개요
이 전에 모놀리식 서버에서 팀 간 배포경합 완화하기라는 글에서 팀내 여러가지 상황을 고려하여 feature-flag를 도입하기로 했다는 글을 작성한 적이 있었는데 구현과정에 대해서 자세하게 소개를 해보려고 한다.
feature-flag를 구현하려면 설정값을 저장하고 관리할 필요가 있는데 이를 위해서 AWS Appconfig를 활용해보기로 하였다.
AWS Appconfig
사실 처음에 AWS Appconfig를 활용해보려고 했던 것은 뭔가 특별한 이유가 있었다 라기 보단 CTO께서 이런 서비스를 AWS에서 제공하고 있는데 사용해보는 것이 어떻겠냐고 하여 해당 서비스에 대해서 조사를 시작했다.
구성요소
- application
- 구성요소를 사용할 어플리케이션의 이름
- configuration
- 어떤 구성 혹은 설정인지를 구분, 하나의 어플리케이션에 여러개의 configuration이 들어갈 수 있음
- environment
- 배포환경, 보통 dev, prod 같은 느낌으로 사용
- version
- 처음배포를 하면 1부터 시작, 변경 후 배포를 할 때 마다 1씩 증가
설정포맷
- feature flag
- 설정파일이 따로 없고 key값만 정의가능, 모든 value는 boolean이라고 보면 된다
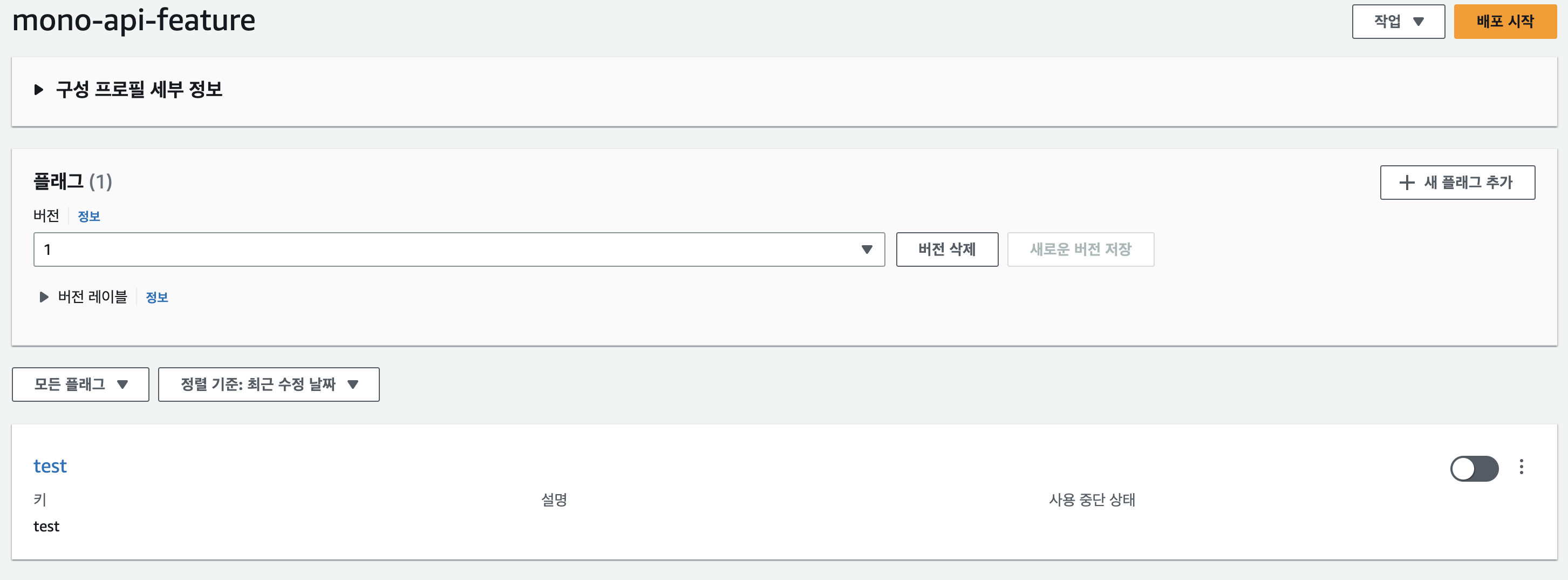
- 설정파일이 따로 없고 key값만 정의가능, 모든 value는 boolean이라고 보면 된다
- 자유양식
- 텍스트방식으로 자유롭게 작성이 가능, 기본적으로 json, yaml의 validation을 지원하며 lambda와 연결하여 custom한 validation 작성도 가능
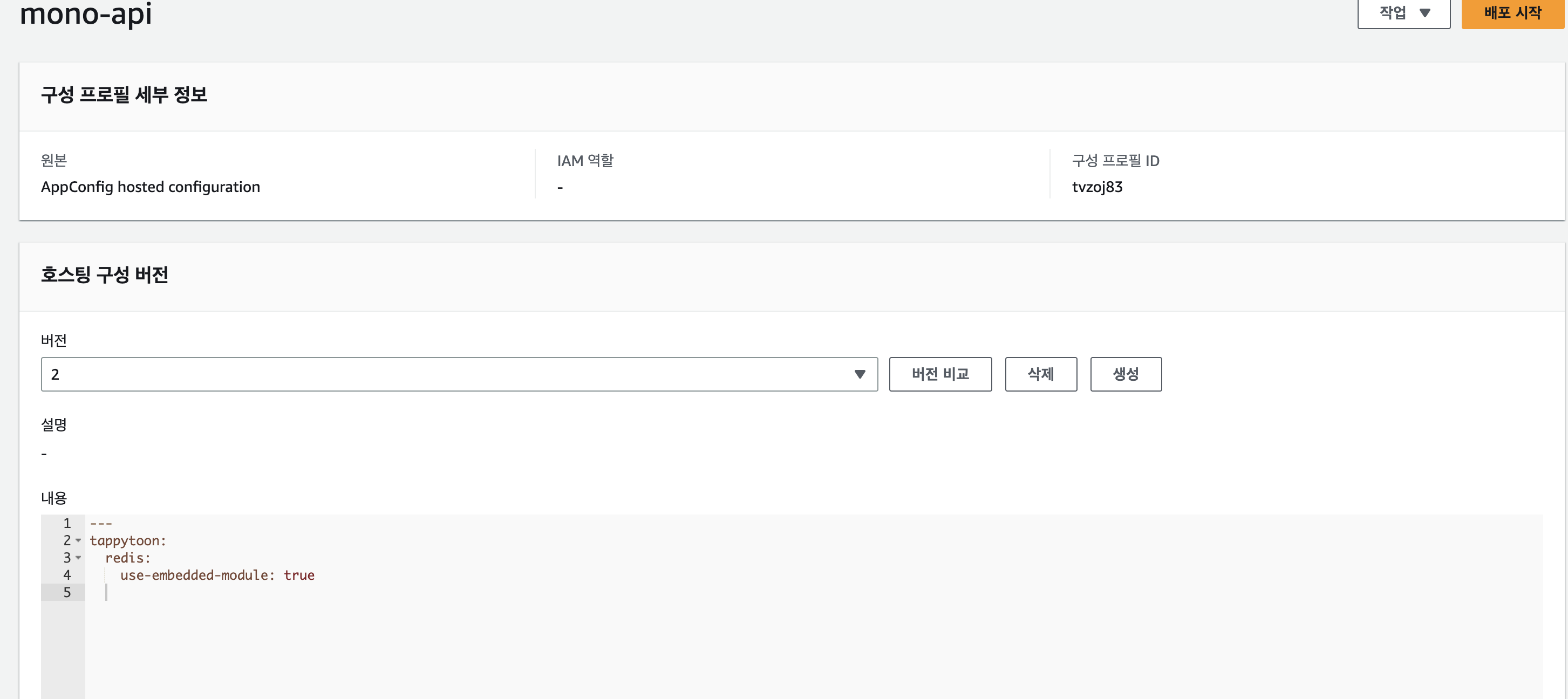
- 텍스트방식으로 자유롭게 작성이 가능, 기본적으로 json, yaml의 validation을 지원하며 lambda와 연결하여 custom한 validation 작성도 가능
사실 두가지 방식이 근복적으로 다르진 않지만 단순 기능의 on/off만을 위해 사용한다면 feature flag가 관리 용이성 측면에서 더 좋다라고 느껴져 해당 방식을 사용하였습니다.
