
5주차 진도(1/29 ~ 2/4) : Chapter 06
✅ 기본 미션
p. 310 인덱스 생성하고 key_name이 PRIMARY로 출력된 결과 화면 캡처하기

✅ 선택 미션
인덱스 생성, 제거하는 기본 형식 작성하기
1️⃣ 인덱스 생성
CREATE [UNIQUE] INDEX 인덱스_이름
ON 테이블_이름 (열_이름) [ASC | DESC]2️⃣ 인덱스 제거
DROP INDEX 인덱스_이름 ON 테이블_이름인덱스
개념
📖 인덱스 (Index)
데이터 빠르게 찾을 수 있도록 도와주는 도구 → 실무에선 필수
특징
장단점
👍 장점
- SELECT문의 검색 속도 빨라짐 🐎
- 적절한 인덱스 생성 & 인덱스 사용 SQL 만들면 아주 빠른 응답 속도 얻을 수 있음
- 적은 처리량 발생 → 컴퓨터 부담 감소 → 전체 시스템 성능 향상 효과 발생
👎 단점
- 처음 인덱스 만들 때 시간 오래 걸림
- 남용하면 오히려 느려짐
- 필요 없는 인덱스 → 데이터베이스가 차지하는 공간만 늘어나 공간 낭비
- 필요 없는 인덱스 → 인덱스 이용해 데이터 찾는 것이 전체 테이블 찾는 것보다 느려짐
생성
- 테이블 열(컬럼) 단위로 생성
- 하나의 열에 하나의 인덱스 생성 👌
인덱스 확인 : SHOW INDEX문 사용
-
테이블 생성
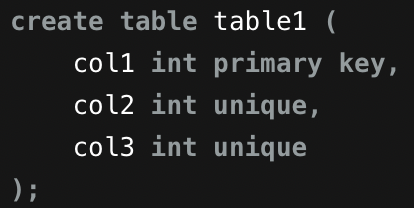
-
SHOW INDEX 사용

-
인덱스 지정된 열 확인
- Non_unique
- 0 → False 의미, 고유 인덱스(Unique Index), 중복 허용 ❌
- 1 → True 의미, 단순 인덱스(Non-Unique Index), 중복 허용 ⭕️
- Key_name
- PRIMARY KEY → 기본 키(중복 허용 ❌)로 설정해 자동으로 생성된 인덱스
- 열 이름 → 고유 키(중복 허용 ❌)로 설정해 자동으로 생성된 보조 인덱스
- Column_name → 인덱스 지정된 열
- Non_unique

