fairseq 는 Meta (Facebook) 에서 공개한 오픈 소스 sequence modeling toolkit 으로 번역, 요약, 생성 등의 Language modeling 을 제공한다.
fairseq 를 사용해서 번역하는 방법을 정리한다.
1. Download and Install Fairseq
git clone https://github.com/pytorch/fairseq
cd fairseq
pip install --editable ./2. Preprocess the Dataset
dataset 을 preprocess 할 때 fairsesq command line tool 을 사용하면 편하다. data preprocess 하기 위해서는 fairseq-preprocess 를 사용한다.
이때 꼭 기억할 것! fairseq-preprocess 하기 전에 데이터에 먼저 BPE 를 수행해야 한다. 그렇지 않으면 training 결과 아주 많은 <unk> 토큰이 생긴다.
참고:
https://github.com/facebookresearch/fairseq/issues/2299
https://github.com/facebookresearch/fairseq/issues/2702
import torch
en_lm = torch.hub.load('pytorch/fairseq', 'transformer_lm.wmt19.en', tokenizer='moses', bpe='fastbpe')
file = "data/iwslt2017-en_test.noise"
save = "data/iwslt2017-en_test_tok.noise"
lines = open(file).readlines()
f = open(save, "w")
for line in lines:
f.write(en_lm.bpe.encode(line.strip())+"\n")
f.close()

위에 처럼 데이터가 저장되어있는 상태에서,
# preprocess dataset
fairseq-preprocess \
--source-lang noise \
--target-lang clean \
--trainpref data/iwslt2017-en_train \
--validpref data/iwslt2017-en_valid \
--testpref data/iwslt2017-en_test \
--destdir fairseq_processed이렇게 실행하면 전처리 된 데이터가 --destdir 뒤에 명시한 디렉터리에 아래와 같이 저장된다.
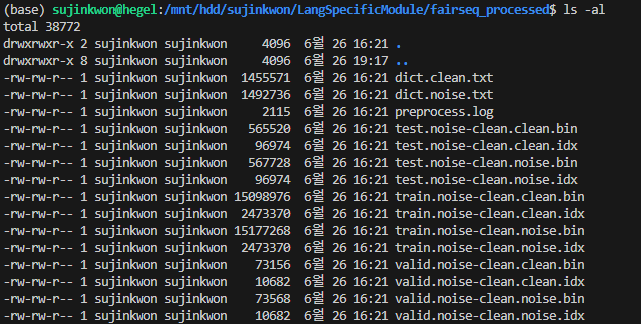
3. Train the Transformer
이제 데이터를 갖고 transformer 모델을 학습해보자. 모델을 학습할 때는 fairseq-train 을 사용할 수 있다.
# train
fairseq-train /mnt/hdd/sujinkwon/LangSpecificModule/fairseq_processed/ \
--task translation \
--arch transformer \
--encoder-layers 6 \
--decoder-layers 6 \
--encoder-embed-dim 512 \
--decoder-embed-dim 512 \
--encoder-ffn-embed-dim 2048 \
--decoder-ffn-embed-dim 2048 \
--encoder-attention-heads 8 \
--decoder-attention-heads 8 \
--optimizer adam \
--max-epoch 10 \
--batch-size 10 \
--save-dir fairseq_train \
--ddp-backend=legacy_ddpError Shooting
train 을 돌리려고 할 때 다음과 같은 에러가 났었다.
RuntimeError: Expected to have finished reduction in the prior iteration before starting a new one. This error indicates that your module has parameters that were not used in producing loss. You can enable unused parameter detection by passing the keyword argument `find_unused_parameters=True` to `torch.nn.parallel.DistributedDataParallel`, and by
making sure all `forward` function outputs participate in calculating loss.
If you already have done the above, then the distributed data parallel module wasn't able to locate the output tensors in the return value of your module's `forward` function. Please include the loss function and the structure of the return value of `forward` of your module when reporting this issue (e.g. list, dict, iterable)find_unused_parameters=True 를 지정해주어도 해결이 되지 않았다. DDP 에서 문제가 있다는 걸 보고 --ddp-backend=legacy_ddp 를 추가해주니 에러가 해결되고 train 이 실행되었다.
메모리 에러 - https://github.com/facebookresearch/fairseq/issues/1372#issuecomment-760745629
4. Translate (Generate)
# test
fairseq-generate fairseq_processed/ \
--path fairseq_train/checkpoint_best.pt \
--source-lang noise \
--target-lang clean \
--task translation \
--batch-size 10 \
--results-path ./train 한 checkpoint 를 사용해서 번역을 한다. 결과 파일이 generate-test.txt 로 지정한 경로에 저장된다.
참고: https://github.com/facebookresearch/fairseq/issues/3000
5. Scoring
앞에서 생성한 generate-test.txt 에서 다음의 커맨트로 각 파일을 추출해낸다.
> grep '^S' generate-test.txt | cut -f2- > gen.out.sys
> grep '^T' generate-test.txt | cut -f2- > gen.out.ref
그리고 처음에 데이터에 bpe 를 수행한 그대로 @@ 가 남아있기 때문에 다음과 같이 디코딩을 해주면 된다.
file = "gen.out.ref"
save = "gen.out.ref.decode"
lines = open(file).readlines()
f = open(save, "w")
for line in lines:
f.write(en_lm.bpe.decode(line.strip())+"\n")
f.close()reference translation 으로 generated translation 의 BLEU score 를 계산한다.
# score
fairseq-score \
--sys gen.out.sys.decode \
--ref gen.out.ref.decode[Reference]
https://towardsdatascience.com/implementing-transformer-for-language-modeling-ba5dd60389a2
https://yscho03.tistory.com/205
https://fairseq.readthedocs.io/en/latest/command_line_tools.html
