설정
'ansible_ssh_private_key_file': os.path.join(BASE_DIR, "user_keys", f"{row['username']}_key.pem"),
# StrictHostKeyChecking=no: 처음 접속하는 서버의 지문(fingerprint)을 자동으로 수락
# 이게 없으면 앤서블이 "모르는 서버인데 믿어도 돼?"라고 물어보느라 멈춘다.
'ansible_ssh_common_args': '-o StrictHostKeyChecking=no',
# 플레이북에서 동적으로 사용할 변수 (호스트네임 동기화용)
'target_hostname': row['instance_name']
}
except Exception:
continue
return inventory
if __name__ == "__main__":
# 앤서블은 이 스크립트를 실행한 결과값(JSON)만 가져가서 사용
print(json.dumps(get_inventory()))# init_setup.yaml
---
- name: OpenStack Instance Post-Deployment Setup
hosts: openstack_nodes # inventory.py에서 정의한 그룹 이름과 일치
become: yes # 패키지 설치를 위해 sudo 권한을 사용
tasks:
- name: 1. 패키지 리스트 업데이트 및 업그레이드
apt:
# update_cache: yes == apt update
update_cache: yes
# upgrade: dist== apt dist-upgrade
# 인프라 보안 패치를 한 번에 끝내기 위해 전체 OS 패키지를 최신 버전으로 업그레이드
upgrade: dist
# autoremove: yes == apt autoremove
# 업그레이드 과정에서 더 이상 필요 없어진 오래된 패키지들을 지워 디스크 용량 확보
autoremove: yes
- name: 2. OS 내부 호스트네임 설정 (DB 이름과 동기화)
hostname:
# inventory.py에서 넘겨준 target_hostname 변수를 사용하여 서버 실제 이름 변경
name: "{{ target_hostname }}"
- name: 3. /etc/hosts 파일에 호스트네임 반영
# lineinfile 모듈 : 파일 안의 특정 줄을 찾아서 수정하거나 추가
lineinfile:
path: /etc/hosts
# 127.0.1.1로 시작하는 줄을 찾아 교체
regexp: '^127.0.1.1'
line: "127.0.1.1 {{ target_hostname }}"- 유휴 리소스 감지 및 회수 권고
- 오픈스택을 구동하고 있는 호스트가 노트북이기 때문에 노트북의 리소스 관리가 중요하다.
- 사용하지 않는 오픈스택 리소스가 삭제되지 않고 있으면 노트북의 리소스를 계속 점유하기 때문에 해당 자원을 찾아 회수를 제안할 수 있도록 한다.