배포
모든 구성(configuration)은 배포를 해야 사용가능 합니다. 배포방식은 정책에 따라 배포 간격, 베이크 타임을 조절 가능하나 뒤에서 후술하겠지만 점진적 배포의 경우 서비스에서 제대로 설명하지 않은 문제점이 존재합니다.
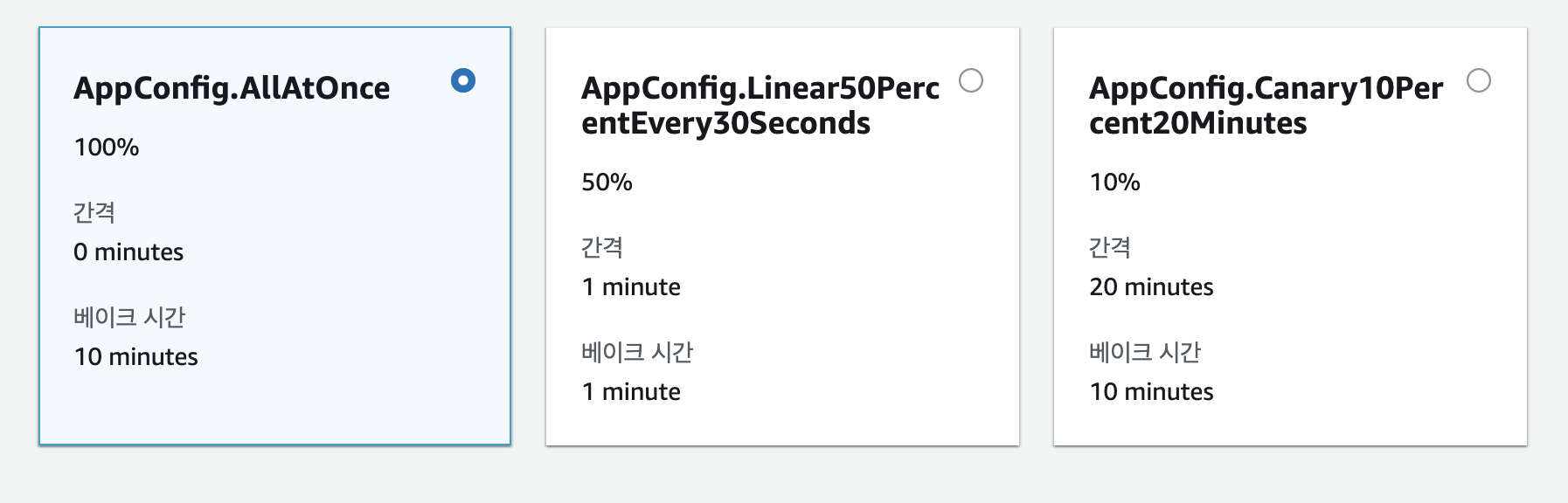
사용하기
Appconfig의 조회는 아래와 같은 API를 사용하면 되는데 점진적 배포와 연동되는 세션을 활용하려면 StartConfigurationSession와 GetLatestConfiguration를 활용해야 합니다.
금액은 한번 호출에 0.0008 USD라고 합니다. 캐싱을 잘 활용한다면 합리적으로 사용할 수 있을 것 이라 생각이 듭니다.
그외에 배포에 대한 이벤트를 sqs나 eventbridge에 연동하거나 cloudwatch에 연동 후 에러 알람 발생 시 롤백을 하는 기능등이 있지만 해당 기능은 사용하지 않았기에 언급만 하고 넘어가겠습니다.
조사를 하다보니 도입을 하지 않을 이유가 없어 구체적인 개발을 시작하였습니다. 조사를 하면서 개인적으로 생각한 Appconfig 장점은
- 설정에 대한 버전관리 및 배포 가능
- 점진적 배포와 롤백이 가능
- 합리적인 금액
- feature-flag 템플릿 지원
- cloudwatch 연동을 통한 자동 롤백
정도가 아닐까 생각이 듭니다.
