Item 78 - 공유 중인 가변 데이터는 동기화해 사용하라
(1) 핵심 정리
- 여러 스레드가 가변 데이터를 공유한다면 그 데이터를 읽고 쓰는 동작은 반드시 동기화 해야 한다.
- 동기화하지 않는다면 한 스레드가 수행한 변경을 다른 스레드가 보지 못할 수도 있다.
- 배타적 실행은 필요 없고 스레드끼리의 통신만 필요하다면 volatile 한정자만으로 동기화할 수 있다. 다만, 올바로 사용하기가 까다롭다.
(2) 동기화의 기능
2.1 배타적 실행
- 한 스레드가 변경하는 중이라면 다른 스레드가 보지 못하게 막는 용도를 말한다.
- 즉, Lock 을 걸어 동시에 여러 스레드가 접근하는 것을 차단한다.
2.2 스레드 사이의 안정적 통신
- 동기화 없이는 한 스레드가 만든 변화를 다른 스레드에서 확인하지 못할 수 있다.
- 즉, Lock 의 보호하에 수행된 모든 이전수정의 최종 결과를 보게 해준다.
(3) 원자적 연산
3.1 원자적 연산
- 중단될 수 없는 연산
- 여러 스레드가 동시에 접근해도 연산 결과가 깨지지 않음
Java에서의 특징:
long,double을 제외한 기본 타입의 읽기/쓰기는 원자적
단, 원자적 = 스레드 안전 은 아니다 ❌
3.2 왜 long / double 은 원자적이지 않을까 ?
- 자바 메모리 모델(JMM)은 32비트 단위 연산을 기준으로 설계됨
long,double은 64비트 → 32비트씩 두 번에 나눠 처리될 수 있음- 이 과정에서 다른 스레드가 끼어들면 찢어진 값(torn read) 발생 가능
3.3 그렇다면 JVM 64-bit machine 에서도 원자적이지 않을까??
- 최신 64-bit JVM에서는 대부분 원자적으로 구현되어 있음
- 하지만 자바 언어 명세(JLS)는 이를 보장하지 않는다
따라서 명세에 의존한 안전한 코드를 작성해야 하며,
volatile또는synchronized사용이 정석이다.
(4) Synchronized
4.1 Synchronized 란 ?
- Java 에서는 synchronized 키워드를 통해 메서드나 블록을 한번에 한 스레드씩 수행하도록 보장한다.
4.2 예제
- 기능
- boolean 필드를 polling 하면서 값을 체크하는 로직으로 Thread 를 정지
-
AS-IS: 무한 루프
public class StopThread { private static boolean stopRequest; public static void main(String[] args) throws InterruptedException { Thread thread = new Thread(() -> { int i = 0; while (!stopRequest) { i++; /** * print 를 하니까 정상 종료 됨 ?? * System.out.println("i: " + i + "stopRequest: " + stopRequest); */ } }); thread.start(); TimeUnit.SECONDS.sleep(1); stopRequest = true; } } -
TO-BE: 1초 후 Stop
public class StopThreadSync { private static boolean stopRequested; // write private static synchronized void requestStop() { stopRequested = true; } // read private static synchronized boolean stopRequest() { return stopRequested; } public static void main(String[] args) throws InterruptedException { Thread thread = new Thread(() -> { int i = 0; while (!stopRequest()) { i++; } }); thread.start(); TimeUnit.SECONDS.sleep(1); requestStop(); } } -
위 예제 코드를 살펴보면 쓰기/읽기 모두 synchronized 키워드가 붙어 있음을 볼 수 있다.
-
즉, 쓰기/읽기 모두 동기화되지 않으면 동작을 보장하지 않는다.
4.3 Thread.stop()을 사용하지 않은 이유
- Thread.stop() 은 안전하지 않아, Java 11 에서 deprecated 되었다.
- 오라클 문서에서는 아래와 같이 설명하고 있다.

- Thread.stop() 을 호출하는 순간, 해당 스레드를 바라보고 있던 다른 스레드들에 대한 lock 이 해제가 된다.
- stop() 메서드가 호출 ---> ThreadDeath exception 전파 ---> 바라보고 있는 스레드의 lock 해제
- 따라서 객체의 일관성을 보장하기 어려울 뿐만 아니라, ThreadDeath 객체는 특별한 경고 없이 스레드를 죽이기 때문에 개발자가 캐치하기 어렵다.
(5) Volatile
5.1 Volatile ?
- Volatile 한정자는 배타적 수행과는 상관없지만 항상 가장 최근에 기록된 값을 읽게 됨을 보장한다.
