Process Management Activities
- The operating system is responsible for the following activities in connection with process management:
- Creating and deleting both user and system processes
- Suspending and resuming processes
- Providing mechanisms for process synchronization
- Providing mechanisms for process communication
- Providing mechanisms for deadlock handling
Process: What is it?
- A running program (= A program currently in execution)
- An active entity, with a program counter(PC) specifying the next instruction to be executed and a set of associated resources
- A program is a passive entity, like the contents of a file stored on a disk
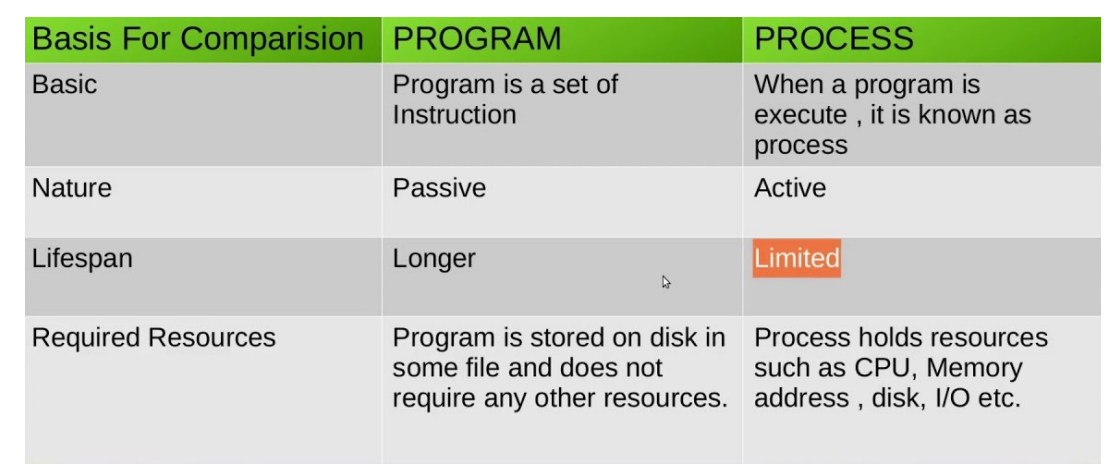
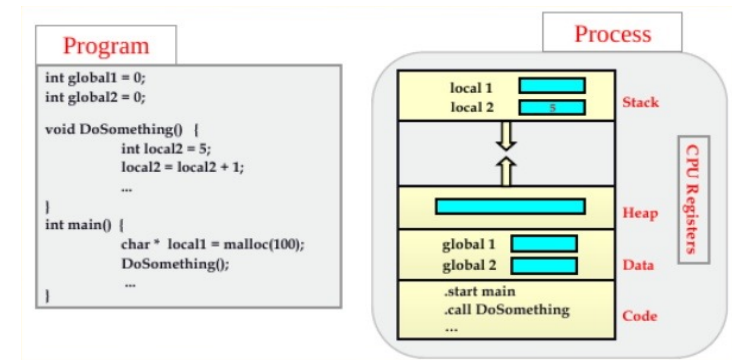
The Memory Layout of a Process
- Typically divided into multiple sections:
- “Text Section” containing the executable code
- “Data Section” containing global variables
-> These two sections’ sizes are fixed, as their sizes do not change during program run time!
-> However, the following two sections can shrink and grow dynamically during program execution. OS must ensure they do not overlap one another!!
Stack Section & Heap Section
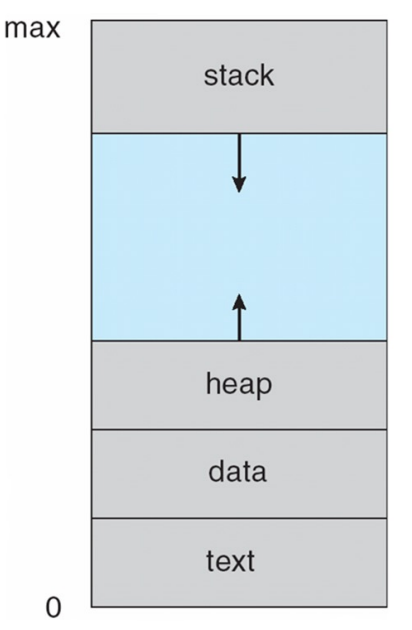
- Typically divided into multiple sections:
- “Stack Section” containing temporary data storage when invoking functions
- Each time a function is called, an activation record containing function parameters, local variables, and the return address is pushed onto the stack;
- When control is returned from the function, the activation record is popped from the stack
- “Heap Section” will grow as memory is dynamically allocated (i.e., created at runtime by malloc), and will shrink when memory is returned to the system.
