1. 웹 클라이언트와 서버
웹 콘텐츠는 웹 서버에 존재한다. 웹 서버는 HTTP 프로토콜로 의사소통하기 때문에 보통 HTTP 서버라고 불린다. 이들 웹 서버는 인터넷의 데이터를 저장하고, HTTP 클라이언트가 요청한 데이터를 제공한다.
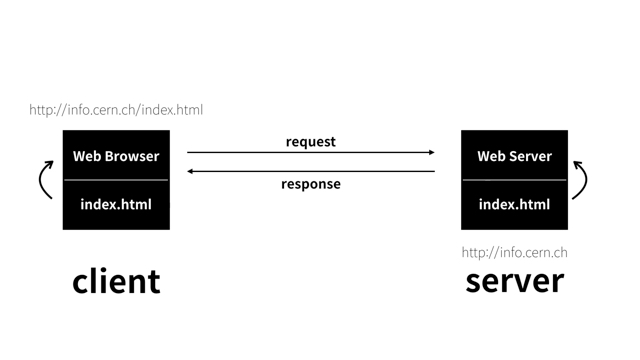
그림에 그려진 대로, 클라이언트는 서버에게 HTTP 요청을 보내고 서버는 요청된 데이터를 HTTP 응답으로 돌려준다. HTTP 클라이언트와 HTTP 서버는 월드 와이드 웹의 기본 요소이다.
예를 들어 https://www.google.co.kr/ 페이지를 열어볼 때, 웹브라우저는 HTTP 요청을 www.google.co.kr/ 서버로 보낸다. 서버는 요청받은 객체(index.html)를 찾고 , 성공했다면 그것의 타입, 길이 등의 정보와 함께 HTTP 응답에 실어서 클라이언트에게 보낸다.
2. 리소스
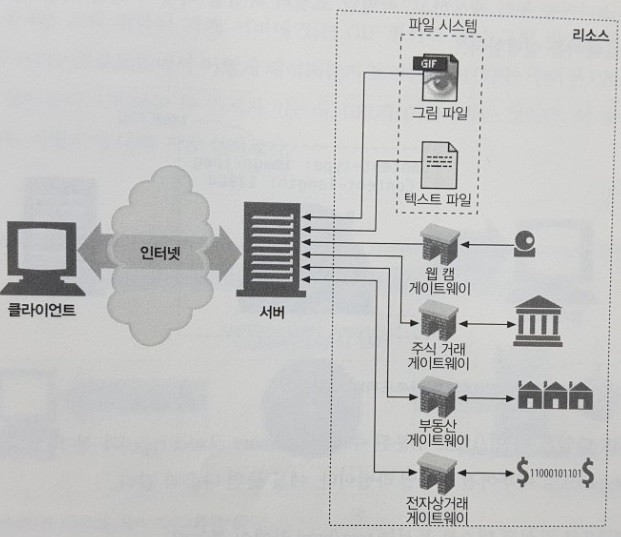
웹 서버는 웹 리소스를 관리하고 제공한다. 웹 리소스는 웹 콘텐츠의 원천이다. 가장 단순한 웹 리소스는 웹 서버 파일 시스템의 정적 파일이다. 정적 파일은 텍스트 파일, HTML 파일, 마이크로소프트 워드 파일, JPEG 이미지 파일, 동영상 파일, 그 외 모든 종류의 파일을 포함한다.
그러나 리소스는 받느시 정적 파일이어야 할 필요는 없다. 리소스는 요청에 따라 콘텐츠를 생산하는 프로그램이 될 수도 있다. 이를 동적 콘텐츠 리소스라고 한다. 사용자와 상호작용을 할 수 있고 주식 거래, 쇼핑몰에서 상품 구매등을 할 수 있게 해줄 수도 있다.
한마디로, 웹에 콘텐츠를 제공하는 모든 것
3. 미디어 타입
인터넷은 수천 가지 데이터 타입을 다루기 때문에, HTTP는 웹에서 전송되는 객체 각각에 신중하게 MIME 타입이라는 데이터 포맷 라벨을 붙인다. MIME(Multipurpose Internet Mail Extensions, 다목적 인터넷 메일 확장)은 원래 각기 다른 전자메일 시스템 사이에서 워낙 잘 동작했기 때문에, HTTP에서도 멀티미디어 콘텐츠를 기술하고 라벨을 붙이기 위해 채택되었다.
웹 서버는 모든 객체를 돌려받을 때, 다룰 수 있는 객체인지 MIME 타입을 통해 확인한다.

MIME 타입은 사선(/)으로 구분된 주 타입(primary object type)과 부 타입(specific subtype)으로 이루어진 문자열 라벨이다.
우리가 개발할 때 사용하는 📖 Content-Type 혹은 Accept-Type 에서 헤더로 지정한다.
4. URI
웹 서버 리소스는 각자 이름을 갖고 있기 때문에, 클라이언트는 관심 있는 리소스를 지목할 수 있다. 서버 리소스 이름은 통합 자원 식별자(uniform resource identifier), 혹은 URI로 불린다. URI는 인터넷의 우편물 주소 같은 것으로, 정보 리소스를 고유하게 식별하고 위치를 지정할 수 있다.