terraform 모듈 구현
우리는 사내 모든 인프라를 terraform으로 관리하고 있습니다. appconfig도 인프라의 일부로 간주하고 terraform으로 feature-flag 모듈을 구성하기로 했습니다. feature-flag 모듈을 구성하는데 사용할 terraform 리소스는 아래와 같습니다.(리소스 관련 문서)
- aws_appconfig_application
- aws_appconfig_configuration_profile
- aws_appconfig_environment
- aws_appconfig_hosted_configuration_version
# main.tf 자세한 코드는 생략..
resource "aws_appconfig_application" "this" {
# ...
}
resource "aws_appconfig_environment" "this" {
# ...
}
resource "aws_appconfig_configuration_profile" "this" {
# ...
}
resource "aws_appconfig_hosted_configuration_version" "this" {
# ...
}
# variables.tf 자세한 코드는 생략..
variable "application_name" {
type = string
}
variable "flags" {
type = list(object({
key = string
is_enabled: bool
}))
}위에서 언급한 4가지 구성요소를 관리하도록 하였습니다. 해당 모듈은 사용할 서비스의 인프라 관련 코드로 가서 아래와 같이 사용하면 됩니다.
#...
module "feature_flag" {
source = "../../../path/to/feature-flag/module"
application_name = "service name"
flags = [
{ "flag_1", true },
{ "flag_2", false }
]
}
#...하나의 어플리케이션은 하나의 aws_appconfig_application, aws_appconfig_environment(env가 하나인 이유는 사내 prod 계정을 별도로 관리하고 있기 때문)을 갖습니다.
하나의 aws_appconfig_application은 여러개의 flag를 갖고 있기 때문에 여러개의 aws_appconfig_configuration_profile을 갖습니다.
그리고 각 aws_appconfig_configuration_profile은 여러개의 버전(flag의 값)을 갖고 있기 때문에 여러개의 aws_appconfig_hosted_configuration_version을 갖게 됩니다.
간단하게 표현하면 아래와 같은 관계를 갖게됩니다.
실제 어플리케이션 1 : 1 aws_appconfig_application, aws_appconfig_environment
aws_appconfig_application 1 : N aws_appconfig_configuration_profile을
aws_appconfig_configuration_profile을 1 : N aws_appconfig_hosted_configuration_version
다만 여기서 문제가 한가지 있었는데 aws_appconfig_hosted_configuration_version 리소스가 apply마다 destroy 후 생성한다는 것 이었습니다. 그러면 배포를 하더라도 원래 참고하던 리소스가 없어지면서 참고할 데이터가 사라지는 불상사가 생기게 됩니다.
그래서 aws_appconfig_hosted_configuration_version은 테라폼에서 관리하지 말아야 하나.. 라는 고민까지 했지만 그렇게 해버리면 테라폼으로 관리할 이유자체가 없을듯 하여 null_resource를 활용해보기로 하였습니다.
resource "null_resource" "appconfig_configuration_version" {
triggers = {
application_name = var.application_name
configurations = join(" ", [for v in var.flags : v])
}
provisioner "local-exec" {
command = "sh ./path/to/script ${self.triggers.application_name} ${self.triggers.configurations}"
}
lifecycle {
create_before_destroy = true
}
depends_on = [ aws_appconfig_configuration_profile.appconfig_configuration ]
}위 처럼 triggers에 변화가 있는 경우에만 쉘스크립트를 실행하도록 하였습니다.
스크립트와 terraform 코드는 아래의 사항들을 고려하여 작성하였습니다.
- 쉘스크립트는 configurations의 값을 받아 true와 false인 version을 모두 생성
- 쉘스크립트로 전달되지 않은 configuration 인데 aws 상에 존재하면 제거
- aws_appconfig_configuration_profile이 생성된 이후 실행이 되어야함
- destroy를 먼저하는 경우 aws_appconfig_configuration_profile의 제거를 먼저하게 되는데(depends_on이 걸려있기 때문..) 이 시점에는 기존의 version들이 존재하기에 제거에서 에러가 발생하기에
create_before_destroy = true로 설정
여기서 스크립트에서 true와 false인 버전을 모두 생성해주는 이유는 어차피 flag가 가질 수 있는 값은 이 2가지 뿐이고 배포 시 이 2가지 값이 모두 필요하기 때문입니다. 이 부분은 다음 항목에서 더 자세히 설명하겠습니다. 결론적으로 flag의 값은 테라폼에서 관리를 하나 모두 생성해주기 때문에 아래와 같이 flag의 값만 설정해주면 되게 되었습니다.
