서론
이번에 toss에서 발표한 slash22에서 서버와 관련된 세션을 보면서 오히려 궁금증이 커졌던 부분에 대해 조사를 해보려고 한다. 사실 나머지 세션은 대부분 서버의 인프라를 어떻게 구성했는가? 에대한 이야기들이었다. 간단하게 이야기 하면 금융권에서 MSA를 어떤식으로 구성했는가? 외부환경에 대한 영향을 어떻게 최소화 했는가에 대한 이야기 였는데 이런 이야기들은 지금의 나에겐 크게 도움이 될 것이란 생각이 들지 않았다.
'JAVA Native Memory Leak 원인을 찾아서' 세션의 내용을 간략하게 설명하면 toss에선 전체 시스템의 안정성을 위해 OOM(Out Of Memory)이 발생할 가능성이 있는 POD(아마도 쿠버네티스의 인스턴스)을 모니터링하여 미리 종료시켜주는 OOM Killer라는 툴을 사용하고 있다. 이 OOM Killer가 비정상적으로 자주동작하여 원인을 찾아 해결하는 것이 주된 내용이다.
OOM의 원인은 C2 컴파일러의 최적화 과정에서 발생했고 이를 컴파일러의 설정을 Graal Compiler로 변경하는 것으로 해결했다고 한다. 세션을 보고 원인과 해결방법은 알려주었지만 정확히 어떻게 C2 컴파일러가 문제가 되었고 Graal Complier는 무엇이기에 이를 해결할 수 있었던 것인지 알수없었다. 이에 대해서 나름대로의 조사를 해보려고 한다.
Java의 컴파일 과정
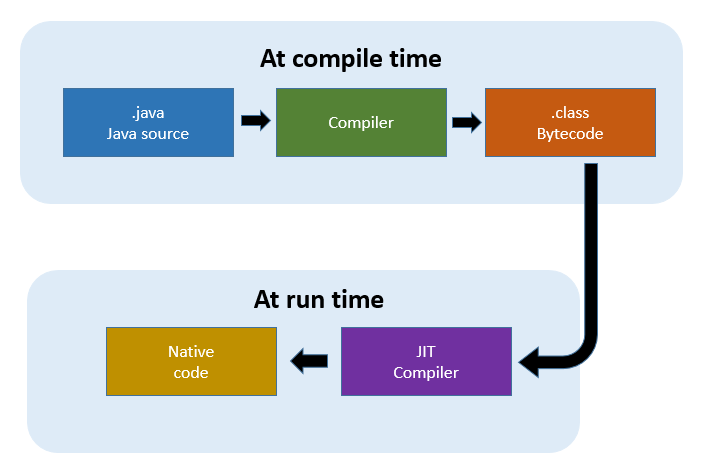
알다싶이 Java는 바로 기계어로 컴파일되지 않고 바이트코드로 컴파일 된다. 그 후에 환경에 맞는 JVM에서 인터프리트 방식으로 기계어로 번역인 됩니다. 이러한 방식 때문에 바로 기계어로 번역이 되는 언어들 보다 느릴 수 밖에 없습니다. 이러한 문제점을 보완하기 위해 JIT(Just-In-Time) 컴파일러라는 것을 사용하게 되는데 말그대로 그때 그때 컴파일을 하겠다는 것 입니다. 그렇다면 문제는 언제 컴파일을 하냐일텐데 아주 단순하게 이야기하면 자주 호출되는 함수를 컴파일을 해둔다고 생각하면 될 것 같습니다.
이 과정에서 위에서 이야기 한 C2 컴파일러가 등장하게 됩니다. JVM JIT 컴파일러는 흔히 C1(클라이언트) 컴파일러와 C2(서버) 컴파일러로 나뉩니다. 이 둘의 차이는 위에서 이야기한 컴파일 되는 시점입니다. C1 컴파일러가 C2 컴파일러 보다 적극적으로 컴파일을 수행합니다. 그래야 실행시간(start up)이 더 빠르기 때문입니다. 하지만 덩치가 매우큰 프로그램의 경우에는 최적화에 좀더 많은 정보가 필요하게 될 것 입니다. C2 컴파일러는 실행시간보다 프로그램의 전체적인 퍼포먼스에 좀더 비중을 두고 있다고 보면 될 것 같습니다.
현재 Java의 디폴트 JIT 컴파일러는 티어드 컴파일러 입니다. 티어드 컴파일러는 먼저 C1 컴파일러로 컴파일을 수행하고 많이 사용하게 되면 역최적화 이후 C2 컴파일러로 컴파일을 하게 됩니다.
C2 컴파일러가 발생시킨 문제점?
그렇다면 이 C2 컴파일러가 메모리를 많이 차지했던 이유는 무엇일까? 영상에선 자세히 나오지 않아 한번 관련내용이 openjdk 버그 리포트에 있는지 찾아 보았다. 사실 봐도 정확한 파악은 힘들었지만 그나마 비슷해 보이는 이슈는 C2 Compiler native memory leak endless "retry class loading during parsing" | OpenJDK 11.0.5 이다. 이 이슈는 이미 컴파일을 위해 할당된 캐시를 전부 사용했는데도 컴파일을 무한히 시도해서 생기는 문제인 것으로 보인다. 다만 해당 문제는 이미 해결된 것으로 보인다. 영상에서도 JDK11의 최신버전이나 JDK17을 사용해도 문제가 발생했다고 한 것으로 봐선 해당 문제는 아닌 것 같은데 이 부분은 좀더 찾아봐야 할 것 같다.
