[Story Generation] Generating Biographies on Wikipedia: The Impact of Gender Bias on the Retrieval-Based Generation of Women Biographies 리뷰
0
https://aclanthology.org/2022.acl-long.586.pdf
3줄 요약
- Wikipedia Article 같은 Factual long-form text를 generation 하려 한다! (Biography를 중점적으로...)
- 1) 정보 검색을 통해 웹에서 관련 info를 식별하고, 2) 이를 바탕으로 section by section biography 생성하겠어!
- 1)의 정보 검색이 output text에 어떤 영향을 미치는지 평가하기 위해 1,500개의 biographies about women(일반적으로 웹 검색 정보가 적음) 데이터를 생성했다!
- biographies about women 데이터와 general biographies의 성능을 비교하겠다!!
Wikipedia Biography???
https://en.wikipedia.org/wiki/Marie_Curie
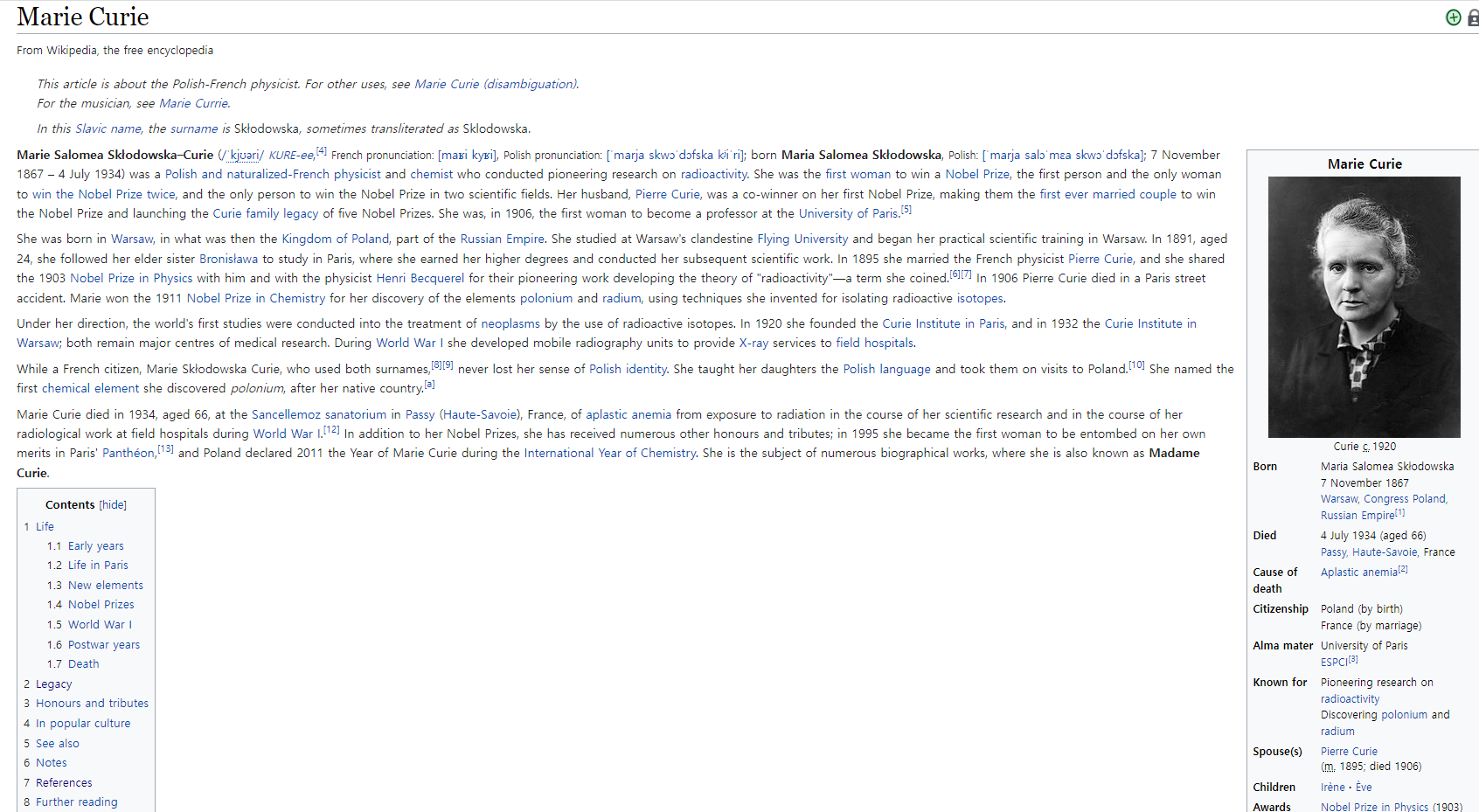
Introduction
- Wikipedia는 전세계에 지식을 전파하는 주요 사이트 중 하나!!
