ElasticSearch란?
ElasticSearch는 Apache Lucene기반의 자바 오픈소스 분산 검색 엔진이다.
이것도 데이터베이스처럼 따로 데이터를 json 형태로 저장하고 있다.
하지만 일반적인 데이터베이스는 데이터를 저장하고 관리하는데에 범용적인 목적을 두고 있다면, ElasticSearch는 정말 특정 키워드로 검색(Full Text Search)하는 속도를 증진시키는데에 전용적인 목적을 둔 느낌이 강했다.
이는 ElasticSearch에서 역 인덱스(Inverted Index)라는 자료구조를 사용하여 구성되기 때문에 가질 수 있는 특징이다.
기존 DB에서는 실질적인 데이터들을 직접적으로 탐색하면서 원하는 데이터를 검색했다면, ES에서는 원하는 데이터의 위치를 가르키는 테이블을 통해 원하는 문서를 가져오는 구조로 설계되어있다.
ElasticSearch가 사용되는 기능
특정 키워드로 검색하는 데에 강점을 지닌 만큼, 문자열 관련 서칭이 들어가는 기능에 유용하게 사용된다.
- 검색 기능
- 로깅 및 로그 분석
ElasticSearch 구성요소
Elasticsearch에서 사용되는 기본 개념/단위들, 혹은 구조에 대해서 알아보자
논리적 요소
기존 RDB와 매핑되는 개념으로 보면 조금 더 이해가 빠를 것 같아 비교 사진을 첨부하였다.
여기서 추가적으로 ElasticSearch의 주요 구성요소들이 RDB와 매핑되는 부분에서 어떤 점이 다른지 살펴보자
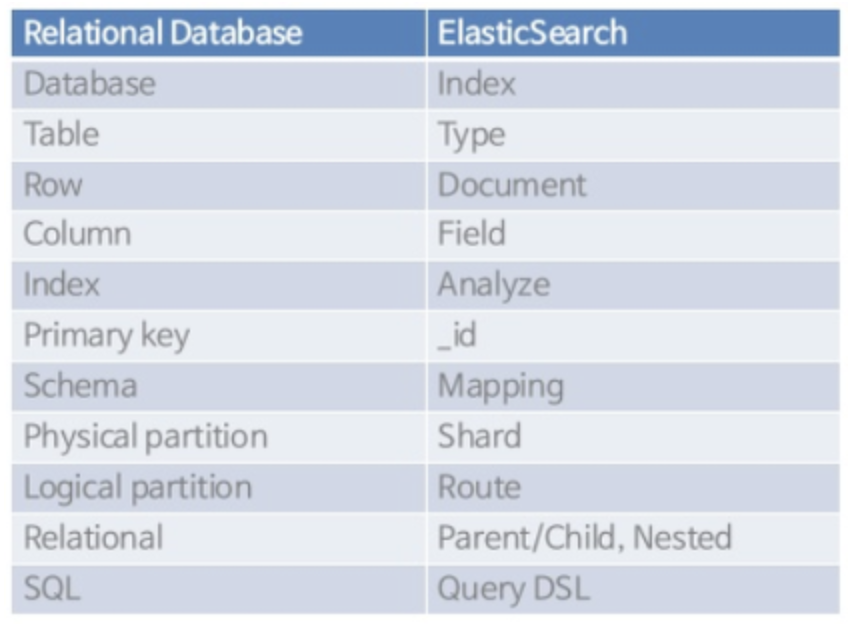
- Type
- 여러개의 Document가 모여 하나의 Type을 이룬다. (Elasticsearch 7.0부터 Type이 완전히 사라짐)
→ 즉, RDB로 따지면 데이터베이스 개념이 사라지고 테이블이 각각의 최상단에 구성돼있는 형태로 변경되었다고 생각하면 이해가 편할 것 같다.
- Index
- 여러개의 Type이 모여 하나의 Index를 이룬다. ( Elasticsearch 6.1부터 하나의 index는 하나의 type만 가질 수 있도록 변경됨 )
- 쿼리 하나로 여러 Index를 동시에 조회할 수 있다.
- 하나의 Index는 여러 노드에 분산 저장/관리된다.
