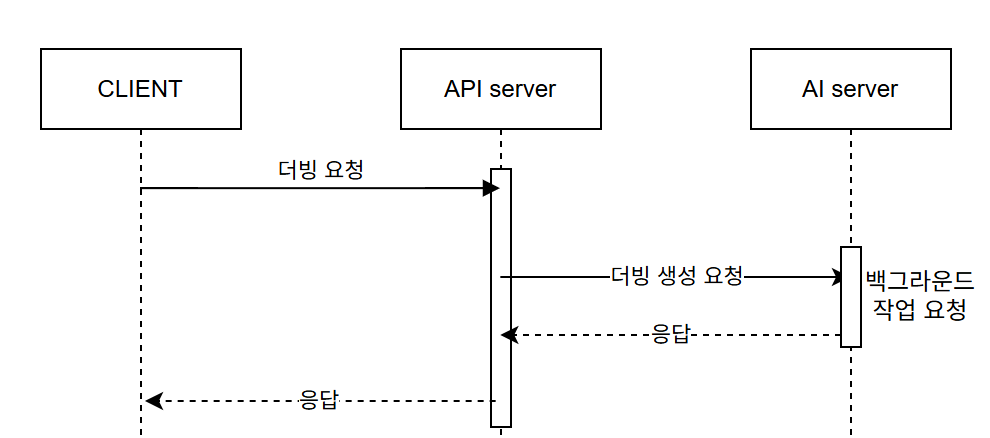
기존 로직
사용자가 더빙하기 버튼을 누르면 API 서버가 AI 서버로 TTS 요청을 동기적으로 보냄.
TTS 생성에 기본적으로 시간이 걸리기 때문에 이 시간동안 유저는 대기 해야함.
또 TTS 생성에 시간이 오래 걸리기 때문에 time out error가 발생하기도 함.
→ 일시적인 대처로 RestTemplate으로 요청을 보낼 때 요청 유지 시간을 넉넉히 늘림.
하지만 이런 대처는 동작할 수 있게만 만든 결과가 되어버림.
근본적인 문제를 해결하기 위해서는 로직 자체를 수정해야 했음.
V1. 우선 응답으로 사용자 대기 없애기
가장 먼저 한 조치는 사용자가 무작정 대기하는 것을 피하기 위해 더빙 요청 시 AI 서버에서는 우선 응답을 보내고 백그라운드에서 더빙 작업 (TTS로 음성 데이터 생성)을 하는 것으로 수정했음.
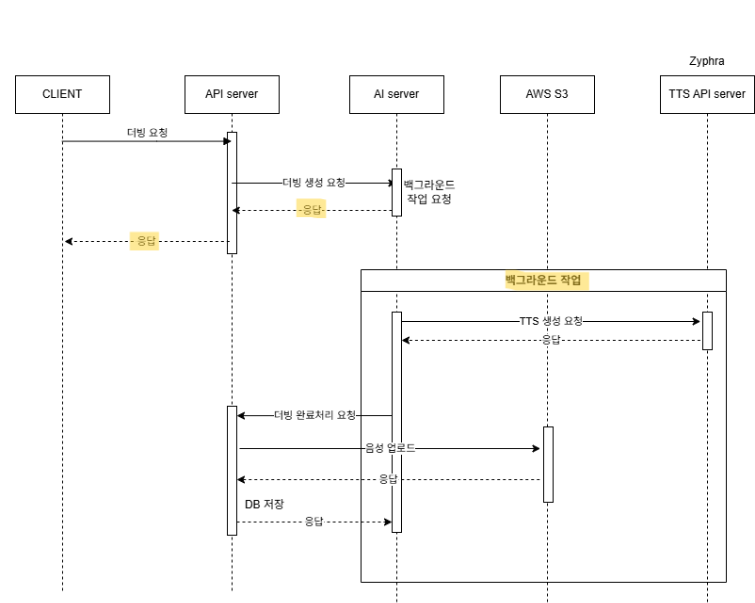
AI 서버에서 더빙 작업이 완료되면 API 서버에서 더빙 작업 요청 시 같이 전달한 webhook url로 작업이 완료됐다는 신호와 함께 동화 페이지 id를 키 값들로 base64로 인코딩된 음성 데이터들을 Map 형태로 보낸다.
API 서버는 신호를 받으면 S3에 음성 데이터를 업로드하고 DB에도 더빙 데이터들을 저장한다.
이로써 사용자는 더빙하기 버튼을 누르고 다른 활동을 할 수 있게 됨.
그리고 백그라운드에서 더빙 작업이 완료되면 사용자가 더빙된 동화를 들을 수 있음.
