"해당 게시물은 MySQL 기준으로 정리한 글임을 알려드립니다!"
인덱스
쉽게 찾아볼 수 있도록 순서에 따라 놓은 목록. 데이터베이스의 테이블에 대한 검색 속도를 향상시켜주는 자료구조 입니다.
ex) 책의 색인(찾아보기)
특징
- 인덱스는 항상 최신의 정렬 상태를 유지
- 하나의 데이터베이스 객체
- 데이터베이스 크기의 약 10% 정도의 저장공간 필요
파일구성
테이블 생성 시, 3가지 파일이 생성됩니다.
FRM : 테이블 구조 저장 파일
MYD : 실제 데이터 파일
MYI : Index 정보 파일 (Index 사용 시 생성)
사용자가 쿼리를 통해 Index를 사용하는 칼럼을 검색하게 되면, 이때 MYI 파일의 내용을 활용합니다.
커버링 인덱스(Covering Index)
커버링 인덱스는 쿼리의 실행 결과를 반환하는 데 필요한 모든 데이터를 인덱스에서 바로 찾을 수 있는 인덱스를 말합니다. 즉, 인덱스 자체가 모든 필요한 정보를 포함하고 있어서 디스크에 저장된 실제 데이터를 참조하지 않아도 쿼리를 완료할 수 있습니다.
예를 들어, '성'과 '이름' 두 개의 컬럼을 가진 테이블에서, '성'에 대한 쿼리만 수행하는 경우, '성'과 '이름' 두 컬럼 모두를 포함하는 인덱스가 있다면 이 인덱스는 커버링 인덱스가 됩니다.

커버링 인덱스 사용 시 실행 계획을 확인하는 'explain' 명령어를 확인하면, Extra에 'Using index' 라고 적혀 있습니다.
어떤 기준으로 인덱스를 설정해야 할까요?
- 규모가 큰 테이블
- 조회가 많고, INSERT, UPDATE, DELETE가 자주 발생하지 않는 컬럼
- JOIN이나 WHERE 또는 ORDER BY에 자주 사용되는 컬럼
- 카디널리티(컬럼 중 요소의 개수)가 높은 컬럼(중복도가 낮은)
- 예를 들면, 성별의 카디널리티는 최대가 2이므로 중복도가 매우 높아 인덱스 설정에 적합하지 않습니다.
- 카디널리티 높은 컬럼 예) 주민등록번호, 계좌번호
테이블에 인덱스를 많이 설정하면 좋을까요?
- 디스크 공간을 많이 차지하게 되어 성능 저하를 일으킬 수 있습니다.
- INSERT, UPDATE, DELETE 시에 오버헤드를 일으켜 성능 저하를 일으킵니다.
오버 헤드
추가적인 작업이나 자원 사용을 의미합니다.
데이터 삽입/수정/삭제는 데이터를 변형만 업데이트 하는 것이 아닌, 인덱스도 같이 업데이트 해주는 동기화 작업이 필요합니다.
생성 방법
1. CREATE INDEX 명령어 사용하기
CREATE INDEX index_name
ON table_name(column_name);2. ALTER TABLE 명령어 사용하기
ALTER TABLE table_name
ADD INDEX index_name(column_name);3. 테이블 생성 시 인덱스 설정하기
CREATE TABLE table_name (
column_name1 data_type,
column_name2 data_type,
INDEX index_name (column_name1)
);4. 다중 컬럼 인덱스(Multi Column Index)
CREATE INDEX index_name
ON table_name(column1, column2);다중 컬럼 인덱스는 두 개 이상의 컬럼을 합쳐서 하나의 인덱스로 만드는 것을 말합니다.
예를 들어, '성(last_name)'과 '이름(first_name)' 두 개의 컬럼을 가진 테이블에서, 성과 이름을 모두 사용하여 검색을 수행하는 경우, 성과 이름에 각각 인덱스를 만드는 것보다 성과 이름을 같이 포함하는 하나의 복합 인덱스를 만드는 것이 더 효율적입니다.