- “Stack Section” containing temporary data storage when invoking functions
User Space VS. Kernel Space Memory
- Kernel space
- Memory region that stores all code and data related to OS kernel
- Any user process cannot access the kernel space, otherwise resulting in a segmentation fault
단, 커널모드일때만 접근 가능하다 - All user processes share the same kernel space region
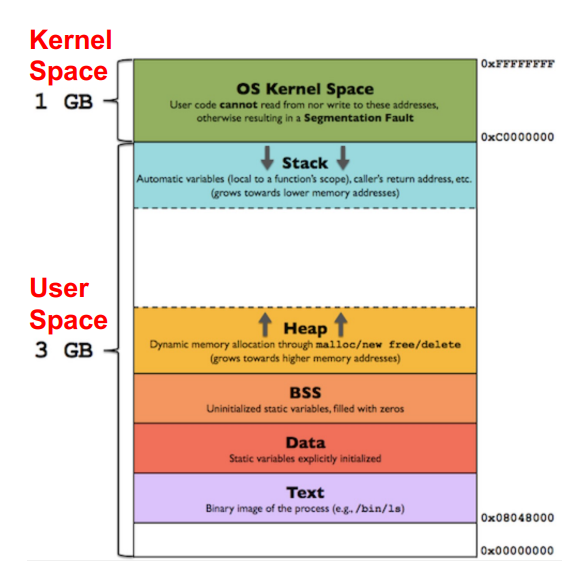
BSS와 data 차이
global variable로 초기화 하면 data, 초기화 하지 않으면 bss로..
Memory Layout of a C Program (1/2)
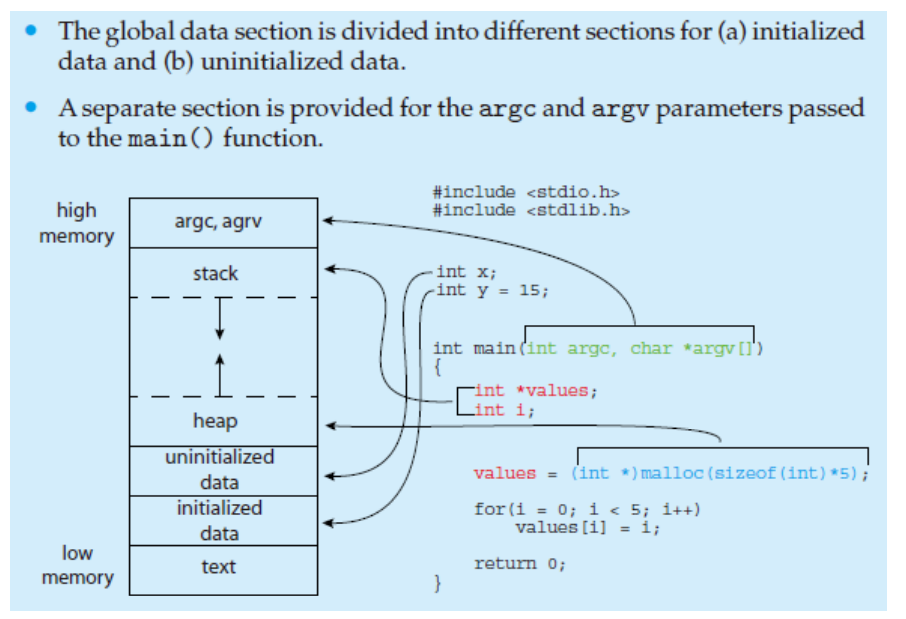
Memory Layout of a C Program (2/2)

heap과 stack은 run time에 동작할때 바뀌는 값이기 때문에 기재되어있지 않다.
Program versus Process
- A program by itself is not a process; It becomes a process when an executable file is loaded into memory
- Two common techniques for program execution: double-clicking an icon (= the executable file) and typing command line for the executable file’s name
- Although several processes may be associated with the same program, they are nevertheless considered separate execution sequences
- Text sections are equivalent, but the data/heap/stack sections vary.