- 오픈스택에 존재하는 모든 인스턴스 리스트와 DB의 인스턴스 리스트를 비교
- 후보 필터링
- 오픈스택에는 있으나 DB에 없는 경우
- 포트가 연결되지 않은 미사용 Floating IP
- 필터링된 리소스를 대시보드에 노출 및 필요한 경우 해당 리소스 회수 및 DB에서 삭제
- 오픈스택을 구동하고 있는 호스트가 노트북이기 때문에 노트북의 리소스 관리가 중요하다.
def get_cleanup_candidates(self, db_instance_ids):
cleanup_list = []
now = datetime.now(timezone.utc)
all_servers = list(self.conn.compute.servers(all_projects=True))
for server in all_servers:
created_at = datetime.fromisoformat(server.created_at.replace('Z', '+00:00'))
is_old = (now - created_at) > timedelta(hours=12) # 12시간 경과 체크
is_orphaned = server.id not in db_instance_ids # DB 미등록 체크
if is_old or is_orphaned:
cleanup_list.append({"type": "Instance", "id": server.id, "reason": "12시간 경과" if is_old else "유령 리소스"})
# port_id가 없는 미사용 Floating IP
all_fips = list(self.conn.network.ips())
for fip in all_fips:
if not fip.port_id:
cleanup_list.append({"type": "Floating IP", "id": fip.id, "reason": "미사용 IP"})
return cleanup_list
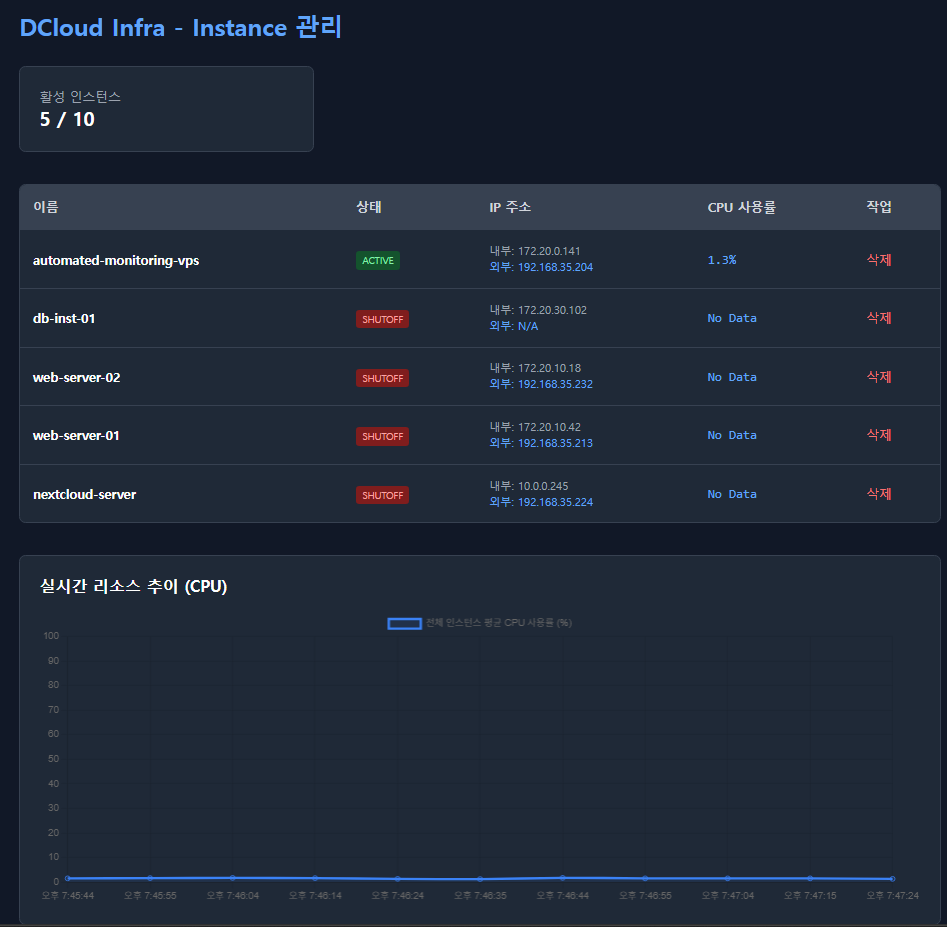
- 위 사진은 앤서블 돌려서 호스트네임 업데이트 성공 확인
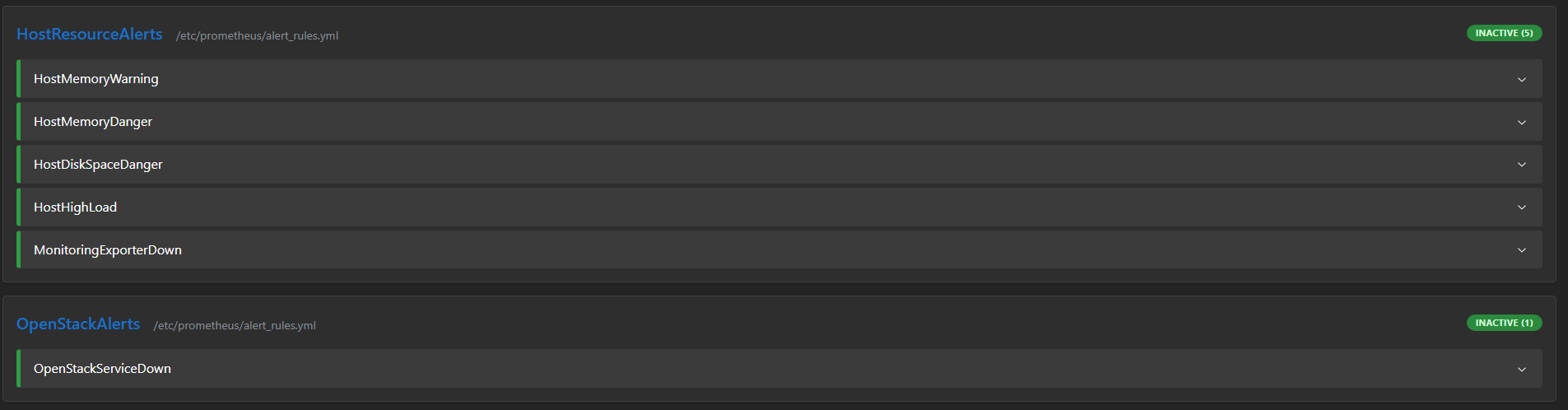
Prometheus Alertmanager
- 오픈스택 환경 보호를 위해 리소스 부족 시 디스코드로 알림을 보내도록 구성
- 특히 노트북 환경인 만큼 메모리가 부족해 평소에도 사용량이 높은 만큼 인스턴스를 몇 개만 만들어도 램 사용량이 크게 오르며, 잘못하면 OOM Killer로 인해 오픈스택 인프라가 잠시 꺼지는 상황이 발생한다.
- 이를 방지하기 위해 메모리 사용량이 80%일 때 주의 알림을 전송하고, 90% 이상일 때 Danger 알림을 보내 오픈스택이 꺼지지 않도록 주의하려고 한다.
- 이를 방지하기 위해 메모리 사용량이 80%일 때 주의 알림을 전송하고, 90% 이상일 때 Danger 알림을 보내 오픈스택이 꺼지지 않도록 주의하려고 한다.