URI에는 두 가지가 있는데, URL과 URN이라는 것이다.
URL
통합 자원 지시자(uniform resource locator, URL)는 리소스 식별자의 가장 흔한 형태다. URL은 특정 서버의 한 리소스에 대한 구체적인 위치를 서술한다. URL은 리소스가 정확히 어디에 있고 어떻게 접근할 수 있는지 분명하게 알려준다.

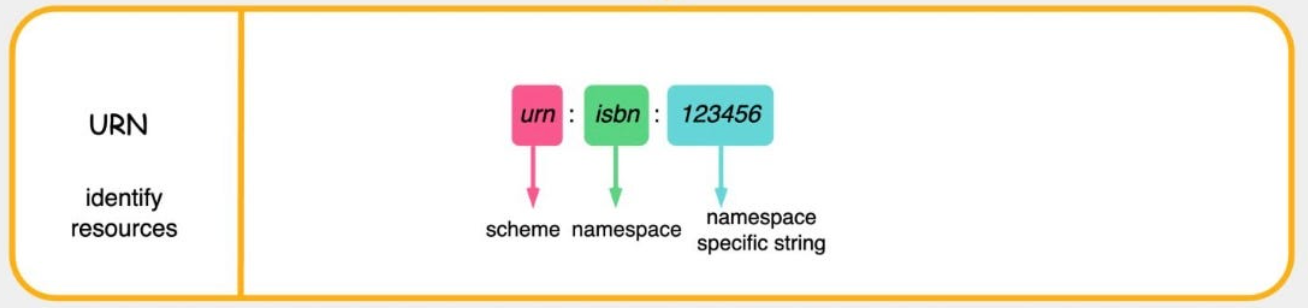
URN
URI의 두 번째 종류는 유니폼 리소스 이름(unifrom resource name, URN)이다. URN은 콘텐츠를 이루는 한 리소스에 대해, 그 리소스의 위치에 영향 받지 않는 유일무이한 이름 역할을 한다.이 위치 독립적인 URN은 리소스를 여기저기로 옮기더라도 문제없이 동작한다.
5. 트랜잭션
HTTP 트랜잭션은 요청 명령과 응답 결과로 구성되어 있다.
트랜잭션은
- 하나의 논리적 기능을 수행하기 위한 작업 단위
- 데이터베이스의 상태를 변경시키기 위해 수행하는 작업 단위
- 데이터베이스의 무결성을 지킬 수 있는 좋은 방법중 하나

A 계좌에서 B 계좌로 송금을 한다고 생각해보자.
먼저 A계좌에서 10만원을 차감한 다음, B계좌에 10만원을 입금하는 절차를 거친다.
만약 A계좌에서 10만원이 차감되고, 오류가 발생한다면? B계좌는 입금받지 못하고 A계좌에서 출금만 되는 아찔한 상황이 일어날 것이다.
트랜잭션을 사용하면 이런 문제를 해결할 수 있다.
시스템 오류를 감지하고, A계좌에서 차감되었던 10만원을 다시 돌려놓는 것이다.
이러한 트랜잭션은 다양한 데이터 항목들을 엑세스하고 갱신하는 프로그램 수행의 단위가 된다.
모든 작업이 정상적으로 성공하는 경우 데이터베이스에 정상 반영하는 것을 Commit이라고 하며,
작업 중 하나라도 실패해서 이전으로 되돌리는 것을 Rollback이라고 한다.
6. 메시지
웹 클라이언트에서 웹 서버로 보낸 HTTP 메시지를 요청 메시지라고 부른다. 서버에서 클라이언트로 가는 메시지는 응답 메시지라고 부른다. 그 외에 다른 종류의 HTTP 메시지는 없다.
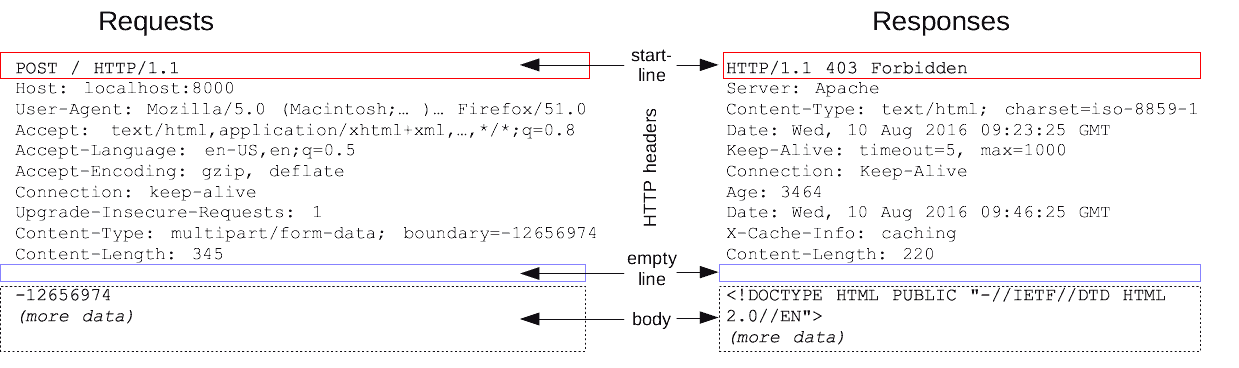
시작줄
메시지의 첫 줄은 시작줄로, 요청이라면 무엇을 해야 하는지 응답이라면 무슨 일이 일어났는지 나타낸다.