종류
1️⃣ 클러스터형 인덱스 (Clustered Index)
특징
- 기본 키로 지정 → 자동 생성 ⭕️
- 테이블 당 1개만 만들 수 있음
- 기본 키로 지정한 열 기준으로 자동 정렬 ⭕️
예) 영어사전 : 별도의 찾아보기 없이 책 내용이 이미 알파벳 숫서대로 정렬되어 있어 책 자체가 찾아보기
예시1
-
mem_id열 기본 키로 설정
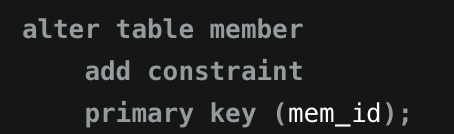
-
mem_id열 기준 정렬 확인
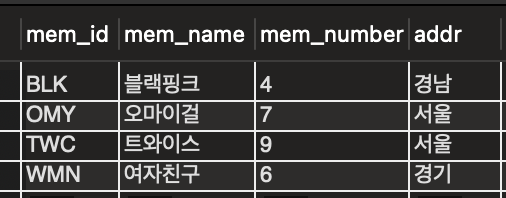
예시2
-
기본 키 삭제 후 mem_name열 Primary key 지정
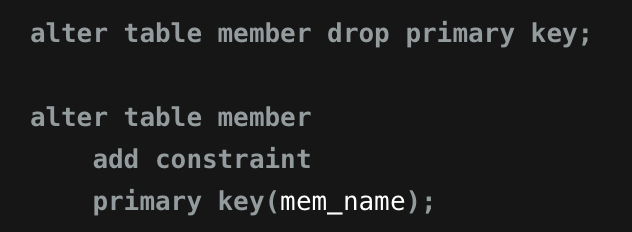
-
mem_name열 기준 정렬 확인
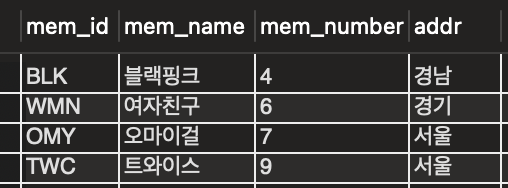
2️⃣ 보조 인덱스 (Secondary Index)
- 중복 ⭕️/❌ 따라 단순 보조 인덱스 / 고유 보조 인덱스 로 나뉨
- 고유 키로 지정 → 자동 생성 ⭕️
- 여러 개 만들기 가능하지만 자동 정렬 ❌
- 만들 때마다 데이터베이스 공간 차지 & 시스템에 나쁜 영향 미침 → 적절히 보조 인덱스 생성해야 함❗️
예) 일반 책 : 뒤에 찾아보기가 따로 있어 찾아보기에서 단어를 찾은 후 그 페이지를 펼쳐야 찾는 내용 존재
예시1
-
고유 키 없는 테이블
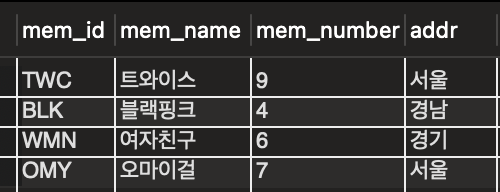
-
고유 키 설정
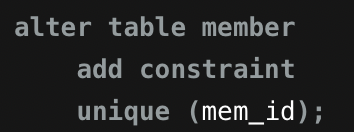
-
고유 키 있는 테이블 → 데이터 내용 변화 ❌
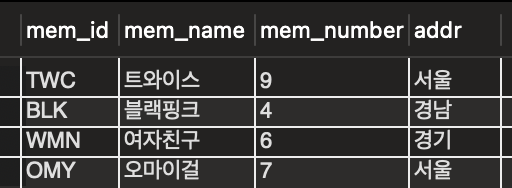
-
고유 키 설정 추가
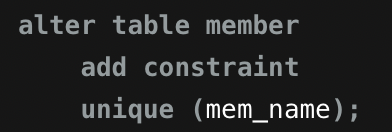
-
고유 키 2개 있는 테이블 → 데이터 내용 변화 ❌
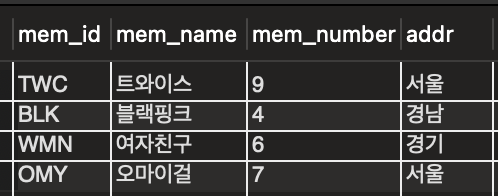
-
고유 키 확인

