📍hash
해시의 대략적인 개념들 먼저 알아보자.
[ 해시함수(hash function) ]
- 데이터의 효율적 관리를 목적으로 임의의 길이의 데이터를 고정된 길이의 데이터로 매핑하는 함수
- 해시함수의 해시값이 최대한 균등하게 나오게 하는게 중요하다!
[ 해싱(hashing) ]
- 키(key) : 매핑 전 원래 데이터의 값
- 해시값(hash value) : 매핑 후 데이터의 값
매핑하는 과정 자체를 해싱이라 한다.
[ 해시충돌(collision) ]
- 해시함수는 해시값의 개수보다 대개 많은 키값을 해쉬값으로 변환(many-to-one 대응) 하기 때문에 해시함수가 서로 다른 두 개의 키에 대해 동일한 해시값을 내는 해시충돌이 발생하게 된다.

- 그래서 충돌을 최소화할 수 있는 해시함수를 사용해야한다.
📍 Hash table (hash map)
[ Map ]
- 정의 : 특정 순서에 따라 키와 매핑된 값의 조합으로 형성된 자료구조
- 구현체 : hash table, tree-based
[ Hash table (hash map) ]
- 정의 : 배열과 해시 함수(hash function)를 사용하여 map을 구현한 자료구조
- 키에 대한 해시 값을 사용하여 값을 저장하고 조회하며, 키-값 쌍의 개수에 따라 동적으로 크기가 증가하는 associate array
- 그래서 일반적으로 상수 시간으로 데이터에 접근하기 때문에 빠르다.
조금 더 자세하게 hash table에서 해시함수는 임의의 데이터를 정수로 변환해 준다!
-
이때 데이터가 저장되는 곳은 버킷(bucket) 또는 슬롯(slot) 이라고 한다.
- 메모리를 절약하기 위하여 객체에 대한 해시 코드의 나머지 값을 해시 버킷 인덱스 값으로 사용한다.
- (HashMap을 비롯한 많은 해시 함수를 이용하는 associative array 구현체에서) -
저장/조회할 해시 버킷을 계산하는 방법
int index = X.hashCode() % M;1) 데이터 삽입
- 예시: 데이터를 저장하는 과정
ex. put("John Smith", "521-1234")
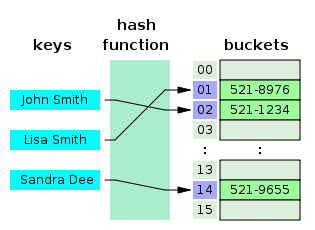
현재 버킷의 capacity는 16이다.
- 이 경우에 key 값이 hash function에 나온 결과 210 % 16를 하면 값은 2가 된다. 이 2는 Index 2번 위치에 저장하라는 말이 된다.
| Index(Hash Value) | Data |
|---|---|
| 01 | (Lisa Smith, 521-8976) |
| 02 | (John Smith, 521-1234) |
2) 데이터 조회
ex. get("Jeongyoon Park")
- 동일하게 hash function에 값을 돌리고 226 % 16를 하면 값은 2가 된다. 이때 2 인덱스에 찾으러 갔을 때 Data는 (John Smith, 521-1234)가 저장되어 있다.
- John Smith와 Jeongyoon Park을 비교했을 때 값이 다르기 때문에 값을 찾지 못하고 종료한다.
💥 Hash collision (해시 충돌)
- key는 다른데 hash가 같을 때
- key도 hash도 다른데 hash % map_capacity 결과가 같을 때
보통의 경우는 실제로 사용하는 key 개수보다 적은 해시테이블의 크기를 가질 것이다.
- 다뤄야 할 데이터가 정말 많고, 메모리 등 리소스 문제도 생기기 때문이다.
- 위에서도 간단하게 설명했지만 해시함수는 해시값의 개수보다 대개 많은 키값을 해쉬값으로 변환(many-to-one 대응) 하기 때문에 줄어든 범위에서 충돌이 발생할 수밖에 없다.
그렇기 때문에 해시함수의 해시값이 최대한 균등하게 나오게 하는 게 중요하다!
[ 해결 방법 ]
1. open addressing (개방 주소법)
해당 버킷에 데이터가 이미 있는데 key 값이 다르면 충돌이 발생한다. 이런 경우에 아래 Separate chaining과 다르게 open addressing 방식은 비어있는 버킷을 활용한다.
