#주저리주저리
최근 JAVA로 알고리즘 공부를 하면서 Scanner를 사용하면 Fail이 나오지만, BufferedReader를 사용하면 통과하는 기상천외한 상황을 겪으면서.. 이와 관련된 게시글들을 찾아보게 되었다.
그 과정에서 내가 사용하던 BufferedReader는 기존 System.in이라는 Node Stream에 byte 데이터를 char 데이터로 받아와주는 InputStreamReader라는 보조 스트림에 덧붙혀져서 사용되는 형태라는 것을 알게 되었는데, 여기서 한 가지 의문이 발생했다.
'대체 왜? 내가 입력하는 데이터를 버퍼에 저장한다고 왜 입력 속도가 4~5배는 빨라지는 거지?'
물론 유튜브나 기타 스트리밍 사이트에서 불규칙적인 네트워크 환경으로 인한 끊킴 현상을 버퍼를 사용해 해결할 수 있다는 것까지는 이해할 수 있다.
하지만... 내가 직접 키보드로 입력해서 내 컴퓨터에서 보는데.. 대체 버퍼를 사용할 일이 뭐가 있으며 이게 이렇게 효과가 있다는 것도 이해가 되지 않았다.
따라서 이번 기회에 확실히 버퍼에 대한 개념을 잡고, 더 나아가 BufferedReader와 Scanner의 차이에 대해서 알아보려한다.
버퍼란?
Buffer란 말이야 거창하지, 결국 임시 저장 공간이다.
아마 개발자라면 더 자주 접하고 잘 알고 있는 캐시 또한 버퍼의 한 종류다.
캐시는 속도 차이가 있는 두 장치 사이에서 그 차이로 인한 문제를 해결하기 위해 사용된다
그리고 버퍼 역시 마찬가지다. 그렇다면 두 기술의 차이는 무엇일까?
바로 데이터를 사용 후에 폐기하냐 안하냐의 차이다.
버퍼는 속도가 빠른 장치에서 들어오는 모든 데이터를 잠시 저장해놓고 버퍼가 꽉 차거나, 특정 커맨드를 입력받았을 때 일괄적으로 내보내고, 버퍼를 초기화시킨다. 즉, 속도가 느린 장치에서 일을 여러번 하지 않도록 속도가 빠른 장치에서 미리미리 처리해두고 "버퍼"라는 임시 공간에 보관해두었다가 한번에 넘겨주는 것이다.
간단한 예를 들어보자. A라는 사람이 이사를 가려고 한다.
여기서 게으른 친구 B 혹은 성실한 친구 C는 짜잘한 잡동사니들을 필요한 것들을 하나씩 찾아서 A에게 가져다주면, A는 트럭을 타고 이사 가는 곳으로
옮긴다고 가정하자.
그럼 여기서 게으른 B는 A의 트럭이 있을때만 잡동사니를 가져와서 옮기고, A는 하나라도 트럭에 실리면 바로 출발하는 것
이게 버퍼없이 동작하는 과정이다.
반면, 성실한 C는 지게차에다가 찾아놓은 잡동사니들을 가져다놓고, A는 C가 모아놓은 잡동사니들을 트럭에 한번에 싣고 옮기는 것
이게 버퍼가 있을 때 동작하는 과정이라고 비유할 수 있다.캐시 역시 마찬가지로 임시 저장해놓지만, 지역성의 원칙에 의거하여 사용 후에도 저장해놓고 해당 서비스에서 정해놓은 LRU 등의 캐시 교체 알고리즘에 따라 빠르고 효율적으로 엑세스할 수 있도록 지속적으로 사용한다.
즉, 간단히 말하자면 다음과 같이 정리할 수 있다.
- 캐시는 한번 접했던 데이터를 다시 접근할 때 굳이 속도가 느린 장치에 엑세스하지 않고 빠르게 가져올 수 있도록 하는 것
- 버퍼는 애초에 데이터를 가져올 때, 속도가 느린 장치로 인해서 속도가 빠른 장치가 일을 쉬는 것을 방지하여 더 빠르고 안정적인 퍼포먼스를 내게 하는 것
여기까지가 Buffer와 Cache의 차이와 Buffer의 기본적인 개념과 원리다.
