멀티스레드란?
프로세스 : 운영체제로부터 자원을 할당받는 범위, 실행될 때 프로세서, 필요한 저장 공간, 데이터, 메모리 영역 등을 할당 받는다
스레드 : 프로세스가 할당한 자원을 이용한 실행의 범위, Stack(임시저장공간)을 제외하고 나머지 메모리영역은 프로세스 내의 다른 스레드와 공유
멀티 스레드란? 한 프로세스가 두 가지 이상의 작업을 수행 <=> 1 프로세스 N 코드 실행 흐름
멀티 프로세스 vs 멀티 스레드
- 멀티 프로세스 : 한번에 여러 프로그램(프로세스)을 같이 돌리는 것
각각 프로세스는 각자의 메모리를 가지고 독립적으로 운용됨
하나의 프로세스가 오류가 나더라도 다른 프로세스에 영향이 가지 않는다
ex) 엑셀파일과 워드파일을 동시에 사용하던 중 엑셀에서 오류가 발생 but, 워드에는 아무런 문제가 없다 - 멀티 스레드 : 한 프로그램 안에서 여러 작업(스레드)을 한번에 하는 것, 장점은 공유하고 있는 메모리 자원을 아낄 수 있고 통신의 부담이 적다
하나의 스레드가 예외를 발생시키면 프로세스 자체가 종료될 수도 있어 다른 스레드에게 영향을 미친다
ex) 엑셀 내에서 한번에 여러가지 일을 같이 하고 있음, 파일을 전송하던 중 오류가 발생하면 엑셀 전체가 꺼지고 모든 작업이 중지됨
따라서, 멀티 스레드는 예외 처리가 무엇보다 중요함
멀티 스레드의 쓰임새
- 대용량 데이터의 처리 시간을 줄이기 위해 데이터를 분할 후 병렬로 처리
- UI를 가지고 있는 애플리케이션에서 네트워크 통신을 위해 사용