인덱스 자료 구조
Hash Table
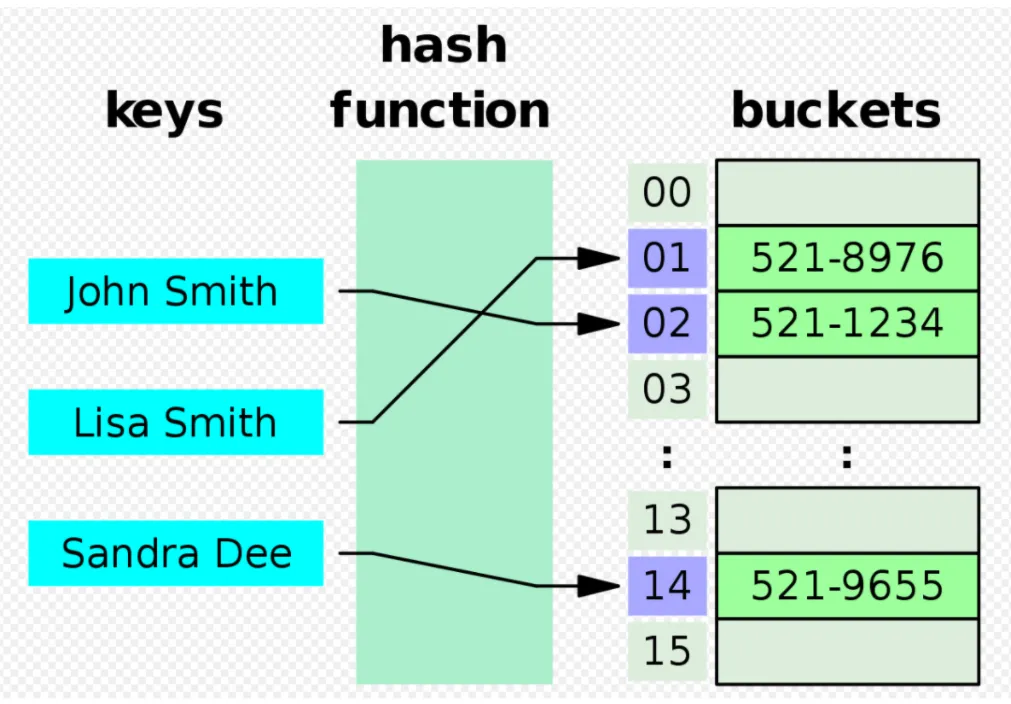
- (Key, Value)로 데이터를 저장하는 자료구조
- 내부적으로 배열(버킷)을 사용하여 데이터를 저장
- 데이터 요소의 주소/인덱스 값이 해시 함수에서 생성
- 키는 해싱 함수를 통해 생성
- 키 값 자체가 데이터를 저장하는 배열의 인덱스가 되기 때문에 데이터 요소의 검색 및 삽입 기능 향상
- 시간 복잡도는 O(1)
- 등호(=) 연산에만 특화 -> '단 하나'의 데이터를 찾을 때 유리
- 해시 함수는 값이 조금이라도 달라지면 완전히 다른 해시 값을 생성
- 부등호 연산(>, <)이 자주 사용되는 데이터베이스 검색을 위해서는 해시 테이블이 부적합
B-Tree
트리는 층 별로 루트 - 브랜치 - 리프 페이지로 나뉩니다.
* 페이지(데이터가 저장되는 단위 - MySQL 기준 16Kbytes)
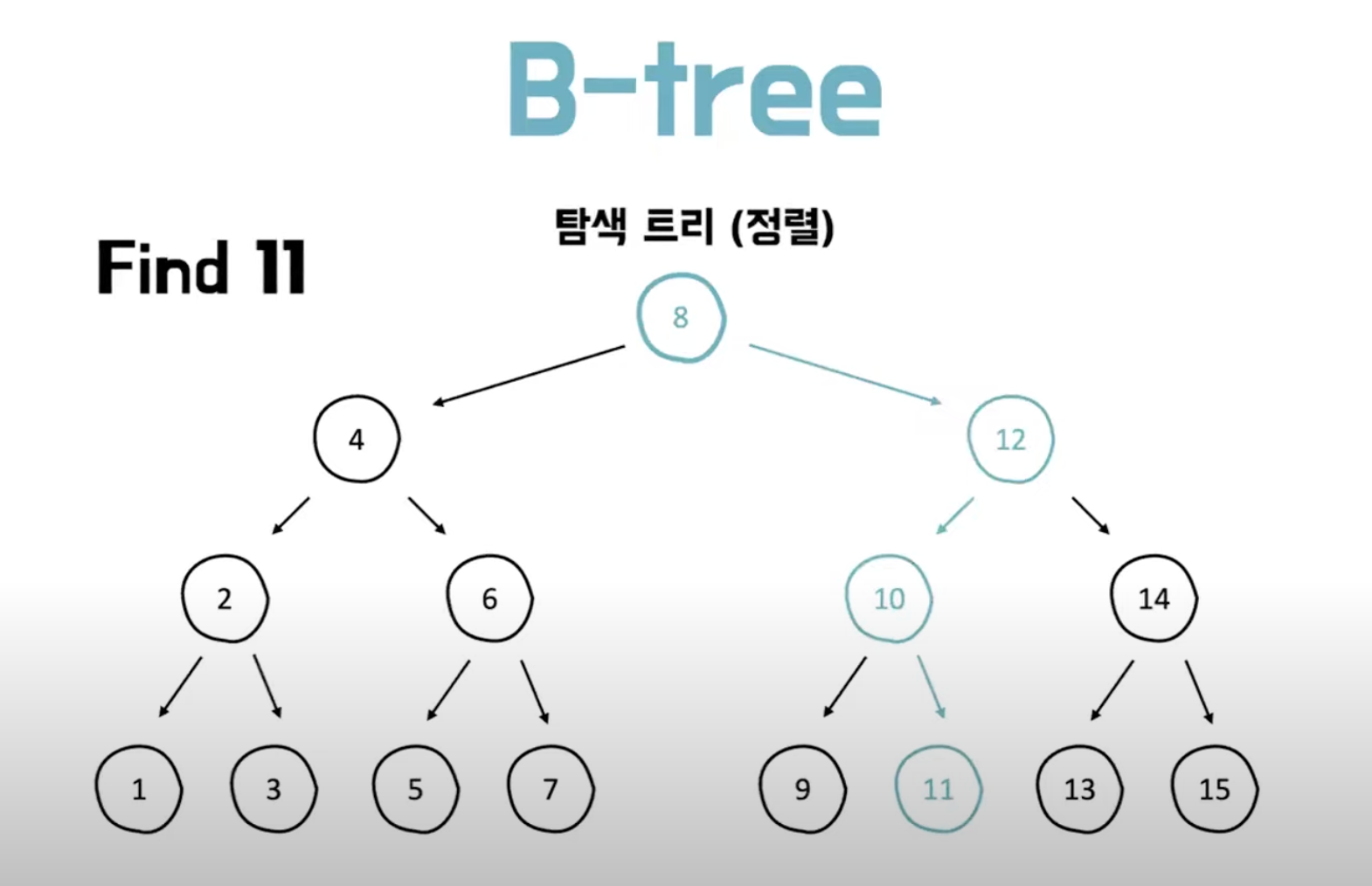
- 한 노드 당 2개 이상의 자식 노드를 가짐.
