WMT2024 Research Paper
- ChatGPT MT: Competitive for High- (but not Low-) Resource Languages
ChatGPT 와 같은 LLM 이 다양한 언어들에 대해서는 번역을 어떻게 할까?
많은 연구들이 LLM 의 번역 능력에 대해 연구했지만, 다양한 언어들에 대해 LLM MT 의 능력이 어떤지는 연구가 거의 없었다. 이 연구에서는 Flores-200 데이터를 사용하여 204 개의 언어들에 대해 분석한다. GPT 모델이 high-resource language (HRL) 에 대해서는 traditional MT 를 넘어섰지만 여전히 low-resource language (LRL) 에 대해서는 뒤떨어진다.
Introduction
구글 번역기와 같은 상업 시스템은 low-resource language 를 지원하지만, 다른 시스템들은 다양한 LRL 언어들을 잘 지원하지 않는다. ChatGPT 와 같은 LLM 을 점점 더 많은 end user 들이 사용하고 있다. 그런데 최근 LLM 의 MT 능력이 다양한 언어에 대해서는 평가가 많이 되지 않았다.
따라서 다양한 언어를 사용하는 end user 가 ChatGPT 를 사용할 수 있는지, ChatGPT 와 다른 LLM 들이 믿을만한 translator 로 작동할 수 있는지 의문을 가지게 된다. ChatGPT 와 GPT4 와 같은 LLM 의 training data 와 method 에 대한 정보는 한계가 있기 때문에, 이런 질문들은 실험을 통해 검증해야 한다.
이 연구에서는 (1) Flores-200 으로 204 개의 언어들에 대해 ChatGPT 의 능력을 평가하고, GPT4, Google Translate, NLLB 와 비교한다.
(2) LLM 이 많은 HRL 에 대해서는 traditional MT 모델과 견줄만 한 반면에 LRL 에 대해서는 뒤떨어지는 것을 보여준다.
(3) few-shot prompt를 사용하면 LLM translation 에 marginal benefit 를 주는 것을 보여준다.
(4) MT 시스템들 간의 cost 를 비교해서 보여준다.
Methodology
실험에 사용한 데이터는 Flores-200 으로 devtest (1012) 를 메인 실험에 쓰고, dev (997) 를 follow-up 실험에 사용했다. OpenAI API 로 test 했다. OpenAI GPT 모델이 Flores-200 데이터에 해당하는 Wikipedia 영어 데이터에 학습이 되어있기 때문에, ENG->X 방향으로만 테스트 했다.
Experimental setup
NLLB-MOE 를 baseline 으로 사용한다. ChatGPT MT 는 zero- 그리고 five-shot 로 실험했다. (2.3)
또한 선택한 언어들에 대해 두개의 다른 MT 엔진과 비교했다. (Google Translate API) Google API 가 204 개의 언어를 전부 지원하지 않기 때문에 115 개의 언어에 대한 결과만 볼 수 있다. (GPT-4) GPT4 는 비용이 많이 든다는 이유로 20개의 언어를 선택해서 실험을 진행하고 결과를 보여주었다. chrfGPT−chrfNLLB 값을 정렬해서 10개 언어들 마다 한 언어를 선택해서 총 20개 언어를 골랐다.
zero-shot 과 few-shot 의 프롬프트는 이전 연구 (Gao et al. (2023)) 를 참고해서 아래와 같이 사용했다.

Results and Analysis
1. Traditional MT 모델이 LLM 보다 잘 번역한다.
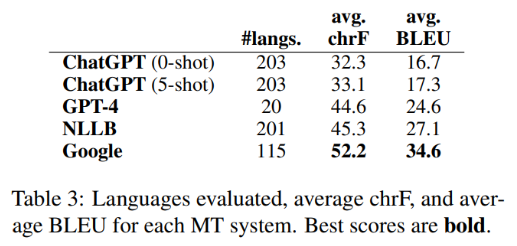
아래 테이블은 각 모델의 chrF 와 BLEU 결과의 평균값을 보여준다. 전반적인 결과는 (1) Google, then (2) NLLB, (3) GPT-4, (4) ChatGPT 순서로 번역을 잘 하는 것으로 보여주었다.
(그런데 모델의 상황에 따라 언어의 수를 다르게 사용해서 평균 값을 구한 결과를 보여주고 있어서, 아래 표가 공평한 결과를 보여주는 지는 잘 모르겠다.)
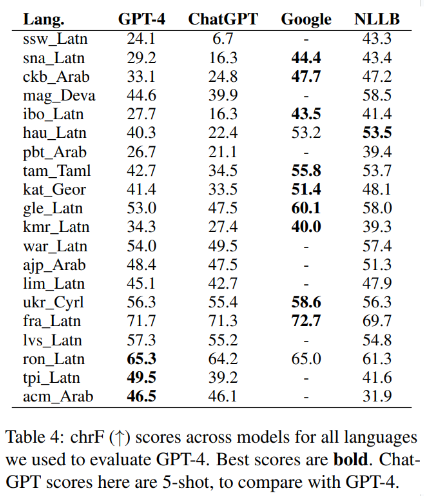
앞서 이야기 했듯 GPT-4 는 20개의 언어에 대해서만 결과를 보여주고 있다. 아래는 그 20개의 언어에 대해 각 모델들의 chrF 결과를 비교해서 보여주는 표이다. 20 개 언어에 대해 GPT-4 가 ChatGPT 를 chrF 평균 6.5 점 뛰어넘었다.
