Tree Algorithm
Tree Algorithm은 Classification과 Regression에서 모두 사용할 수 있다.
- 목표변수가 범주형인 경우: Classification Tree
- 목표변수가 연속형인 경우: Regression Tree
Decision Tree(의사 결정 나무)
의사 결정 규칙(Decision Rule)을 나무의 가지처럼 집단을 몇 개의 소집단으로 분할해가며 분류 및 예측하는 방법이다.
특징
-
장점
- split 규칙이 이해하기 쉽다.(If Then Else)
- 특성변수 및 목표변수가 연속형, 범주형 자료에 상관없이 적용할 수 있다.
- 표준화, 스케일링 등의 데이터 전처리가 거의 필요하지 않다.
- 이상치에 대한 민감도가 상대적으로 낮다
- 모형에 가정이 필요없는 비모수적 모형이다. 즉 정규 가정이 필요 없다.
모수적: 모집단의 분포가 정규분포 등 특정 분포를 따를 때 모집단에 대한 추가적인 가정이 있는 경우표본의 확률을 추론하는 방식을 의미한다.
-
단점
- 모델의 변동성이 크기 때문에 훈련 결과가 불안정하다. 즉 과적합 가능성이 높다.
- 특성변수의 축에 수직인 분류경계면을 가진다. 즉 격자 모양으로 분류 모형이 생성된다.
- Depth가 깊어질수록 과적합으로 인한 예측력이 하락하며, 해석이 어려워진다.
1. Classification Tree
구조
- Root Node: 전체 자료로 구성된 시작(첫 번째) Node
- Parent Node: Child Node의 상위 Node
- Child Node: 하나의 Node에서 분리된 2개 이상의 Nodes
- Terminal(Leaf) Node: child Node가 없는 끝에 위치한 Node(예측 값이 결정되는 Node)
- Internal Node: Parent Node와 Child Node를 모두 가지고 있는 Node
- Depth(깊이): 분할된 Node의 높이(Leaf Node에서 Root Node 까지의 계층). 위의 그림에서 Depth는 3이다.

분리 규칙 종류
| 분리기준 | 특징 | |
|---|---|---|
| CART | - Classification: 지니 불순도(Impurity) - Regression: 분산감소량 / MSE | - 항상 이진분리(n(Child Node) = 2) - 개별 특성변수 및 특성변수의 선형결합 형태의 분리 기준도 가능함 |
| C4.5 / C5.0 | - 엔트로피 불순도로구한 정보 이득 | - 범주형 특성변수는다진분리 - 연속형 특성변수는이진분리 |
| CHAID | - Classification: chi-square - Ressetion: ANOVA F | - 다진분리 - 변수 간 통계적 관계에 기반 |
이진분리: Child Node가 2개로 분리되는 방식
다진분리: Child Node가 2개 이상으로 분리되는 방식
선형결합: 와 같이 각 특성변수에 계수를 취하는 방식
카이스퀘어: 두 범주형 변수 간 연관성을 분석하는 검증값, 카이스퀘어 값이 크면 연관성이 크다
ANOVA F: F 값이 크면 평균이 다르다는 것을 의미한다
불순도
Y의 범주가 J = 1, 2 ... C로 구성될 때 t Node에서의 불순도 imp(t)는 다음과 같다. 불순도는 Child Node 내의 이질성을 의미한다. 따라서 불순도가 크면 Child Node 내의 이질성이 높다. 즉 분리가 부적절하게 수행되었다는 것을 의미한다. 따라서 불순도가 가장 작아지는 방향으로 가지를 분할해야 한다.

- : t마디로 분류했을 때 범주 에 속할 확률
- Gini Impurity(지니 불순도):
 참고자료 1
참고자료 1
- 예) 얼룩말 6마리, 하마 1마리
Pr(Interspecific Encounter) =
- 예) 순록 3마리, 타조 3마리, 코뿔소 1마리, 원숭이 1마리
Pr(Interspecific Encounter) =
- 예) 얼룩말 6마리, 하마 1마리
- Entropy Impurity(엔트로피 불순도):
불순도의 향상된 정도(Goodness of Split)
Parent Node t에서 분리기준 s로 분리한 후 생성된 두 Child Node이 각각 , 이면,
이다. 이 때 G(s, t)가 최대가 되는 점을 찾는 것이 목표이다.
예컨대 Parent Node에서 100개가 왼쪽 Child Node에 80개 오른쪽 Child Node의 20개로 분리되었다면, Parent Node의 불순도에서 만큼 가중치를 준 왼쪽 Child Node의 불순도와 만큼 가중치를 준 오른쪽 Child Node의 불순도를 뺀 값이 최대가 되는 지점을 찾아 분리 기준으로 정한다.