5.2 예제
public class StopThreadVolatile {
private static volatile boolean stopRequested;
public static void main(String[] args) throws InterruptedException {
Thread thread = new Thread(() -> {
int i = 0;
while (!stopRequested) {
i++;
}
});
thread.start();
TimeUnit.SECONDS.sleep(1);
stopRequested = true;
}
}5.3 Volatile 원리
-
Volatile 키워드가 붙은 데이터는 메인 메모리에 저장이된다.
-
Multi-thread 환경
-
task 를 수행하는 동안 성능 향상을 위해 CPU cache 에 저장하고 활용한다.
-
즉, 각각의 스레드의 CPU cache 에 저장된 값이 다르기 때문에 동시성 문제가 발생한다.
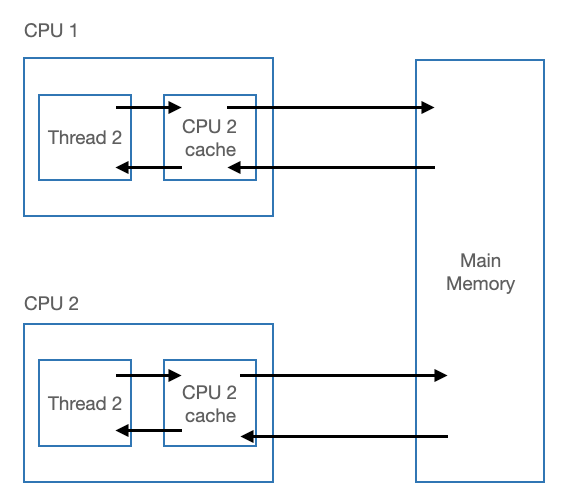
-
- 따라서 Volatile 키워드를 사용하면 해당 변수를 메인 메모리에 저장하고 읽기 때문에 항상 최근에 기록된 값을 읽을 수 있다.
- 하지만 CPU cache 보다 메인 메모리에 접근하면 비용이 더 발생한다.
5.4 Volatile 한계
- 증가 연산자(++) 와 같이 필드를 두 번 접근하는 연산은 한다면 동시성을 보장할 수 없다.
- 따라서 Volatile 키워드는 하나 이상의 스레드가 write 하는 상황에서는 동시성을 보장한다고 볼 수 없다.
👉 실무에서는 volatile를 잘 쓰지 않는다?
- volatile은 가시성만 보장하고 원자성은 보장하지 않는다
- 실무에서 동시성 이슈의 핵심은 대부분 쓰기의 원자성 문제
웹 애플리케이션 특성상
→ 최신 값이 잠시 보이지 않아도 치명적이지 않은 경우가 많음- 그래서 현업에서는 volatile보다 Atomic / Lock / Concurrent 컬렉션을 주로 사용한다
- volatile은 종료 플래그 같은 단순 상태 공유에만 제한적으로 사용됨
Item 79 - 과도한 동기화는 피하라
동기화 안에서 외부 코드(콜백)를 호출하지 마라. → 성능 저하, 예외, 교착상태 위험
-
과도한 동기화 문제
- 성능 나빠짐
- 교착상태(서로 기다리다 멈춤)
- 예상 못 한 버그 발생
- synchronized 블록 안에서 클라이언트가 준 코드(람다, 콜백)를 실행하지 마라
→ 이걸 제어권을 클라이언트에 넘긴다고 함
왜 위험한가?
1️⃣ ConcurrentModificationException
- 동기화된 상태에서
- 관찰자가 자기 자신을 제거
- → 순회 중 컬렉션 수정 → 예외 발생
2️⃣ 교착상태 (Deadlock)
- 메인 스레드가 락 잡고 있음
- 콜백에서 다른 스레드가 락 요청
- 서로 기다리다 멈춤
문제 원인
- 동기화 영역 안에서
- 언제 끝날지 모르는 외부 코드 실행
- 이런 메서드를 열린 호출(Open Call) 이라고 함
해결 방법
방법 1. 스냅샷 떠서 밖에서 실행
synchronized (observers) {
snapshot = new ArrayList<>(observers);
}
for (SetObserver<E> observer : snapshot)
observer.added(this, element);방법 2. CopyOnWriteArrayList 사용
- 동기화 문제 자동 해결
- 관찰자 패턴에 특히 잘 맞음
정리
- 동기화 블록 안에서는 최소한의 일만
- 계산, 콜백, IO → ❌ 밖으로 빼기
Item 80 - 스레드보다는 실행자, 태스크, 스트림을 애용하라
Effective Java 초판에서는 작업 큐(work queue)를 직접 구현하는 방법을 소개했지만, 이는 코드가 복잡하고 동시성 오류에 취약했다. 스레드 생성과 관리, 예외 처리까지 모두 개발자가 책임져야 했기 때문이다.