- 그러나 Wikipedia의 지식은 중립적이지 않고 다양하게 bias 되어 있다
- Marit Hinnosaar. 2019. Gender inequality in new media: Evidence from wikipedia. Journal of Economic Behavior & Organization, 163:262–276.
- Katja Geertruida Schmahl, et al. 2020. Is wikipedia succeeding in reducing gender bias? assessing changes in gender bias in wikipedia using word embeddings. In Proceedings of the Fourth Workshop on Natural Language Processing and Computational Social Science, pages 94–103.
- 그러나 Wikipedia의 지식은 중립적이지 않고 다양하게 bias 되어 있다
- 특히 biographies 부분에서 압도적으로 남성에 대해 주로 쓰여져 있다는 연구 결과
- Wikipedia Women in Red 같은 프로젝트로 성별 격차를 줄이는 기사 작성을 고려
- 그러나 여전히 인간 contributors로 인해 작성되고 편집된 상태로 남아있다
- 또한 Wikipedia 기사의 자동 생성은 여전히 어려움 (Liu et al., 2018)
- 따라서 우리는 biography domain에 초점을 맞춰 전체 Wikiepdia 기사를 영어로 작성할 수 있는 시스템 제작
- Major Challenges
- 기본적으로 Long-form generation task다
- Factuality 문제 -> article은 사실적으로 정확해야 한다
- Wikipedia 기사는 웹에서 흔히 볼 수 있는 자료를 사용하여 작성되므로, 기본적으로 웹 검색으로 정보를 찾고 수집해야함
- 생성 단계
- 웹 검색 결과가 주어지면, pre-trained generation architecture를 사용해 정보를 식별하고 biography 작성
- TransformerXL과 유사한 caching mechanism을 사용해 섹션 별로 섹션 생성 -> 이전 섹션 참조 후 더 큰 document-level content 생성
- 각 섹션 뒤에 검색된 웹 기반 Citation 추가
- Major Challenges
- Automatic metric을 통해 quality of generation을 quantify한다
- 또한 검색에 대한 방법의 의존성 연구 -> 이를 평가하는 dataset 설계
- 1,527개의 Wikipedia biographies about women
- 이를 활용해 검색이 어려울 때의 모델 quality와 검색이 정확할 때의 모델 quality 간의 격차 분석
- Factuality 평가를 위해 대규모 human evaluation 수행
Task
Input
- a person's name
- one or more occupation(s)
- CommonCrawl as a source of evidence
- (Section Header)
Output
- generated a Wikipedia biography
- 각 섹션을 적절한 참고 문헌과 연결
- Section Header를 추가 정보로 사용해 section별 biography section 생성
- toplevel 이라는 특수 section header가 기사의 시작으로 사용됨
- 후속 header는 다음 section의 입력으로 각 section의 끝에서 자동 생성됨
- 각 Section의 Input: name, occupation, section header, CommonCrawl(Web evidence)
- 각 섹션을 적절한 참고 문헌과 연결
Method
- Wikipedia biographies는 introductory paragraph로 시작하고 다양한 subsection이 뒤따른다
- 아래 그림과 같이 section by section으로 biograph 생성
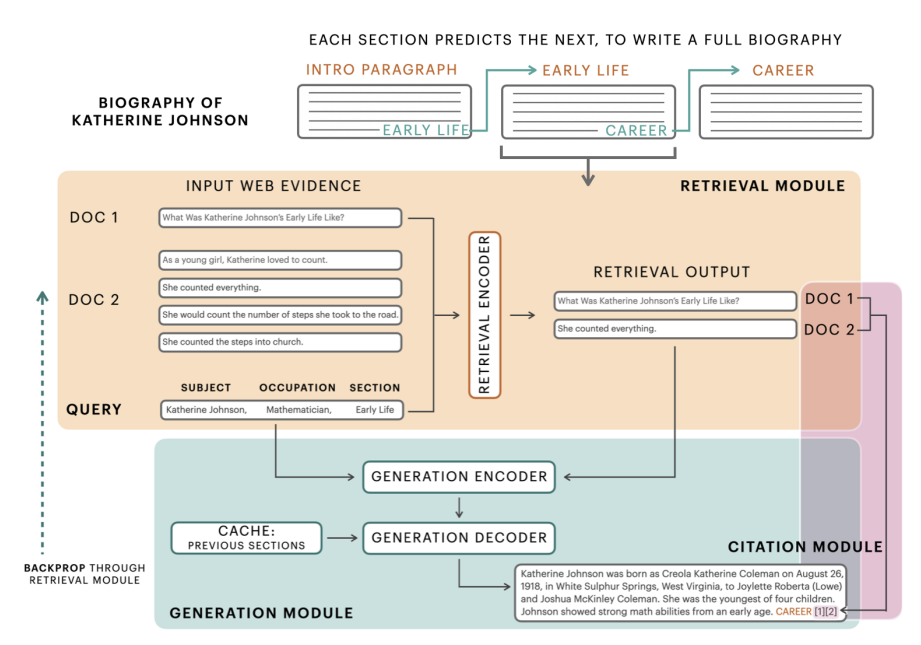
- subject, occupation, section heading이 주어지면, 모델은 먼저 web search에서 triplet 모듈을 이용해 relevant evidence 식별