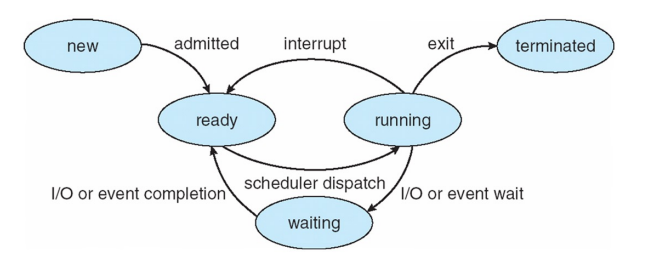
Process State
- As a process executes, it changes “state”, and the state may be in one of the followings:
- New: The process is being created
- Ready: The process is waiting to be assigned to a processor
- Running: Instructions are being executed
-> Only one process can be running on any processor core at any instant; Many processes may be ready and waiting states - Waiting: The process is waiting for some event to occur (such as I/O completion or reception of a signal)
- Terminated: The process has finished execution
Process Representation
- Each process is represented in the OS by “Process Control Block (PCB),” also called a Task Control Block
- In brief, it serves as the repository for all the data needed to start, or restart, a process, along with some accounting data
- Thus, it contains many pieces of information associated with a specific process
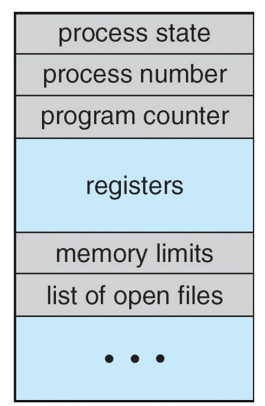
Process Control Block (PCB)
- Process state
- Program counter: the address of the next instruction to be executed for this process
- CPU Registers: Contents of all process-centric registers
- CPU Scheduling information: process priorities, scheduling queue pointers, and any other scheduling parameters
- Memory Management information: memory allocated to the process
- Accounting info: The amount of CPU used, clock time elapsed since start, time limits, and so on
- I/O status information: The list of I/O devices allocated to process, a list of open files, and so on

Process Representation in Linux (1/2)
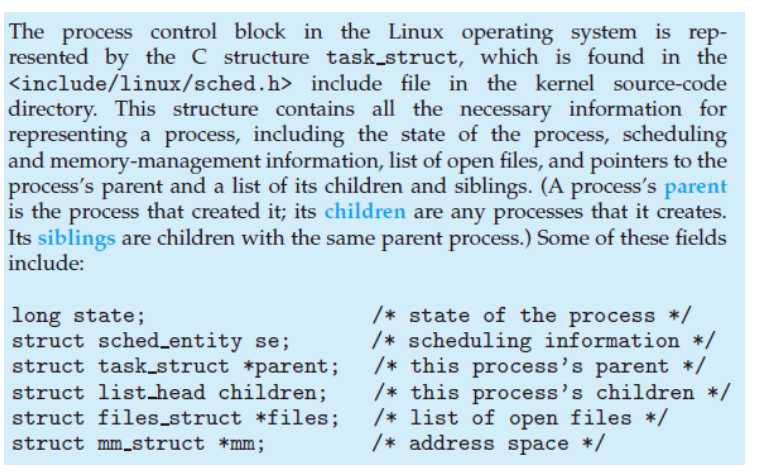
Process Representation in Linux (2/2)

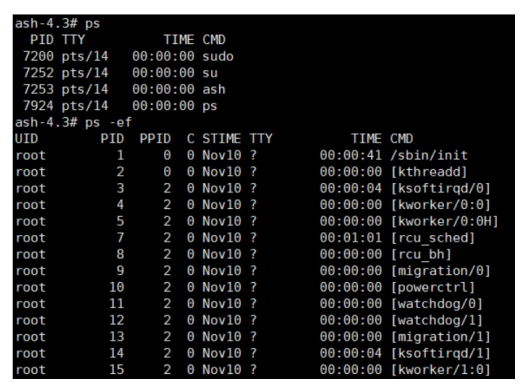
ps
- Most operating systems have system programs that allow the user to look at the current process list
- On Unix/Linux systems, one can run the ps program.
ps: Report a snapshot of the current processesps –elTo show complete information for all processes currently active in the systemps –efTo show all processes or threads running on the system
-e가 있으면 현재 로그인한 사용자와 관련된 모든 프로세스를 나열한다는 의미이고,l은 좀 더 길게f는 좀 더 간결하게를 의미한다.
Process Scheduling
- The objective of multiprogramming is to have some process running at all times so as to maximize CPU utilization
- The objective of time sharing is to switch a CPU core among processes so frequently that users can interact with each program while it is running
- To meet these objectives, the process scheduler selects an available process (possibly from a set of several available processes) for program execution on a core
- Interrupts cause the OS to change CPU core from its current task and to run a kernel routine. When an interrupt occurs, the system needs to save the current context of the process running on the CPU core
OS가 CPU 코어를 현재 작업에서 변경하고 커널 루틴을 실행합니다
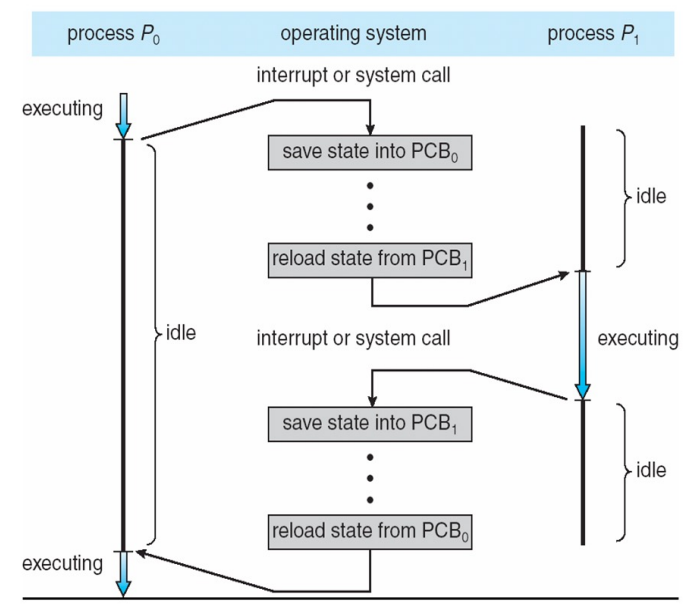
Context Switch
- The context is represented in the PCB of the process. It includes the value of the CPU registers, the process state, and memory management information.