사실 Cache는 앞으로 설명할 부분에는 필요없지만, Buffer에 대한 확실한 개념을 잡기 위해 잠깐 특별 게스트로 모셔온 것이다...ㅎ
그렇다면 BufferedReader는 뭐고, Scanner는 대체 어떻게 동작하길래 속도차이가 이렇게 극심한 것일까?
BufferedReader vs Scanner
서론
BufferedReader에 대해서 제대로 알아보기 위해서는 Stream에 대한 기본적인 개념과 노드 스트림, 보조 스트림에 대해서 알아야한다. 이와 관련해서 간단하게 설명하자면, 노드 스트림은 하나의 스트림에 주축을 이루는 요소이고, 보조 스트림은 이 노드 스트림을 통해 들어오거나, 나가는 데이터를 잘 처리하여 효율적으로 사용하기 위해 사용되는 일종의 플러그인이다.
따라서 노드 스트림은 반드시 하나이며, 보조 스트림은 없거나 많을 수 있다.
여기서 BufferedReader는 바로 보조 스트림의 하나이다.
자 그럼 여기서 보조 스트림이 대체 뭔지는 잘 모르겠지만, BufferedReader가 보조 스트림의 하나라는 것만 기억하고 아래를 보자.
BufferedReader와 Scanner의 사용 예시 비교
이 글을 보고있는 사람들이라면 System.in이 매우 익숙할 것이다.
아래와 같은 구성을 매우 자주! 보았을 것이다.
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
Scanner sc = new Scanner(System.in);하지만 좀 더 직관적인 예시를 위해 다른 케이스들을 한번 살펴보자.
만약 우리가 매번 직접 입력하기 너무 귀찮아서 파일에서 읽어오도록 하려면 어떻게 해야할까? 아마 구글링해보면 기본적으로 FileInputStream과 FileReader가 나올 것이다.
여기서 FileInputStream을 사용해서 각각을 구성해보면 아래와 같다.
1. 기존 System.in을 FileInputStream으로 바꾸기
BufferedReader br = new BufferedReader(new InputStreamReader(new FileInputStream("input.txt")));
Scanner sc = new Scanner(new FileInputStream("input.txt"));여기서 우리는 Scanner와 BufferedReader의 한가지 공통점을 알 수 있다.
바로 System.in 이라는 부분이 new FileInputStream("input.txt")로 바꼈다는 것이다.
2. Scanner의 파라미터를 BufferedReader와 동일하게 변경하기
그리고 여기서 굉장히 재밌는 부분을 발견할 수 있다. 만약, 둘의 파라미터를 BufferedReader에 맞춰서 동일하게 설정하면 어떨까?
BufferedReader br = new BufferedReader(new InputStreamReader(new FileInputStream("input.txt")));
Scanner sc = new Scanner(new InputStreamReader(new FileInputStream("input.txt")));잘 동작한다. 그럼 Scanner에 맞춰서 변경하면?
3. BufferedReader의 파라미터를 Scanner와 동일하게 변경하기
BufferedReader br = new BufferedReader(new FileInputStream("input.txt"));
Scanner sc = new Scanner(new FileInputStream("input.txt"));바로 에러가 발생한다.
4. 각각의 파라미터를 FileReader로 변경하기
그럼 만약 여기서 FileReader를 사용해서 구성하면 어떻게 해야할까?
BufferedReader br = new BufferedReader(new FileReader("input.txt"));
Scanner sc = new Scanner(new FileReader("input.txt"));위처럼 구성할 수 있다.
잘보면 BufferedReader에서 new InputStreamReader가 빠졌다는 것을 알 수 있다.
왜 이런 구조를 지니는 것일까?
