
(오늘의 영화 : 벌새)
오늘 한 일 (To Do List)
-
어제부터 진행하던, Naver 영화 랭크 1-50위 크롤링하기
https://movie.naver.com/movie/sdb/rank/rmovie.nhn?sel=pnt&date=20200213&tg=0
// 네이버 영화 랭크 -
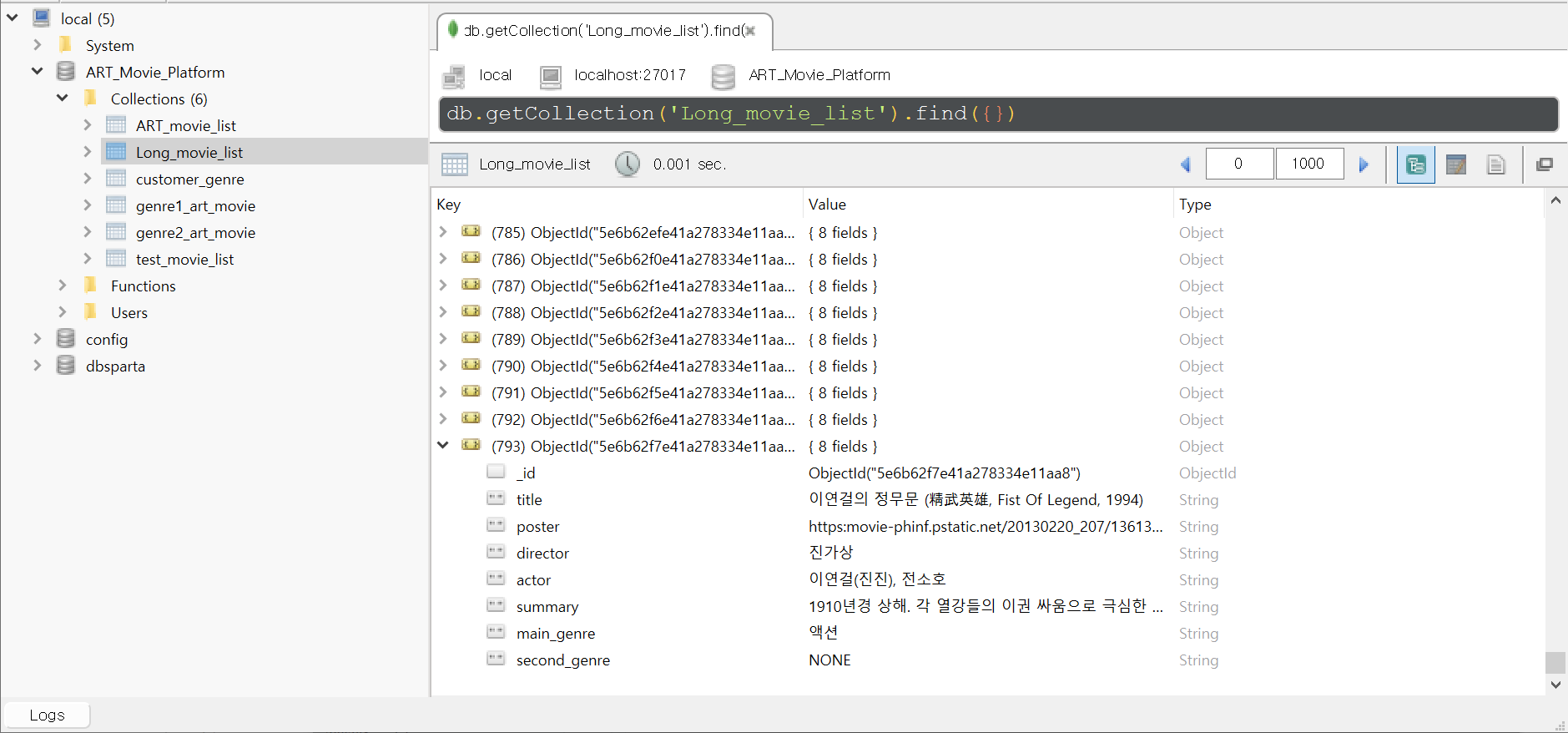
네이버 영화 1-50 위 크롤링 성공
=> Long_moive_list에 저장 완료 (크롤링 한 번 하는데, 15-20분 정도 소요되는 듯)
=> (기존) 168개 / (크롤링 후) 793개
어려웠던 부분
- 자동방지기능을 우회해서 크롤링 하는 것
(바로 이전 포스팅해서 확인할 수 있음) - 디버깅 한 번을 하기 위해서 한 번에, 15-20분 정도 소요
(한 번 Run 시킬 때마다, 신중하게 다 훑어보고 돌리는 습관이 조금씩 들었던 것 같다.) - If / elif / else 구문의 활용방법
(elif의 기능을 몰라서, 2-3시간 동안 삽질의 향연이었다..★)https://dojang.io/mod/page/view.php?id=1262
// if, elif, else 설명 블로그
'내일부터 진행할 것들'
독립영화 DB를 더 채우기 위해서, 기존에 사용한 '영화진흥위원회' 사이트를 이용하거나 새로운 DB 사이트를 찾아야할 것 같다.
(기존) 422개 _ 영호진흥위원회 활용
[네이버 영화 크롤링]
(원본은 GitHub에서 확인)
https://github.com/JiHoon-JK/ART_Cinema_Real_Final/blob/master/ART_CINEMA-final--master/naver_movie.py
// 네이버 영화 크롤링 github
from selenium import webdriver
from bs4 import BeautifulSoup
from pymongo import MongoClient # pymongo를 임포트 하기(패키지 인스톨 먼저 해야겠죠?)
client = MongoClient('localhost', 27017) # mongoDB는 27017 포트로 돌아갑니다.
db = client.ART_Movie_Platform # 'ART_Movie_Platform' 이라는 이름의 db를 만듭니다.