- : t Node에서 자료 수
- : t Node에서 불순도
분석 절차
Growing
각 Node에서 어떤 특성 변수를 어떻게 분할한 것이지에 대한 적절한 분리규칙(Splitting Rule)을 찾아 Tree를 성장시킨다. 단 정지 규칙(Stopping Rule)을 만족하는 경우 성장을 중단한다.
분류 기준은 해당 Node에서 그 기준으로 하위 Node로 분기하였을 때, 하위 Node내에서는 동질성이, 하위 Node 간에는 이질성이 가장 커지도록 선택한다.
- 이진분할의 분리규칙 형태
- 연속형 특성변수
분리에 사용될 특성변수 X와 분리점 c를 활용해 X < c일 때는 Left Child Node로 X ≥ c일 때는 Right Child Node로 분리한다. - 범주형 특성변수
분리에 사용될 특성변수 X가 가지는 전체범주 중에서 부분집합인 A를 활용하여 X ∈ A일 때는 Left Child Node로 분리하고, 그렇지 않으면 Right Child Node로 분리한다.
- 연속형 특성변수
Pruning
오류율(Error rate)를 증가시킬 위험이 높거나 부적절한 추론 규칙을 가지고 있는 가지를 제거한다. Depth가 증가하며 Leaf Node로 갈수록 분류되는 개수가 작아지고 이는 곧 과적합 리스크를 유발한다.
타당성 평가
평가자료(Test Data)를 활용해 의사 결정 나무의 성능을 평가한다.
- Classification: Accuracy, Precision, Recall
- Regression: RMSE, R-Square, MAE, MAPE
해석 및 예측
만들어진 Tree 모형을 해석하고 분류 및 예측 모형을 설정한다.
2.Regression Tree
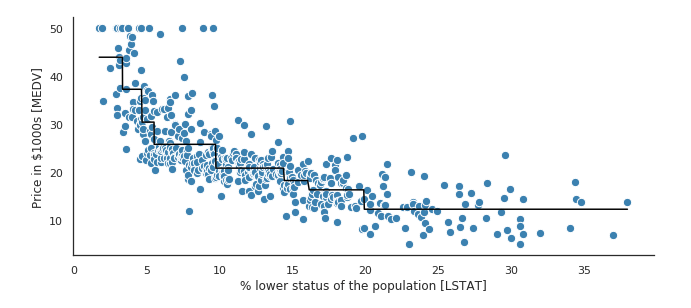
일반적으로 다른 회귀(Regression) 알고리즘에 비해 성능이 떨어진다. 위의 그림과 같이 Regression Tree로 예측하게 되면 Leaf Node로 분리된 값의 평균(상수 값)을 반환하기 때문에 선형으로 구성된 계단의 형태를 띄게 된다. 즉 선형회귀로 예측했다면 곡선으로 예측하기 때문에 보다 높은 예측력을 가지게 될 것이다.
단, 특성 변수의 개수가 많고 변수 사이의 상관관계가 높은 경우 유리하다.
분리 규칙
분산 감소량
각 CGroup(Child Node) 내에서 목표변수(Y)의 분산이 작을수록 그룹 내 이질성이 낮다. 따라서 Child Node로 분리했을 때 분산의 감소량이 가장 커지도록 하는 분리 규칙을 탐색한다.
Classification Tree의 불순도와 Regression Tree의 분산은 유사한 역할을 수행한다.
ANOVA F 통계량
F값이 클수록 Group(Child Node) 간 평균의 차이가 존재한다. 즉 Group 간 이질성이 크다. 따라서 F 값이 가장 커지도록 분리 규칙을 탐색한다. 3개 이상의 Child Node로 분리할 때도 사용할 수 있다.
과적합 방지 방법
정지규칙(Stopping Rule)
특정 조건에 도달하면 Tree가 Node를 분리하지 않고 성장을 멈추도록 한다. Hyper Parameter를 Tuning하여 정지 규칙을 설정한다.
- 모든 자료의 목표변수(Y) 값이 동일할 때
- Node에 속하는 자료의 개수가 일정 수준보다 적을 때
- Depth가 일정 수준 이상일 때
- 불순도의 감소량이 지정된 값보다 적을 때. 즉 성능의 개선 정도가 미미할 때
가지치기(Pruning)
성장이 끝난 Tree의 가지를 제거하여 적당한 Depth를 가지도록 한다. 이 때 Validation Data를 활용해 예측 오류가 가장 적은 나무 모형을 찾는 것이 일반적이다.