이후 자바에는 java.util.concurrent 패키지, 즉 Executor Framework가 도입되었다. Executor를 사용하면 스레드나 큐를 직접 다룰 필요 없이 작업 실행을 간단히 처리할 수 있다.
ExecutorService exec = Executors.newSingleThreadExecutor();
exec.execute(runnable);
exec.shutdown();ExecutorService는 작업 실행뿐 아니라 작업 완료 대기, 결과 수집, 주기적 실행 등 다양한 기능을 제공한다. 작은 규모의 프로그램에는 newCachedThreadPool이 적합하며, 기존 스레드를 재사용하고 필요 시 새 스레드를 생성한다. 반면 대규모 애플리케이션에서는 스레드 수가 고정된 newFixedThreadPool을 사용하는 것이 안전하다.
저자가 스레드보다 Executor 사용을 권장하는 이유는, Thread가 작업의 단위와 실행 메커니즘을 함께 가지고 있기 때문이다. Executor Framework에서는 이 둘이 분리된다. 작업의 단위는 태스크이며, Runnable과 Callable이 이에 해당한다. 덕분에 실행 정책을 바꾸더라도 작업 코드는 영향을 받지 않는다.
자바 7부터는 ForkJoinPool을 통해 fork-join 작업을 지원하며, 이를 기반으로 한 parallel stream은 병렬 처리를 더 쉽고 효율적으로 만들어준다.
Item 81 - wait와 notify보다는 동시성 유틸리티를 사용하라
자바는 오래전부터 wait, notify, notifyAll을 통해 스레드 간 협력을 지원해왔다. 하지만 Java 5 이후 도입된 고수준 동시성 유틸리티 덕분에, 이 저수준 메서드들을 직접 사용할 이유는 점점 줄어들었다.
wait / notify란?
-
wait()- 고유 락을 반납하고 스레드를 대기 상태로 만듦
- 반드시
synchronized블록 내부에서 호출해야 함
-
notify()- 대기 중인 스레드 하나를 임의로 깨움
-
notifyAll()- 대기 중인 모든 스레드를 깨움
👉 세 메서드 모두 Object에 정의되어 있다.
wait 사용 시 반드시 지켜야 할 규칙
synchronized (obj) {
while (condition) {
obj.wait();
}
}wait는 조건 검사 반복문(wait loop) 안에서만 사용- 깨어난 뒤에도 조건을 다시 검사해야 함
- 그렇지 않으면 락이 보호하는 불변식이 깨질 수 있음
조건이 충족되지 않았는데 깨어나는 경우
- 다른 스레드가 상태를 변경한 경우
- 실수 또는 악의적인
notify호출 notifyAll로 모든 스레드가 깨어난 경우- 허위 각성(spurious wakeup)
➡️ 이 모든 상황을 고려해야 하므로 구현 난이도가 매우 높다.
synchronized의 한계
- 메서드 진입·탈출 시 오버헤드 발생
- 읽기 전용 작업도 락 때문에 대기
- 락 경쟁이 심해질수록 성능 저하
👉 단순히 synchronized 키워드 하나 차이로도 성능이 크게 달라질 수 있다.
동시성 유틸리티가 필요한 이유
Java 5부터 제공되는 java.util.concurrent는
안전성 + 성능 + 가독성을 모두 개선한다.
주요 동시성 유틸리티 분류
1️⃣ 실행자 프레임워크
ExecutorService,Executors- 스레드 생성과 관리 책임을 프레임워크에 위임
2️⃣ 동시성 컬렉션
ConcurrentHashMap,ConcurrentLinkedQueue- 외부 락 없이 높은 동시성 제공
Collections.synchronizedMap보다 성능 우수
3️⃣ 동기화 장치(Synchronizer)
CountDownLatch: 특정 조건까지 대기Semaphore: 자원 접근 개수 제한- 의도가 명확하고 사용이 안전함
결론
wait와notify는 저수준 도구로 사용이 어렵고 위험하다synchronized기반 설계는 성능과 확장성에 한계가 있다- 특별한 이유가 없다면
👉 동시성 유틸리티를 우선적으로 사용하자
Item 82. 스레드 안전성 수준을 문서화하라
멀티스레드 환경에서 여러 스레드가 동시에 메서드를 호출할 때의 동작 방식은 클래스와 클라이언트 사이의 중요한 계약이다. 하지만 API 문서에 스레드 안전성에 대한 설명이 없다면, 사용자는 스스로 가정을 할 수밖에 없고 이는 심각한 오류로 이어질 수 있다. 동기화가 부족하면 버그가 발생하고, 과도하면 성능이 급격히 저하된다.