# 우분투에서 webdriver 키기
# chrome_options = webdriver.ChromeOptions()
# chrome_options.add_argument("--headless")
# chrome_options.add_argument("--no-sandbox")
# chrome_options.add_argument("--disable-dev-shm-usage")
# driver 값에다가 넣기 , chrome_options = chrome_options
# 크롤링하다가, 자동 bot으로 인지하지 않도록, 유저정보 넣어주기
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.77 Safari/537.36'}
driver = webdriver.Chrome('./chromedriver')
url = 'https://movie.naver.com/movie/sdb/rank/rmovie.nhn?sel=pnt&date=20200213&tg='
# 드라이버를 여는데, 2초 정도 기다린다. (네트워크가 따라오지 못하는 것을 방지하기 위해서)
driver.implicitly_wait(2)
driver.get(url)
# 청불영화로 인한, 크롤링시 로그인 활성화되는 현상을 방지하기 위해서 임시계정을 만듬
# 아이디 : art_cinema_test / 비번 : a1357924680!
driver.find_element_by_xpath("//*[@id='gnb_login_button']/span[3]").click()
# 임시로, 본인계정으로 로그인 진행
# 조건을 입력해야하는 태그에 대한, ID 값을 찾아서 Send_keys 값으로 입력.
id = 'art_cinema_test'
pw = 'a1357924680!'
driver.execute_script("document.getElementsByName('id')[0].value=\'" + id + "\'")
driver.execute_script("document.getElementsByName('pw')[0].value=\'" + pw + "\'")
# 로그인 버튼을 클릭한다.
driver.find_element_by_id("log.login").click()
Long_movie_ex = {
'title': '',
'poster': '',
'director': '',
'actor': '',
'summary': '',
'main_genre': '',
'second_genre': ''
}
# 0 부터 18까지
for i in range(20):
print('<'+str(i)+'>')
# 느와르 장르는 버림...너무 조건이 많이 붙어야해서...
if i == 3 or i == 8 or i == 9 :
continue
# 장르가 가족(i=12)일 때, 영화가 36개 밖에 없음
elif i == 12 :
driver.get(url + str(i))
print('<' + str(i) + '>')
for j in range(36):
if j == 10 :
continue
if j < 21 :
print(j)
driver.find_element_by_xpath("//*[@id='old_content']/table/tbody/tr[" + str(j + 2) + "]/td[2]/div/a").click()
# 1~20 = +2 , 21~30 = +3, 31~40 = +4 , 41~50 = +5
soup = BeautifulSoup(driver.page_source, 'html.parser')
Long_movie_infos = soup.select('#content > div.article')
# 장르 '드라마' 에 있는 첫 번째 영화에서 추출해야하는 영화정보 제일 큰 셀렉터
for Long_movie_info in Long_movie_infos:
title = str(
Long_movie_info.select_one('div.mv_info_area > div.mv_info > h3 > a').text) + ' (' + str(
Long_movie_info.select_one('div.mv_info_area > div.mv_info > strong').text) + ')'
#print(title)
poster = str(Long_movie_info.select_one('img').attrs['src']).replace('//', '')
#print(poster)
director = str(Long_movie_info.select_one('div.mv_info_area > div.mv_info > dl > dd:nth-child(4) > p > a').text)
#print(director)
actor = str(
Long_movie_info.select_one('div.mv_info_area > div.mv_info > dl > dd:nth-child(6) > p').text)
#print(actor)
summary = ''
#print(summary)
# bold 한 줄거리가 있을경우
if Long_movie_info.select_one('div.section_group.section_group_frst > div:nth-child(1) > div > div.story_area > h5') != None:
summary += str(Long_movie_info.select_one('div.section_group.section_group_frst > div:nth-child(1) > div > div.story_area > h5').text) + \
str(Long_movie_info.select_one(
'div.section_group.section_group_frst > div:nth-child(1) > div > div.story_area > p').text)
elif Long_movie_info.select_one('div.section_group.section_group_frst > div:nth-child(1) > div > div.story_area > p') == None:
summary += 'None'
else:
summary += str(Long_movie_info.select_one('div.section_group.section_group_frst > div:nth-child(1) > div > div.story_area > p').text)
#print(summary)
main_genre = str(Long_movie_info.select_one('div.mv_info_area > div.mv_info > dl > dd:nth-child(2) > p > span:nth-child(1) > a').text)
#print(main_genre)
# 두번째 장르가 존재할경우
if Long_movie_info.select_one(
'div.mv_info_area > div.mv_info > dl > dd:nth-child(2) > p > span:nth-child(1) > a:nth-child(2)') != None:
second_genre = str(Long_movie_info.select_one(
'div.mv_info_area > div.mv_info > dl > dd:nth-child(2) > p > span:nth-child(1) > a:nth-child(2)').text)
else:
second_genre = 'NONE'
Long_movie_ex = {
'title': title,
'poster': poster,
'director': director,
'actor': actor,
'summary': summary,
'main_genre': main_genre,
'second_genre': second_genre
}
print(Long_movie_ex)
# 하나의 딕셔너리로 변수를 만들어서, 효율적인 관리 추구
db.Long_movie_list.insert_one(Long_movie_ex)
# DB에 'Long_movie_list' 라는 목록이름으로 저장
driver.back()
# 21~30번쨰는 +3
# div.mv_info_area > div.mv_info > h3 > a
if 21 <= j and j <= 30 :
# //*[@id="old_content"]/table/tbody/tr[25]/td[2]/div/a
# //*[@id="old_content"]/table/tbody/tr[25]/td[2]/div/a
print (j)
driver.find_element_by_xpath("//*[@id='old_content']/table/tbody/tr[" + str(j + 3) + "]/td[2]/div/a").click()
soup = BeautifulSoup(driver.page_source, 'html.parser')
Long_movie_infos = soup.select('#content > div.article')