하지만
사용자가 더빙이 완성되기까지 같은 화면을 보고 기다리는 시간은 없어졌지만, 더빙 요청-완료 시간이 약 2분 30초 정도가 걸렸음. 사용자는 완성된 결과물을 최대한 빨리 확인하고 싶을 것이 당연할 거고 완성 시간이 오래 걸린다면 UX가 떨어질 것으로 예상했음.
또 TTS로 생성된 음성 데이터를 S3에 저장하기 위해 AI 서버에서 API 서버으로 보낼 때에도 문제가 발생할 수 있는 부분이 있다.
AI 서버는 AI 관련 로직만 수행하기 위해 DB나 S3는 API 서버에서 관리하기로 구상하고 설계를 했다.
그래서 AI 서버에서 직접 S3에 음성데이터를 저장하지 않고 API 서버에 전달 후 S3와 DB에 순서대로 저장하는 흐름으로 구현했다.
API 서버에서만 S3에 데이터를 저장하도록 설계한 이유는?
S3에 데이터를 저장하려면 AWS 접근을 위한 access key와 secret key를 관리해야 하고, 관련 설정(Configuration)도 필요하다. 또한 예외 상황에 대비한 안정성 확보도 고려해야 한다.
현재는 API 서버에 S3와 연결된 환경이 구축되어 있지만, AI 서버에서도 직접 S3에 업로드하려면 별도의 설정과 구성이 또 필요하다.따라서 S3 업로드는 API 서버에서만 담당하도록 하면, 권한을 중앙에서 집중적으로 관리할 수 있고 각 서버의 역할도 명확히 구분할 수 있다고 판단해 이렇게 설계했다.
크기가 큰 경우 음성 데이터 하나 당 약 250Kb였고 현재 동화 페이지는 10페이지로 고정시켜둔 상태이므로 AI 서버에서 생성한 10개의 더빙 음성 데이터 약 2.5Mb를 API 서버로 전송해야 한다.
이때 동화 페이지 ID와 매칭을 위해 Map 형식으로 API 서버에 전송해야 하기 때문에 JSON으로 응답을 해야한다.
JSON은 바이트 데이터를 표현할 수 없기 때문에 안정적인 전송을 위해 base64로 인코딩이 필요한데, 인코딩으로 인해 기존 데이터보다 크기가 33% 커진 3.5mb이다.
단일 전송으로는 무리가 없지만 한꺼번에 많은 더빙 요청이 온다면 서버에 부하가 갈 수 있다.
V2. Pre-signed URL로 S3 업로드하기
위 문제를 해결할 방법을 찾으면서 AI 서버에서 직접 S3에 업로드하게도 해봤지만, 더 효율적인 방법이 없는지 계속해서 찾아봤다.
그 결과 AWS S3에 Pre-signed URL이라는 개념이 있다는 것을 찾았다.
Pre-signed URL이란?
AWS S3에 업로드 또는 다운로드할 수 있는 일시적인 접근 권한이 포함된 URL이다. 이 URL을 받은 사용자는 S3에 직접 접근할 수 있지만, 정해진 시간 동안만 유효하며, 특정 작업(예: 업로드, 다운로드)만 수행할 수 있다.
왜 사용하는가?
👉 S3 접근 권한 없이도 안전하게 파일을 업로드/다운로드할 수 있게 하기 위해
👉 클라이언트에게 직접 S3 접근 권한을 부여하지 않고도 파일 전송을 가능하게 하기 위해사용 예시
사용자가 프로필 이미지를 등록할 때
👉 API 서버가 S3의 PUT 방식 Pre-signed URL을 생성해 클라이언트에게 전달
👉 클라이언트가 해당 URL로 이미지 파일을 S3에 직접 업로드
✅ 장점: 서버가 파일을 직접 처리하지 않아 트래픽 절감대용량 파일 처리
👉 동영상, 로그, 데이터 파일 등 대용량 파일을 다룰 때
👉 서버를 경유하지 않고 클라이언트가 S3와 직접 통신하게 유도
✅ 장점: 서버 부하 최소화, 비용 절감
클라이언트가 프로필 이미지를 등록하는 것이 이 방식에 가장 흔한 예시로 나온다.
나는 이 방식을 조금 변형하여 클라이언트를 AI 서버라고 생각했고, AI 서버가 더빙 음성 데이터를 PUT 방식 Pre-signed URL으로 직접 업로드하게 구조를 다시 설계했다.