# variable.tf
variable "flags" {
# 해당 코드 제거
# type = list(object({
# key = string
# is_enabled: bool
# }))
type = set(string)
}
#...
module "feature_flag" {
source = "../../../path/to/feature-flag/module"
application_name = "service name"
flags = [
"flag_1",
"flag_2"
]
}
#...결론적으로 아래와 같은 관계를 갖게되었습니다.
실제 어플리케이션 1 : 1 aws_appconfig_application, aws_appconfig_environment
aws_appconfig_application 1 : N aws_appconfig_configuration_profile을
aws_appconfig_configuration_profile을 1 : 2(true, false하나 씩) aws_appconfig_hosted_configuration_version
여기서 주의할 부분은 테라폼으로 실제 배포가 이루어지진 않는다는 것 입니다. flag의 값의 저장까지만 테라폼으로 관리를 하고 실제 배포는 개발자가 권한을 받아 aws 콘솔을 통해 진행하게 됩니다. 이렇게 수행하는 이유는 배포 도중 문제 발생 시 롤백을 빠르게 하기 위함 입니다.
어플리케이션 코드에 적용
실제 서비스에 분기 값을 적용하는 부분은 사이드카를 활용하여 간단하게 처리할 수 있었습니다. aws에서 제공하는 appconfig 사이드카를 배포하는 컨테이너 그룹에 서비스와 별도의 컨테이너를 추가하는 것 입니다.
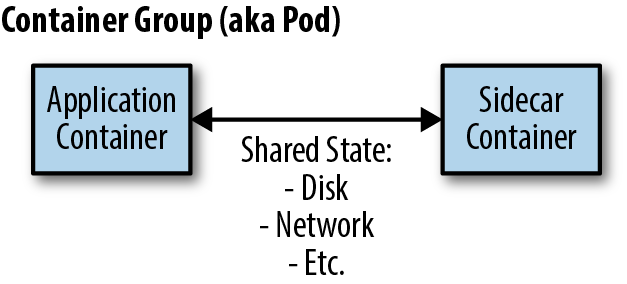
출처: https://www.oreilly.com/library/view/designing-distributed-systems/9781491983638/ch02.html
appconfig 사이드카는 캐싱과 폴링을 통해 appconfig의 설정값을 관리해줍니다. 그래서 어플리케이션 부분에서 할 일은 flag가 분기되는 부분이 호출될 때 마다 사이드카를 호출하는 것 뿐입니다.
interface FeatureFlagClient {
fun get(key: String) : Boolean
}
@Component
@Profile("local")
class FeatureFlagLocalClient : FeatureFlagClient {
// 대충 로컬테스트용 구현체
}
@Component
@Profile("!local")
class FeatureFlagAppConfigClient : FeatureFlagClient {
// 실제 appconfig 사이드카를 호출하는 구현체
}위와 같이 인터페이스로 flag의 값을 가져오는 행위를 정의하고 로컬에서 사용할 테스트용 구현체와 실제 appconfig의 값을 가져오는 구현체를 구성하였습니다. appconfig 사이드카를 호출하는 방법은 default 설정이라면
$ curl "http://localhost:2772/applications/application_name/environments/environment_name/configurations/configuration_name?flag=flag_name"위 처럼 api만 호출해주면 됩니다. 사이드카 내부적으로 캐싱을 하고 있기 때문에 추가적인 프로그래밍은 필요없고 단순히 api 호출만 해주면 됩니다.
다만 여기서 주의할 부분은 바로 true로 배포 후 롤백을 하면 flag값 조회 시 NotFound가 되어 버리는데(이전 설정이 없기 때문) 사이드카에서 false로 변경되지 않고 정상적인 응답(200 ok)을 받았던 값을 캐시에서 지우지 않고 계속 true를 반환하게 됩니다. 그래서 terraform 모듈을 만들 때 언급했던 것 처럼 false와 true 값을 모두 생성할 필요가 있엇던 것 이었습니다.
