인덱스란?
테이블에서 검색 성능을 높이기 위한 보조 자료구조
MS SQL에서는 삽입 시 pk를 기준으로 정렬된 형태로 삽입, pk로 검색 시 이진탐색으로 데이터를 찾음
→ 그럼 pk가 아닌 데이터로 검색하려면? RID를 이용한 인덱스로 탐색
클러스터드 인덱스
파일 자체가 인덱스인 경우, 파일을 조직할 때 레코드의 순서를 파일에 대한 인덱스의 순서와 동일한 순서로 유지(인덱스의 순서 == 실제 데이터의 순서)
복합키 인덱스
- 인덱스가 여러 개의 필드를 포함하는 경우 복합 키(Composite Key) 또는 접합 키(Concatenated Key)라고 부름
- 데이터 조직과 쿼리 형태에 따라 높은 성능을 보임, 하지만 데이터 크기가 커짐
쿼리 옵티마이저가 자동으로 탐색 plan을 지정
인덱스를 생성하고 쿼리문을 실행시켜도 쿼리 옵티마이저 판단에 더 효율적인 방식으로 탐색한다.
// CategoryNo를 기준으로 하는 Index(idx_product_categoryNo) 생성
SELECT *
FROM Product
WHERE CategoryNo > 0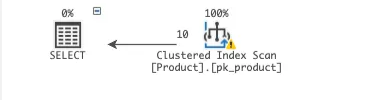
내가 원하는 플랜으로 실행하려면 인덱스를 명시해줘야한다.
SELECT *
FROM Product
WITH (INDEX(idx_product_categoryNo))
WHERE CategoryNo > 0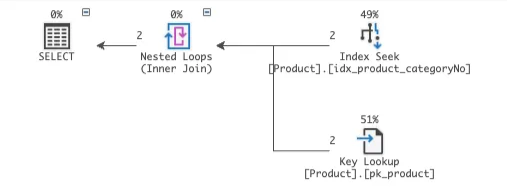
인덱스는 만능??
인덱스는 테이블의 검색 성능을 향상시키기 위한 보조 자료구조로써 성능 향상에 큰 도움이 된다.
하지만 모든 데이터에 대해서 빠른 성능을 내기 위해 인덱스를 생성하는 것은 바람직하지 않다. 인덱스를 사용하는 데는 몇 가지 단점도 함께 존재하는데, 이를 제대로 이해하고 관리하지 않으면 성능이 오히려 악화될 수 있다.
1. 쓰기 성능 저하 (삽입, 수정, 삭제)
인덱스는 읽기 성능을 빠르게 해주는 대신, 데이터를 삽입하거나 수정, 삭제할 때는 성능을 저하시킬 수 있다.
- 추가 작업: 데이터를 변경할 때마다 인덱스도 함께 업데이트되기 때문에, 그만큼 인덱스를 재정렬하거나 재구성하는 작업이 추가된다. 이로 인해 쓰기 작업이 느려질 수밖에 없다.
- 다중 인덱스 문제: 테이블에 인덱스가 많으면 많을수록 이런 쓰기 작업의 성능 저하가 더 커진다. 특히 데이터 변경이 잦은 테이블에서는 이 문제가 더 심각해질 수 있다.
2. 디스크 공간 추가 소모
인덱스는 별도의 데이터 구조로 저장되기 때문에 추가적인 디스크 공간이 필요하다.
- 인덱스 저장 공간: 인덱스를 많이 만들면 그만큼 저장해야 하는 공간도 더 필요하다. 테이블의 크기가 커질수록 인덱스가 차지하는 공간도 커진다.
- 복잡한 인덱스 구조: 복합 인덱스(여러 열을 포함하는 인덱스)나 다중 인덱스를 사용할 경우, 필요한 디스크 공간은 더욱 늘어난다.
3. 인덱스 관리 오버헤드
인덱스는 시간이 지나면서 비효율적으로 변할 수 있다.
- 재구성 필요: 데이터가 추가되고 삭제되면서 인덱스의 구조가 엉망이 될 수 있다. 이럴 경우 인덱스를 주기적으로 재구성(리빌드)하거나 최적화하는 작업이 필요하다. 이 과정에서 관리 비용과 시간이 추가된다.
- 인덱스의 부적절한 사용: 적절하지 않은 열에 인덱스를 생성하거나, 지나치게 많은 인덱스를 만드는 경우 성능 저하가 발생할 수 있다. 인덱스는 많이 만든다고 해서 무조건 좋은 것이 아니며, 전략적인 설계가 필요하다.
4. 복잡한 쿼리에서 인덱스가 비효율적일 수 있음
모든 쿼리가 인덱스를 잘 활용하지는 않는다.
- 범위 검색: 예를 들어, LIKE 검색이나 BETWEEN, <, >와 같은 범위 조건을 사용하는 경우, 인덱스가 성능을 크게 개선하지 못할 때가 있다.
- 함수 사용: 특정 열에 함수나 연산을 적용한 조건에서는 인덱스가 무효화될 수 있다. 이 경우 인덱스가 제대로 사용되지 않으면서 성능 이점을 얻지 못한다.
5. 중복 인덱스 문제
인덱스는 적절하게 설계되지 않으면 오히려 성능을 저하시키기도 한다.
- 중복된 인덱스: 비슷한 열에 여러 개의 인덱스를 생성하면 성능이 향상되기보다는 오히려 더 느려질 수 있다. 이런 경우 중복된 인덱스를 통합하거나 삭제하는 것이 필요하다.
6. 인덱스가 항상 성능을 향상시키는 것은 아님
작은 테이블에서는 인덱스가 오히려 비효율적일 수 있다.
- 작은 테이블: 테이블이 작을 경우, 인덱스를 사용하는 것보다 그냥 테이블을 풀 스캔하는 것이 더 빠를 때도 있다. 인덱스를 검색한 후 다시 테이블 데이터를 가져오는 과정이 더 많은 비용을 발생시킬 수 있기 때문이다.
- 빈번한 데이터 변경: 데이터가 자주 변경되는 테이블에서는 인덱스가 오히려 성능을 떨어뜨릴 수 있다. 인덱스를 지속적으로 업데이트해야 하므로 쓰기 작업이 느려지기 때문이다.
결론
인덱스는 검색 성능을 높이는 강력한 도구지만, 그만큼 쓰기 성능 저하, 디스크 공간 소모, 관리 오버헤드와 같은 단점도 있다. 특히, 인덱스를 너무 많이 만들거나 부적절하게 사용할 경우, 성능이 오히려 악화될 수 있다. 따라서 데이터베이스를 설계할 때는 인덱스 사용의 이점과 단점을 충분히 고려하여 적절한 인덱스 전략을 수립하는 것이 중요하다.