2. ChatGPT 는 Low-resource language 에 대해 성능이 낮다.
ChatGPT 는 HRL 보다 LRL 에서 성능이 더 낮다. ChatGPT chrF score와 NLLB chrF score 성능의 correlation 을 비교해보면, LRL (ρ=0.78) 보다 HRL (ρ=0.85) 에서 더 높은 것을 보여주었다. 이 결과를 통해 ChatGPT 가 NLLB 에 비해 LRL 에서 좀 더 못하는 것을 보여준다.
3. Few-shot prompts 는 marginal 한 성능향상을 보여준다.
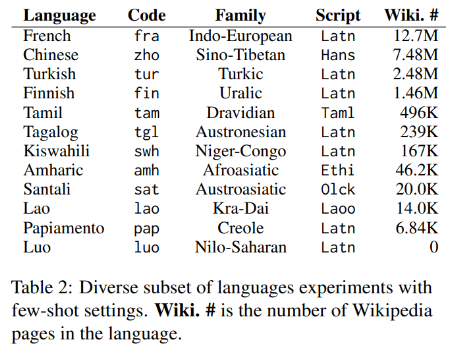
FLORES-200 의 12 language families 중에서 한 언어씩 선택해서, 아래와 같이 4개의 HRL (≥1M Wikipedia pages 6), 4개의 LRL (25K-1M pages), 4개의 extremely LRL (≤25K pages) 를 선택했다.
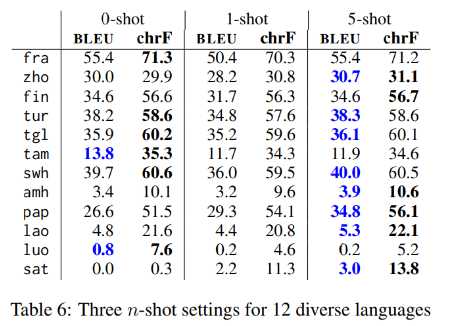
12개의 언어들에 대해, five-shot prompt가 가장 좋은 성능을 보여주었다. 몇가지 LRL에 대해서 ChatGPT가 아예 번역을 못하는 결과도 보여주었다. (Santali 언어는 zero-shot에서 아예 script 를 생성하지 못했다.)
one-shot setting 에서는 결과가 가장 좋지 않았다. 이와 같은 결과는 few-shot 을 사용하는 것이 성능 향상에 있어서 크게 영향을 주지 않는다는 것을 보여주었다.
4. language features 의 중요성
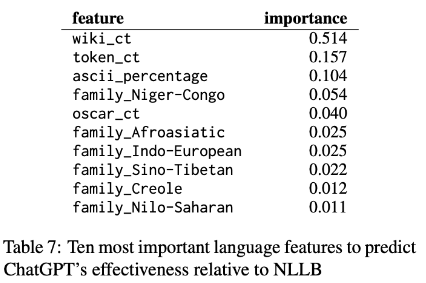
5. Impact of script
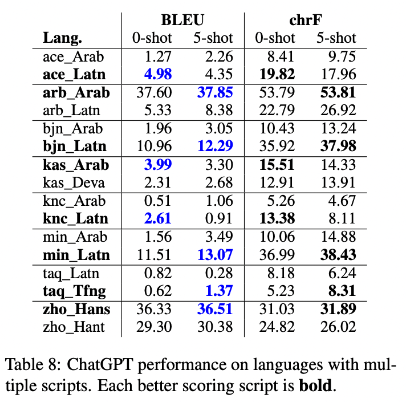
6. LLMs 은 가끔 다른 언어로 번역을 하는 경우가 있다.
LLM 의 성능이 NLLB 에 비해 좋지 않은 것이 target 언어로 번역을 할 때 다른 언어로 번역하기 때문일 수도 있다. 표에서 language ID 의 accuracy 를 확인해보면 ChatGPT 는 72%, 83% 인데 비해 NLLB 는 91% 이다.

7. Cost comparison
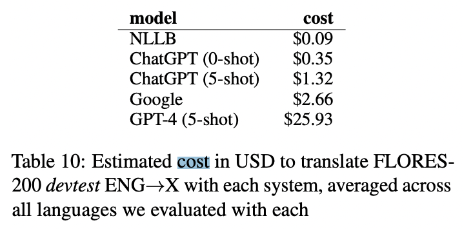
Nathaniel Robinson, Perez Ogayo, David R. Mortensen, and Graham Neubig. 2023. ChatGPT MT: Competitive for High- (but Not Low-) Resource Languages. In Proceedings of the Eighth Conference on Machine Translation, pages 392–418, Singapore. Association for Computational Linguistics.