BufferedReader는 버퍼링을 제공해주는 보조 스트림 라이브러리이고,
Scanner는 파라미터에 담긴 스트림에 따라 오버로딩을 통해 Scanner의 메소드를 사용하기 위한 스트림 형태로 변경해주는 편의를 제공하는 라이브러리이기 때문이다.
Stream?
수수께끼같은 소리는 그만하고 본론으로 넘어가보자.
Scanner와 BufferedReader의 파라미터에 들어가는 것들은 스트림이다.
모든 스트림은 데이터 타입 ( Char 또는 Byte ), 방향 ( Input 또는 Output )에 따라 결정되며, 노드 스트림은 추가적으로 노드 타입 ( File 또는 키보드 등등 )에 따라 결정되고 보조 스트림은 기능에 따라 결정된다.
위의 예시에서 노드 스트림은 FileInputStream, FileReader이며,
보조 스트림은 BufferedReader, InputStreamReader가 여기에 해당한다.
단, FileInputStream는 데이터 타입이 Byte로 반환되는 반면, FileReader, BufferedReader, InputStreamReader는 Char로 반환된다.
눈치 빠른 사람들은 이미 알아차렸을텐데, 바로 ~~Reader냐, ~~Stream이냐에 따라 이 데이터 형태가 결정된다는 것이다.
( System.in은 시스템 상에서 기본적으로 설정된 입력 스트림을 의미하므로 이러한 명칭 컨셉을 따르지 않는다. System.in이 Stream이 될수도, Reader가 될 수도 있으며, File 입력이 될 수도 있다 )
즉, BufferedReader는 보조스트림으로써 Char 데이터를 반환한다는 것을 알 수 있다.
하지만 BufferedReader는 말그대로 보조스트림이기 때문에, 직접적으로 데이터를 Char 형태로 받지 못하고, 이전의 데이터가 Char 형태로 넘어와야 버퍼링을 적용하여 반환해줄 수 있다.
이 때 사용되는 것이 바로 InputStreamReader이다. InputStream -> Reader로 변환해주는 녀석으로 Byte 형태를 Char 형태로 변환해준다.
그럼 BufferedReader가 아닌, BufferedInputStream을 사용하면 되는 것이 아닌가 하는 생각이 들 수 있다. 하지만 한글의 경우, 영어와 달리 1Byte가 아닌 3Byte로 구성되어 있기 때문에 Char형태로 받지 않으면 엉뚱한 기준으로 끊켜버리기 때문에 최소한 국내에서는 BufferedReader를 사용해서 입력받는 것이 좋다.
간단하게 위 내용을 정리해보자면 우리가 알고리즘을 사용할 때 System.in이 기본적으로 키보드 입력을 받고 이를 Byte 형태로 전달해주기 때문에, BufferedReader를 사용하기 위해서는 반드시 Char형태로 변환해주는 InputStreamReader가 필요하구나! 라고 생각할 수 있다. 반면, File데이터를 그대로 받아오는 노드 스트림인 FileReader에 적용할 때는 바로 적용할 수 있는 것이다.
Scanner의 편의성 - 성능차이 원인 (1)
지금까지 BufferedReader와 Stream 개념을 엮어서 왜 우리가 BufferedReader를 저런 형태로 사용하고 있는지 알아보았다.
이제 Scanner가 왜 더 느린지에 대해 설명해보려 한다.
우선 위의 예시에서 필자는 Scanner가 사용자에게 편의를 제공해준다고 했다.
즉, 사용자가 원하는대로 최대한 기능을 제공해주려고 한다는 것이다.
위 예시를 통해 Scanner는 BufferedReader와 달리 오버로딩을 통해 어떤 형태의 스트림이던간에 내부적으로 알아서 처리하도록 설정되어 있다는 것을 알 수 있다.
(Byte 스트림이 들어오면 내부적으로 InputStreamReader로 변환해줌)
그 뿐만 아니라 BufferedReader는 반드시 char 형으로 입력받는 대신, Scanner는 nextInt(), nextDouble() 등의 메소드가 있다.