→ Index가 DB와 매핑된다고 했는데, Type이 사라지면서 이러한 특징이 이제는 RDB에서 여러 테이블을 동시에 조회하는 것과 유사한 느낌으로 이해하면 될 것 같다.
- Document
- MongoDB와 유사하게 JSON Object 하나의 단위를 의미한다.
- 각각의 필드에 대응되는 값들이 저장된 최소 단위의 데이터이다.
- Field
- 각 데이터를 구성하는 값들의 Key 혹은 Attribute를 나타낸다.
- 스키마에 대한 제한이 없고 들어가는 데이터 구조에 대해서도 유연하다.
→ 원자성을 지키지 않아도 되고 필드 값이 Document가 되어도 된다. ( = MongoDB )
물리적 요소
노드
- 하나의 클러스터를 구성하는 서버의 단위를 의미한다.
- 데이터가 커질 때, 기존 RDB는 보통 Scale-Up 방식을 사용하지만, Elasticsearch는 노드를 추가하는 방식으로 Scale-Out에 유용하다. ( NoSQL도 Scale-Out이 비교적 용이하지만, Elasticsearch는 애초에 분산 환경을 목적으로 만들어져 손쉽게 할 수 있다 )
- 하나의 노드에 문제가 발생하더라도 클러스터 환경으로 유연하게 대처가 가능하다.
샤드
- 인덱스에 색인된 데이터들이 집중되어 있지 않고, 물리적 공간에 N분할되어 산재되어 있다. 각각을 샤드라고 한다.
- 따라서 하나의 물리적 공간에 구애받지 않고 따로따로 분할하여 저장함으로써 확장에 용이하다.
- 여러 샤드에서 병렬적으로 처리가 가능하기 때문에 거의 실시간으로 결과를 도출할 수 있다.
→ 성능, 처리량 ↑
세그먼트
-
문서의 빠른 검색을 위한 자료구조
→ 역 인덱스 구조로 설계되어 있음
-
각 샤드는 여러개의 세그먼트로 구성되어 있다.
→ 검색 요청을 분산처리하여 효율적인 검색이 가능
-
세그먼트는 immutable (불변)이다.
→ 주기적인 세그먼트 통합을 제외하고는 수정을 일절 허용하지 않는다.
→ 데이터를 저장하면, 메모리에 데이터를 보관해두다가 새로운 세그먼트를 디스크에 기록하고 검색 대상에 추가시킨다.
→ 데이터를 수정하면 기존 세그먼트를 삭제 표시만 해두고, 수정된 데이터로 새로운 세그먼트를 생성한다.
-
Commit Point라는 자료구조를 통해 세그먼트들을 관리한다.
-
주기적인 세그먼트 통합이 이뤄진다.
→ 불변성으로 인해 세그먼트가 단시간내에 빠르게 추가되는데, 세그먼트 갯수가 많아지면 성능이 저하되기 때문에 세그먼트들을 통합하거나, 삭제 표시된 세그먼트를 처리하는 작업을 취한다.
ElasticSearch의 특징
- 분산 / 확장성 / 병렬처리
초기부터 분산 시스템을 염두에 두고 개발이 되었다. 여러개의 노드로 이루어진 클러스터로 구성되어 있고 각각 샤드로 분리되어 있지만 복사본이 저장되어 있어 데이터가 안정적으로 보장될 수 있다.
또한, 운영 중에도 노드가 추가되면 샤드를 적절히 재분배하도록 설계되어 있어 스케일 아웃에도 유연하며 병렬처리 기능도 제공하여 실시간 검색에도 무리없이 작동할 수 있다.
- 고가용성
동작 중에 죽은 노드를 감지하고 삭제하는 과정을 통해 일부 노드에 문제가 발생하더라도 문제 없이 서비스를 제공할 수 있는 고가용성을 지니고 있다.
- 멀티 테넌시
기존의 RDB에서는 각각 다른 데이터베이스의 데이터를 검색하기 위해서는 별도의 Connection을 생성해야한다. 하지만 ES에서는 하나의 쿼리나 그룹 쿼리로 여러 인덱스의 데이터를 검색할 수 있다.
- 문서 중심 & Schemaless → NoSQL
NoSQL과 유사한 데이터 구조를 지니기 때문에 NoSQL의 특징을 지닌다
References