- 다수 클라이언트의 요청을 처리하는 서버를 개발할 때 사용
멀티 스레드 활용
메인 스레드 : main() 메소드를 의미, 메인 스레드는 필요에 따라 작업 스레드들을 만들어서 병렬로 코드 실행 즉, 멀티 스레드를 이용해 멀티 태스킹 수행
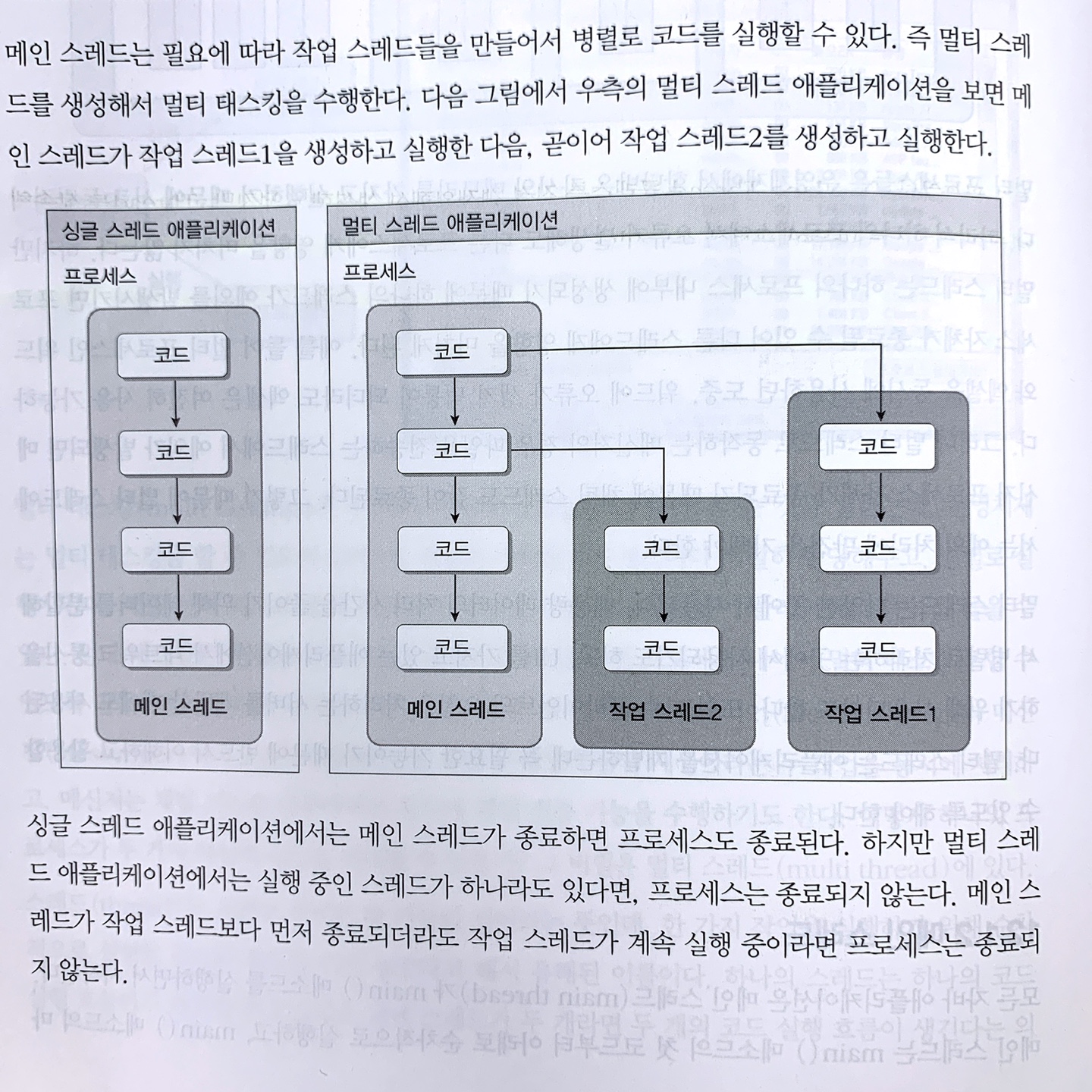
메인 작업 이외에 추가적인 병렬 작업의 수만큼 스레드를 생성하면 됨
스레드도 객체로 생성되기 때문에 클래스가 필요
스레드의 구현 클래스는 run() 메소드를 재정의해서 작업 스레드가 실행할 코드를 작성하면 된다
스레드의 이름
- thread.setName() : 스레드의 이름 지정하기
- thread.getName() : 스레드의 이름 불러오기
- thread.currentThread() : 스레드의 객체 가져오기 (참조)
- 순서 currentThread -> setName -> getName
스레드에도 이름 필요 => 디버깅할 때 어떤 스레드가 어떤 작업을 하는 지 조사할 목적으로 사용
동시성 : 멀티 작업을 위해 하나의 코어에서 멀티 스레드가 번갈아 가면서 실행하는 성질
병렬성 : 멀티 작업을 위해 멀티 코어에서 개별 스레드를 동시에 실행하는 성질
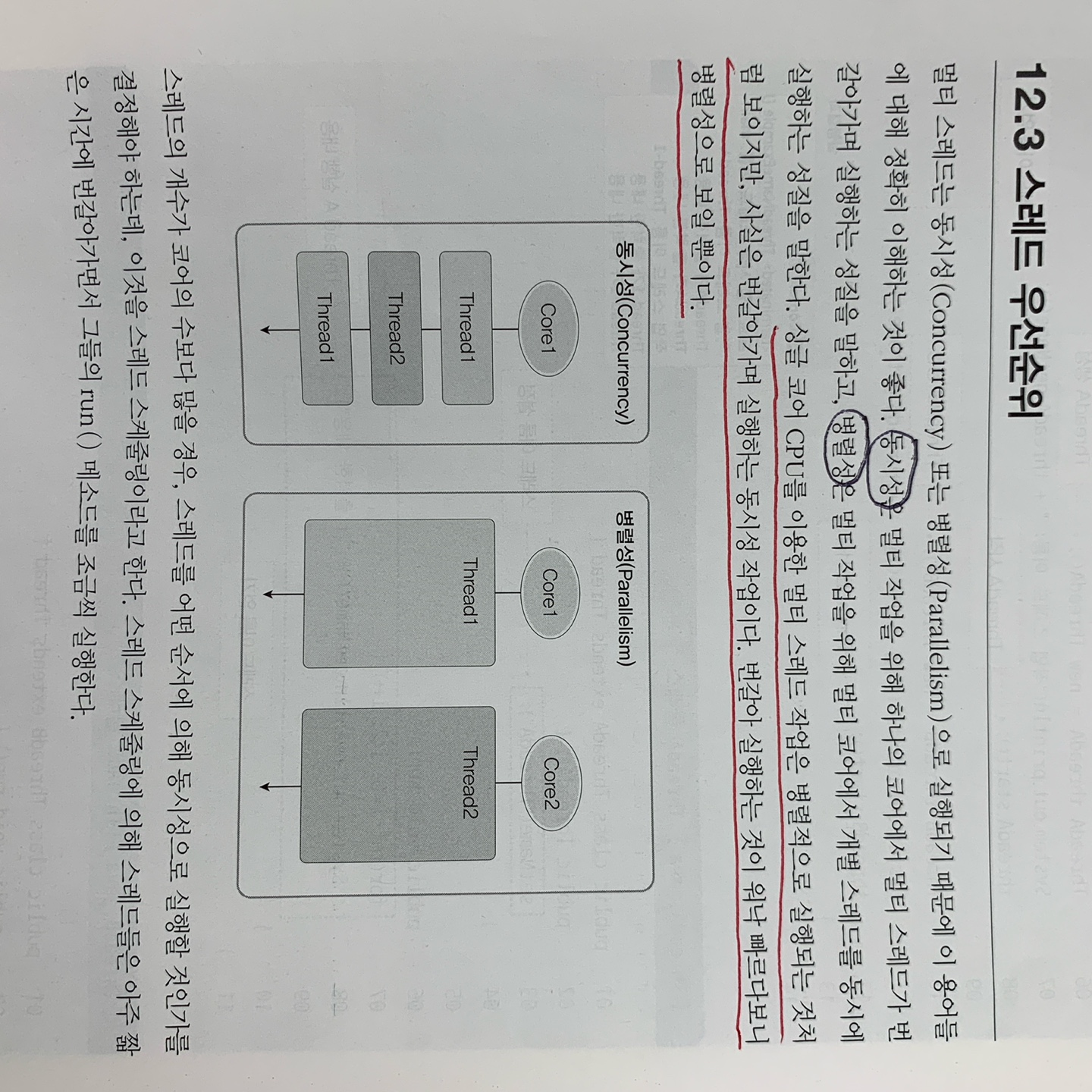
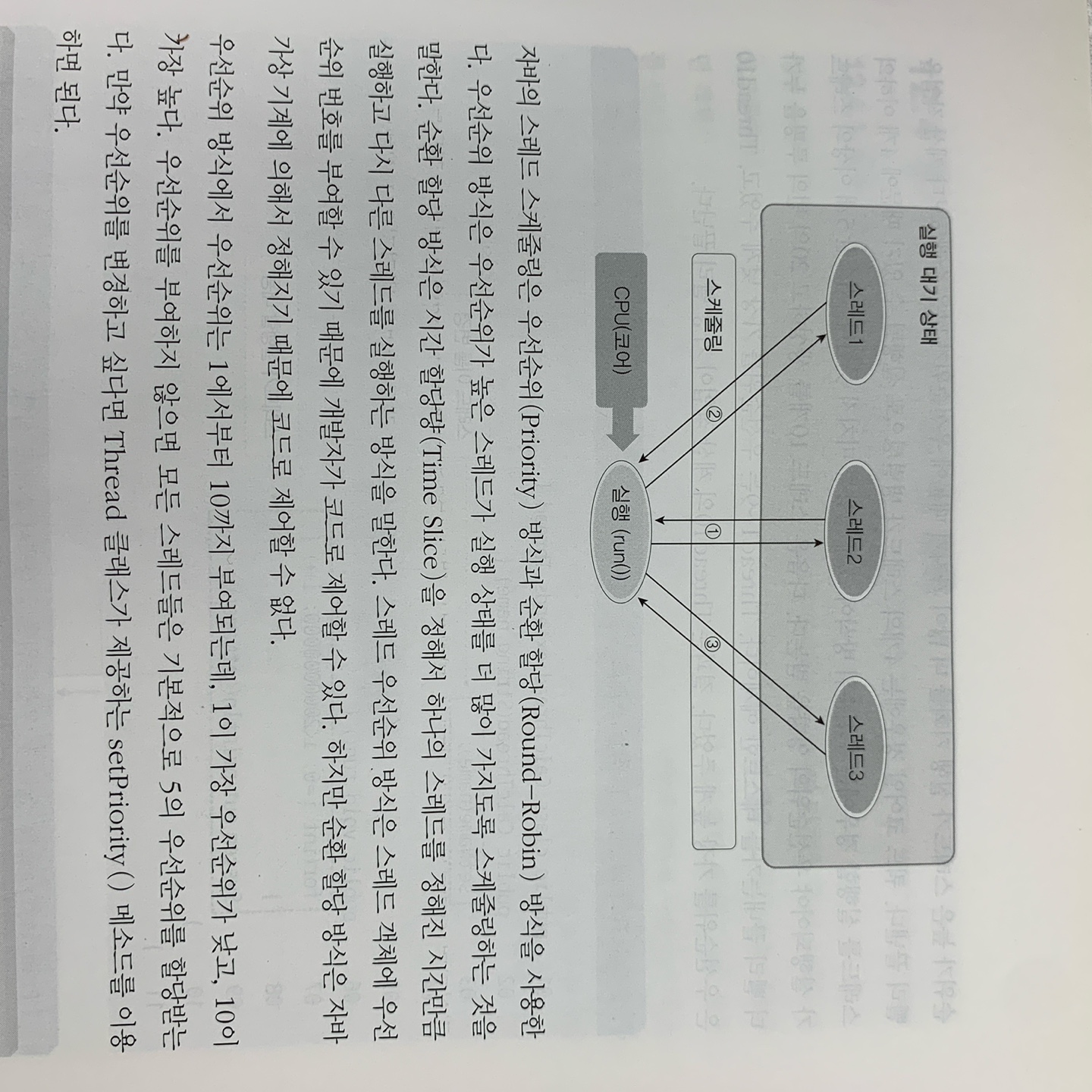
스레드 스케줄링