- branch 노드에 key와 data를 담는 형식
- 시간복잡도는 O(log N)
- 노드안의 배열은 항상 정렬된 상태로 있어 부등호 연산 가능
- 노드의 개수를 늘리고 트리의 전체 높이를 줄여서 빠른 탐색 속도
- 인덱스의 개수는 보통 3~4개가 적당합니다.
균형 트리
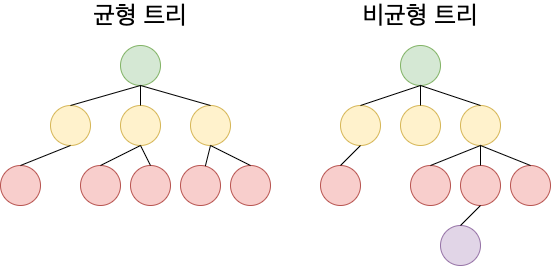
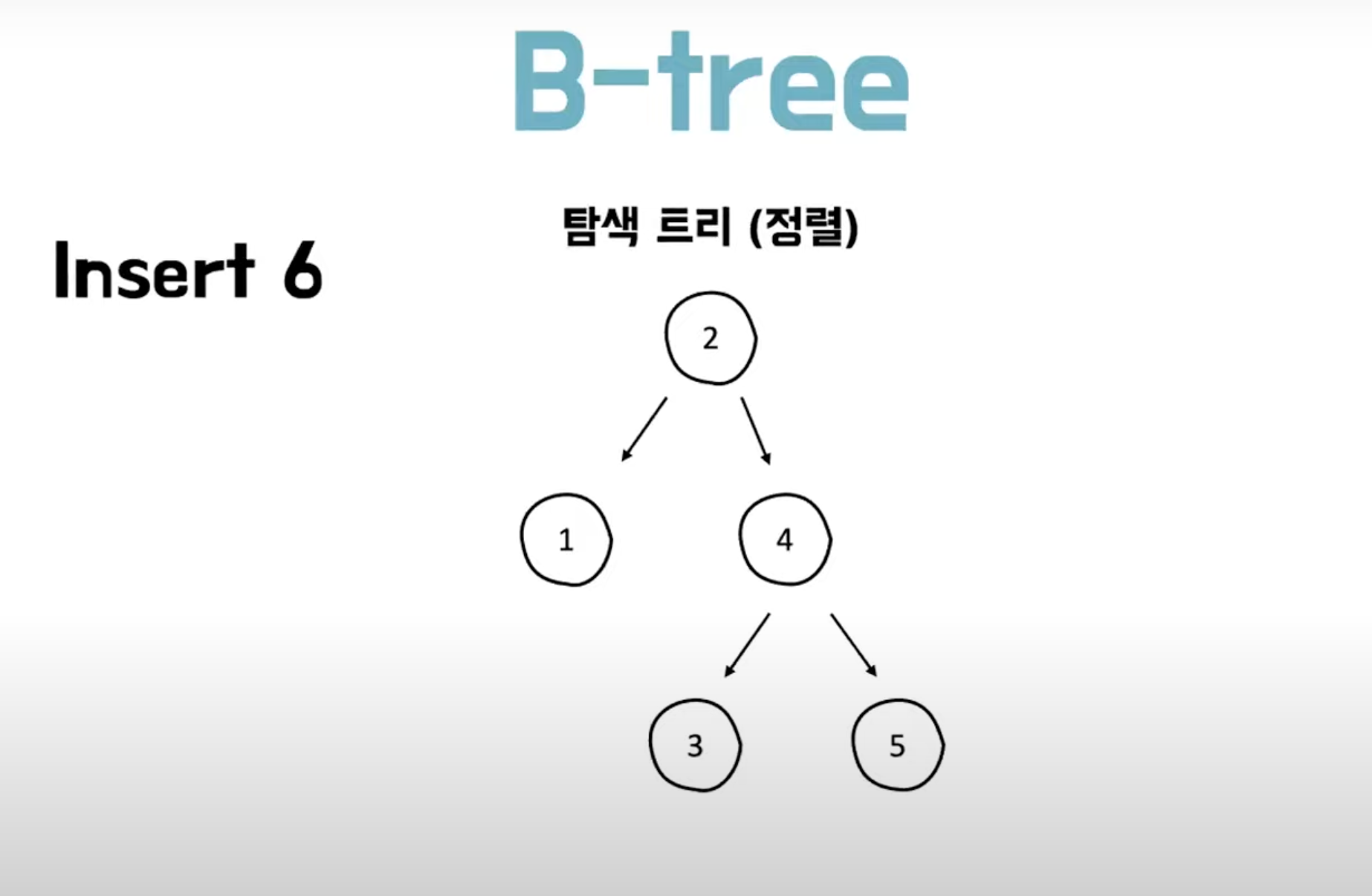
B-tree는 균형적인 트리를 가지는 특성이 있어 삽입/수정/삭제 시에 재정렬이 발생합니다.
