평균값(Mean)
모든 데이터들의 합 / 데이터 개수
중간값(Median)
데이터셋에서 딱 중간에 있는 값
정렬된 데이터에서
데이터 개수 홀수일때 -> 가운데
데이터 개수 짝수일때 -> 가운데 2개 값의 평균
평균값 vs 중간값
데이터 분석에서는 중간값이 평균값보다 유용한 경우가 있음
(평균값은 잘못된 데이터 한 두개로 이상해질 수 있지만 중간값은 영향을 덜 받기 때문)
Q1(데이터의 25% 지점), Q3(데이터의 75% 지점) 구하기
특정 퍼센트 지점의 인덱스를 구하려면 데이터의 개수에서 1을 뺀 뒤, 원하는 숫자를 곱하면 된다.
ex) 데이터 개수가 8개이면, (8-1)*0.25 해서 1.75라는 결과를 얻을 수 있음.
데이터 개수에서 1을 빼는 것은 파이썬 인덱스가 0부터 시작하기 때문이다.
- 인덱스 1.75의 의미 :

이상값 구하기
박스 플롯에서 박스와 위스커 바깥에 있는 점들을 이상점이라고 부른다.
이상점을 구분하기 위한 명확한 기준이 몇 가지 있는데 대표적인 것 중 하나로 Q1,Q3를 활용하는 방식이 있다.
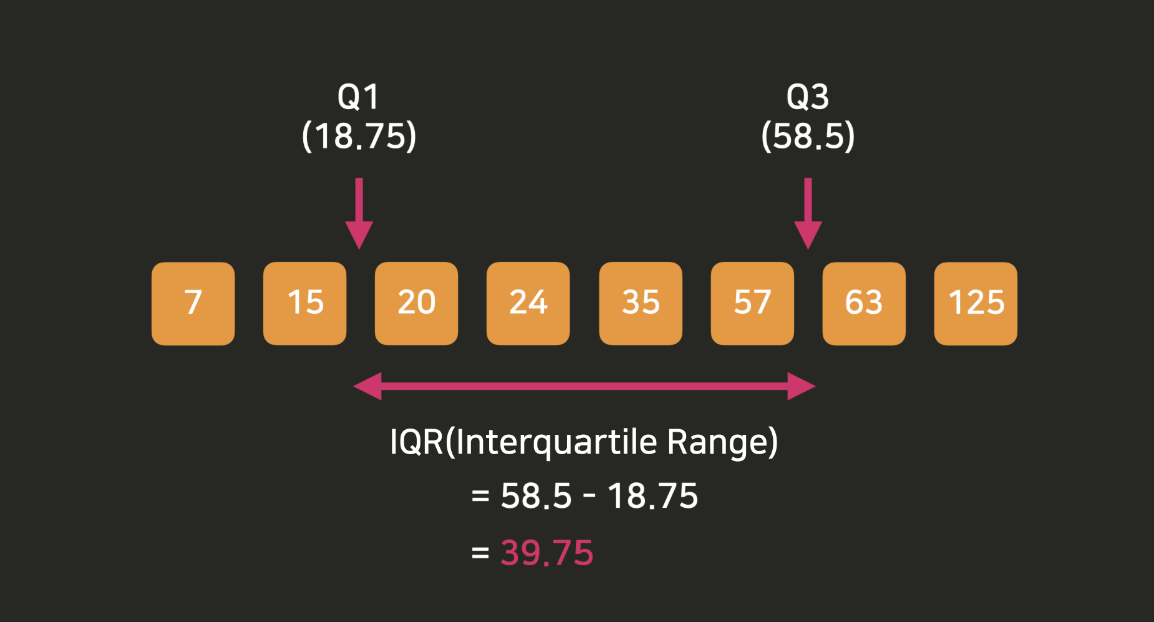
Q3에서 Q1을 뺀 값을 IQR(Interquartile Range)라고 부른다.
보통 Q1 지점에서 아래로 1.5 IQR 더 떨어져 있거나, Q3 지점에서 위로 1.5 IQR 더 떨어져 있는 값은 이상값이라고 판단한다.
상관 계수(Correlation Coefficient)
상관 계수에는 여러 가지 종류가 있는데 그중 가장 널리 쓰이는 것이 피어슨 상관 계수이다.
피어슨(Pearson) 상관계수 (-1에서 1까지의 값을 가짐)
- 0이면 x와 y는 연관이 없음
- 값이 0보다 클 때 1에 가까워질수록 연관성이 크다 (x가 커질수록 y가 커짐)
- 1이면 x와 y는 확실한 연관성
- 값이 0보다 작을 때 -1에 가까워질수록 연관성이 크다(x가 커질수록 y가 작아짐)
- -1이면 x와 y는 확실한 반대 관계
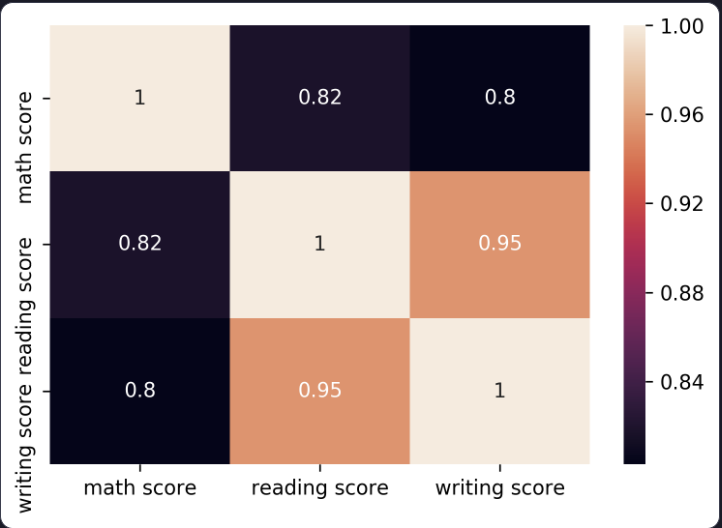
상관 계수 시각화
히트맵은 상관 계수를 시각화하는 대표적인 방법이다.
Seaborn의 heatmap 메소드 이용
%matplotlib inline
import pandas as pd
import seaborn as sns
df = pd.read_csv('data/exam.csv')
sns.heatmap(df.corr())

색이 밝을수록 상관 계수가 더 높다는 의미
annot = True 옵션을 추가해주면, 색상 뿐 아니라 숫자도 함께 보여줌.
sns.heatmap(df.corr(), annot = True)