- Prometheus Alertmanager 컨테이너 생성 및 알림 설정
# docker-compose.yml
prometheus:
image: prom/prometheus:latest
container_name: prometheus
volumes:
- ./prometheus.yml:/etc/prometheus/prometheus.yml
- ./alert_rules.yml:/etc/prometheus/alert_rules.yml # 알림 규칙 파일
network_mode: "host"
restart: always
alertmanager:
image: prom/alertmanager:latest
container_name: alertmanager
network_mode: "host"
volumes:
- /home/khs/openstack-monitoring/alertmanager.yml:/etc/alertmanager/alertmanager.yml:ro
restart: always# alert_rules.yml
groups:
- name: HostResourceAlerts
rules:
- alert: HostMemoryWarning
expr: (1 - (node_memory_MemAvailable_bytes / node_memory_MemTotal_bytes)) * 100 > 80
for: 5m
labels:
severity: warning
annotations:
summary: "호스트 메모리 주의"
description: "현재 메모리 사용량 : {{ $value | printf \"%.2f\" }}%"
- alert: HostMemoryDanger
expr: (1 - (node_memory_MemAvailable_bytes / node_memory_MemTotal_bytes)) * 100 > 90
for: 2m
labels:
severity: critical
annotations:
summary: "호스트 메모리 고갈 위기"
description: "현재 메모리 사용량 : {{ $value | printf \"%.2f\" }}%"
- alert: HostDiskSpaceDanger
expr: (node_filesystem_avail_bytes{mountpoint="/"} / node_filesystem_size_bytes{mountpoint="/"}) * 100 < 10
for: 5m
labels:
severity: critical
annotations:
summary: "디스크 용량 고갈 위기"
description: "루트 파티션의 남은 용량 10% 미만"
- alert: HostHighLoad
expr: node_load1 > (count by(instance) (node_cpu_seconds_total{mode="idle"}) * 1.5)
for: 5m
labels:
severity: warning
annotations:
summary: "시스템 부하 지수 상승"
description: "현재 시스템 Load({{ $value }})가 코어 수 대비 높음. 처리 속도 저하 위험."
- alert: MonitoringExporterDown
expr: up{job="node-exporter"} == 0
for: 1m
labels:
severity: critical
annotations:
summary: "모니터링 에이전트 중단"
description: "대상({{ $labels.job }})이 응답하지 않음. 데이터 수집이 중단되었습니다."
- name: OpenStackAlerts
rules:
- alert: OpenStackServiceDown
expr: openstack_compute_service_state == 0
for: 1m
labels:
severity: critical
annotations:
summary: "오픈스택 서비스 장애"
description: "서비스({{ $labels.service }}) 상태 DOWN."
# alertmanager.yml
route:
group_by: ['alertname']
group_wait: 30s
group_interval: 5m
repeat_interval: 30m
receiver: 'discord'
receivers:
- name: 'discord'
discord_configs:
- webhook_url: 'discord_webhook-url'
# prometheus.yml
...
alerting:
alertmanagers:
- static_configs:
- targets: ['localhost:9093']- 각 알림별 세부 설명
- HostMemoryWarning & HostMemoryDanger
- 호스트 OS의 메모리 자원 임계치를 감시하여 시스템의 안정성을 보장
- PromQL : (1 - (node_memory_MemAvailable_bytes / node_memory_MemTotal_bytes)) * 100 > [80 또는 90]
node_memory_MemAvailable_bytes: 커널이 새로운 프로세스에 즉시 할당할 수 있는 메모리 양.node_memory_MemTotal_bytes: 시스템의 전체 물리 메모리 크기.- 계산 : 전체에서 가용 비율을 뺀 후 100을 곱하여 현재 메모리 사용률(%)을 산출.
- 설정 이유 : 메모리가 고갈되면 리눅스 커널은 시스템 다운을 막기 위해 OOM Killer를 작동시킨다. 이때 가장 메모리를 많이 점유하는 프로세스(주로 오픈스택 서비스나 데이터베이스)를 강제 종료시키므로, 이를 방지하기 위해 80%에서 경고, 90%에서 위기 알림을 설정.
- 상황 파악 : 인스턴스가 과하게 생성되었거나, 특정 서비스에서 메모리 누수가 발생하여 시스템 성능 저하 및 서비스 중단이 임박한 상태.
- 해결 방법 : 유휴 인스턴스 종료 및 삭제, 메모리 점유가 높은 프로세스 확인(top, htop), 필요 시 가상 메모리(Swap) 설정 검토 또는 물리 메모리 증설.
- HostDiskSpaceDanger
- 시스템의 데이터 저장 공간 가용성을 감시.
- PromQL : (node_filesystem_avail_bytes{mountpoint="/"} / - node_filesystem_size_bytes{mountpoint="/"}) * 100 < 10
node_filesystem_avail_bytes{mountpoint="/"}: 루트 디렉토리에 마운트된 파일 시스템의 가용 바이트.- 계산 : 전체 크기 대비 가용 공간의 비율이 10% 미만인지를 체크.
- 설정 이유 : 파일 시스템이 100% 점유되면 데이터베이스 쓰기가 불가능해져 오픈스택 제어부가 즉시 다운된다. 또한 로그 파일이 생성되지 않아 장애 추적도 불가능해지며, Glance 이미지 업로드 등 모든 기록 작업이 실패한다.
- 상황 파악 : 로그 파일 누적, 오픈스택 가상 이미지 파일 과다 생성, Docker 볼륨 내 임시 데이터 과다 적재.
- 해결 방법 : du -sh /* 명령으로 대용량 디렉토리 확인, 로그 로테이션(Log Rotate) 주기 확인, 미사용 오픈스택 이미지/볼륨 삭제, docker system prune을 통한 찌꺼기 제거.