하지만 nextInt()라고 해놓고 우리가 정말 int형태로 데이터를 줄지 어떻게 보장할 수 있을까?
우리의 입력값은 런타임 이전에는 알 수 없는 부분이다. 그러나 우리의 Scanner는 무진장 친절해서 개떡같이 작성해도 이를 정말 int로 바꿀 수 없는지 여러 예외적인 케이스들에 대해서도 정규식을 통해 검증해준다.
따라서 이런 변환 과정과 정규식으로 올바른 형태인지 판단하는 과정에서 추가적인 시간이 소모되는 것이다
데이터 입력에서 버퍼의 동작 - 성능차이 원인 (2)
또한 위에서 보조스트림은 해당 기능에 따라서 명칭이 구분된다고 했다.
즉, BufferedReader는 기존 스트림에 버퍼라는 임시공간을 제공해주는 보조 스트림이라는 것을 알 수 있다.
반면 Scanner는 사용자에게 편한 인터페이스 ( 스트림 자동 변환, Type Converting ) 는 제공해주지만 버퍼 기능은 제공해주지 않는다.
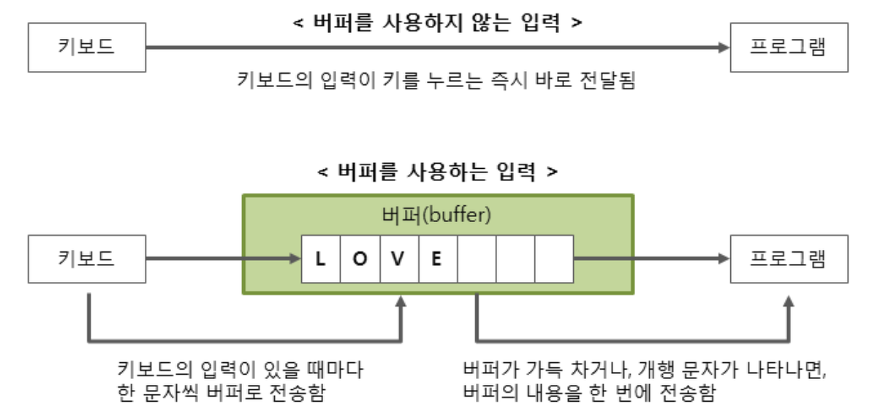
그렇다면 데이터 입력에서 버퍼는 대체 왜 사용되는 것일까.
위의 버퍼 개념 예시에서 말했듯, 입력이 발생하면 그 즉시, 한 Byte 혹은 한 Char 형태로 전달되기 대문이다.
하나의 글자 및 Byte의 입력에 대해 매번 프로그램에 끌어다 사용해야하는 I/O가 발생한다.
하지만 버퍼를 사용하면 입력을 보아두고 있다가 버퍼의 크기 및 특정 키워드를 기반으로 잘라서 통째로 전달하는 방법으로 시간을 단축시킬 수 있는 것이다.
그렇기에 버퍼링 기능이 탑재된 BufferedReader가 Scanner에 비해 뛰어난 성능을 보이는 것이다
마치며
평소 버퍼에 대한 개념을 확실하게 한번 정리하고 싶었는데, 마침 좋은 계기가 생겨 열정적으로 공부하고 정리해본 것 같다...
원래 공부한 내용을 정리해보고, 남한테 내 생각을 쉽고 간단하게 정리해서 전달하는 능력을 키우기 위해서 블로그를 작성하게 된건데...적고보니 생각보다 양이 너무 많아지고 두서가 없는 것 같다ㅋㅋㅋㅋㅋㅋㅋ
아무튼 이번 기회로 버퍼에 대해 다시는 잊지 않도록 확실하게 정리할 수 있었던 것 같다.
혹시 나처럼 매번 까먹고 헷갈리는 사람들도 이 글을 통해 조금이나마 도움이 됐으면 좋겠다.
