스프링
1.스프링 오픈소스
- 소스코드가 공개 되있다
- 내부를 볼수있고 고칠수도 있다
2.스프링은 IoC 컨테이너를 가진다
- IoC컨테이너란?(Inversion of Controll)
- 제어의 역전
- 주도권이 스프링이 가지고 있다는것
- class(설계도), object(객체 : 실체화가 가능한 것), instance(실체화 된것)
- 인스턴스들을 메모리에 적재(new)하지 않아도 스프링이 객체들을 스캔하여 메모리에 적재, 관리한다.
3.스프링은 DI를 지원한다
- Dependency Injection(DI : 의존성 주입)
- 내가 원하는 곳에서 스프링이 메모리에 적재한 객체들을 사용할수 있다.
- 스캔하면 한번만 메모리에 적재(싱글톤)하고 적재된 것을 공유
4.스프링은 많은 필터(인터셉터)를 가지고 있다
- 필터 : 문지기(권한체크)
- 스프링이 가지고있는 필터는 인터셉터
- 스프링 자체가 기본적으로 가지고있는 필터(인터셉터)가 있다
- 자체 필터를 사용할수있고 , 사용하고있지 않은 필터를 사용할수 있고
- 직접 필터를 생성할 수도있다
5.스프링은 많은 어노테이션을 가지고있다.(리플렉션, 컴파일체킹)
-
컴파일체킹
어노테이션 (주석 + 힌트) ← 컴파일러 무시 x!
// 글~~ (주석) ← 컴파일러 무시! -
스프링에서는 주로 어노테이션을 통해서 객체생성
@Component → 클래스 메모리에 로딩 @Autowired → 로딩된 객체를 해당 변수에 대입해 예) @Component Class A → A Class객체를 heap영역에 메모리에 올림 Class B { @Autowired A a; → B Class에 내부에 어떤것이 있는지 분석(리플렉션) : 메소드 , 필드 , 어노테이션 체킹 있다면 어떤행동을 설정가능 리플렉션(분석하는 기법 → 런타임시 분석) }
6.스프링은 MessageConverter를 가지고 있다. 기본값은 현재 Json이다
-
중간언어 : xml → Json
-
자바 Object → Json → 파이썬 Object