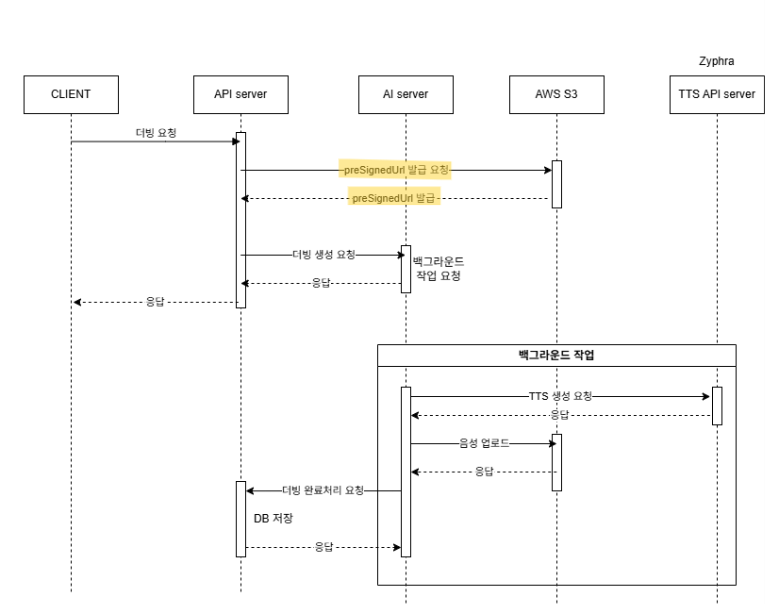
Pre-signed URL을 발급받는 과정에서 API 호출이 발생하긴 하지만 Pre-signed URL로 AI 서버에 S3 업로드 환경을 구축하지 않고도 S3에 데이터를 업로드 할 수 있게 됐다.
다음으로는 더빙 요청에 대한 상대적인 시간을 감소하는 것에 이어서 절대적인 시간을 감소시킬 방법이 필요하게 됐다.
V3. 백그라운드 작업 비동기 처리
코드는 가독성을 위해 주요 로직만 남김.
def process_dubbing_v2(request: DubbingRequest):
zyphra = Zyphra(api_key)
base64_audio = zyphra.get_base64_audio(request.voice_audio_url)
for page_id, content_and_url in request.story_page_map.items():
content = content_and_url.content
pre_signed_url = content_and_url.pre_signed_url
# tts 생성
audio_bytes: bytes = zyphra.generate_speech(base64_audio, content)
# s3에 업로드
http_response = requests.put(pre_signed_url, data=audio_bytes, headers={"Content-Type": "audio/wav"})
# 더빙 작업 완료 시 api 서버에 완료 처리 (POST 요청)
requests.post(request.webhook_url, json={"status": "completed"})*story_page_map
key: 동화의 페이지를 식별하는 page_id
value: TTS의 대상이 되는 content, 완성된 음성을 업로드 할 Pre-signed URL
기존에는 for문을 돌면서 모든 작업을 동기적으로 수행하고 있다.
문제는 동기적으로 한 페이지의 TTS 요청과 s3 업로드가 끝날 때까지 다른 작업이 수행될 수 없다는 것이다.
현재 구조는 for문을 순회하면서 TTS 요청을 위한 외부 API를 호출하고, 응답을 받으면 S3에 업로드하기 위해 API를 호출한다.
CPU-bound 작업이 없고 대부분 I/O-bound 작업이기 때문에, asyncio 기반 비동기 처리에 매우 적합하다고 판단해 아래와 같이 비동기 처리를 해줬다.
async def process_dubbing_v3(request: DubbingRequest):
zyphra = Zyphra(api_key)
base64_audio = zyphra.get_base64_audio(request.voice_audio_url)
tasks = []
async with httpx.AsyncClient() as client:
async def process_page(page_id, content, pre_signed_url):
try:
audio_bytes: bytes = await zyphra.generate_speech_async(base64_audio, content)
response = await client.put(pre_signed_url, content=audio_bytes, headers={"Content-Type": "audio/wav"})
except Exception as e:
logger.exception(f"Error processing page {page_id}: {str(e)}")
# 각 페이지에 대해 Task 생성
for page_id, content_and_url in request.story_page_map.items():
tasks.append(process_page(page_id, content_and_url.content, content_and_url.pre_signed_url))
# 병렬 실행
await asyncio.gather(*tasks)
# 완료 알림
await client.post(request.webhook_url, json={"status": "completed"})zyphra(TTS) SDK의 비동기적으로 TTS 요청을 하고, 응답을 받으면 S3에 업로드하는 메서드에 async/await를 적용해 비동기적으로 S3에 음성 데이터를 업로드할 수 있게 했다.
이 tasks를 await asyncio.gather(*tasks)로 비동기/병렬 실행해 1초가 걸리는 10개의 작업을 1~2초에 끝날 수 있게 했다.
비동기처리를 적용한 결과 요청시간을 약 5배 감소시킬 수 있게 됐다. (150s -> 30s)