인덱스 내부 작동
내부 작동 원리
- 내부 작동 원리 이해 → 인덱스 사용해야 할 경우/사용하지 말아야 할 경우 선택 도움
- 클러스터형 인덱스 & 보조 인덱스 모두 내부적으로 균형 트리로 만들어짐
균형 트리
- 데이터 검색(SELECT 구문 사용)할 때 아주 뛰어난 성능 발휘
🌳 노드 (node) = 📄 페이지 (page, MySQL 용어)
- 노드 : 데이터가 저장되는 공간
- 유형
- 루트 노드 (root node) : 노드의 가장 상위 노드
- 중간 노드 (internal node) : 루트와 리프 노드 중간에 끼인 노드
- 리프 노드 (leaf node) : 제일 마지막 하위 노드
- 페이지 : 최소 저장 단위
- 16Kbyte 크기
- 데이터 1건만 입력해도 1개 페이지 필요
📕 동작 (데이터 MMM 찾기)
- 리프 페이지만 있는 경우 (균형 트리 구성 ❌, 인덱스 없는 경우)
- 원하는 데이터 찾으려면 처음부터 검색해야만 함 = 전체 테이블 검색 (Full Table Scan)
- 8건의 데이터, 3개의 페이지 읽음
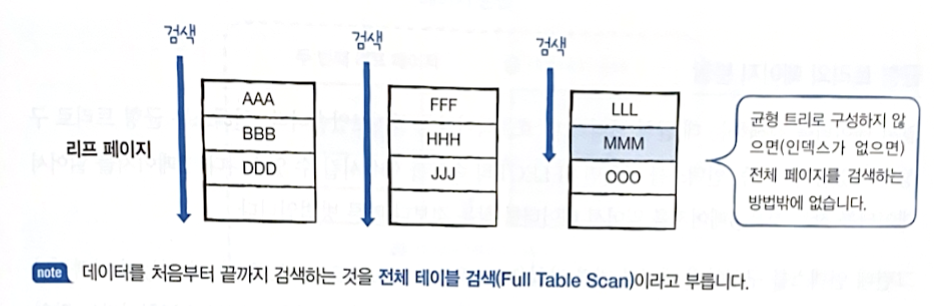
- 균형 트리에서 검색
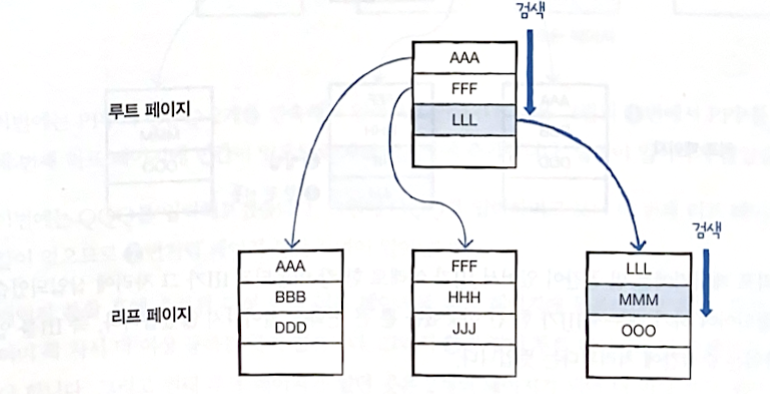
- 무조건 루트 페이지부터 검색
- 모든 데이터 정렬되어 있는 상태
- 5건의 데이터, 2개의 페이지 읽음 → 더 효율적
📑 페이지 분할
- 새로운 페이지 준비해 데이터 나누는 작업
- 현재 존재하는 리프 페이지에 빈 공간이 없을 경우 발생
- 인덱스 구성 시 데이터 변경 작업(INSERT, UPDATE, DELETE) 성능 나빠지는 이유
- 특히, INSERT 작업 발생할 때 더 느림
- 루트 페이지에 빈 공간이 없다면 새로운 페이지 할당 및 분할 필요하므로 성능 👎
- 너무 자주 발생 → 성능에 큰 영향
인덱스 사용
인덱스 생성
인덱스 자동 생성
- 기본 키 설정(Primary Key문법 사용) → 클러스터형 인덱스
- 고유 키 설정(Unique 문법 사용) → 보조 인덱스
그외 인덱스 생성
CREATE INDEX문 사용
CREATE [UNIQUE] INDEX 인덱스_이름
ON 테이블_이름 (열_이름) [ASC | DESC]- UNIQUE
- 중복 안되는 고유 인덱스 만듦, 생략 시 중복 허용
- CREATE UNIQUE로 인덱스 생성 위해
- 기존 입력 값에 중복 있으면 ❌
- 생성 후 입력 데이터와도 중복 ❌
- ASC | DESC
- 인덱스를 오름차순/내림차순으로 만듦
- 기본 : ASC (DESC는 거의 없음)
인덱스 제거
DROP INDEX문 사용
DROP INDEX 인덱스_이름 ON 테이블_이름- CREATE INDEX로 생성된 인덱스 제거 ⭕️
- 자동 생성된 인덱스(기본 키, 고유 키)는 제거 ❌
- ALTER TABLE으로 기본 키/고유 키 제거 후 인덱스 제거 ⭕️
- 제거 시, 보조 인덱스부터 제거하는 것이 좋음
생성 실습
1️⃣ 인덱스 설정 확인
SHOW INDEX FROM member;
2️⃣ 인덱스 크기 확인
SHOW TABLE STATUS LIKE 'member';
- Data_length
- 클러스터형 인덱스/데이터 의 크기를 Byte단위로 표기한 것
- MySQL
- 1페이지 = 16KB
- 클러스터형 인덱스 : 16384/(16*1024) = 1페이지 할당됨
- Index_length
- 보조 인덱스 크기
- 보조 인덱스 없으면 표기 ❌
3️⃣ 단순 보조 인덱스 생성1
CREATE INDEX idx_member_addr
ON member (addr);- 주소(addr) 중복 허용 단순 보조 인덱스 생성
- 인덱스 이름 'idx_member_addr'로 지정