-
자바 객체를 파이썬에 전달할떄 파이썬 Object로 변환시 Json이라는 중간단계를 거쳐 전달
-
자바Object가 전송되기전에 Json으로 바뀌고 전송되고나면 Json을 다시 파이썬Object로 변환
- Class Animal{ Animal 전송을할대 → MessageConverter:Jackson → Json데이터 int num = 10; (Json데이터로 변경하여) → {"num" : 10 , "name" :"사자"} 로 변환 String name = "사자" }
7.스프링은 BufferedReader와 BufferedWriter를 쉽게 사용할수 있다.
- BufferedReader 가변길이의 문자를 받을수 있다.
- 어노테이션을 통해 데이터 입출력
@ResponseBody → Buffered Writer동작 : 데이터를 전송
@RequestBody → Bufferd Reader동작 : 데이터를 읽어드릴때
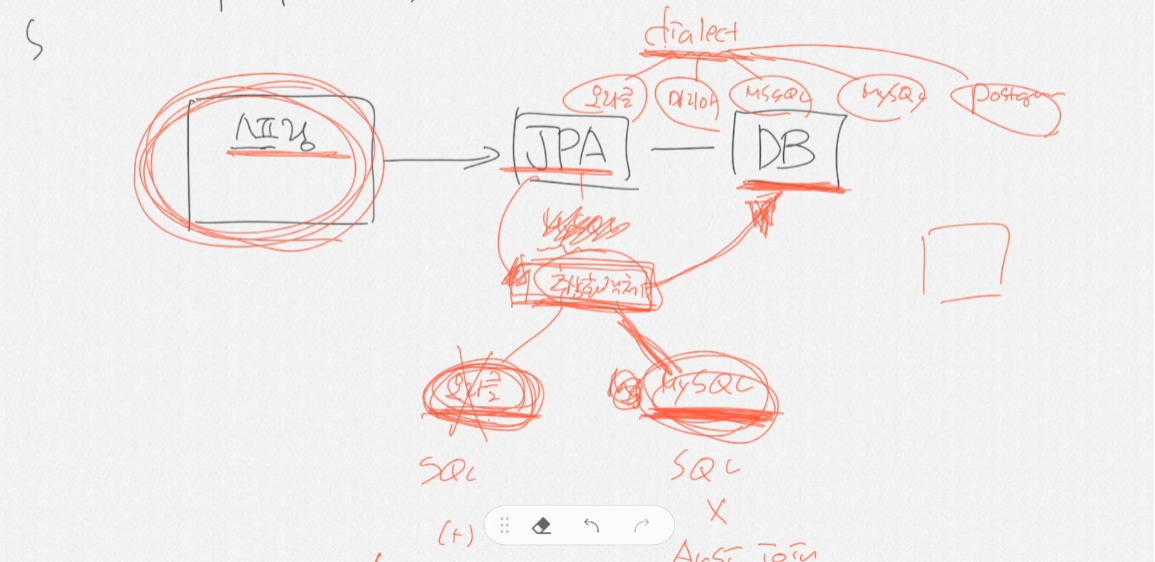
JPA란
1.JPA는 Java persistence API 이다 (영속성) 프로그램이 종료되도 DB에 기록
- Java의 데이터를 영구히 기록할수있게 하는 API
- API 애플리케이션(Application) 프로그래밍(Programing) 인터페이스(Interface)
2.ORM 기술이다.
- Object Relational Mapping
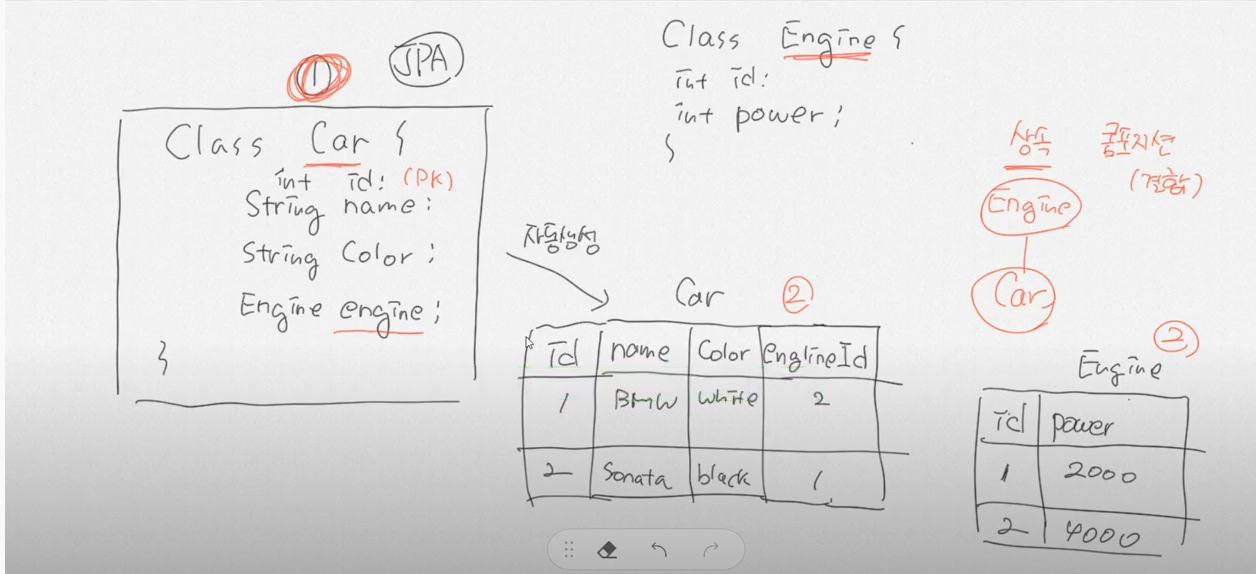
- 객체 관계 매핑 : 객체와 관계형 데이터베이스의 데이터를 자동으로 매핑(연결) 해주는것
- 객체 지향프로그래밍은 클래스를 사용하고, 관계형 데이터베이스는 테이블을 사용한다.
- 객체 모델과 관계형 모델간에 불일치가 존재(데이터 타입이 다름)
- ORM을 통해 객체간의 관계를 바탕으로 SQL을 자동으로 생성하여 불일치를 해결
- 데이터베이스 데이터 ←매핑→ Object 필드
- 오브젝트를 데이터베이스에 연결하는 방법론?