- When CPU switches to another process, the system must save the state of the old process and load the saved state for the new process via a context switch!
- Context-switch time is overhead, because the system does no useful work while switching
- Switching speed varies from machine to machine, depending on h/w support
Diagram showing Context Switch from Process to Process
Operations on Processes
- Process creation
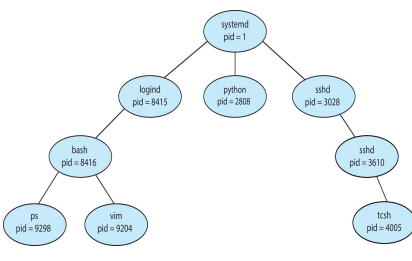
- Parent process create children processes, which may in turn create other processes, forming a tree of processes
- Process is identified and managed via a process identifier (pid), which is typically an integer value
- The init process serves as the root parent process for all user processes
[init has been replaced with the systemd process in recent distributions of Linux]
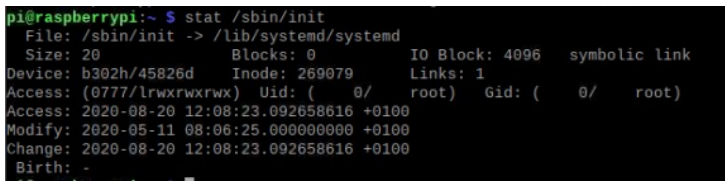
The init program file is linked to the systemd program for compatibility with previous Linux versions
Process Tree with ‘systemd’ process as the root of all user-level processes
- pstree command on RaspberryPi
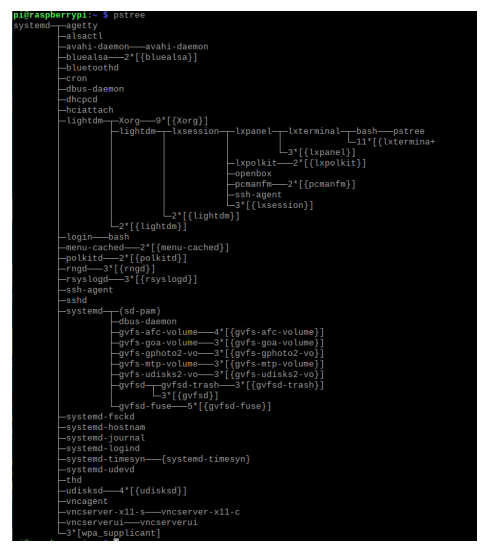
전체 프로세스의 트리구조는 한 눈에 볼 수 있다.
Operations on Processes
- Process creation
- In general, when a process creates a child process, that child process will need certain resources (CPU time, memory, files, I/O devices) to accomplish its task
- 1) A child process may be able to obtain its resources directly from OS, or 2) it may be constrained to a subset of the resources of the parent process.
- For 2), the parent may have to partition its resources among its children, or it may be able to share some resources (such as memory or files) among several of its children
» Restricting a child process to a subset of the parent’s resources prevents any process from overloading the system by creating too many child processes
- For 2), the parent may have to partition its resources among its children, or it may be able to share some resources (such as memory or files) among several of its children
부모 프로세스에 할당된 메모리를 사용하면 아무리 자식 프로세스를 많이 만들어도 과부하가 일어날일이 없다는 장점이 2번은 가지고 있다.
fork()
- The
fork()system call creates a new process identical to the calling one (= a clone of the currently running program)- The new process consists of a copy of the address space of the original process
- Both processes (the parent and the child) continue execution at the next line of code after the fork(), with one difference: the return code!