- 우선순위 방식 : 우선순위가 높은 스레드가 실행 상태를 더 많이 가져가도록 스케줄링, 스레드 객체에 우선순위 번호 부여
- 순환 할당 방식 : 시간 할당량을 정해서 하나의 스레드를 정해진 시간만큼 실행하고 다른 스레드를 실행하는 방식, 자바 가상 기계에 의해서 정해지기 때문에 제어할 수 없다
멀티 스레드 프로그램에서 스레드들이 객체를 공유할 일이 많다
이 경우 스레드 A를 사용하던 객체가 스레드 B에 의해 상태가 변경 될 수 있기 때문에 스레드 A가 의도했던 것과는 다른 결과를 산출할 수 있다
스레드가 사용 중인 객체를 다른 스레드가 변경할 수 없도록 하려면 스레드 작업이 끝날 때 까지 객체에 잠금을 걸어서 다른 스레드가 사용할 수 없게 해야한다

스레드 상태 : 스레드는 4가지의 상태로 나타난다
- 객체 생성 : 스레드 객체가 생성, 아직 start() 메소드가 호출되지 않음 (열거상수 = NEW)
- 실행 대기 : 실행 상태로 언제든 갈 수 있는 상태 (열거상수 = RUNNABLE)
- 일시 정지 : 3가지 형태가 있는데 다른 스레드가 통지할 때까지 기다리는 형태, 주어진 시간 동안 기다리는 형태, 사용하고자 하는 락이 풀릴 때 까지 기다리는 형태 (차레대로 열거상수 = WAITING, TIMED_WAITING, BLOCKED)
- 종료 : 실행을 마친 상태 (열거상수 = TERMINATED)
스레드 상태 제어
- sleep : 스레드를 잠시 멈춤
- yield : 다른 스레드에게 실행 양보