# 장르 '드라마' 에 있는 첫 번째 영화에서 추출해야하는 영화정보 제일 큰 셀렉터
# 출력 양식 설정. 근데 이 포문이 의미가 있을까 ?
for Long_movie_info in Long_movie_infos:
# 21번째부터 영화정보 xpath 값 바뀌는거 확인하기 (이후부터 할 것)
title = str(Long_movie_info.select_one('div.mv_info_area > div.mv_info > h3 > a').text) + ' (' + str(Long_movie_info.select_one('div.mv_info_area > div.mv_info > strong').text) + ')'
#print(title)
poster = str(Long_movie_info.select_one('img').attrs['src']).replace('//', '')
#print(poster)
director = str(Long_movie_info.select_one('div.mv_info_area > div.mv_info > dl > dd:nth-child(4) > p > a').text)
#print(director)
actor = str(Long_movie_info.select_one('div.mv_info_area > div.mv_info > dl > dd:nth-child(6) > p').text)
#print(actor)
summary = ''
#print(summary)
# bold 한 줄거리가 있을경우
if Long_movie_info.select_one('div.section_group.section_group_frst > div:nth-child(1) > div > div.story_area > h5') != None:
summary += str(Long_movie_info.select_one('div.section_group.section_group_frst > div:nth-child(1) > div > div.story_area > h5').text) + '/' +str(Long_movie_info.select_one('div.section_group.section_group_frst > div:nth-child(1) > div > div.story_area > p').text)
#줄거리가 없는 경우
elif Long_movie_info.select_one('div.section_group.section_group_frst > div:nth-child(1) > div > div.story_area > p') == None:
summary += 'None'
else:
summary += str(Long_movie_info.select_one('div.section_group.section_group_frst > div:nth-child(1) > div > div.story_area > p').text)
print(summary)
main_genre = str(Long_movie_info.select_one('div.mv_info_area > div.mv_info > dl > dd:nth-child(2) > p > span:nth-child(1) > a').text)
#print(main_genre)
# 두번째 장르가 존재할경우
if Long_movie_info.select_one('div.mv_info_area > div.mv_info > dl > dd:nth-child(2) > p > span:nth-child(1) > a:nth-child(2)') != None:
second_genre = str(Long_movie_info.select_one('div.mv_info_area > div.mv_info > dl > dd:nth-child(2) > p > span:nth-child(1) > a:nth-child(2)').text)
else:
second_genre = 'NONE'
#print(second_genre)
Long_movie_ex = {
'title': title,
'poster': poster,
'director': director,
'actor': actor,
'summary': summary,
'main_genre': main_genre,
'second_genre': second_genre
}
print(Long_movie_ex)
# 하나의 딕셔너리로 변수를 만들어서, 효율적인 관리 추구
db.Long_movie_list.insert_one(Long_movie_ex)
# DB에 'Long_movie_list' 라는 목록이름으로 저장
driver.back()
# 31~40번째는 +4
if 31 <= j and j <= 40 :
print(j)
driver.find_element_by_xpath("//*[@id='old_content']/table/tbody/tr[" + str(j + 4) + "]/td[2]/div/a").click()
soup = BeautifulSoup(driver.page_source, 'html.parser')
Long_movie_infos = soup.select('#content > div.article')
# 장르 '드라마' 에 있는 첫 번째 영화에서 추출해야하는 영화정보 제일 큰 셀렉터
# 출력 양식 설정. 근데 이 포문이 의미가 있을까 ?
for Long_movie_info in Long_movie_infos:
title = str(Long_movie_info.select_one('div.mv_info_area > div.mv_info > h3 > a').text) + ' (' + str(Long_movie_info.select_one('div.mv_info_area > div.mv_info > strong').text) + ')'
#print(title)
poster = str(Long_movie_info.select_one('img').attrs['src']).replace('//', '')
#print(poster)
director = str(Long_movie_info.select_one('div.mv_info_area > div.mv_info > dl > dd:nth-child(4) > p > a').text)
#print(director)
actor = str(Long_movie_info.select_one('div.mv_info_area > div.mv_info > dl > dd:nth-child(6) > p').text)
#print(actor)
summary = ''
#print(summary)
# bold 한 줄거리가 있을경우
if Long_movie_info.select_one('div.section_group.section_group_frst > div:nth-child(1) > div > div.story_area > h5') != None:
summary += str(Long_movie_info.select_one('div.section_group.section_group_frst > div:nth-child(1) > div > div.story_area > h5').text) + '/' +str(Long_movie_info.select_one('div.section_group.section_group_frst > div:nth-child(1) > div > div.story_area > p').text)
elif Long_movie_info.select_one('div.section_group.section_group_frst > div:nth-child(1) > div > div.story_area > p') == None:
summary += 'None'
else:
summary += str(Long_movie_info.select_one('div.section_group.section_group_frst > div:nth-child(1) > div > div.story_area > p').text)
#print(summary)
main_genre = str(Long_movie_info.select_one('div.mv_info_area > div.mv_info > dl > dd:nth-child(2) > p > span:nth-child(1) > a').text)
#print(main_genre)
# 두번째 장르가 존재할경우
if Long_movie_info.select_one('div.mv_info_area > div.mv_info > dl > dd:nth-child(2) > p > span:nth-child(1) > a:nth-child(2)') != None:
second_genre = str(Long_movie_info.select_one('div.mv_info_area > div.mv_info > dl > dd:nth-child(2) > p > span:nth-child(1) > a:nth-child(2)').text)
else:
second_genre = 'NONE'
#print(second_genre)
Long_movie_ex = {
'title': title,
'poster': poster,
'director': director,
'actor': actor,
'summary': summary,
'main_genre': main_genre,
'second_genre': second_genre
}
print(Long_movie_ex)
# 하나의 딕셔너리로 변수를 만들어서, 효율적인 관리 추구
db.Long_movie_list.insert_one(Long_movie_ex)
# DB에 'Long_movie_list' 라는 목록이름으로 저장
driver.back()
continue
# 장르가 전쟁(i=14)일 때,영화가 44개 존재
elif i == 14 :
print('<' + str(i) + '>')
driver.get(url + str(i))
for j in range(44):
if j == 10 :
continue
if j < 21 :
print(j)
driver.find_element_by_xpath("//*[@id='old_content']/table/tbody/tr[" + str(j + 2) + "]/td[2]/div/a").click()
# 1~20 = +2 , 21~30 = +3, 31~40 = +4 , 41~50 = +5
soup = BeautifulSoup(driver.page_source, 'html.parser')