insert 시에,
<"before">
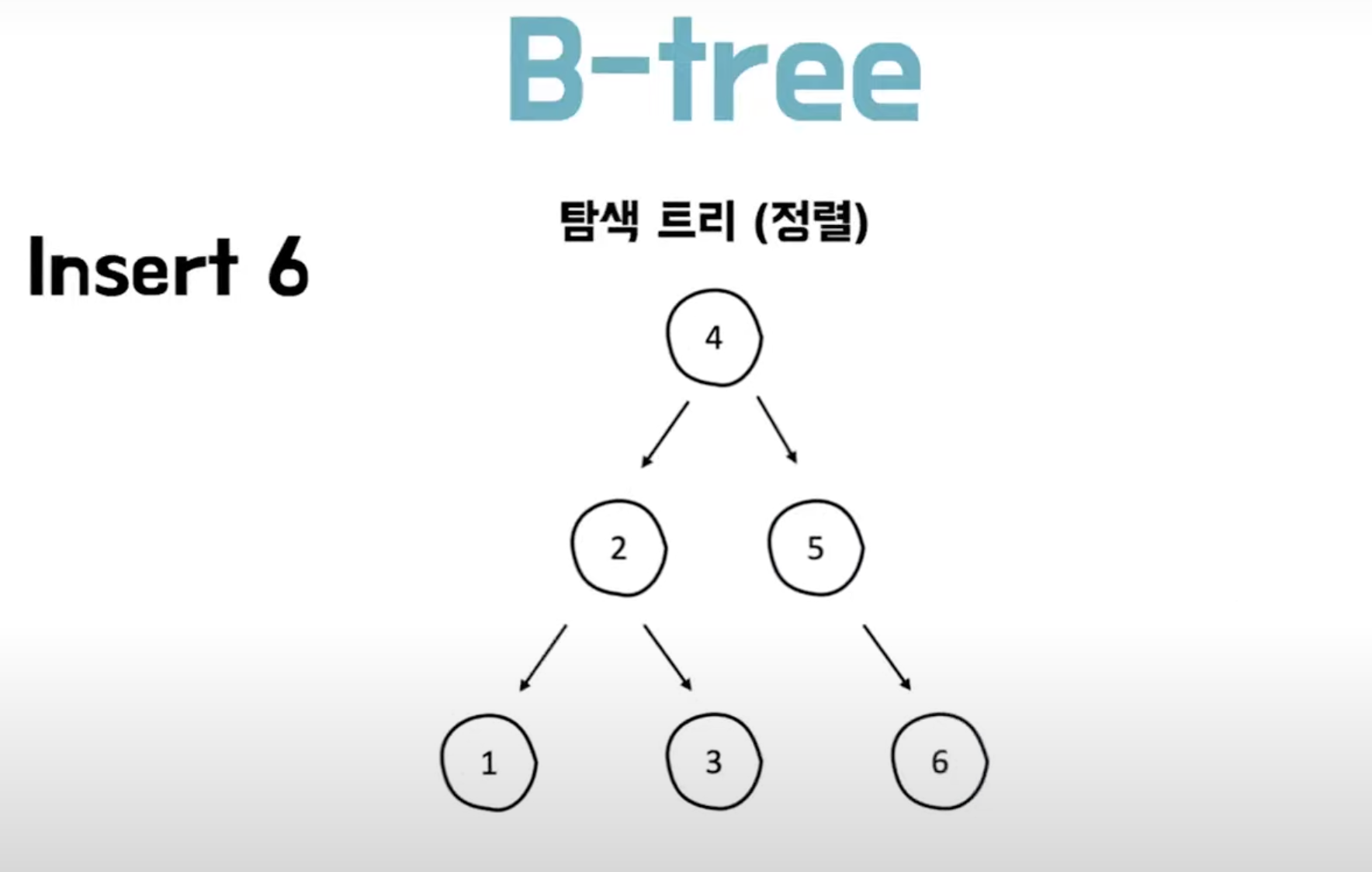
<"after">
B+ Tree
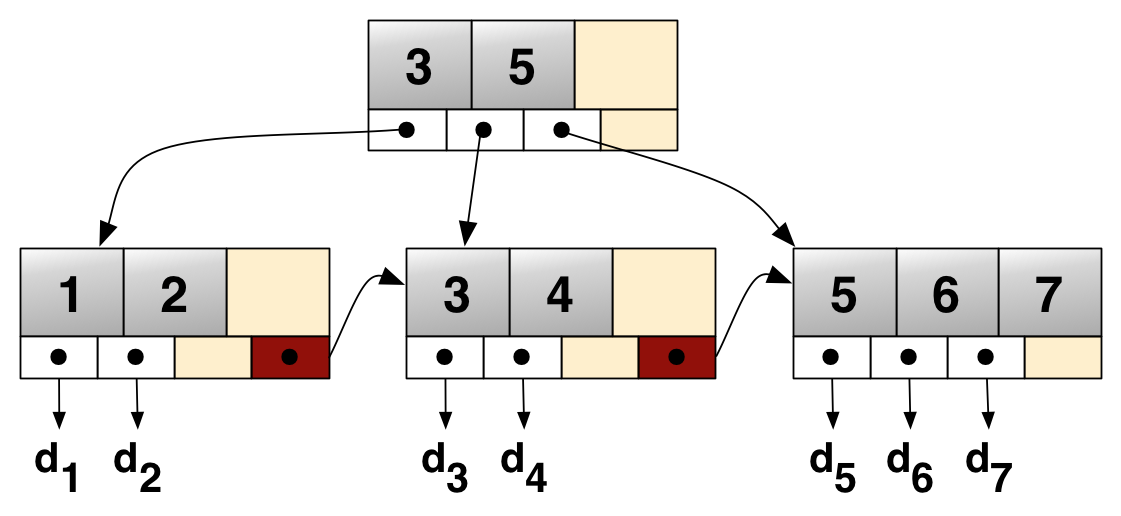
- B-tree의 확장개념, 브랜치 노드에 key만 담아두고, data는 담지 않음
리프 노드에만 key와 data를 저장하고, 리프 노드끼리 Linked list로 연결
- 메모리를 더 확보함으로써 더 많은 key들을 수용
- 하나의 노드에 더 많은 key들을 담을 수 있기에 트리의 높이는 더 낮아짐
- 풀 스캔 시 리프 노드에 데이터가 모두 있기 때문에 한 번의 선형탐색만 하면 됨. B-tree의 경우에는 모든 노드를 확인해야 함
- 범위 검색 시에 b-tree와 성능 차이가 확연합니다.
동작 원리