- join : 다른 스레드의 종료를 기다림
- wait, notify, notiftAll : 스레드 간 협업
- stop, interrupt : 스레드 종료
스레드 그룹 : 관련된 스레드를 묶어서 관리
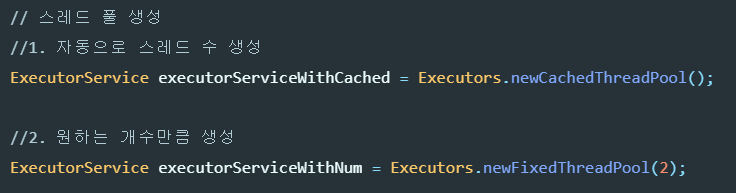
스레드 풀 : 병렬 작업의 폭증으로 인한 스레드의 폭증을 막으려면 스레드 풀을 사용해야 함
- 스레드 풀은 작업 처리에 사용되는 스레드를 제한된 개수만큼 정해놓고 작업 큐에 들어오는 작업들을 하나씩 스레드가 맡아서 처리한다
- 작업 처리가 끝난 스레드는 다시 작업 큐에서 새로운 작업을 가져와 처리 그렇기 때문에 작업 처리 요청이 폭증되어도 스레드 전체 개수가 늘어나지 않는다
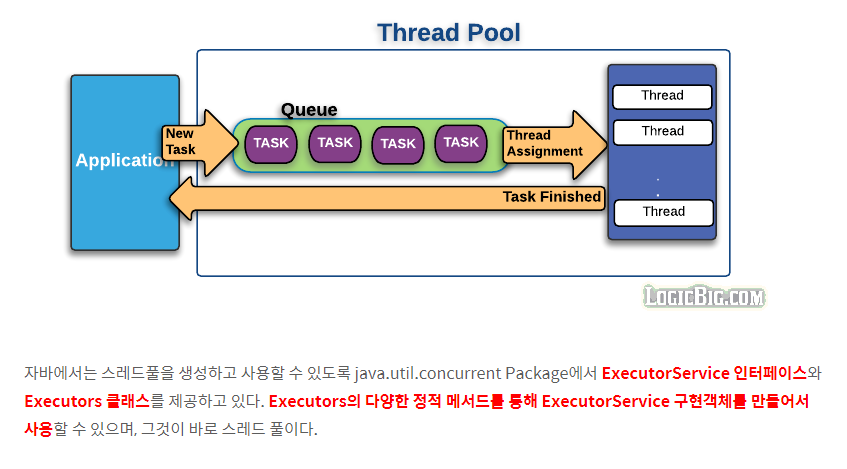
작업 생성은 Runnable이나 Callable 구현 클래스로 표현한다. 두 클래스의 차이점은 전자는 return 값이 없고 후자는 return 값이 있다
작업 처리 요청은 ExecutorService의 작업 큐에 Runnable이나 Callable 객체를 넣는 행위이다
ExecutorService는 두 가지의 메소드를 제공하는데 execute()는 작업 처리 결과를 받을 수 없고 submit()은 작업 처리 결과를 받을 수 있도록 Future를 return한다
작업 완료 통보 방법