- Caching mechanism을 이용해 이전 section에 접근할 수 있는 Seq2Seq 모델을 사용해, 해당 evidence를 조건으로 Section 생성
- Wikipedia article (citation module)을 모방해 사용된 evidence 문서를 표시하고 이를 인용으로 출력
Retrieval Module
- 쿼리 Q와 이 쿼리를 기반으로 웹에서 검색된 웹문서 D가 주어지면, Retrieval module은 주어진 Q와 가장 관련 있는 D의 subset 검색
- Challenge! -> 유용한 정보를 최대한 많이 선별하는 것!
Query
- 3부분으로 구성
- Biography를 생성할 사람의 Name
- Multiple Occupations
- Section heading
- 2와 3을 이용하면 모호한 Name을 더 좁혀서 적절한 정보를 검색할 수 있다
Documents
- 쿼리 Q는 Search engine을 통과함으로써 검색 후보 문서 D 생성
- D는 오직 text로만 표시, text가 아닌 정보 삭제
Retrieval
- D의 관련 subset을 검색하기 위해 D의 각 문장을 RoBERTa 기반 인코딩
- name, occupation, section header 또한 인코딩
- 현재 인코딩된 쿼리 Q가 어떤 문서와 가장 연관이 있는지 식별하기 위한 dot product 연산 (Karpukhin et al., 2020)
- 그 후 가장 관련성 높은 상위 k개의 문장 도출
Generation Module
- Transformerbased Sequece-to-Secuence model initialized with BART-Large(Lewis et al., 2019)
- input: Name, Occupation, Section header, Retrived evidence
- Decoder는 input information을 바탕으로 Section 생성
- Problem!
- 한 Section이 독립적으로 생성된다면 생성된 section 간에 중복이 발생할 수 있다!
- TransformerXL의 cache mechanism을 사용해 이전 section을 참조하는 mechanism 장착 (Dai et al., 2019)
- 모든 레이어에서 이전 section의 hidden state를 확인하고 이를 메모리로 사용하여 현재 section 생성
Citation Module
- 사용된 정보 인용
- original document를 추적해 각 section의 끝에 인용 작성
Bringing it All Together
- 각 section에 따른 Introductory paragraph 생성 필요
- toplevel이라는 section heading으로 introductory paragraph가 표시된다
- 앞선 작업이 완료 되면 모델은 다음 section의 section heading 생성
생성 예시

Creating an Evaluation Dataset
- 좋은 biography를 생성하기 위해서는 충분한 relavent information에 접근해야 한다!
- 정확한 retrieval이 generation quality에 미치는 영향을 연구하기 위해 이 문제를 내세우는 특정 평가 데이터셋을 설계하겠다!
- 여성의 biography로만 구성된 새로운 평가 데이터셋
- candidate biography, occupation에 대한 retrieve information, web search를 이용한 web source를 수집
- 총 1,527개의 biography

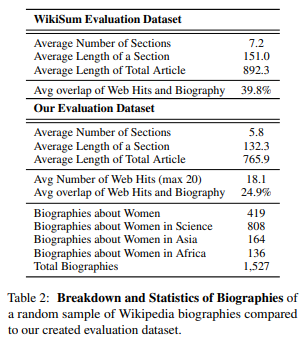
Identifying Biographical Subjects
- Wikipedia에서 다양한 notable women 검색
- Biographies about Women
- Biographies about Women in Science
- Biographies about Women in Asia
- Biographies about Women in Africa
- 총 1,527개의 biographies 수집
- 이렇게 4가지로 나눈 이유에 대해서 자세히 설명하고 있지 않음...