Long_movie_infos = soup.select('#content > div.article')
# 장르 '드라마' 에 있는 첫 번째 영화에서 추출해야하는 영화정보 제일 큰 셀렉터
for Long_movie_info in Long_movie_infos:
title = str(
Long_movie_info.select_one('div.mv_info_area > div.mv_info > h3 > a').text) + ' (' + str(
Long_movie_info.select_one('div.mv_info_area > div.mv_info > strong').text) + ')'
#print(title)
poster = str(Long_movie_info.select_one('img').attrs['src']).replace('//', '')
#print(poster)
director = str(Long_movie_info.select_one('div.mv_info_area > div.mv_info > dl > dd:nth-child(4) > p > a').text)
#print(director)
actor = str(
Long_movie_info.select_one('div.mv_info_area > div.mv_info > dl > dd:nth-child(6) > p').text)
#print(actor)
summary = ''
#print(summary)
# bold 한 줄거리가 있을경우
if Long_movie_info.select_one('div.section_group.section_group_frst > div:nth-child(1) > div > div.story_area > h5') != None:
summary += str(Long_movie_info.select_one('div.section_group.section_group_frst > div:nth-child(1) > div > div.story_area > h5').text) + \
str(Long_movie_info.select_one(
'div.section_group.section_group_frst > div:nth-child(1) > div > div.story_area > p').text)
elif Long_movie_info.select_one('div.section_group.section_group_frst > div:nth-child(1) > div > div.story_area > p') == None:
summary += 'None'
else:
summary += str(Long_movie_info.select_one('div.section_group.section_group_frst > div:nth-child(1) > div > div.story_area > p').text)
#print(summary)
main_genre = str(Long_movie_info.select_one('div.mv_info_area > div.mv_info > dl > dd:nth-child(2) > p > span:nth-child(1) > a').text)
#print(main_genre)
# 두번째 장르가 존재할경우
if Long_movie_info.select_one(
'div.mv_info_area > div.mv_info > dl > dd:nth-child(2) > p > span:nth-child(1) > a:nth-child(2)') != None:
second_genre = str(Long_movie_info.select_one(
'div.mv_info_area > div.mv_info > dl > dd:nth-child(2) > p > span:nth-child(1) > a:nth-child(2)').text)
else:
second_genre = 'NONE'
Long_movie_ex = {
'title': title,
'poster': poster,
'director': director,
'actor': actor,
'summary': summary,
'main_genre': main_genre,
'second_genre': second_genre
}
print(Long_movie_ex)
# 하나의 딕셔너리로 변수를 만들어서, 효율적인 관리 추구
db.Long_movie_list.insert_one(Long_movie_ex)
# DB에 'Long_movie_list' 라는 목록이름으로 저장
driver.back()
# 21~30번쨰는 +3
# div.mv_info_area > div.mv_info > h3 > a
if 21 <= j and j <= 30 :
# //*[@id="old_content"]/table/tbody/tr[25]/td[2]/div/a
# //*[@id="old_content"]/table/tbody/tr[25]/td[2]/div/a
print (j)
driver.find_element_by_xpath("//*[@id='old_content']/table/tbody/tr[" + str(j + 3) + "]/td[2]/div/a").click()
soup = BeautifulSoup(driver.page_source, 'html.parser')
Long_movie_infos = soup.select('#content > div.article')
# 장르 '드라마' 에 있는 첫 번째 영화에서 추출해야하는 영화정보 제일 큰 셀렉터
# 출력 양식 설정. 근데 이 포문이 의미가 있을까 ?
for Long_movie_info in Long_movie_infos:
# 21번째부터 영화정보 xpath 값 바뀌는거 확인하기 (이후부터 할 것)
title = str(Long_movie_info.select_one('div.mv_info_area > div.mv_info > h3 > a').text) + ' (' + str(Long_movie_info.select_one('div.mv_info_area > div.mv_info > strong').text) + ')'
#print(title)
poster = str(Long_movie_info.select_one('img').attrs['src']).replace('//', '')
#print(poster)
director = str(Long_movie_info.select_one('div.mv_info_area > div.mv_info > dl > dd:nth-child(4) > p > a').text)
#print(director)
actor = str(Long_movie_info.select_one('div.mv_info_area > div.mv_info > dl > dd:nth-child(6) > p').text)
#print(actor)
summary = ''
#print(summary)
# bold 한 줄거리가 있을경우
if Long_movie_info.select_one('div.section_group.section_group_frst > div:nth-child(1) > div > div.story_area > h5') != None:
summary += str(Long_movie_info.select_one('div.section_group.section_group_frst > div:nth-child(1) > div > div.story_area > h5').text) + '/' +str(Long_movie_info.select_one('div.section_group.section_group_frst > div:nth-child(1) > div > div.story_area > p').text)
elif Long_movie_info.select_one('div.section_group.section_group_frst > div:nth-child(1) > div > div.story_area > p') == None:
summary += 'None'
else:
summary += str(Long_movie_info.select_one('div.section_group.section_group_frst > div:nth-child(1) > div > div.story_area > p').text)
#print(summary)
main_genre = str(Long_movie_info.select_one('div.mv_info_area > div.mv_info > dl > dd:nth-child(2) > p > span:nth-child(1) > a').text)
#print(main_genre)
# 두번째 장르가 존재할경우
if Long_movie_info.select_one('div.mv_info_area > div.mv_info > dl > dd:nth-child(2) > p > span:nth-child(1) > a:nth-child(2)') != None:
second_genre = str(Long_movie_info.select_one('div.mv_info_area > div.mv_info > dl > dd:nth-child(2) > p > span:nth-child(1) > a:nth-child(2)').text)
else:
second_genre = 'NONE'
#print(second_genre)
Long_movie_ex = {
'title': title,
'poster': poster,
'director': director,
'actor': actor,
'summary': summary,
'main_genre': main_genre,
'second_genre': second_genre
}
print(Long_movie_ex)
# 하나의 딕셔너리로 변수를 만들어서, 효율적인 관리 추구
db.Long_movie_list.insert_one(Long_movie_ex)
# DB에 'Long_movie_list' 라는 목록이름으로 저장
driver.back()
# 31~40번째는 +4
if 31 <= j and j <= 40 :
print(j)
driver.find_element_by_xpath("//*[@id='old_content']/table/tbody/tr[" + str(j + 4) + "]/td[2]/div/a").click()
soup = BeautifulSoup(driver.page_source, 'html.parser')
Long_movie_infos = soup.select('#content > div.article')