- HostHighLoad
- 시스템의 연산 부하(Load Average)를 감시하여 응답성을 관리.
- PromQL 분석 : node_load1 > (count by(instance) (node_cpu_seconds_total{mode="idle"}) * 1.5)
node_load1: 최근 1분간 실행 중이거나 실행을 대기하는 프로세스의 평균 수.count by(instance) (node_cpu_seconds_total{mode="idle"}): 시스템의 전체 CPU 코어 수를 동적으로 계산.- 계산 : 부하 지수가 코어 수의 1.5배를 초과하는지 확인한다. (ex. 4코어 환경에서 Load가 6 이상인 경우)
- 설정 이유 : CPU 사용률이 낮더라도 I/O 대기 등으로 인해 Load가 높으면 시스템 응답 속도가 비정상적으로 느려진다. 이는 API 타임아웃으로 이어져 인프라 제어 능력을 상실하게 만든다.
- 상황 파악 : CPU 코어 수보다 훨씬 많은 작업이 대기열에 쌓여 있는 병목 현상 발생. 노트북 환경의 경우 하드웨어 발열로 인한 CPU 쓰로틀링 가능성도 있다.
- 해결 방법 : 부하가 높은 프로세스 식별, 인스턴스 CPU 쿼타(Quota) 제한 설정, 하드웨어 쿨링 상태 점검.
- MonitoringExporterDown
- 모니터링 시스템 자체의 무결성을 감시하는 알림.
- PromQL 분석 : up{job="node-exporter"} == 0
up: 프로메테우스가 대상을 성공적으로 스크레이핑했는지 나타내는 합성 메트릭. (1: 성공, 0: 실패)- 설정 이유 : 모니터링 데이터 수집이 중단되면 현재 시스템이 안전한지 판단할 수 있는 근거 자체가 사라진다. 알림이 오지 않는 것이 문제가 없어서 아니라 모니터링 자체에 이상이 있어서인지 확인한다.