Biography Text and Occupation
- Wikidata API를 사용해 직업 검색
- 평균적으로 article은 130 단어가 포함된 약 6개의 section으로 구성됨
- 일반적으로 writer, teacher, doctor가 표현되지만 평균 2개의 직업을 가진 약 500가지 직업이 포함되어 있음
Retrieving Web Evidence
- Web source 수집
- subject name과 occupation을 기반으로 CommonCrawl를 쿼리한 후 상위 20개의 검색 결과 반환
- Wikipedia와 관련된 링크는 제외
- 평균적으로 약 18개의 정보 쿼리 가능
Experimental Details
Training Data
- WikiSum dataset (Liu et al., 2018) paried with web references
- 직업을 검색하고 이름을 인식하는 방식으로 biography만 추출
- 총 677,085개의 biograpies
- WikiSum dataset based on English Wikipedia and suitable for a task of multi-document abstractive summarization.
- Input : a Wikipedia topic (title of article) and a collection of non-Wikipedia reference documents
- Output : Wikipedia article text
Evaluation Data
- WikiSum dataset (Liu et al., 2018) filtered to biographies
- 앞서 제작한 women 데이터도 evaluation에 사용
Baseline
- BART model and finetune on the Biography subset of the WikiSum data
- Section 별로 내용 생성하도록 훈련
- retrieval module, caching mechanism, citation module을 사용하지 않는다
Automatic Evaluation
- 3가지 automatic metrics 사용
- 생성된 text와 Wikipedia text 간의 ROUGE-L을 통한 유사성 평가
- 문장 유사성 평가 : MNLI dataset에서 pre-trained, fined-tuned된 모델을 사용해 생성된 text와 Wikipedia text의 문장이 의미적으로 동일한지 계산 -> 동일한 비율 계산
- Entity linking 기반 평가 : BERT 기반 entity linking system인 BLINK를 사용해 Entity 추출 -> 감지된 named entity의 비율 계산
- Entity Linking: 문장에서 개체의 mention을 확인한 후 지식베이스에 연결하는 NLP Task
- Entity Linking: 문장에서 개체의 mention을 확인한 후 지식베이스에 연결하는 NLP Task
Human Evaluation
- 해당 section의 정보가 wikipedia text 또는 web document와 관련하여 사실인지 평가
- reference section 중 generated section에 얼마나 많은 정보가 포함되어 있는지
- generated section의 정보가 web evidence를 기반으로 얼마나 검증 가능한가?
- 생성된 문장 정보가 reference section에 존재하는지 (ground truth)
- 생성된 문장의 정보가 cited document에 존재하는지 (web evidence)
- reference sentence에 있는 정보가 생성된 section 내에 존재하는지
Results and Discussion
- 생성 예시

Quality of Generated Biographies (WikiSum)
Automatic Evaluation
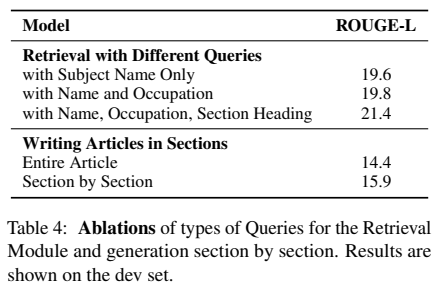
- Retrieval Module 추가하면 성능 상승
- Caching Mechanism 추가하면 더 상승
- Biography를 작성하기 위해서는 가장 관련성이 높은 정보를 검색하는 것이 중요하다!

- Biography를 작성하기 위해서는 가장 관련성이 높은 정보를 검색하는 것이 중요하다!
- Name only
- Name + Occupation
- Name + Occupation + Section Heading
- 풍부한 Query를 사용하는 것이 검색 품질을 거의 2 ROUGE-L 만큼 향상시킨다!
- 명확성 개선, 동음이의어가 아닌 entity와 관련된 증거를 검색하는 것에 도움이 됨
- 풍부한 Query를 사용하는 것이 검색 품질을 거의 2 ROUGE-L 만큼 향상시킨다!