# 장르 '드라마' 에 있는 첫 번째 영화에서 추출해야하는 영화정보 제일 큰 셀렉터
# 출력 양식 설정. 근데 이 포문이 의미가 있을까 ?
for Long_movie_info in Long_movie_infos:
title = str(Long_movie_info.select_one('div.mv_info_area > div.mv_info > h3 > a').text) + ' (' + str(Long_movie_info.select_one('div.mv_info_area > div.mv_info > strong').text) + ')'
#print(title)
poster = str(Long_movie_info.select_one('img').attrs['src']).replace('//', '')
#print(poster)
director = str(Long_movie_info.select_one('div.mv_info_area > div.mv_info > dl > dd:nth-child(4) > p > a').text)
#print(director)
actor = str(Long_movie_info.select_one('div.mv_info_area > div.mv_info > dl > dd:nth-child(6) > p').text)
#print(actor)
summary = ''
#print(summary)
# bold 한 줄거리가 있을경우
if Long_movie_info.select_one('div.section_group.section_group_frst > div:nth-child(1) > div > div.story_area > h5') != None:
summary += str(Long_movie_info.select_one('div.section_group.section_group_frst > div:nth-child(1) > div > div.story_area > h5').text) + '/' +str(Long_movie_info.select_one('div.section_group.section_group_frst > div:nth-child(1) > div > div.story_area > p').text)
elif Long_movie_info.select_one('div.section_group.section_group_frst > div:nth-child(1) > div > div.story_area > p') == None:
summary += 'None'
else:
summary += str(Long_movie_info.select_one('div.section_group.section_group_frst > div:nth-child(1) > div > div.story_area > p').text)
#print(summary)
main_genre = str(Long_movie_info.select_one('div.mv_info_area > div.mv_info > dl > dd:nth-child(2) > p > span:nth-child(1) > a').text)
#print(main_genre)
# 두번째 장르가 존재할경우
if Long_movie_info.select_one('div.mv_info_area > div.mv_info > dl > dd:nth-child(2) > p > span:nth-child(1) > a:nth-child(2)') != None:
second_genre = str(Long_movie_info.select_one('div.mv_info_area > div.mv_info > dl > dd:nth-child(2) > p > span:nth-child(1) > a:nth-child(2)').text)
else:
second_genre = 'NONE'
#print(second_genre)
Long_movie_ex = {
'title': title,
'poster': poster,
'director': director,
'actor': actor,
'summary': summary,
'main_genre': main_genre,
'second_genre': second_genre
}
print(Long_movie_ex)
# 하나의 딕셔너리로 변수를 만들어서, 효율적인 관리 추구
db.Long_movie_list.insert_one(Long_movie_ex)
# DB에 'Long_movie_list' 라는 목록이름으로 저장
driver.back()
# 41~50번째 +5
if 41 <= j and j <= 51 :
print(j)
#// *[ @ id = "old_content"] / table / tbody / tr[55] / td[2] / div / a
driver.find_element_by_xpath("//*[@id='old_content']/table/tbody/tr[" + str(j + 5) + "]/td[2]/div/a").click()
soup = BeautifulSoup(driver.page_source, 'html.parser')
Long_movie_infos = soup.select('#content > div.article')
# 장르 '드라마' 에 있는 첫 번째 영화에서 추출해야하는 영화정보 제일 큰 셀렉터
# 출력 양식 설정. 근데 이 포문이 의미가 있을까 ?
for Long_movie_info in Long_movie_infos:
title = str(Long_movie_info.select_one('div.mv_info_area > div.mv_info > h3 > a').text) + ' (' + str(Long_movie_info.select_one('div.mv_info_area > div.mv_info > strong').text) + ')'
poster = str(Long_movie_info.select_one('img').attrs['src']).replace('//', '')
director = str(Long_movie_info.select_one('div.mv_info_area > div.mv_info > dl > dd:nth-child(4) > p > a').text)
actor = str(Long_movie_info.select_one('div.mv_info_area > div.mv_info > dl > dd:nth-child(6) > p').text)
summary = ''
# bold 한 줄거리가 있을경우
if Long_movie_info.select_one('div.section_group.section_group_frst > div:nth-child(1) > div > div.story_area > h5') != None:
summary += str(Long_movie_info.select_one('div.section_group.section_group_frst > div:nth-child(1) > div > div.story_area > h5').text) + '/' +str(Long_movie_info.select_one('div.section_group.section_group_frst > div:nth-child(1) > div > div.story_area > p').text)
else:
summary += str(Long_movie_info.select_one('div.section_group.section_group_frst > div:nth-child(1) > div > div.story_area > p').text)
main_genre = str(Long_movie_info.select_one('div.mv_info_area > div.mv_info > dl > dd:nth-child(2) > p > span:nth-child(1) > a').text)
# 두번째 장르가 존재할경우
if Long_movie_info.select_one('div.mv_info_area > div.mv_info > dl > dd:nth-child(2) > p > span:nth-child(1) > a:nth-child(2)') != None:
second_genre = str(Long_movie_info.select_one('div.mv_info_area > div.mv_info > dl > dd:nth-child(2) > p > span:nth-child(1) > a:nth-child(2)').text)
else:
second_genre = 'NONE'
Long_movie_ex = {
'title': title,
'poster': poster,
'director': director,
'actor': actor,
'summary': summary,
'main_genre': main_genre,
'second_genre': second_genre
}
print(Long_movie_ex)
# 하나의 딕셔너리로 변수를 만들어서, 효율적인 관리 추구
db.Long_movie_list.insert_one(Long_movie_ex)
# DB에 'Long_movie_list' 라는 목록이름으로 저장
driver.back()