- 상황 파악 : node-exporter 컨테이너가 중단되었거나 호스트 네트워크 설정 오류로 프로메테우스가 에이전트에 접근하지 못하는 상태입니다.
해결 방법 : docker ps로 컨테이너 가동 여부 확인, 9100 포트 방화벽 상태 확인, 에이전트 서비스 로그 확인.
- OpenStackServiceDown
- OpenStack의 핵심 서비스 가동 여부를 감시.
- PromQL 분석 : openstack_compute_service_state == 0
openstack_compute_service_state: 오픈스택 익스포터가 수집한 각 서비스의 상태 값. (1: Up, 0: Down)- 설정 이유 : OS의 자원이 충분하더라도 오픈스택의 핵심 컴포넌트가 죽으면 인스턴스 생성 및 네트워크 제어가 불가능하다. 플랫폼 수준의 장애를 인지하기 위한 지표.
- 상황 파악 : nova-compute 등 특정 오픈스택 마이크로서비스가 자원 부족 혹은 설정 오류로 인해 비정상 종료된 상황.
- 해결 방법 : openstack compute service list 명령으로 장애 서비스 확인, 해당 서비스 컨테이너 로그(docker logs) 분석 및 재시작.
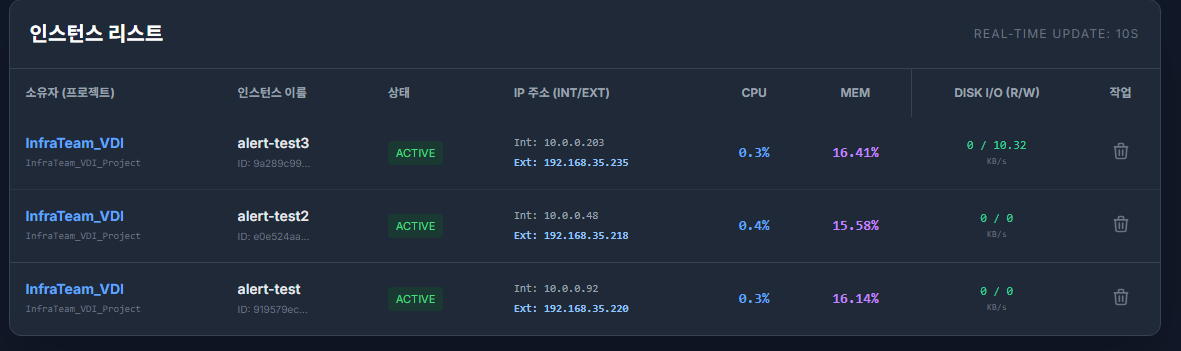
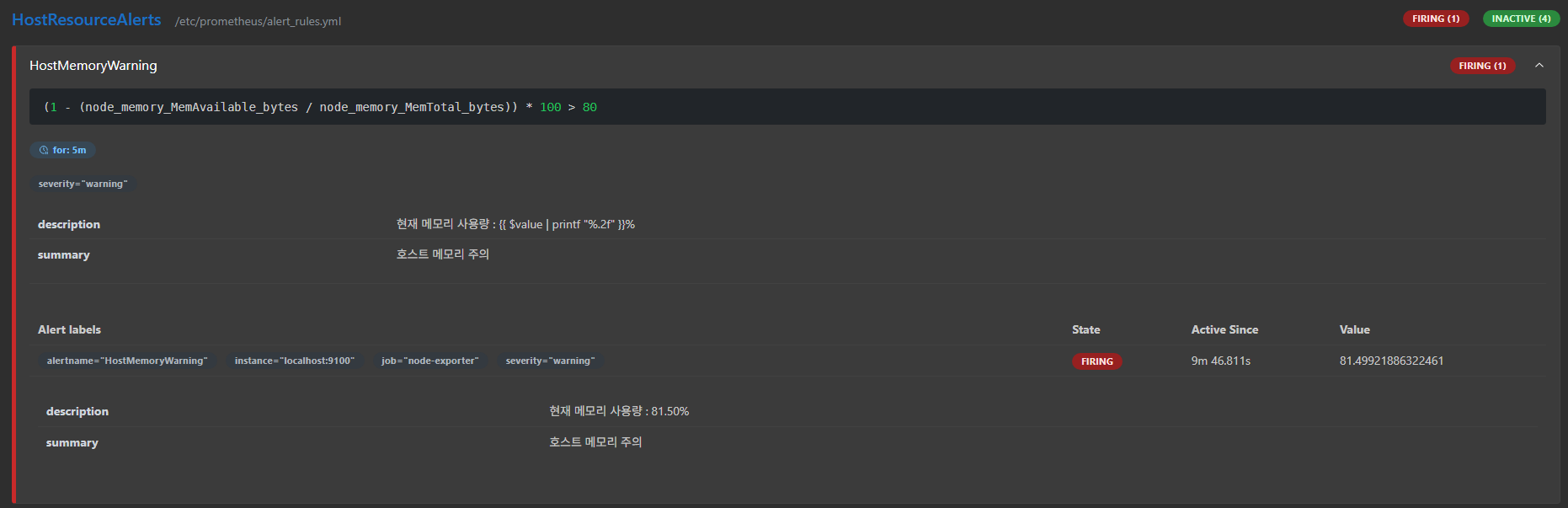
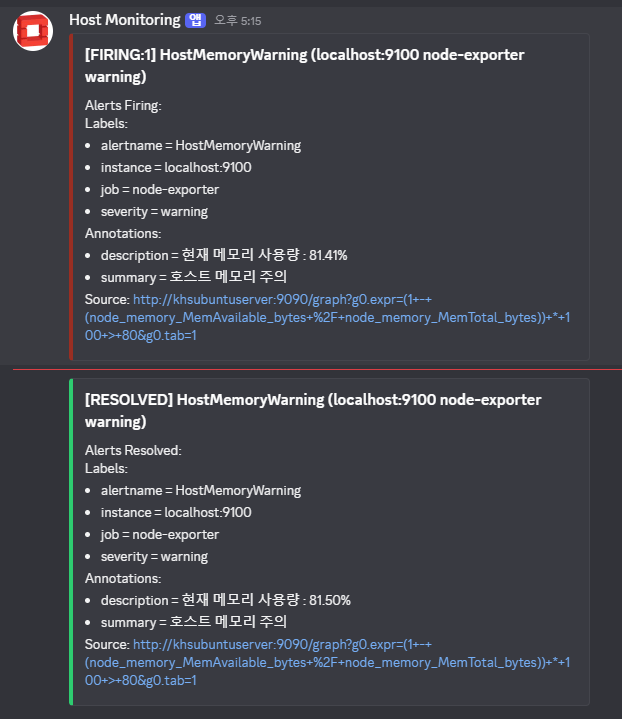
- 알림 테스트를 위해 인스턴스 3개를 생성 후 메모리 사용량을 80% 이상으로 유지

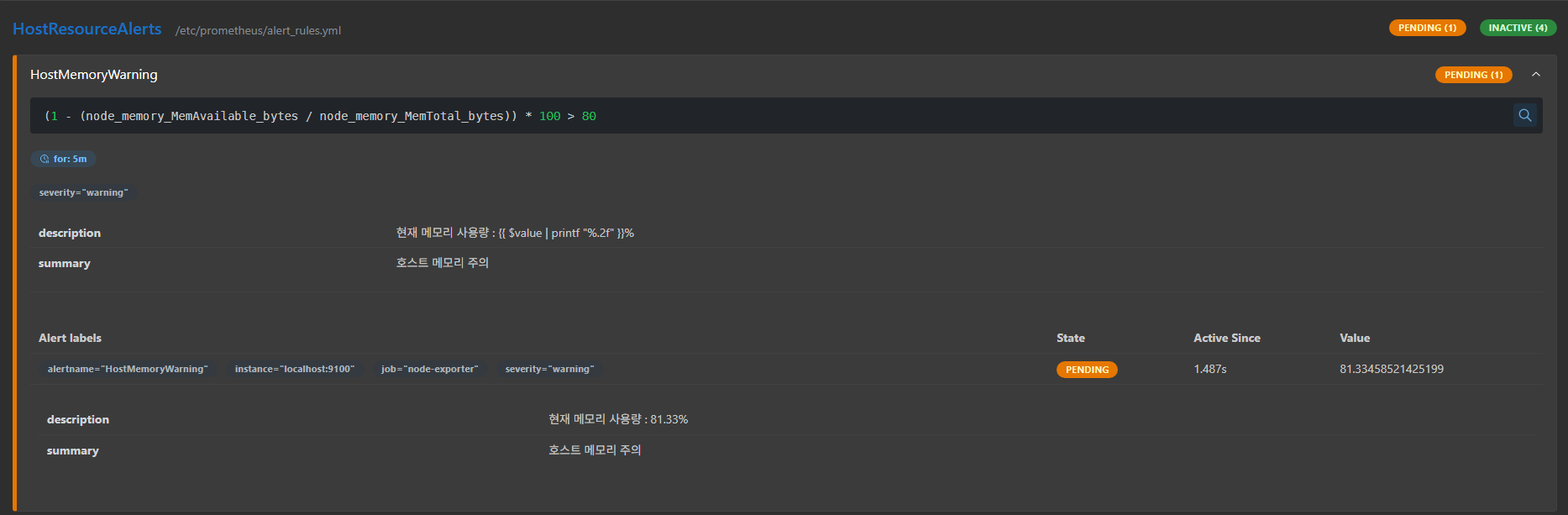
- 램 사용량이 80% 이상으로 유지된지 5분이 지나면 FIRING 상태가 되면서 디스크로 알림 전송됨.