- 자바클래스를 만들고, 클래스를 데이터베이스에 테이블이 자동생성 하기위한 interface
- DB에있는 데이터를 자바에 모델링하지 않고
- ORM은 자바클래스를 만들면 자동으로 데이터베이스 테이블이생성하는 기법
3.JPA는 반복적인 CRUD작업을 생략하게 해준다.
- 자바 ↔ DB
- 쿼리문전송 → Data(DB) → JAVA의 데이터타입이 다르므로 해당 데이터를 자바 객체로 변경해야한다 , 반복로직을 해야한다.
- JPA를 사용하면 쿼리전송,응답,세션연결,Connection연결 등을 함수를 통해 쉽게 가능
4.JPA는 영속성 컨텍스트를 가지고있다.
- 영속성 : 데이터 → 영구적으로 저장 → DB
- 컨텍스트 : context (대상에 대한 모든정보)
- 영속성 컨텍스트(Persistence Context)란 엔티티를 영구 저장하는 환경으로, 애플리케이션과 데이터베이스 사이에서 객체를 보관하는 논리적인 개념
- 자바가 데이터베이스에 저장,조회해야되는 모든정보 영속성컨텍스트가 가지고있다.
- 자바는 영속성 컨텍스트를 통해서 DB에 저장, 조회
영속성컨텍스트에는 DB의데이터가 자바의 오브젝트형태로 되있다.
5.JPA는 DB와 OOP의 불일치성을 해결하기 위한 방법론을 제공한다.(DB는 객체저장 불가능)
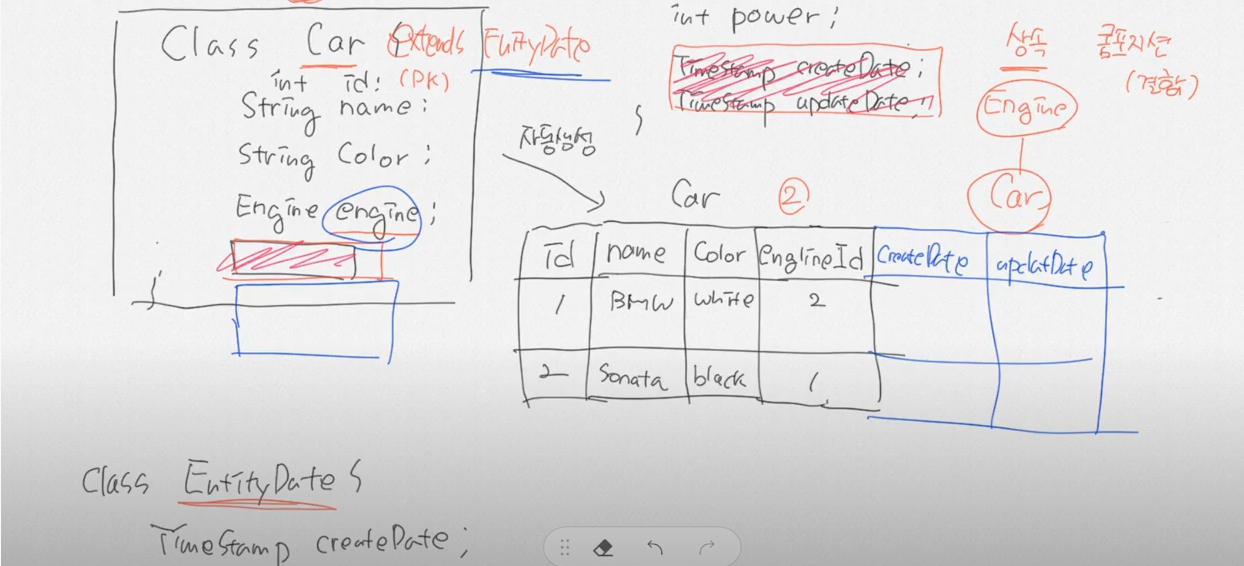
6.JPA는 OOP관점에서 모델링을 해준다.
- 자바의 상속,컴포지션 (결합),연관 관계를 토대로 테이블을 생성해준다.
7.방언처리(dialect)가 용이하여 Migartion하기 좋음. 유지보수에도 좋음.
- JAP는 MySQL뿐아니라 오라클등 여러DB의 연결을 지원하고 변경이 용이하다