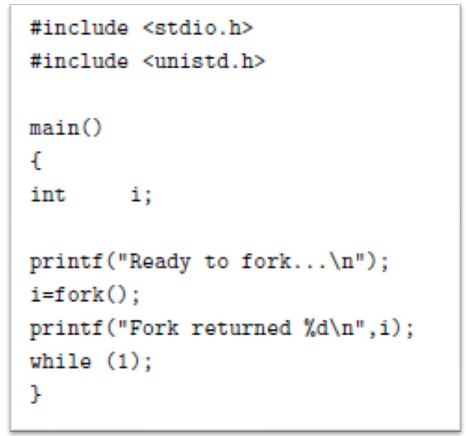
- This program calls the fork() function and then goes into an infinite loop
- Assuming the program is stored in a file named fork1.c, then it can be executed as follows:
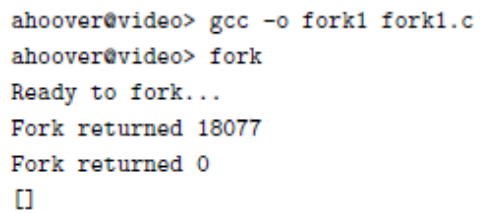
아가는 0, 부모는 자식 프로세스의 pid를 리턴받는다!!
Return Code for the fork()
- Return value for the fork() differs…
- Zero for the new (“Child”) process
- Process ID of the child process for the “Parent” process
- The figure below displays a timeline of events during a fork system call

Example of fork()

- The return value from
fork()allows a program to affect which code its clone will execute. - At
fork(), the parent and child processes will each go into different code blocks. Each process has its own variables, and they are executing different codes. - The order of the lines of output will vary from run to run. This is because after fork(), both processes are running concurrently and the order of execution is not predictable.
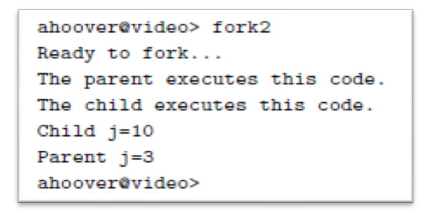
Using fork() in a nested fashion
- The fork() function can be called iteratively, meaning that one process can start up multiple new processes, which can in turn start multiple new processes, and so on.
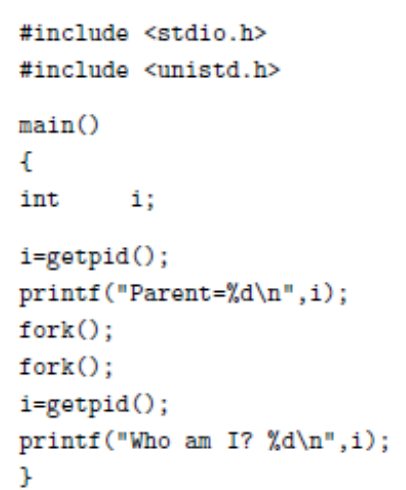
- The getpid() function is a system call that returns the PID of the current process.
- This program calls fork(), creating a clone. Then each of those programs calls fork(), creating another clone each.
exec() family
- After a fork() system call, one of the two processes typically uses the exec() family of system calls to replace the process’s memory space with a new program
포크(fork) 시스템 호출 후 두 프로세스 중 하나는 일반적으로 exec() 시스템 호출 패밀리를 사용하여 프로세스의 메모리 공간을 새 프로그램으로 교체합니다- The process retains its PID but becomes a new program
- Several variations in the exec() family of functions, including execl(), execlp(), exece(), execv(), and execvp()

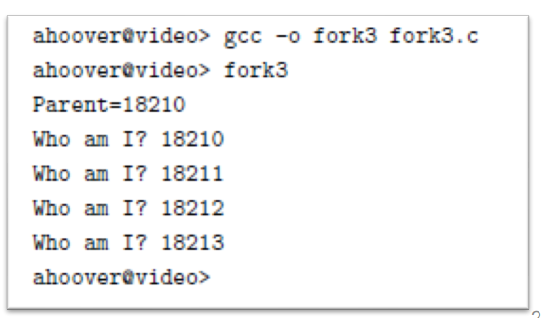
- This program outputs the line “Ready to exec() …” and after calling execvp(), replaces its code with the date program
- Note that the line “… did it work” is not displayed, because at that point the code has been replaced. Instead, we see the output of executing “date –u”
execvp(program, args) 에서 args[0]은 항상 program 이름값과 동일하다!!