SELECT userID, name
FROM userTbl
WHERE name = '바비킴'를 실행했을 때,
index가 있는 지 체크.
- index 없을 시
=> 전체 튜플 확인(Full Table Scan)
Result
userID name BBK 바비킴
예시의 인덱스가 작아서 금방 찾지만, 만약 1억 개의 튜플이 있다면 조회 성능은 매우 안 좋을 것입니다.
2. index 있을 시 => 여러 자료 구조 별로 데이터 검색[여기서는 B-tree(Balanced tree) 형태]로 조건에 맞는 데이터 탐색.
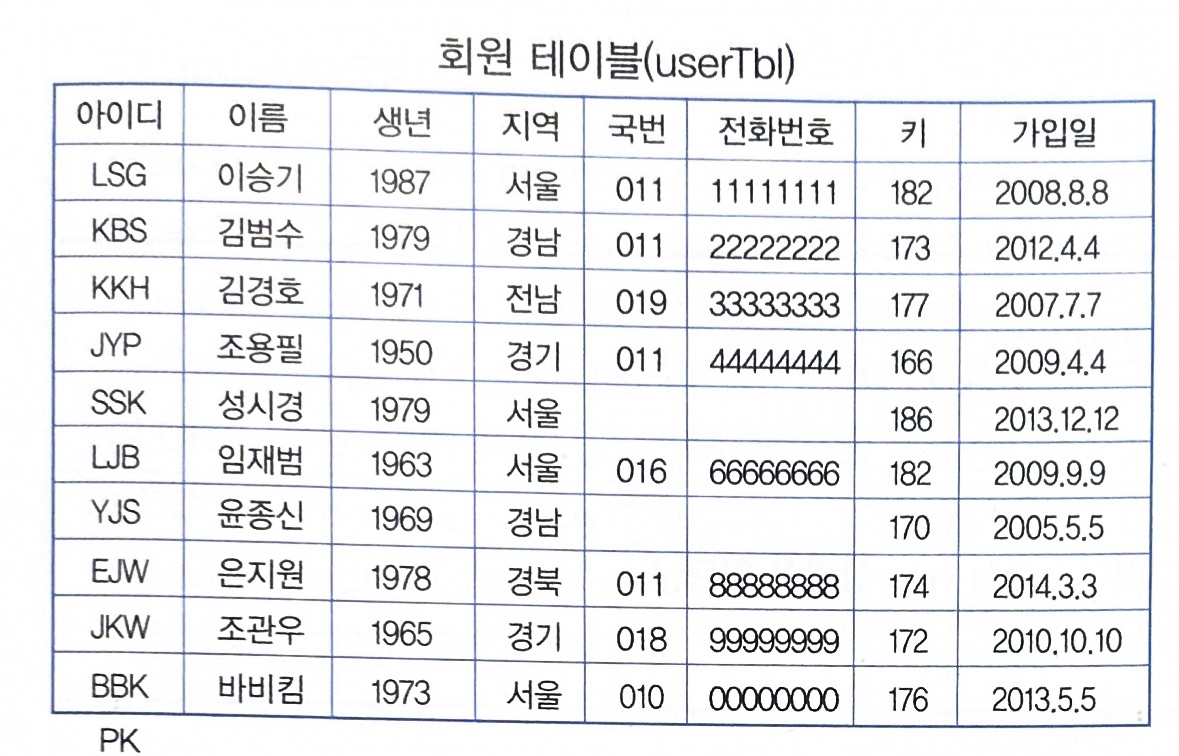
Clustered Index
PK 값과 일치합니다. (테이블 당 1개 제한)
Clustered Index의 대상은 다음과 같습니다.