이론 공부 / Why
- 📌네트워크 : Neutron 패킷 흐름
- 오픈스택엣거 인스턴스가 생성될 때 네트워크가 연결되는 논리적/물리적 구조를 이해한다. Kolla-Ansible은 기본적으로
Open vSwith(OVS)를 사용한다. - 테넌트 격리 (L2 Isolation)
- 사용자(Tenant)가 생성한 네트워크는 다른 사용자와 겹치지 않아야 한다.
VXLAN/VLAN: 주로 사용되는 터널링 기술로, 같은 Private IP 대역을 쓰더라도VNI(VXLAN Network Identifier)를 통해 L2 레이어에서 패킷이 격리된다.OVS Bridges: 인스턴스는br-int(Integration Bridge)에 연결되고, 외부와의 통신은br-ex(External Bridge)를 통해 이루어진다.
- L3 라우팅 및 Floating IP (L3 Agent)
- 인스턴스가 외부(인터넷)와 통신하려면 Router가 필요하다.
- Fixed IP : 인스턴스 생성 시 내부 네트워크에서 할당받는 사설 IP.
- Floating IP : 외부 네트워크 대역의 IP를 인스턴스의 Fixed IP와 1:1로 매핑한다.
- 동작 원리 (NAT) : 라우터 네임스페이스(qrouter-xxx) 내부에서 iptables를 사용하여 DNAT(외부->내부)와 SNAT(내부->외부) 처리를 수행한다.
- VXLAN과 프라이빗 IP 중첩
- 여러 테넌트가 동일한 프라이빗 IP 대역을 사용할 수 있는 이유는 VXLAN(Virtual Extensible LAN) 기술 덕분이다.
- L2 over L3 오버레이 : VXLAN은 가상 2계층(L2) 네트워크 패킷을 표준 3계층(L3) UDP 패킷 안에 캡슐화한다.
- VNI (VXLAN Network Identifier) : 기존 VLAN이 12비트(4,096개)의 한계를 가진 반면, VXLAN은 24비트(약 1,600만 개)의 VNI를 가진다. 각 테넌트(사용자)는 고유한 VNI를 할당받는다.
- 격리 원리 : 사용자 A의 패킷은 VNI 100에 담기고, 사용자 B의 패킷은 VNI 200에 담긴다. 두 패킷이 동일한 사설 IP(192.168.0.10)를 목적지로 하더라도, VNI가 다르기 때문에 네트워크 스택은 이를 완전히 다른 목적지로 인식하여 충돌이 발생하지 않는다.
- 여러 테넌트가 동일한 프라이빗 IP 대역을 사용할 수 있는 이유는 VXLAN(Virtual Extensible LAN) 기술 덕분이다.
- 호라이즌 대시보드에서 라우터와 네트워크를 구성했을 때는 라우터의 인터페이스 탭에서 내부 인터페이스와 외부 게이트웨이가 표시되는데, 코드로 구성했을 때는 내부 인터페이스만 보이는 이유가 뭘까? (네트워크 토폴로지를 확인했을 때는 외부-라우터-내부가 연결되어 있음)
- 호라이즌 대시보드에서 라우터를 클릭했을 때 나오는
인터페이스탭은 해당 라우터가 연결된 사설 서브넷 (Internal Subnet) 목록만 보여준다.- 내부 인터페이스 (Internal Interface**) : 라우터가 사설 네트워크(VXLAN)과 통신하기 위한 안쪽 문.
add_interface_to_router 함수로 추가하며, 인터페이스 탭에 표시된다. - 외부 게이트웨이 (External Gateway) : 라우터가 외부망과 통신하기 위한 바깥 문.
external_gateway_info로 설정하며, 이는 인터페이스 목록이 아니라 라우터의 개요 탭에서 확인 가능하다.
- 내부 인터페이스 (Internal Interface**) : 라우터가 사설 네트워크(VXLAN)과 통신하기 위한 안쪽 문.