헤더
시작줄 다음에는 0개 이상의 헤더 필드가 이어진다. 각 헤더 필드는 쉬운 구문분석을 위해 쌍점(:)으로 구분되어 있는 하나의 이름과 하나의 값으로 구성된다. 헤더 필드를 추가하려면 그저 한 줄은 더하기만 하면 된다. 헤더는 빈 줄로 끝난다.
본문
빈 줄 다음에는 어떤 종류의 데이터든 들어갈 수 있는 메시지 본문이 필요에 따라 올 수 있다. 요청의 본문은 웹 서버로 데이터를 실어 보내며, 응답의 본문은 클라이언트로 데이터를 반환한다. 문자열이며 구조적인 시작줄이나 헤더와 달리, 본문은 임의의 이진 데이터를 포함할 수 있다.(이미지, 비디오, 오디오 트랙, 응용 소프트웨어). 물론 본문은 텍스트도 포함할 수 있다.
7. TCP 커넥션
이제 HTTP 메시지가 어떻게 생겼는지 대략 살펴보았으니, 어떻게 메시지가 TCP(Transmission Control Protocol, 전송 제어 프로토콜)커넥션을 통해 한 곳에서 다른 곳으로 옮겨가는지 알아보자
TCP/IP
HTTP는 애플리케이션 계층 프로토콜이다. HTTP는 네트워크 통신의 핵심적인 세부사항에 대해서 신경 쓰지 않는다. 대신 대중적이고 신뢰성 있는 인터넷 전송 프로토콜인 TCP/IP에게 맡긴다. TCP는 다음을 제공한다.
- 오류 없는 데이터 전송
- 순서에 맞는 전달(데이터는 언제나 보낸 순서대로 도착한다)
- 조각나지 않는 데이터 스트림(언제든 어떤 크기로든 보낼 수 있다)

TCP 커넥션이 맺어지면, 클라이언트와 서버 컴퓨터 간에 교환되는 메시지가 없어지거나, 손상되거나, 순서가 뒤바뀌어 수신되는 일은 결코 없다.
접속, IP 주소 그리고 포트번호
HTTP 클라이언트가 서버에 메시지를 전송할 수 있게 되기 전에, 인터넷 프로토콜(Internet protocol, IP) 주소와 포트번호를 사용해 클라이언트와 서버 사이에 TCP/IP 커넥션을 맺어야 한다.
HTTP 서버의 IP 주소와 포트번호를 어떻게 알아낼 수 있을까? URL을 이용하면 된다.
앞에서 URL이란 리소스에 대한 주소하고 언습했었다.
따라서 당연하게도 URL은 그 리소스를 가지고 있는 장비에 대한 IP 주소를 알려줄 수 있다.
그림은 웹브라우저가 어떻게 HTTP를 이용해서 멀리 떨어진 곳에 있는 서버의 단순한 HTML리소스를 사용자에게 보여주는지 묘사하고 있다.
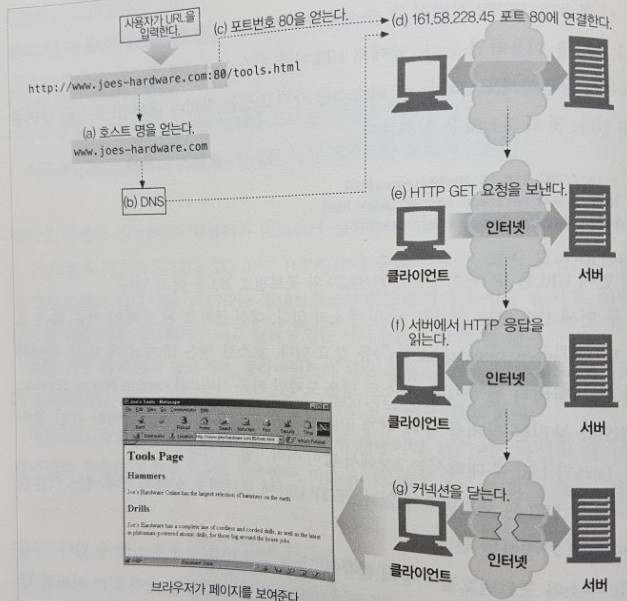
(a) 웹브라우저는 서버의 URL에서 호스트 명을 추출한다.
(b) 웹브라우저는 서버의 호스트 명을 IP로 변환한다.
(c) 웹브라우저는 URL에서 포트번호(있다면)를 추출한다.
(d) 웹브라우저는 웹 서버와 TCP 커넥션을 맺는다.
(e) 웹브라우저는 서버에 HTTP 요청을 보낸다.
(f) 서버는 웹브라우저에 HTTP 응답을 돌려준다.
(g) 커넥션이 닫히면, 웹브라우저는 문서를 보여준다.