continue
# 장르가 뮤지컬일 때, 영화가 16개 밖에 없음
elif i == 17 :
print('<' + str(i) + '>')
driver.get(url + str(i))
for j in range(16):
if j == 10 :
continue
if j < 21 :
print(j)
driver.find_element_by_xpath("//*[@id='old_content']/table/tbody/tr[" + str(j + 2) + "]/td[2]/div/a").click()
# 1~20 = +2 , 21~30 = +3, 31~40 = +4 , 41~50 = +5
soup = BeautifulSoup(driver.page_source, 'html.parser')
Long_movie_infos = soup.select('#content > div.article')
# 장르 '드라마' 에 있는 첫 번째 영화에서 추출해야하는 영화정보 제일 큰 셀렉터
for Long_movie_info in Long_movie_infos:
title = str(
Long_movie_info.select_one('div.mv_info_area > div.mv_info > h3 > a').text) + ' (' + str(
Long_movie_info.select_one('div.mv_info_area > div.mv_info > strong').text) + ')'
#print(title)
poster = str(Long_movie_info.select_one('img').attrs['src']).replace('//', '')
#print(poster)
director = str(Long_movie_info.select_one('div.mv_info_area > div.mv_info > dl > dd:nth-child(4) > p > a').text)
#print(director)
actor = str(
Long_movie_info.select_one('div.mv_info_area > div.mv_info > dl > dd:nth-child(6) > p').text)
#print(actor)
summary = ''
#print(summary)
# bold 한 줄거리가 있을경우
if Long_movie_info.select_one('div.section_group.section_group_frst > div:nth-child(1) > div > div.story_area > h5') != None:
summary += str(Long_movie_info.select_one('div.section_group.section_group_frst > div:nth-child(1) > div > div.story_area > h5').text) + \
str(Long_movie_info.select_one(
'div.section_group.section_group_frst > div:nth-child(1) > div > div.story_area > p').text)
elif Long_movie_info.select_one('div.section_group.section_group_frst > div:nth-child(1) > div > div.story_area > p') == None:
summary += 'None'
else:
summary += str(Long_movie_info.select_one('div.section_group.section_group_frst > div:nth-child(1) > div > div.story_area > p').text)
#print(summary)
main_genre = str(Long_movie_info.select_one('div.mv_info_area > div.mv_info > dl > dd:nth-child(2) > p > span:nth-child(1) > a').text)
#print(main_genre)
# 두번째 장르가 존재할경우
if Long_movie_info.select_one(
'div.mv_info_area > div.mv_info > dl > dd:nth-child(2) > p > span:nth-child(1) > a:nth-child(2)') != None:
second_genre = str(Long_movie_info.select_one(
'div.mv_info_area > div.mv_info > dl > dd:nth-child(2) > p > span:nth-child(1) > a:nth-child(2)').text)
else:
second_genre = 'NONE'
Long_movie_ex = {
'title': title,
'poster': poster,
'director': director,
'actor': actor,
'summary': summary,
'main_genre': main_genre,
'second_genre': second_genre
}
print(Long_movie_ex)
# 하나의 딕셔너리로 변수를 만들어서, 효율적인 관리 추구
db.Long_movie_list.insert_one(Long_movie_ex)
# DB에 'Long_movie_list' 라는 목록이름으로 저장
driver.back()
continue
# 랭킹페이지 접근
else:
driver.get(url + str(i))
print('else구문'+'<' + str(i) + '>')
for j in range(51):
# 장르마다 1위-50위까지 반복
# xpath 를 사용하여, 1위로 찍힌 영화명을 클릭 (클릭해야 영화정보가 있는 사이트로 넘어갈 수 있음)
# //*[@id="old_content"]/table/tbody/tr[2]/td[2]/div/a
# //*[@id="old_content"]/table/tbody/tr[13]/td[2]/div 11번쨰 영화
# //*[@id="old_content"]/table/tbody/tr[22]/td[2]/div/a 20번쨰 영화 +2
# //*[@id="old_content"]/table/tbody/tr[24]/td[2]/div/a 21번째 영화 +3
# //*[@id="old_content"]/table/tbody/tr[33]/td[2] 30번째 +3
# //*[@id="old_content"]/table/tbody/tr[35]/td[2]/div/a 31번째 +4
# //*[@id="old_content"]/table/tbody/tr[44]/td[2]/div/a 40번째 +4
# //*[@id="old_content"]/table/tbody/tr[46]/td[2]/div/a 41번째 +5
# //*[@id="old_content"]/table/tbody/tr[54]/td[2]/div/a 49번째 +5
# //*[@id="old_content"]/table/tbody/tr[55]/td[2]/div/a 50번째 +5
# 1~20 = +2 , 21~30 = +3, 31~40 = +4 , 41~50 = +5 : 더해지는 값이 전부 다 다름
# j = 10 일때의 할당값이 없어서, 10일때는 패스
if j == 10 :
continue
if j < 21 :
print(j)
driver.find_element_by_xpath("//*[@id='old_content']/table/tbody/tr[" + str(j + 2) + "]/td[2]/div/a").click()
# 1~20 = +2 , 21~30 = +3, 31~40 = +4 , 41~50 = +5
soup = BeautifulSoup(driver.page_source, 'html.parser')
Long_movie_infos = soup.select('#content > div.article')
# 장르 '드라마' 에 있는 첫 번째 영화에서 추출해야하는 영화정보 제일 큰 셀렉터
for Long_movie_info in Long_movie_infos:
title = str(
Long_movie_info.select_one('div.mv_info_area > div.mv_info > h3 > a').text) + ' (' + str(
Long_movie_info.select_one('div.mv_info_area > div.mv_info > strong').text) + ')'
#print(title)
poster = str(Long_movie_info.select_one('img').attrs['src']).replace('//', '')
#print(poster)
director = str(Long_movie_info.select_one('div.mv_info_area > div.mv_info > dl > dd:nth-child(4) > p > a').text)
#print(director)
actor = str(
Long_movie_info.select_one('div.mv_info_area > div.mv_info > dl > dd:nth-child(6) > p').text)
#print(actor)
summary = ''