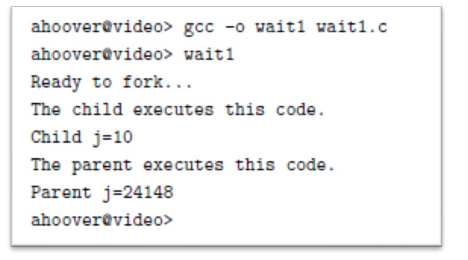
wait()
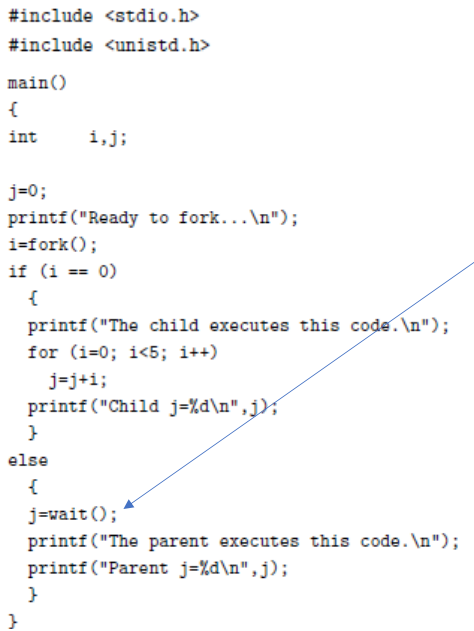
-
It suspends a process, waiting for a child process to finish
-
Its return value is the PID of the child process
부모 아니라 자식의 PID이다!!!
-
Here, the wait() function is executed in the block reached by the parent process. This causes the parent process to pause until the child process has finished, at which time the parent process resumes execution
- Always produced in this order
waitpid()
- The wait() system call pauses the execution of the parent process until any child process has been completed
- The parent issuing wait() makes itself move off the wait queue until the termination of the child
- Fine-grained control over synchronization can be obtained using the waitpid() function, which can wait on a process with a specific PID, or can wait until a process terminates in a specific manner or with a specific condition
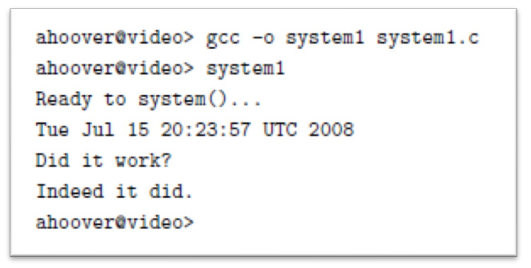
system()
- The system() function is a C standard library function that puts the fork(), exec(), and wait() functions together into a single convenient call

- This program prints out a “ready” message, and then uses system() to execute the date program
exec 함수는 현재 프로세스를 다른 프로그램으로 교체하고, system 함수는 외부 명령어를 실행하고 다시 현재 프로세스로 돌아올 수 있습니다.
Process Termination
- A process terminates when it executes last statement and then asks the OS to delete it by using the exit() system call
- At that point, the process may return a status value (typically an integer) to its waiting parent process (via the wait() system call)
- All the resources of the process – including physical and virtual memory, open files, and I/O buffers – are deallocated and reclaimed by the OS
- Parent may terminate the execution of children processes using the abort() system call. Some reasons for doing so:
- Child has exceeded allocated resources
- Task assigned to child is no longer required
- The parent is exiting, and the OS does not allow a child to continue if its parent terminates
-> This phenomenon is referred to as “cascading termination” (All children, grandchildren, etc. are terminated)
부모가 abort 할때의 상황 암기하면 좋을듯!
- The parent process may wait for termination of a child process by using the wait() system call.
- The call passes a parameter that allows the parent to obtain the exit status of the child. And it also returns the pid of the terminated child
- pid = wait(&status);
자식은 함수 종료시 exit(0)을 호출할때, 여기서 0이 os에 전달하고, os는 부모에게 status 값으로 전달한다.
- pid = wait(&status);
- The call passes a parameter that allows the parent to obtain the exit status of the child. And it also returns the pid of the terminated child
- Zombie process
- A process which is terminated but its parent has not called wait() yet
- The child’s execution result remains alive until being reclaimed
아이의 실행 결과는 회수될 때까지 살아 있습니다
- Orphan process
- A process whose parent exited without calling wait()
- Some OSes initiate cascading termination not to leave orphans
- In UNIX and Linux, the init process adopts such an orphan process and it calls wait() periodically
좀비는 wait를 호출하기 전에 자식 프로세스가 종료되었을때..
고아는 wait를 호출하지 않고 부모 프로세스가 종료되었을때..
Single-threaded & Multi-threaded Processes
- Thread
- A flow of execution with its own execution state (CPU registers & stack) within a process
- The traditional process model has implied that a process is a program that performs a single thread of execution
- This single thread of control allows the process to perform only one task at a time
- Most modern OS provide features enabling a process to have multiple threads of execution and thus to perform more than one task at a time
- Beneficial on multicore systems (that provide multiple CPUs), where multiple threads can run in parallel
여러 스레드를 병렬로 실행할 수 있는 멀티코어 시스템(여러 CPU 제공)에서 유용
- Beneficial on multicore systems (that provide multiple CPUs), where multiple threads can run in parallel
- A thread is a basic unit of CPU utilization; it comprises(구성하다) a thread ID, a program counter(PC), a register set, and a stack.