Graal 컴파일러

아주 단순하게 이야기 하면 Graal 컴파일러는 C2 컴파일러를 대체하는 JIT 컴파일러이다. 우리가 보통 사용하는 JVM인 Hotspot VM에서 C2 컴파일러 부분이 변경되고 이를 VM에서 컴파일요청을 할 수 있도록 JDK9 이후로 추가 된 JVMCI라는 인터페이스를 사용한다.
// 실제로는 더 복잡하다
interface JVMCICompiler {
byte[] compileMethod(byte[] bytecode);
}바이트코드를 매개변수로 받아 기계어에 해당하는 byte array를 반환하는 인터페이스가 있다고 생각하면 편할 것 이다. GraalVM의 공식홈페이지에 GraalVM과 기존의 HotSpotVM을 비교하기 위한 예제가 준비되어 있다.
public class Blender {
private static class Color {
double r, g, b;
private Color(double r, double g, double b) {
this.r = r;
this.g = g;
this.b = b;
}
public static Color color() {
return new Color(0, 0, 0);
}
public void add(Color other) {
r += other.r;
g += other.g;
b += other.b;
}
public void add(double nr, double ng, double nb) {
r += nr;
g += ng;
b += nb;
}
public void multiply(double factor) {
r *= factor;
g *= factor;
b *= factor;
}
}
private static final Color[][][] colors = new Color[100][100][100];
public static void main(String[] args) {
for (int j = 0; j < 10; j++) {
long t = System.nanoTime();
for (int i = 0; i < 100; i++) {
initialize(new Color(j / 20, 0, 1));
}
long d = System.nanoTime() - t;
System.out.println(d / 1_000_000 + " ms");
}
}
private static void initialize(Color id) {
for (int x = 0; x < colors.length; x++) {
Color[][] plane = colors[x];
for (int y = 0; y < plane.length; y++) {
Color[] row = plane[y];
for (int z = 0; z < row.length; z++) {
Color color = new Color(x, y, z);
color.add(id);
if ((color.r + color.g + color.b) % 42 == 0) {
// PEA only allocates a color object here
row[z] = color;
} else {
// Here the color object is not allocated at all
}
}
}
}
}
}Sunflower라는 오픈소스 엔진을 단순화한 버전이라고 한다.
javac Blender.java
java -XX:+UnlockExperimentalVMOptions -XX:+EnableJVMCI -XX:+UseJVMCICompiler Blender #Graal 사용
java -XX:+UnlockExperimentalVMOptions -XX:+EnableJVMCI -XX:-UseJVMCICompiler Blender #Graal 사용하지 않음Blender.java를 바이트코드로 컴파일 한뒤 위와 같은 두가지 옵션으로 실행하여 성능을 비교해 보자.

위가 Graal 컴파일러를 사용한 것이다. 예제라서 그런 것 일수도 있으나 눈에 보일정도의 성능향상을 볼수 있다.
Graal 컴파일러는 값비싼 개체 할당을 제거할 수 있는 기능으로 인해 고도로 추상화된 프로그램의 성능 이점을 보장하고 더 많은 추상화와 Streams 또는 Lambdas와 같은 최신 Java 기능을 사용하는 코드는 더 큰 속도 향상을 볼 수 있다고 한다. I/O, 메모리 할당 또는 가비지 수집과 같은 것으로 수렴되는 저수준 코드 또는 코드는 상대적으로 효과가 미흡하다고 합니다.
성능적인 부분에선 확실히 개선이 있을 수 있다는 생각이 든다. 그렇다면 메모리의 측면에선 어떨까? 위에서 보았던 C2 컴파일러의 버그 때문이라면 단순히 JIT 컴파일러 자체를 변경하는 것으로 해결된 것 일수도 있을 것이다. 일반적인 상황에선 어떨지 한번 확인을 해보기 위해 시간을 측정하는 부분에 아래의 코드를 추가하여 확인해 보았다.
Runtime.getRuntime().gc();
long usedMemory = Runtime.getRuntime().totalMemory() - Runtime.getRuntime().freeMemory();
System.out.println(usedMemory + " bytes");이 경우에는 오히려 Graal 컴파일러가 11842024 bytes, C2 컴파일러가 6156808 bytes로 Graal 컴파일러의 메모리 사용량이 더 높았다. 다만 이 경우에는 heap만 보는 것 이므로 native memory를 많이 사용하는 어플리케이션의 경우에는 또 다른 결과가 나올 수도 있을 것이다. native memory의 경우에는 이런 간단한 어플리케이션에서 테스트 하는 것은 크게 의미가 없을 것 같아 차후에 사이드 프로젝트 같은 것을 만든다면 테스트를 한번 해봐야 겠다.
결론
사실 위에서 간단하게 진행한 테스트는 Graal 컴파일러의 특징을 완벽히 대변한다고 볼 수 없다. 실무에서 사용하는 환경이나 코드의 구성에 따라 위 테스트 결과는 언제든 달라질 수 있다. 여기서 중요한 부분은 Graal 컴파일러의 도입을 고려하고 있는 경우 기존의 C2 컴파일러를 사용하고 있을 때와 무엇이 달라졌는지 면밀히 모니터링을 할 필요가 있다는 것이다. 그리고 Toss처럼 좋은 결과가 나온 경우에만 적용을 하는 것이 좋을 것이라고 생각이 든다.