#print(summary)
# bold 한 줄거리가 있을경우
if Long_movie_info.select_one('div.section_group.section_group_frst > div:nth-child(1) > div > div.story_area > h5') != None:
summary += str(Long_movie_info.select_one('div.section_group.section_group_frst > div:nth-child(1) > div > div.story_area > h5').text) + \
str(Long_movie_info.select_one(
'div.section_group.section_group_frst > div:nth-child(1) > div > div.story_area > p').text)
elif Long_movie_info.select_one('div.section_group.section_group_frst > div:nth-child(1) > div > div.story_area > p') == None:
summary += 'None'
else:
summary += str(Long_movie_info.select_one('div.section_group.section_group_frst > div:nth-child(1) > div > div.story_area > p').text)
#print(summary)
main_genre = str(Long_movie_info.select_one('div.mv_info_area > div.mv_info > dl > dd:nth-child(2) > p > span:nth-child(1) > a').text)
#print(main_genre)
# 두번째 장르가 존재할경우
if Long_movie_info.select_one(
'div.mv_info_area > div.mv_info > dl > dd:nth-child(2) > p > span:nth-child(1) > a:nth-child(2)') != None:
second_genre = str(Long_movie_info.select_one(
'div.mv_info_area > div.mv_info > dl > dd:nth-child(2) > p > span:nth-child(1) > a:nth-child(2)').text)
else:
second_genre = 'NONE'
Long_movie_ex = {
'title': title,
'poster': poster,
'director': director,
'actor': actor,
'summary': summary,
'main_genre': main_genre,
'second_genre': second_genre
}
print(Long_movie_ex)
# 하나의 딕셔너리로 변수를 만들어서, 효율적인 관리 추구
db.Long_movie_list.insert_one(Long_movie_ex)
# DB에 'Long_movie_list' 라는 목록이름으로 저장
driver.back()
# 21~30번쨰는 +3
# div.mv_info_area > div.mv_info > h3 > a
if 21 <= j and j <= 30 :
# //*[@id="old_content"]/table/tbody/tr[25]/td[2]/div/a
# //*[@id="old_content"]/table/tbody/tr[25]/td[2]/div/a
print (j)
driver.find_element_by_xpath("//*[@id='old_content']/table/tbody/tr[" + str(j + 3) + "]/td[2]/div/a").click()
soup = BeautifulSoup(driver.page_source, 'html.parser')
Long_movie_infos = soup.select('#content > div.article')
# 장르 '드라마' 에 있는 첫 번째 영화에서 추출해야하는 영화정보 제일 큰 셀렉터
# 출력 양식 설정. 근데 이 포문이 의미가 있을까 ?
for Long_movie_info in Long_movie_infos:
# 21번째부터 영화정보 xpath 값 바뀌는거 확인하기 (이후부터 할 것)
title = str(Long_movie_info.select_one('div.mv_info_area > div.mv_info > h3 > a').text) + ' (' + str(Long_movie_info.select_one('div.mv_info_area > div.mv_info > strong').text) + ')'
#print(title)
poster = str(Long_movie_info.select_one('img').attrs['src']).replace('//', '')
#print(poster)
director = str(Long_movie_info.select_one('div.mv_info_area > div.mv_info > dl > dd:nth-child(4) > p > a').text)
#print(director)
actor = str(Long_movie_info.select_one('div.mv_info_area > div.mv_info > dl > dd:nth-child(6) > p').text)
#print(actor)
summary = ''
#print(summary)
# bold 한 줄거리가 있을경우
if Long_movie_info.select_one('div.section_group.section_group_frst > div:nth-child(1) > div > div.story_area > h5') != None:
summary += str(Long_movie_info.select_one('div.section_group.section_group_frst > div:nth-child(1) > div > div.story_area > h5').text) + '/' +str(Long_movie_info.select_one('div.section_group.section_group_frst > div:nth-child(1) > div > div.story_area > p').text)
elif Long_movie_info.select_one('div.section_group.section_group_frst > div:nth-child(1) > div > div.story_area > p') == None:
summary += 'None'
else:
summary += str(Long_movie_info.select_one('div.section_group.section_group_frst > div:nth-child(1) > div > div.story_area > p').text)
#print(summary)
main_genre = str(Long_movie_info.select_one('div.mv_info_area > div.mv_info > dl > dd:nth-child(2) > p > span:nth-child(1) > a').text)
#print(main_genre)
# 두번째 장르가 존재할경우
if Long_movie_info.select_one('div.mv_info_area > div.mv_info > dl > dd:nth-child(2) > p > span:nth-child(1) > a:nth-child(2)') != None:
second_genre = str(Long_movie_info.select_one('div.mv_info_area > div.mv_info > dl > dd:nth-child(2) > p > span:nth-child(1) > a:nth-child(2)').text)
else:
second_genre = 'NONE'
#print(second_genre)
Long_movie_ex = {
'title': title,
'poster': poster,
'director': director,
'actor': actor,
'summary': summary,
'main_genre': main_genre,
'second_genre': second_genre
}
print(Long_movie_ex)
# 하나의 딕셔너리로 변수를 만들어서, 효율적인 관리 추구
db.Long_movie_list.insert_one(Long_movie_ex)
# DB에 'Long_movie_list' 라는 목록이름으로 저장
driver.back()
# 31~40번째는 +4
if 31 <= j and j <= 40 :
print(j)
driver.find_element_by_xpath("//*[@id='old_content']/table/tbody/tr[" + str(j + 4) + "]/td[2]/div/a").click()
soup = BeautifulSoup(driver.page_source, 'html.parser')
Long_movie_infos = soup.select('#content > div.article')