- It shares with other threads belonging to the same process its code section, data section, and other operating-system resources, such as open files and signals
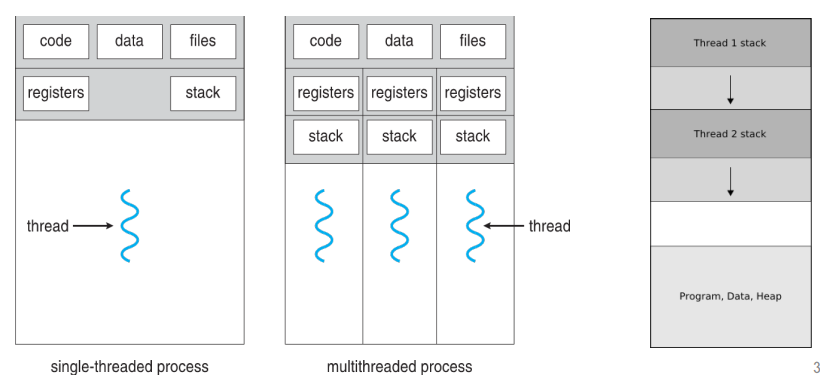
- It shares with other threads belonging to the same process its code section, data section, and other operating-system resources, such as open files and signals
프로세스: 운영체제로부터 자원을 할당받은 작업의 단위.
스레드: 프로세스가 할당받은 자원을 이용하는 실행 흐름의 단위.
운영체제는 프로세스마다 각각 독립된 메모리 영역을, Code/Data/Stack/Heap의 형식으로 할당해 준다
하지만 스레드는 프로세스가 할당받은 메모리 영역 내에서 Stack 형식으로 할당된 메모리 영역은 따로 할당받고, 나머지 Code/Data/Heap 형식으로 할당된 메모리 영역을 공유한다. 따라서 각각의 스레드는 별도의 스택을 가지고 있지만 힙 메모리는 서로 읽고 쓸 수 있게 된다
만약 한 프로세스를 실행하다가 오류가 발생해서 프로세스가 강제로 종료된다면, 다른 프로세스에게 어떤 영향이 있을까? 공유하고 있는 파일을 손상시키는 경우가 아니라면 아무런 영향을 주지 않는다.
그런데 스레드의 경우는 다르다. 스레드는 Code/Data/Heap 메모리 영역의 내용을 공유하기 때문에 어떤 스레드 하나에서 오류가 발생한다면 같은 프로세스 내의 다른 스레드 모두가 강제로 종료된다.
Multithreaded Programming
- Most modern software applications are multithreaded
- Multiple tasks with the application can be implemented by separate threads
- E.g.) Multithreaded server architecture:
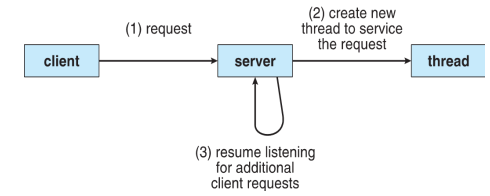
- Most OS kernels are also multithreaded
- During system boot time on Linux systems, several kernel threads are created. Each thread performs a specific task, such as managing devices, memory management, or interrupt handling
- The special kernel thread ‘kthreadd (with PID=2)’ serves as the parent of all other kernel-level threads
The Special “kthreadd” process as the root of all kernel-level threads
- What is ‘kthreadd’?
- Every time a thread is needed to be created in kernel space, kthreadd (PID=2) is invoked.
- Because one can't simply create kernel thread from userspace call, kthreadd is used.
- It has no relation to the init (PID=1) process.
- Every time a thread is needed to be created in kernel space, kthreadd (PID=2) is invoked.
- ps axjf -ejH on RaspberryPi
kthreadd가 직접 커널에서 이용될 스레드를 만들어준다.
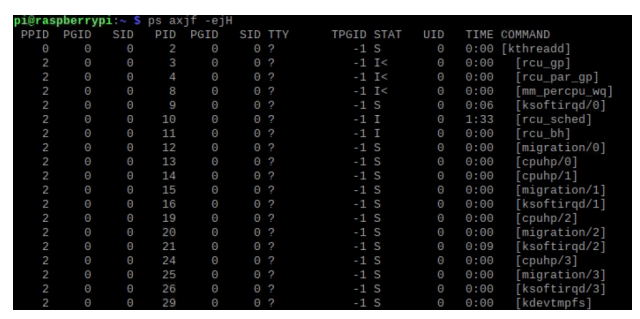
위는 시스템에서 돌아가는 모든 커널 스레드들을 나타내었다.