- 호라이즌 대시보드에서 라우터를 클릭했을 때 나오는
# 라우터 생성 혹은 업데이트 시 설정
router = self.conn.network.create_router(
name=router_name,
project_id=project_id,
external_gateway_info={"network_id": ext_net.id} # <-----
)
# 라우터에 서브넷을 연결
self.conn.network.add_interface_to_router(
router.id,
subnet_id=subnet.id # <------
)- Cloudflare WARP
- 사용자 단말과 네트워크 간에 암호화된 터널을 생성한다. 일반적인 VPN이 특정 서버에 모든 트래픽을 집중시키는 것과 달리 WARP는 Zero Trust 원칙에 기반하여 동작한다.
- WARP는 단순한 IP 우회 도구가 아니라 기업 및 개인 인프라를 보호하는 ZTNA(Zero Trust Network Access)의 클라이언트 역할을 수행한다.
- 엔드포인트 보안 및 인증 : 사용자 기기의 보안 상태를 확인하고, 등록된 이메일이나 소셜 로그인을 통해 신원을 증명하여 네트워크 접근 권한을 부여한다.
- 사설 인프라 연결(Private Network Access) : 공인 IP가 없는 사설 망(ex. 오픈스택 인스턴스)에 외부 사용자가 직접 접근할 수 있도록 암호화된 통로를 제공한다.
- 트래픽 암호화 및 가속 : 사용자의 트래픽을 최단 경로의 Cloudflare Edge(전 세계 글로벌 네트워크)로 전송하며, WireGuard 프로토콜을 사용하여 암호화된 터널을 유지한다.
- WARP를 통한 연결의 동작 원리
- WARP가 사용자 단말에서 오픈스택 인스턴스까지 트래픽을 전달하는 과정은 4단계의 레이어로 구분된다.
- 1_ 터널 수립 및 인증 (Client to Cloudflare Edge)
- WireGuard 프로토콜 : WARP 클라이언트는 현대적인 암호화 기술인 WireGuard를 사용하여 가장 가까운 Cloudflare Edge 데이터 센터와 UDP 기반의 터널을 생성한다.
- Identity 확인 : 사용자가 팀 이름과 이메일 OTP를 입력하면, Cloudflare의 Access 정책 엔진이 가입된 기기인지, 허가된 사용자인지 검증한다.
- 2_ 패킷 가로채기 및 라우팅 (Request Interception)
Split Tunnel링: WARP 클라이언트는 사용자 PC에서 나가는 모든 패킷의 목적지 IP를 감시한다.- CIDR 대역 매칭 : 사용자가 설정한 192.168.35.0/24 대역의 패킷이 감지되면, WARP는 이를 일반 인터넷망으로 내보내지 않고 Cloudflare 터널 내부로 강제 라우팅(Intercept)한다.
- 3_ 글로벌 네트워크 스택 매칭 (Cloudflare Edge Logic)
- 라우팅 테이블 조회 : Cloudflare Edge 서버는 수신된 패킷의 목적지(192.168.35.207)를 보고, 이 IP 대역이 어느 팀의 터널(Connector)에 할당되어 있는지 조회한다.
- Virtual Interface 연결 : Test 팀에 등록된 특정 cloudflared(사용자 노트북에서 실행 중인 서비스)를 찾아 패킷을 캡슐화하여 전달한다.
- 4_ 데이터 전달 및 응답 (Connector to Infrastructure)
- Tunnel Exit : 사용자의 오픈스택 호스트(노트북)에서 실행 중인 cloudflared는 Cloudflare로부터 받은 패킷을 복호화한다.
- Local Delivery : 복호화된 패킷은 호스트의 커널 네트워크 스택을 통해 실제 사설 IP를 가진 가상 머신(인스턴스)으로 전달된다.
- 호스트 모니터링에 사용된 PromQL 해석
- Host OS Load (1m)
- 쿼리 :
node_load1{instance="localhost:9100"} - 해석 : 최근 1분 동안 실행 대기 중이거나 디스크 I/O를 기다리는 프로세스의 평균 개수. 물리 코어 수와 비교하여 시스템 과부하 여부를 즉각 판단하는 기준이 된다.
- 쿼리 :
- Total CPU Usage (%)
- 쿼리:
100 - (avg by (instance) (irate(node_cpu_seconds_total{mode='idle'}[1m])) * 100) - 해석
- node_cpu_seconds_total{mode='idle'} : CPU가 아무것도 하지 않은(유휴) 시간만 추출한다.
- irate(...[1m]) : 최근 1분간의 변화율을 계산하여 실시간성을 높인다.
- avg by (instance) : 여러 개의 CPU 코어 값을 하나로 평균 낸다.
- 100 - ... : 100%에서 노는 시간(idle) 비율을 빼서 실제 사용률을 구한다.
- 쿼리:
- Total RAM Usage (%)
- 쿼리:
(1 - (avg by (instance) (node_memory_MemAvailable_bytes) / avg by (instance) (node_memory_MemTotal_bytes))) * 100 - 해석: 실제 사용 가능한 메모리(MemAvailable)를 전체 메모리(MemTotal)로 나누어 비율을 구한 뒤, 1에서 빼서 현재 점유 중인 메모리 비율을 백분율로 환산한다.