# 장르 '드라마' 에 있는 첫 번째 영화에서 추출해야하는 영화정보 제일 큰 셀렉터
# 출력 양식 설정. 근데 이 포문이 의미가 있을까 ?
for Long_movie_info in Long_movie_infos:
title = str(Long_movie_info.select_one('div.mv_info_area > div.mv_info > h3 > a').text) + ' (' + str(Long_movie_info.select_one('div.mv_info_area > div.mv_info > strong').text) + ')'
#print(title)
poster = str(Long_movie_info.select_one('img').attrs['src']).replace('//', '')
#print(poster)
director = str(Long_movie_info.select_one('div.mv_info_area > div.mv_info > dl > dd:nth-child(4) > p > a').text)
#print(director)
actor = str(Long_movie_info.select_one('div.mv_info_area > div.mv_info > dl > dd:nth-child(6) > p').text)
#print(actor)
summary = ''
#print(summary)
# bold 한 줄거리가 있을경우
if Long_movie_info.select_one('div.section_group.section_group_frst > div:nth-child(1) > div > div.story_area > h5') != None:
summary += str(Long_movie_info.select_one('div.section_group.section_group_frst > div:nth-child(1) > div > div.story_area > h5').text) + '/' +str(Long_movie_info.select_one('div.section_group.section_group_frst > div:nth-child(1) > div > div.story_area > p').text)
elif Long_movie_info.select_one('div.section_group.section_group_frst > div:nth-child(1) > div > div.story_area > p') == None:
summary += 'None'
else:
summary += str(Long_movie_info.select_one('div.section_group.section_group_frst > div:nth-child(1) > div > div.story_area > p').text)
#print(summary)
main_genre = str(Long_movie_info.select_one('div.mv_info_area > div.mv_info > dl > dd:nth-child(2) > p > span:nth-child(1) > a').text)
#print(main_genre)
# 두번째 장르가 존재할경우
if Long_movie_info.select_one('div.mv_info_area > div.mv_info > dl > dd:nth-child(2) > p > span:nth-child(1) > a:nth-child(2)') != None:
second_genre = str(Long_movie_info.select_one('div.mv_info_area > div.mv_info > dl > dd:nth-child(2) > p > span:nth-child(1) > a:nth-child(2)').text)
else:
second_genre = 'NONE'
#print(second_genre)
Long_movie_ex = {
'title': title,
'poster': poster,
'director': director,
'actor': actor,
'summary': summary,
'main_genre': main_genre,
'second_genre': second_genre
}
print(Long_movie_ex)
# 하나의 딕셔너리로 변수를 만들어서, 효율적인 관리 추구
db.Long_movie_list.insert_one(Long_movie_ex)
# DB에 'Long_movie_list' 라는 목록이름으로 저장
driver.back()
# 41~50번째 +5
if 41 <= j and j <= 51 :
print(j)
#// *[ @ id = "old_content"] / table / tbody / tr[55] / td[2] / div / a
driver.find_element_by_xpath("//*[@id='old_content']/table/tbody/tr[" + str(j + 5) + "]/td[2]/div/a").click()
soup = BeautifulSoup(driver.page_source, 'html.parser')
Long_movie_infos = soup.select('#content > div.article')
# 장르 '드라마' 에 있는 첫 번째 영화에서 추출해야하는 영화정보 제일 큰 셀렉터
# 출력 양식 설정. 근데 이 포문이 의미가 있을까 ?
for Long_movie_info in Long_movie_infos:
title = str(Long_movie_info.select_one('div.mv_info_area > div.mv_info > h3 > a').text) + ' (' + str(Long_movie_info.select_one('div.mv_info_area > div.mv_info > strong').text) + ')'
poster = str(Long_movie_info.select_one('img').attrs['src']).replace('//', '')
director = str(Long_movie_info.select_one('div.mv_info_area > div.mv_info > dl > dd:nth-child(4) > p > a').text)
actor = str(Long_movie_info.select_one('div.mv_info_area > div.mv_info > dl > dd:nth-child(6) > p').text)
summary = ''
# bold 한 줄거리가 있을경우
if Long_movie_info.select_one('div.section_group.section_group_frst > div:nth-child(1) > div > div.story_area > h5') != None:
summary += str(Long_movie_info.select_one('div.section_group.section_group_frst > div:nth-child(1) > div > div.story_area > h5').text) + '/' +str(Long_movie_info.select_one('div.section_group.section_group_frst > div:nth-child(1) > div > div.story_area > p').text)
elif Long_movie_info.select_one('div.section_group.section_group_frst > div:nth-child(1) > div > div.story_area > p') == None:
summary += 'None'
else:
summary += str(Long_movie_info.select_one('div.section_group.section_group_frst > div:nth-child(1) > div > div.story_area > p').text)
main_genre = str(Long_movie_info.select_one('div.mv_info_area > div.mv_info > dl > dd:nth-child(2) > p > span:nth-child(1) > a').text)
# 두번째 장르가 존재할경우
if Long_movie_info.select_one('div.mv_info_area > div.mv_info > dl > dd:nth-child(2) > p > span:nth-child(1) > a:nth-child(2)') != None:
second_genre = str(Long_movie_info.select_one('div.mv_info_area > div.mv_info > dl > dd:nth-child(2) > p > span:nth-child(1) > a:nth-child(2)').text)
else:
second_genre = 'NONE'
Long_movie_ex = {
'title': title,
'poster': poster,
'director': director,
'actor': actor,
'summary': summary,
'main_genre': main_genre,
'second_genre': second_genre
}
print(Long_movie_ex)
# 하나의 딕셔너리로 변수를 만들어서, 효율적인 관리 추구
db.Long_movie_list.insert_one(Long_movie_ex)
# DB에 'Long_movie_list' 라는 목록이름으로 저장
driver.back()
driver.close().jpg)
백엔드 개발자 준비생인 영화광 심리학도입니다. #node.js #Javascript #영화광 #심리학 #백엔드개발자