- PK 값
- PK가 없을땐 (유니크키 & Not Null)
- 둘 다 없을 땐 6byte의 Hidden Key를 생성 (rowid)
- 범위 검색이 Non-Clustered Index 보다 우수합니다.
Clustered Index는 리프 노드에 데이터가 있습니다.
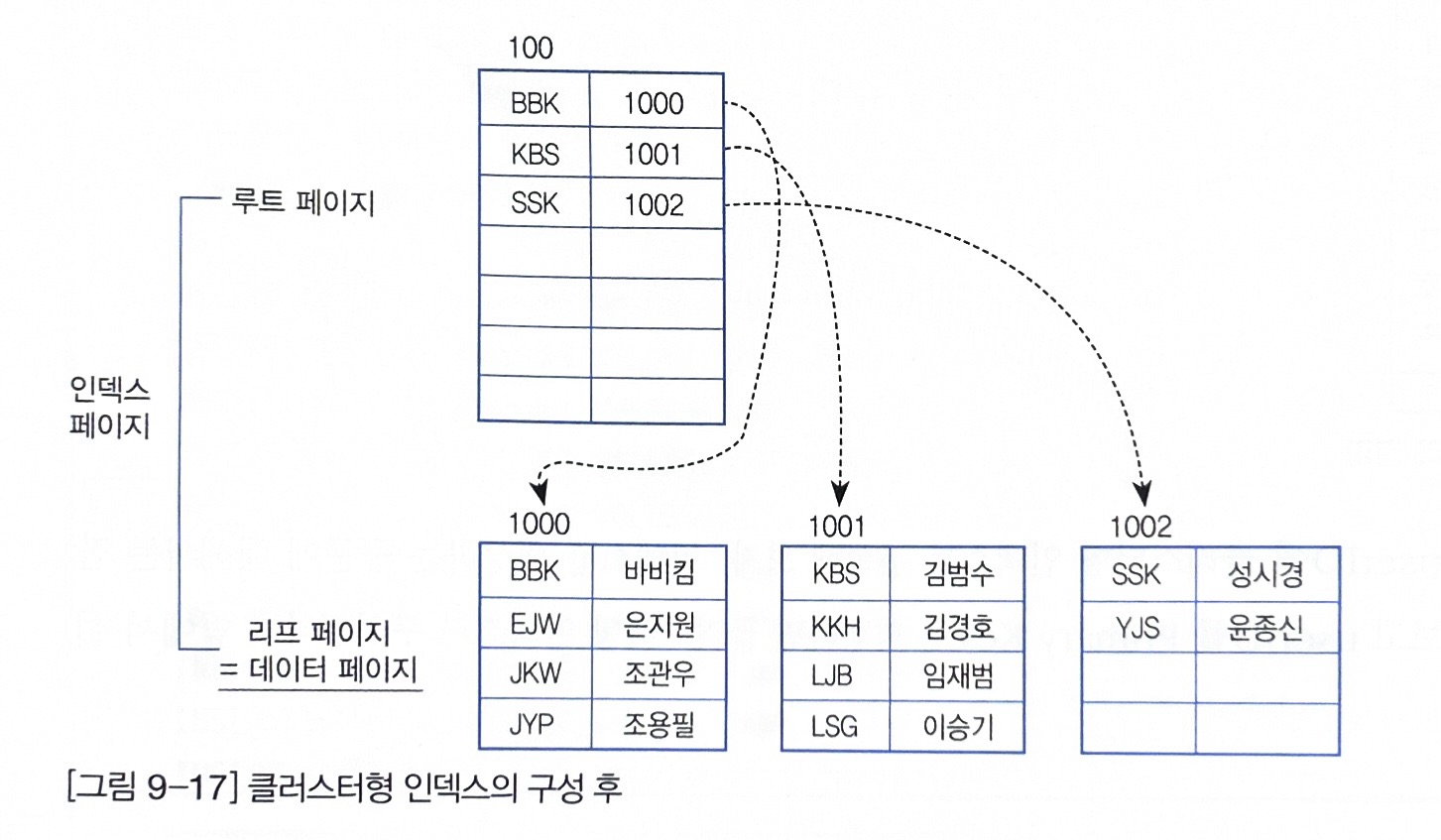
NON-Clustered Index
- 생성된 Index입니다.
- CREATE INDEX 문으로 생성합니다.
- Unique 제약조건을 생성합니다.
- 리프 페이지에서 데이터를 정렬합니다.
- INSERT/UPDATE/DELETE 성능은 Clustered 보다 우수합니다.
데이터 페이지를 정렬하는 것이 아니므로, 뒤쪽 빈 부분에 삽입
Non-Clustered Index는 데이터 페이지를 건드리지 않고, 별도의 장소에 인덱스 페이지를 생성합니다.