- 쿼리:
- Root Disk Usage (%)
- 쿼리:
100 - (sum by (instance) (node_filesystem_avail_bytes{mountpoint='/etc/hosts'}) / sum by (instance) (node_filesystem_size_bytes{mountpoint='/etc/hosts'}) * 100) - 해석 : 특정 마운트포인트(/etc/hosts)의 남은 용량과 전체 용량 비율을 계산한다. sum by (instance)를 사용하여 여러 파티션 라벨이 섞여도 해당 인스턴스의 합계로 정확히 연산하도록 한다.
- 쿼리:
- Network Throughput (Mbps)
- 쿼리:
(sum(rate(node_network_receive_bytes_total{device!~'lo|...'}[1m])) + sum(rate(node_network_transmit_bytes_total{...}[1m]))) * 8 / 1024 / 1024 - 해석
- rate(...[1m]) : 초당 전송되는 바이트(Byte) 수를 구한다.
- device!~'lo|...' : 루프백이나 가상 인터페이스를 제외하고 실제 물리 인터페이스만 합산한다.
- * 8 : Byte를 bit 단위로 변환한다.
- / 1024 / 1024 : 최종적으로 Mbps 단위로 정규화.
- 쿼리:
- Disk IOPS (ops/s)
- 쿼리 :
sum(rate(node_disk_reads_completed_total[1m])) + sum(rate(node_disk_writes_completed_total[1m])) - 해석 : 1분 동안 완료된 읽기 작업과 쓰기 작업의 초당 발생 횟수를 합산한다. 디스크가 물리적으로 처리하고 있는 '일의 양'을 가장 직접적으로 보여준다.
- 쿼리 :
- 앤서블 기본 작동 원리 및 구성 요소
- 앤서블은 에이전트리스 아키텍처를 기반으로 하는 구성 관리 및 오케스트레이션 도구이다.
- Push 모델
- 앤서블은 제어 노드에서 관리 대상 노드로 명령을 밀어넣는 Push 모델을 따른다.
- 인벤토리 읽기 : 제어 노드는 접속할 서버의 목록(IP, 접속 정보)이 인벤토리를 확인한다.
- 모듈 전송 : 실행할 작업에 해당하는 파이썬 코드(모듈)를 관리 대상 노드의 임시 디렉토리로 복사한다.
- 원격 실행 : 대상 노드에 설치된 파이썬 인터프리터를 통해 해당 모듈을 실행한다.
- 결과 반환 및 삭제 : 실행 결과(성공, 실패, 변경 여부)를 JSON 형태로 제어 노드에 반환한 뒤, 임시 복사했던 모듈 파일을 삭제한다.
- 주요 구성 요소
- 제어 노드 : 앤서블이 설치되어 명령을 내리는 서버
- 관리 대상 노드 : 명령을 수행한은 타켓 서버. 별도의 에이전트 설치가 필요 없고 SSH 서비스만 구동 중이면 된다.
- 모듈 : 특정 작업을 수행하기 위해 사전에 정의된 프로그램 단위 (ex. apt)
- Playbook 특성
- 플레이북 : 앤서블이 수행해야 할 작업을 기술한 YAML 형식의 설정 파일
- 선언적 : 어떤 명령을 실행하라는 절차적 방식이 아닌, 시스템이 어떤 상태가 되어야 한다는 최종 상태를 정의한다.
- 멱등성 : 동일한 플레이북을 여러 번 실행해도 시스템이 이미 정의된 상태와 일치한다면 아무런 변경도 가하지 않아 결과의 일관성을 보장한다.
- 구조 : 하나 이상의
Play로 구성되며, 각 Play는 특정 호스트 그룹을 대상으로 수행할Task들의 집합으로 이루어진다.
- 플레이북 : 앤서블이 수행해야 할 작업을 기술한 YAML 형식의 설정 파일
- 원격 서버 접속 방식 (SSH)
- 인증 정보 참조 : 인벤토리 파일이나 환경 변수에서 IP, 계정명, SSH 개인키 경로 등의 정보를 가져온다.
- 보안을 위해 패스워드 방식보다는 SSH 키 페어 방식을 주로 사용한다.
- StrictHostKeyChecking=no 옵션을 사용하여 초기 접속 시 호스트 키 확인 절차를 자동화한다.
- 일반 유저로 접속한 뒤 관리자 작업이 필요한 경우 become: yes 설정을 토앻 sudo 권한을 획득한다.
- 대규모 프라이빗 클라우드에서의 자동화 운용 전략
- 수천 대 규모의 서버 환경에서는 정적인 관리 방식으로는 한계가 있다.
- 동적 인벤토리 : 물리 서버나 가상 머신의 증설/삭제가 빈번한 대규모 환경에서 서버 목록을 수동으로 관리할 수 없다.
- API 연동 : 오픈스택이나 AWS의 API를 호출하여 가동 중인 서버 정보를 실시간으로 수집하는 스트립트를 인벤토리로 사용
- 태깅 기반 그룹화 : 서버의 역할에 따라 태그를 부여하고 앤서블은 태기를 기준으로 특정 그룹에만 정책을 배포
- 인프라 생명주기 관리 자동화
- 자원 생성부터 회수까지의 전체 라이프사이클을 도구별로 분담하여 자동화
- Day 0 (Provisioning) / Day 1 (Configuration) / Day 2 (Optimization)
- 병렬 처리 및 성능 최적화
- 수천 대 규모의 서버 환경에서는 정적인 관리 방식으로는 한계가 있다.