따라서 멀티스레드 환경에서도 API를 안전하게 사용하려면, 클래스가 지원하는 스레드 안전성 수준을 반드시 문서로 명확히 밝혀야 한다. 단순히 메서드에 synchronized를 붙였다고 해서 스레드 안전하다고 판단해서는 안 된다.
스레드 안전성 수준 분류
불변 (Immutable)
- 인스턴스 상태가 절대 변하지 않음
- 외부 동기화 불필요
- 예:
String,Long
무조건적 스레드 안전
- 내부 동기화로 항상 안전
- 외부 동기화 필요 없음
- 예:
AtomicLong,ConcurrentHashMap
조건부 스레드 안전
- 기본적으로 안전
- 일부 메서드는 외부 동기화 필요
- 예:
Collections.synchronizedList
스레드 안전하지 않음
- 동시 사용 시 클라이언트가 직접 동기화
- 예:
ArrayList,HashMap
스레드 적대적
- 외부 동기화로도 안전하지 않음
- 주로 정적 필드를 동기화 없이 수정
- 예:
nextSerialNumber++같은 구현
정리
- 모든 클래스는 자신의 스레드 안전성 수준을 문서화해야 한다
- 스레드 안전성은 암묵적인 추측에 맡기면 안 된다
synchronized는 문서화를 대신할 수 없다
Item 83 - 지연 초기화는 신중히 사용하라
1. 지연 초기화란?
- 값이 처음 필요할 때 초기화
- 안 쓰이면 아예 초기화 안 함
2. 언제 쓰나?
- 해당 클래스의 인스턴스 중 그 필드를 사용하는 인스턴스의 비율이 낮고, 그 필드를 초기화하는 비용이 클 때 (hashCode)
- 지연 초기화 적용 전후의 성능을 측정
3. 단점
- 생성은 빨라짐
- 대신 접근할 때 비용 증가
- 멀티 스레드면 동기화 필수
4. 초기화 방법 한눈에 보기
a. 일반 초기화
private final FieldType field = compute();- 가장 안전하고 단순
b. synchronized 접근자
private FieldType field;
private synchronized FieldType get() {
if (field == null) field = compute();
return field;
}- 초기화 순환 문제 해결
- 느림
c. 정적 필드: 홀더 클래스 (베스트)
private static class Holder {
static final FieldType field = compute();
}
static FieldType get() { return Holder.field; }- 빠르고 안전
- 정적 필드 지연 초기화의 정석
d. 인스턴스 필드 + 성능 중요 → 이중 검사
private volatile FieldType field;
FieldType get() {
FieldType r = field;
if (r != null) return r;
synchronized(this) {
if (field == null) field = compute();
return field;
}
}- 초기화 후엔 락 안 씀
- 반드시
volatile
e. 단일 검사 (중복 초기화 OK)
private volatile FieldType field;
FieldType get() {
if (field == null)
field = compute();
return field;
}- 여러 번 초기화돼도 상관없을 때
- 드문 케이스
Item 84 - 프로그램의 동작을 스레드 스케줄러에 기대지 말라
-
멀티스레드 환경에서 어떤 스레드를 얼마나 실행할지는 OS 스레드 스케줄러가 결정한다.
-
스케줄링 정책은 운영체제마다 다르며,
정확성이나 성능이 스케줄러에 의존하는 프로그램은 이식성이 떨어진다. -
좋은 멀티스레드 프로그램의 핵심은
실행 가능한 스레드 수를 프로세서 수보다 과도하게 늘리지 않는 것이다. -
이를 위해 스레드는
- 할 일이 없으면 대기 상태로 전환되어야 하며
- 당장 처리할 작업이 없으면 실행되면 안 된다.
바쁜 대기(Busy Waiting)
-
바쁜 대기란
- 공유 자원의 상태가 바뀌었는지 쉬지 않고 반복 검사하는 방식
-
문제점
- CPU를 소모하면서 아무 일도 하지 않음
- 시스템 전체 성능 저하
-
스레드는 조건이 만족될 때까지 기다려야지, 확인해서는 안 된다.
Thread.yield
-
Thread.yield()- 현재 스레드가 다른 스레드에게 실행 기회를 양보
- 단, 실제 동작은 전적으로 스케줄러 판단에 달림
-
문제점
- 효과가 플랫폼·환경마다 다름
- 테스트 불가능
- 증상이 완화될 수는 있으나 근본 해결책이 아님
➡️ 스레드가 제대로 실행되지 않는다고
yield로 고치려는 유혹을 반드시 피해야 한다.
올바른 접근 방식
-
스케줄러에 기대지 말고
- 프로그램 구조를 개선해
- 동시에 실행 가능한 스레드 수 자체를 줄여라
-
스레드는
- 작업이 있을 때만 실행
- 없으면 대기(wait / blocking) 상태 유지