4️⃣ 다시 인덱스 크기 확인
SHOW TABLE STATUS LIKE 'member';
- Index_length가 0이 나옴
* 생성한 인덱스 실제 적용 위해선 ANALYZE TABLE문으로 테이블 분석/처리해주어야 함
5️⃣ ANALYZE TABLE문 실행 후 확인
-
실행
ANALYZE TABLE member; -
결과

-
실행
SHOW TABLE STATUS LIKE 'member'; -
결과

6️⃣ 고유 보조 인덱스 생성
❗️반드시 중복값 없는 열에 고유 보조 인덱스 생성해야 함
❗️고유 보조 인덱스 생성 후 중복된 값 입력 ❌ → 절대로 중복되지 않는 열에만 UNIQUE 옵션으로 인덱스 생성
CREATE UNIQUE INDEX idx_member_mem_name
ON member (mem_name);
7️⃣ 단순 보조 인덱스 생성2
CREATE INDEX idx_member_mem_number
ON member (mem_number);
ANALYZE TABLE member;
8️⃣ 숫자 범위로 조회
SELECT mem_name, mem_number
FROM member
WHERE mem_number >= 7;- 숫자 범위로 조회해도 인덱스 사용 가능
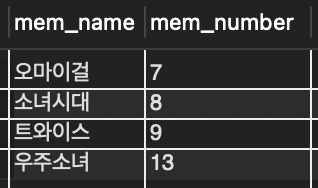
활용 실습
1️⃣ 만든 인덱스 모두 적용
ANALYZE TABLE member;2️⃣ 인덱스 사용 여부 확인
- SELECT문 실행 후 execution plan을 visual explain으로 확인
(현재 나의 상황에서 이 기능이 작동하지 않음...)
제거 실습
1️⃣ 만든 인덱스 이름 확인
SHOW INDEX FROM member;
2️⃣ 보조 인덱스 먼저 제거
DROP INDEX idx_member_mem_name ON member;
DROP INDEX idx_member_addr ON member;
DROP INDEX idx_member_mem_number ON member;3️⃣ 기본 키로 자동 생성된 클러스터형 인덱스 제거
- ALTER TABLE문으로만 제거 가능
- 외래 키 관계가 있을 경우 먼저 제거해야 함
외래 키 이름 알아내기
SELECT table_name, constraint_name
FROM information_schema.referential_constraints
WHERE constraint_schema = 'market_db';- information_schema DB의 referential_constraints 테이블 조회하면 알 수 있음
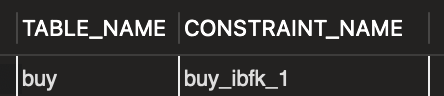
외래 키 제거 후 기본 키 제거
ALTER TABLE buy
DROP FOREIGN KEY buy_ibfk_1;
ALTER TABLE member
DROP PRIMARY KEY;- 결과

✅ 인덱스 효과적으로 사용하는 방법
1️⃣ 인덱스는 열 단위에 생성
→ 하나의 열에 하나의 인덱스 생성 ⭕️
2️⃣ WHERE절에 사용되는 열에 인덱스 생성
→ SELECT문 사용 시, WHERE 절 조건에 해당 열 나와야 인덱스 사용
3️⃣ WHERE절에 사용되더라도 자주 사용해야 효과 ⭕️
→ 자주 사용하지 않는 열에 인덱스 생성하면 INSERT 성능 나쁘게만 함
4️⃣ 데이터 중복 높은 열은 인덱스 만들어도 효과 ❌
→ 열에 들어갈 데이터 종류가 많아야 효과 ⭕️
5️⃣ 클러스터형 인덱스는 테이블당 1개만 생성 ⭕️
→ 데이터 페이지 읽는 수가 보조 인덱스보다 적어 성능 우수
→ 조회 시 가장 많이 사용되는 열에 지정하는 것이 효과적
6️⃣ 사용하지 않는 인덱스 제거
→ 공간 확보 및 데이터 입력 시 발생 부하 감소