그래서 실제 배포하는 경우 false배포(버전1) -> true배포(버전2) 이런 순서로 진행을 하게 됩니다. 그리고 버전2 배포 도중 문제 발생 시 롤백을 하면 버전1로 돌아가게 됩니다.
feature-flag 적용을 위한 매뉴얼 작성
어떻게 보면 가장 난감했던 부분이었습니다. CTO깨서 feature-flag를 남발하게 되는 상황을 굉장히 우려하여 개발자들이 사용 시 경각심을 갖고 활용할 수 있도록 매뉴얼에 최대한 모든 프로세스와 룰을 담을 필요가 있었습니다.
모든 과정을 작성하긴 힘들고 몇가지 feature-flag 적용 시 룰을 적자면
- 배포 시 다른 feature(주로 다른 팀의)에 영향을 주는 경우에만 사용
- diff가 있는 모든 코드를 복사하여 별도의 패키지에 추가하고 기존 코드는 변경하지 않을 것
- entry point에서 분기를 수행할 것(ex) 컨트롤러 레이어, 이벤트 리스너 등...)
- 점진적 배포의 비율을 믿지 말 것!
정도가 큰 룰이 될 것 같습니다. 여기서 마지막 룰이 생긴 이유는 점진적 배포의 비율이 실제 서비스 인스턴스의 분기 값이 변경되는 비율이 1:1로 매칭되지 않았기 때문입니다.
만약 특정 서비스의 인스턴스가 5개 이고 배포시간 10분에 배포 비율을 20%라고 한다면 2분에 하나의 인스턴스가 flag의 값이 변경되는 것을 기대하게 됩니다. 하지만 실제론 일정하지 않게 적용이 되었는데 이에 대해서 aws에 문의한 결과 아래와 같은 답변을 받을 수 있었습니다.
내부 서비스팀으로부터 (Deployment 37) 및 (Deployment 33) 을 분석 후 업데이트가 있었으며, 답변 사항을 아래와 같이 전달 드립니다.
( #내부 서비스팀 답변 사항 )
- Each AWS AppConfig Agent configuration session is associated with a randomly generated session id. On deployments, each session's id is hashed and placed into a deployment bucket which determines when that session will receive the latest update. The hashing algorithm will create uniformly distributed buckets with a larger sample size (number of Agents running); however, your setup currently has 5 agents and 5 buckets which creates an unlikely environment for a perfectly even distribution.
The best way to get a more even distribution of deployments would be to:
- Increase the number of sessions polling by adding more agent containers to your ECS cluster.
- Increase the number of buckets within the deployment by decreasing the "GrowthFactor" value of your linear deployment
- 각 AWS AppConfig Agent configuration 세션은 무작위로 생성된 세션 ID와 연결됩니다. 배포 시 각 세션의 ID는 해시되어 배포 버킷에 배치되며, 배포 버킷은 해당 세션이 최신 업데이트를 받을 시기를 결정합니다. 해싱 알고리즘은 실행 중인 에이전트 수가 더 큰 균일하게 분산된 버킷을 만들지만, 현재 설정에는 5개의 에이전트와 5개의 버킷이 있으므로 완벽하게 균일하게 배포되기 어려운 환경이 조성됩니다. 이에 따라, 보다 균일한 배포를 위해 가장 좋은 방법은 아래와 같습니다:
- ECS 클러스터에 에이전트 컨테이너를 더 추가하여 세션 폴링 수를 늘립니다.
- Linear유형의 배포전략의 "GrowthFactor" 값을 줄여서 배포 내 버킷 수를 늘립니다. (예: 20 -> 10)즉 aws의 appconfig에서 관리하는 버킷과 세션은 1:1로 매칭되지 않는다는 것 이었습니다. 서비스의 인스턴스를 늘리는 것은 굉장히 부담이 크고 배포 비율을 줄이는 것을 생각해볼 수 있을 것 같습니다. 하지만 결론적으로 불확실성이 존재하기에 Appconfig의 점진적 배포는 신뢰하지 않기로 하고 한번에 배포를 하고 롤백을 하는 것으로 결론을 지었습니다.
결론
어떻게 보면 특별한 기능이 없는 그저 true/false를 통해 로직을 분기할 뿐인 스위치 이지만 배포 프로세스와 정책 같은 것을 고민하다 보니 많은 시행착오를 격게 되었던 것 같습니다. 아무튼 만들었으니 팀 내 개발자들이 유용하게 썼으면 하는 바람입니다. 💪