Benefits of Multithreaded Programming
- Responsiveness
- It may allow continued execution if part of process is blocked, especially important for user interfaces
프로세스의 일부가 차단될 경우 지속적인 실행이 가능할 수 있으며, 특히 사용자 인터페이스에 중요합니다
- It may allow continued execution if part of process is blocked, especially important for user interfaces
- Resource Sharing
- Threads share resources of process, easier than shared memory or message passing
- Economy
- Cheaper than process creation, thread switching has lower overhead than context switching
- Scalability
- A process can take advantage of multiprocessor architectures
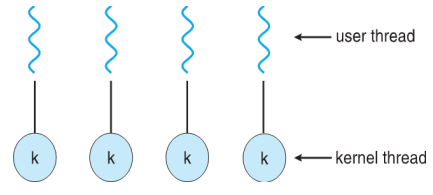
Multi-threading Model
- Support for threads may be provided either at the user level, for user threads, or by the kernel, for kernel threads
- User threads: management done by user-level threads library
- Kernel threads: management directly done by kernel-level OS (kthreadd)
- A relationship must exist between user threads and kernel threads: Many-to-One / One-to-One / Many-to-Many Model
- Linux, along with the family of Windows OSs, implement the one-to-one model (-> More concurrency than many-to-one) 다대일보다 동시성 향상
many-to-one은 커널 스레드가 하나이므로 concurrency가 떨어진다. 왜냐하면 하나의 유저 스레드의 요청이 끝날때까지 다른 유저 스레드가 기다려야하므로!
one-to-one은 유저스레드를 전담하는 커널 스레드가 전담한다.
유저스레드는 시스템 콜을 호출해서 동작을 하더라도 다른 유저스레드들도 언제든지 자신의 시스템 콜을 수행할 수 있다.
many-to-one보다는 많은 concurrency를 제공할 수 있다.
하지만 유저스레드를 생성할때마다 커널스레드도 자동으로 생성되므로 자원을 많이 사용한다는 단점이 있다. 유저스레드가 항상 시스템 콜을호출하지 않으므로 대부분의 커널 스레드들은 노는 애들이 생긴다. 자원 낭비..
many-to-many는 매핑이 static하게 아니라 dynamic 하게 정해진다.
자원 낭비할 일 없고 concurrency 보장..!
Threading Issue: The fork() and exec() System Calls
- The semantics of the fork() and exec() change in a multithreaded program
- exec() usually works as normal – replace the running process including all threads
하나의 스레드가 호출하더라도 전체 space가 변경되기 때문에 기존에 있던 스레드는 모두 사라지고 새로운 프로세스로 넘어간다. - If one thread in a program calls fork(), does the new process duplicate all threads, or is the new process single-threaded?
- Some UNIX systems have two versions of fork(),
one that duplicate all threads (i.e., fork()) and
another that duplicate only the calling thread (i.e., fork1())
-> Which of the 2 versions of fork() to use depends on the application:- If the separate process does not call exec() after forking, the separate process should duplicate all threads
exec를 호출하지 않는다면 fork()가 좋을듯.. - If exec() is called immediately after forking, the new process duplicates only the calling thread
fork() 호출 이후 exec() 함수를 호출한다면 어차피 다른 프로그램으로 변경되므로 fork1()을 호출하는 것이 좋다.
- If the separate process does not call exec() after forking, the separate process should duplicate all threads
Linux Threads
-
Linux uses the term task rather than thread (or process)
스레드와 프로세스 둘다 태스크로 간주한다 -
Thread creation is done through clone() system call
- It behaves identically to fork(), except that it accepts as arguments a set of flags that dictate what resources are shared between the parent and child (whereas a process created with fork() shares no resources with its parent)
부모와 자식 간에 공유할 리소스를 지시하는 플래그 집합을 인수로 받아들인다는 점을 제외하고는 fork()와 동일하게 동작합니다 - Thus, when clone() is invoked, it is passed a set of flags that determine how much sharing is to take place between the parent and the child tasks
fork 함수 내부에 clone 함수가 존재하고, 따라서 빈칸으로 호출한다면 어떠한 것도 공유하지 않는다는 것을 의미함.
- It behaves identically to fork(), except that it accepts as arguments a set of flags that dictate what resources are shared between the parent and child (whereas a process created with fork() shares no resources with its parent)
-
Some of these flags
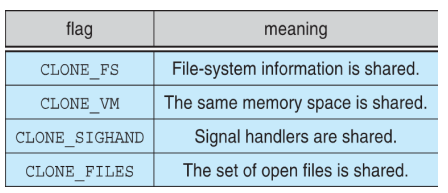
-
If none of these flags is set when clone() is invoked, the associated resources are not shared, resulting in functionality similar to that of the fork() system call
-
fork() is nothing more than a special case of clone() that copies all subcontexts, sharing none