- Section 별 생성과 전체 Article 생성의 차이
- Retrieval mechanism이 Section 정보에 초점을 맞춰 더 좋은 성능을 낸다!
Human Evaluation
- 생성된 텍스트 중 68%가 reference에 없다
- Reference text에 있는 정보의 71%는 생성된 텍스트에 없다
- 그러나 추가된 정보의 17%는 Web evidence를 바탕으로 생성됨 -> 유효한 biography 정보임
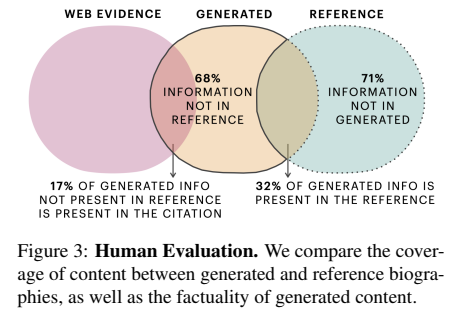
- 생성된 텍스트외 reference text 사이에 정보가 많이 중첩되지 않은 이유
- Web Source에서 reference text가 검색되지 않을 수도 있다
- Annotator는 문장을 비교해야하며, 문장은 부분적인 정보를 포함한다
- Person was born in Chicago in 1968 (generated)
- Person was born in Chicago (reference)
- Reference에 없는 정보이므로 일치하지 않는다고 annotation
- 결론 : Web Evidence가 부족하며, 동일한 핵심 지식을 포함하는지 평가하려는 방식이 어렵다
Performance with Unreliable Retrieval (WikiSum + Women dataset)
- 좋은 biography를 작성하기에 검색 결과가 너무 적거나 노이즈만 포함되는 경우 문제가 생길 수 있다!
- 이에 대한 완화 방법
Evidence Gap
- WikiSum과 비교하여 Women의 데이터셋은 Web hit와 unigram overlap이 낮다
- 전반적으로 WikiSum에서 생성된 biography의 품질이 더 높다
- 이는 Women in Asia와 Women in Africa에서 두드러짐
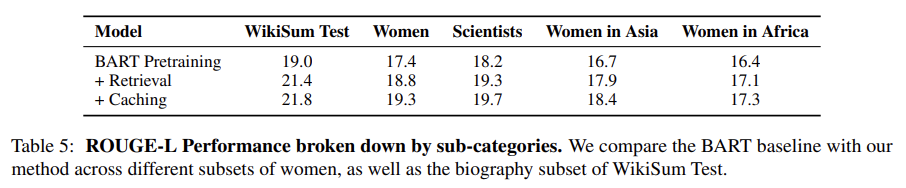
Reducing the Dependency on Retrieval
- retrieval information을 쉽게 사용할 수 있는 train 데이터와, information이 누락된 women 데이터셋 사이에 차이가 있다
- 이를 완화하기 위해 Women 데이터로 fine-tuned
- 성능 향상되긴 했는데 엄청 큰 성능 개선이 아님
- 어찌 됐든 정말로 관련성 있는 정보만 수집하는 것이 필요하다!
- Future work로 가장 관련성이 높은 문서에 접근하는 방식을 연구하려 한다
- 성능 향상되긴 했는데 엄청 큰 성능 개선이 아님
- 이를 완화하기 위해 Women 데이터로 fine-tuned

요약...
- Factual long-form text (ex. Wikipedia articles)
- how to gather relevant evidence
- how to structure information into well-formed text
- how to ensure that the generated text is factually correct
- 해당 문제를 해결하기 위해 English text model 개발
- Retrieval mechanism을 사용해 웹에서 relevent information 식별
- Pre-trained 된 encoder와 decoder를 이용해 section by section long-form biographies 생성
- Web evidence가 output text에 미치는 영향을 평가하기 위해 biographies about women과 biographies generally 생성의 성능을 비교했다 (일반적으로 biographies about women은 웹에서 사용할 수 있는 정보가 적음)
- 1,500개의 biographies about women dataset을 제작
- 데이터의 차이가 generation에 미치는 영향을 이해하기 위해 생성된 텍스트 분석
- Automatic metrics & Human evaluation
- Factuality, Fluency and Quality of the generated texts
내 생각...
- Bias 관련 연구가 이렇게도 진행될 수 있구나!
- 이건 Article generation인데 Story Generation 쪽이 더 재밌는 것 같다!! formal한 text 노잼
- 중간중간 설명이 생략되어 있는 부분이 있어서 좀 아쉬웠다

wtf