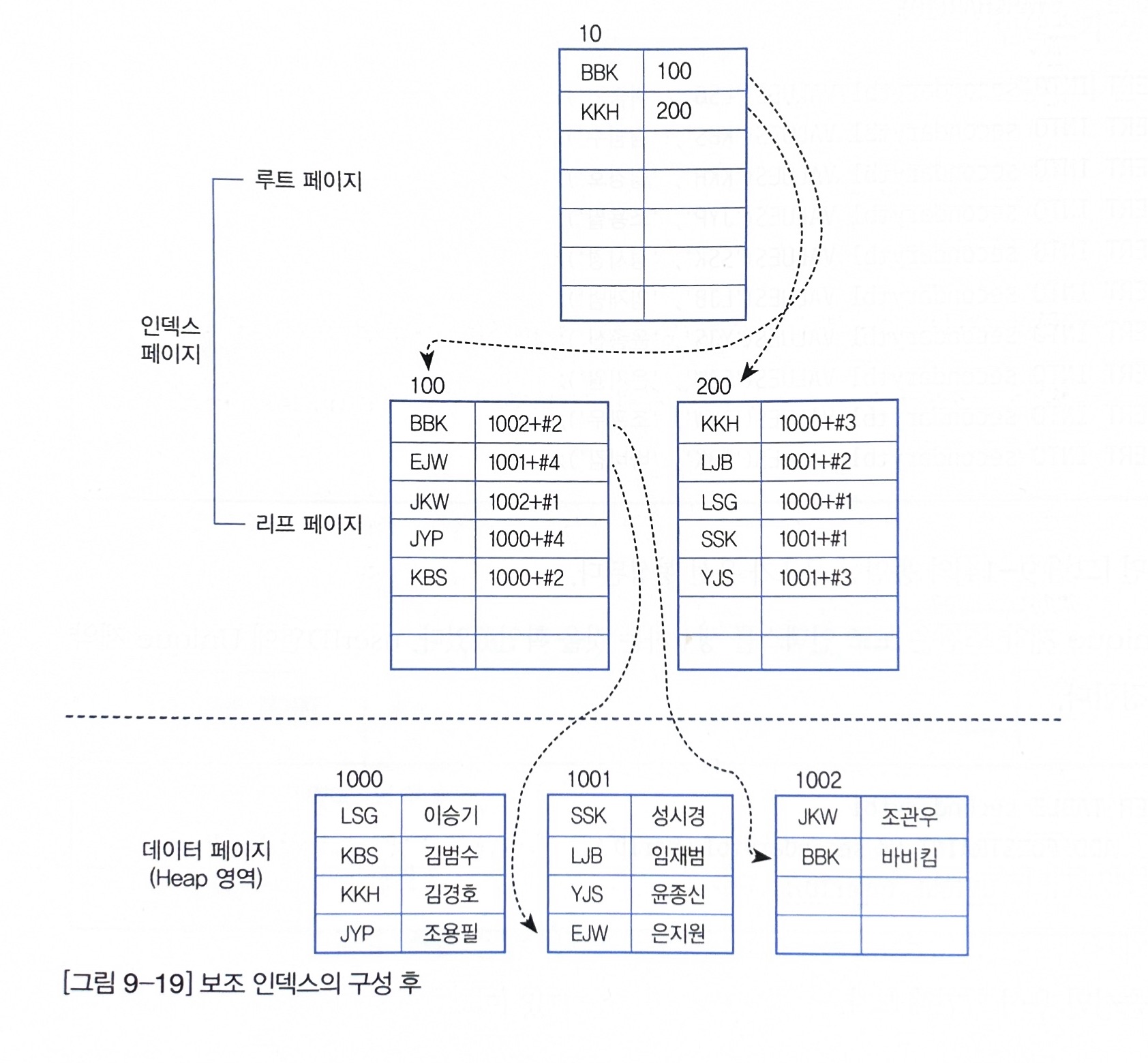
그럼, Clustered Index와 Non-Clustered Index가 같이 있는 경우는 어떻게 실행될까요? 실제로 Non-Clustered Index는 무조건 Clustered Index를 포함하게 됩니다.