- 블로킹 방식의 작업 완료 통보 : submit() 메소드가 Future 객체를 리턴하면 Future 객체는 작업이 완료될 때 까지 기다렸다가 최종 결과를 얻는데 사용된다
즉, Future의 get() 메소드를 호출하면 스레드가 작업을 완료할 때 까지 블로킹되었다가(다른 코드 실행 불가) 작업을 완료하면 처리 결과를 리턴한다 - 리턴 값이 없는 작업 완료 통보 : Runnable 객체로 생성하면 리턴 값이 없는 작업 완료 통보가 가능하다
- 리턴 값이 있는 작업 완료 통보 : Callable로 객체를 생성하면 리턴 값이 있는 작업 완료 통보가 가능하다
- 작업 처리 결과를 외부 객체에 저장 : 스레드가 작업 처리를 완료하고 외부 Result 객체에 작업 결과를 저장하면 application이 Result 객체(공유 객체)를 사용해서 어떤 작업을 진행할 수 있다
- 작업 완료 순으로 통보 : CompletionService를 이용하면 스레드 풀에서 작업 처리가 완료된 순으로 통보 받을 수 있다
- 콜백 방식의 작업 완료 통보 : 블로킹방식과 유사하지만 콜백 방식은 작업 처리를 요청한 후 결과를 기다릴 필요 없이 다른 기능을 수행할 수 있다
그 이유는 작업 처리가 완료되면 자동적으로 콜백 메소드가 실행되어 결과를 알 수 있기 때문이다
콜백이란? 애플리케이션이 스레드에게 작업 처리를 요청한 후 스레드가 작업을 완료하면 특정 메소드가 자동으로 실행되느 기법

[제가 직접 구매한 이것이 자바다 책에 나온 내용을 일부 캡처했습니다.]

개발자 별 거 아냐! 일단 봐봐