- 즉, open addressing은 한 버킷당 들어갈 수 있는 엔트리가 하나뿐인 해시테이블이다.
이것을 구현하는 방법에는 3가지가 있다.
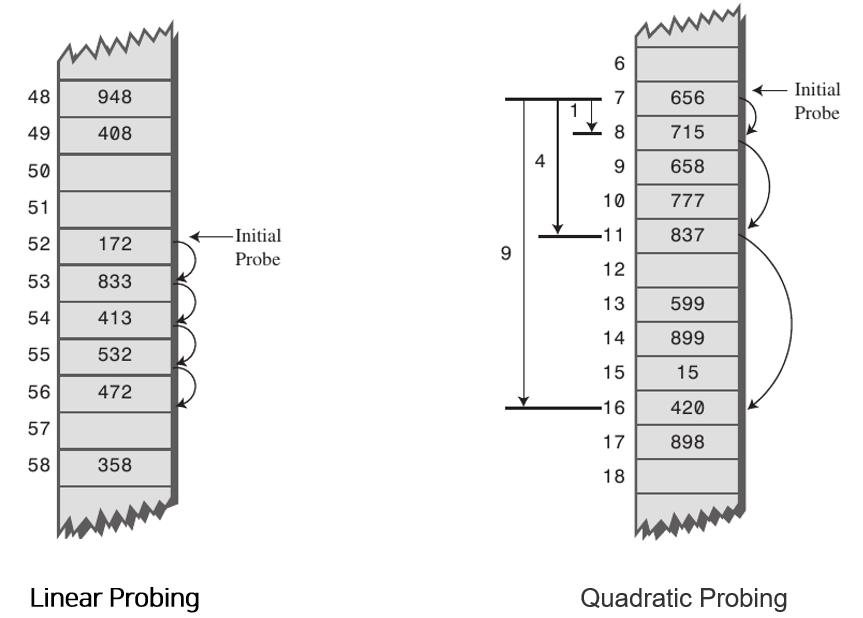
- Linear Probing(선형 조사법): 현재 버킷의 index에서 고정폭만큼씩 이동하여 비어 있는 버킷에 저장한다.
- Quadratic Probing(이차 조사법): 현재 버킷의 index에서 제곱수만큼씩 이동하여 비어 있는 버킷에 저장한다.
- ex. 처음에는 1만큼 이동하고 그다음 계속 충돌이 발생하면 2^2, 3^2칸씩 이동하는 방식
- 선형 조사법과 이차 조사법의 경우 충돌 횟수가 많았지만 특정 영역에 데이터가 집중적으로 몰리는 클러스터링현상이 발생하는 단점이 있고 이 경우 평균 탐색 시간이 증가한다.
- Double Hashing Probing(이중 해시, 중복 해시): 이중 해싱은 클러스터링 문제가 발생하지 않도록 2개의 해시 함수를 사용하는 방법이다.

2. Separate chaining (분리 연결법)
간단한 아이디어로 한 버킷당 들어갈 수 있는 엔트리의 수에 제한을 두지 않음으로써 모든 자료를 해시테이블에 담는다.
- 해당 버킷에 데이터가 이미 있는데 key 값이 다르면 충돌이 발생한다. 이때 연결리스트에 노드를 추가하여 데이터를 저장한다.
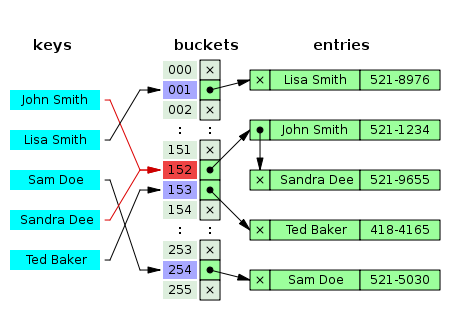
👍 장점
유연하다.
👎 단점
메모리 문제를 야기할 수 있다.
데이터의 수가 많아지면 동일한 버킷에 chaining 되는 데이터가 많아져 캐시의 효율성이 감소한다.
📓출처: https://github.com/devSquad-study/2023-CS-Study/blob/main/java/java_hashmap.md