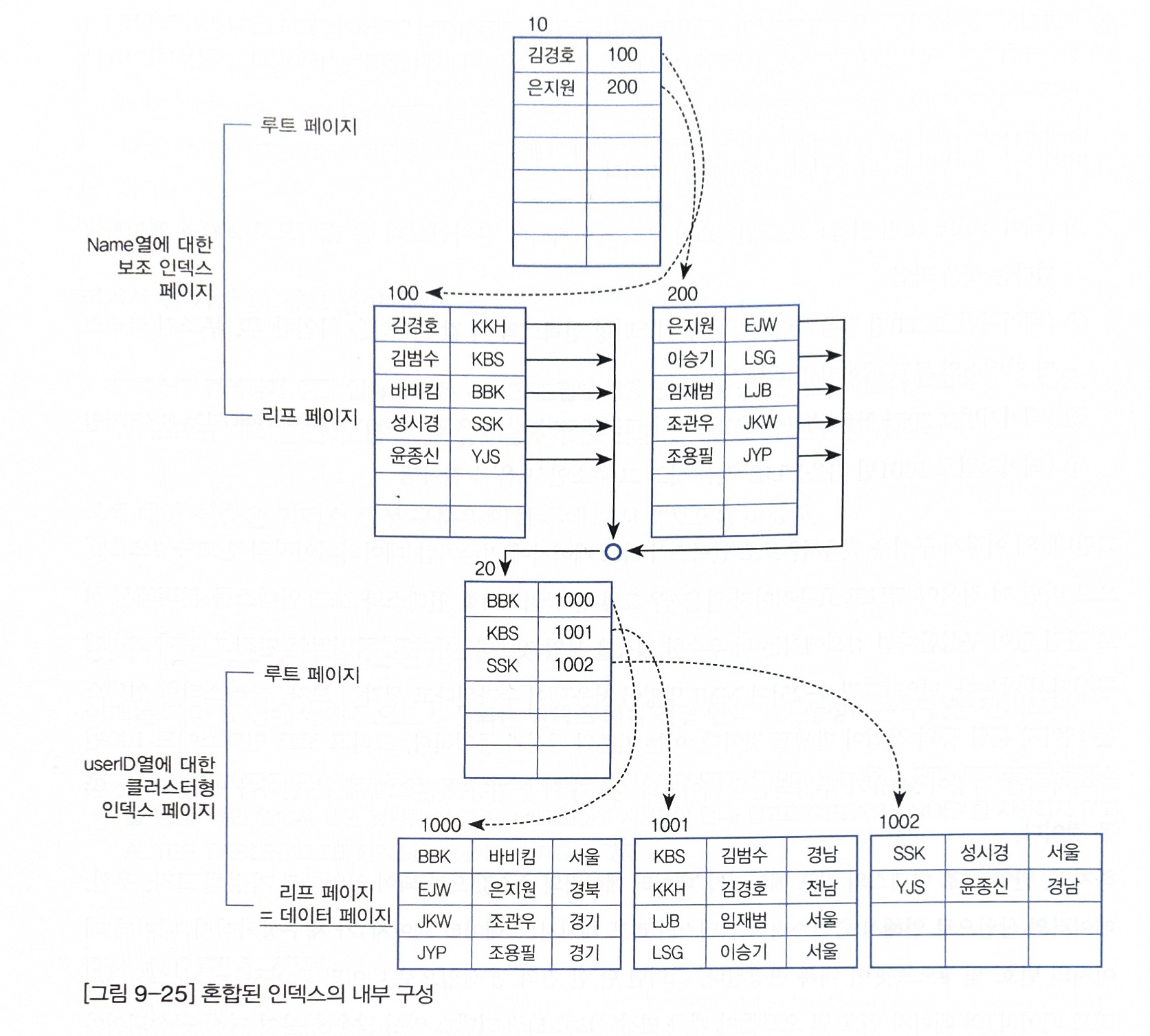
위 그림과 같이 Non-Clustered Index -> Clustered Index 순으로 진행됩니다.
Non-Clustered Index은 키 값(보조키 값 name)으로 index페이지 정렬이 진행됩니다. 여기서, 원래라면 리프 페이지에서 데이터 페이지의 주소 값을 가지고 있어야 하지만 Clustered Index의 데이터를 가지고 있습니다.
특징은 다음과 같습니다.
- Non Clustered Key (일반적인 인덱스) 에는 인덱스 컬럼의 값들과 Clustered Key (PK) 의 값이 포함되어 있음
- Clustered Key 만이 실제 테이블의 row 위치를 알고 있음
인덱스 스캔 방식
Index Range Scan
특정 범위의 키 값을 가진 레코드를 인덱스에서 스캔하는 방식입니다.
주로 BETWEEN, >, >=, <, <= 연산과 같은 범위 쿼리에서 사용됩니다.
Index Unique Scan
유일한 값을 가지는 고유 인덱스를 활용하여 스캔하는 방식입니다.
주로 PRIMARY KEY 또는 UNIQUE 제약 조건이 있는 컬럼에 대한 조회에서 사용됩니다.
Index Full Scan
인덱스의 전체 범위를 스캔하는 방식입니다.
주로 전체 데이터를 조회하는 쿼리에서 사용됩니다.
Loose Index Scan
인덱스의 일부만을 스캔하는 방식입니다.
즉, 모든 레코드를 순차적으로 접근하면서 일치하는지 확인합니다.
Merge Scan
두 개 이상의 인덱스를 이용하여 여러 개의 인덱스 스캔을 병합하는 방식입니다.
여러 인덱스 간의 병합을 통해 최종 결과를 얻습니다.
실행 계획
실행 계획은 쿼리의 성능을 분석하고 최적화하는 데 중요한 도구로, DBMS의 쿼리 옵티마이저가 자동으로 생성합니다. 쿼리 옵티마이저는 주어진 쿼리를 실행하는 데 가능한 모든 방법을 고려하고, 데이터 통계, 인덱스 정보, 테이블 구조 등을 바탕으로 가장 효율적인 실행 계획을 선택합니다.
explain 명령어를 사용하여 실행계획을 확인해볼 수 있습니다.

힌트
힌트는 SQL 튜닝 중 하나로, 옵티마이저의 실행 계획에 관여를 하는 것입니다.
쿼리에 직접적으로 /*+ 힌트구문 */ 형태의 문법으로 삽입하여 옵티마이저에게 실행 계획을 알려주게 됩니다
힌트로 인덱스 사용, 조인 순서, 조인 방법, 직-병렬 처리 등을 관리할 수 있습니다.
References
