이 글은 MIT 6.006 강좌의 4번째 수업을 바탕으로 작성되었습니다. 이 글에서는 Heap 을 정의하고 관련된 중요 특성과 여러 수행을 알아본다. 이를 바탕으로 heap-sort 의 전략을 이해한다.
Heap 은 기본적으로 array 와 같지만 binary tree 로 거의 동일하게 시각화 될 수 있는 자료구조이다.
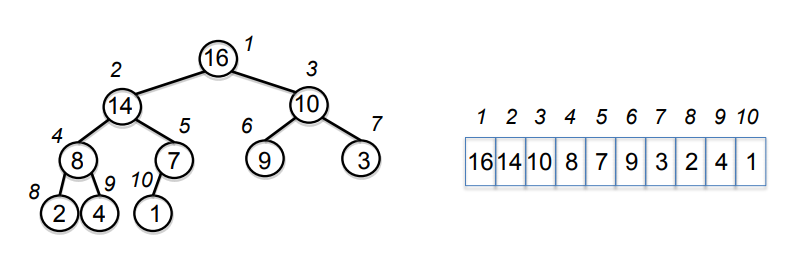
위 그림에서 오른쪽 array 가 왼쪽 binary tree 형태로 시각화 되어있는 것을 확인할 수 있다. 전체 array 와 heap 을 A로 정의하고 i 번째 key 를 A[i]로 정의하자. e.g. A[1] = 16
정의
-
tree 의 root(첫번째 node)는 array 의 첫 번째 key
-
parent(i) = i/2: i번째 node의 부모 node, 엄밀히는 i/2로 나누었을 때, i/2 보다 작은 정수 e.g. if i = 5, parent(i) = 2
-
left(i) = 2i : i번째 node의 왼쪽 child node
-
right(i) = 2i+1 : i번째 node의 오른쪽 child node
node 는 위 그림의 동그라미로 둘러쌓인 숫자들의 위치를 의미한다. 각 node 의 순서 또는 index 는 동그라미 옆 숫자로부터 확인할 수 있다.
Heap 에는 Max Heap Property(특성)와 Min Heap Property 가 있는데 여기에서는 Max Heap Property 위주로 설명한다. Min Heap Property 는 Max Heap Property 에서 부등호 방향이 반대인 것이므로 Max 를 이해하면 Min 을 이해하기는 어렵지 않다.
Max Heap Property
Max Heap Property :한 node 의 key(element, 위 그림에서 동그라미 안에 있는 숫자)가 그 nod 의 children nodes 의 key 들 보다 크거나 같아야 한다 : A[parent(i)] >= A[i]
위 그림의 heap 에서는 모든 node 들에서 Max Heap Property 가 충족되고 있는 것을 확인 할 수 있다. Max Heap Property 를 만족하는 Heap 을 max_heap 이라 한다.
다음은 두 가지 중요한 Heap Operations 이다.
1) buld_max_heap : 정렬되지 않은 array 로부터 max_heap 생성하기
2) max_heapify : binary tree로 시각화된 heap에서 A[i]만 유일하게 max heap property를 위반했다면, 해당 위반을 수정하기
2)를 이해하는 것이 처음에는 까다로울 수 있지만 매우 중요하다. 먼저 tree 와 관련한 몇 가지 개념을 더 살펴보자.
tree
-
node 들을 연결하는 선들은 edge 라고 부른다.
-
한 tree 구조에서 마지막 node 들을 tree의 leaf nodes 또는 leaves(나뭇잎)라고 한다.
-
한 node 의 height(높이)는 그 node에서 한 leaf까지 밑으로 도달하는 가장 긴 경로를 구성하는 edge 의 수로 정의된다.
-
heap 의 height 는 root 의 height 로 정의한다. e.g. n 개의 element 를 가지는 heap 의 height 는 lg(n), lg 는 밑을 2 로 가지는 log, lg(10) = 3.32 -> 3
위 그림의 tree 를 예로 들면 2 번 node(key or element가 14)를 root 로 가지고 8, 9, 10번 node 들을 leaf node 로 가지는 subtree 를 정의할 수 도 있지만, 전체 tree 의 leaf node 인 8번이나 10번 node 도 그 자체로 root 가 되고 root 로만 구성된 subtree 가 될 수 있는 것이다.
subtree 를 이해했으니 위의 2) 수행을 이해하여 보자. 우선 주의해야할 중요한 점은 2)의 수행은 다음을 가정한다.
max_heapify
Assumption of max_heapify : A[i]를 root 로 하는 subtree 를 정의했을 때 A[i]의 left(i) 와 right(i)를 root 로 하는 subtree 들은 모두 max-heaps 이다.
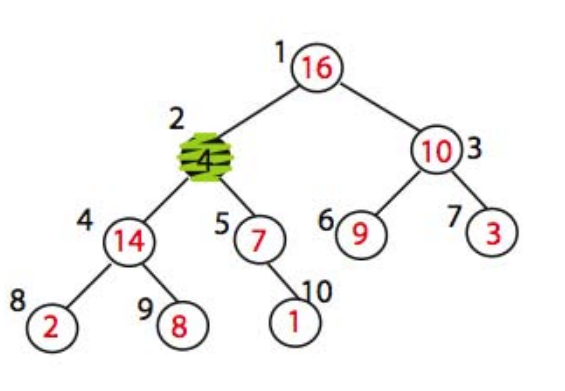
예를 들어서, 위 그림에서 A[2] 에서 max_heapify 를 수행하고자 한다. 이 때, A[2]의 왼쪽 child node 인 A[4]를 root 로 하는 subtree 와 오른쪽 child node 인 A[5]를 root 로 하는 subtree 는 모두 max_heap 을 만족해야한다. 위 그림에서는 이 가정을 만족하고 있는 것을 확인하자.
A[i]만 유일하게 max_heap property 를 위반하고 있다는 것은 다음과 같다.
A[2]는 현재 max_heap 특성을 지키지 못하고 있지만 (자식 node 들의 key 14와 7보다 작은 4의 값을 가지고 있으므로) A[2]의 자식 node 들은 모두 max_heap 특성을 만족하고 있다. 즉, A[2] 를 root 로 하는 subtree 에서 A[2] node 만 유일하게 해당 특성을 충족하지 못하고 있고, 이 것을 수정한다는 것이다.
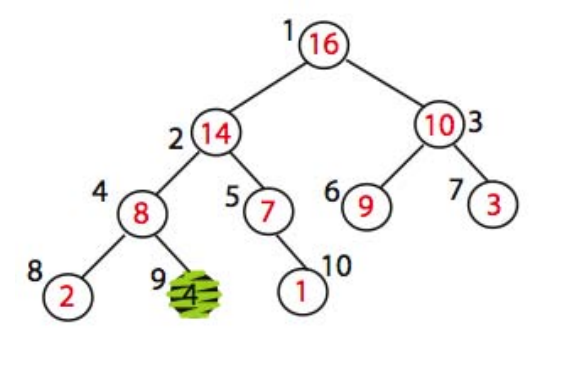
어떻게 수정할까? 방법은 간단하다. 해당 노드의 key 를 아래로 내리면서 자식 node key 의 큰 값과 바꿔주면 된다. 이 때, 자식 node key 중 가장 큰 값과 바꿔주어야 한다. 위 그림에서는 A[2] <=> A[4], A[4] <=> A[9] 를 차례로 수행하면, 최종적인 형태는 다음과 같다.
다음은 max_heapify 의 pseudo code :
Max_Heapify(A, i):
l = left(i)
r = right(i)
if (l <= heap-size(A) and A[l] > A[i])
then largest = l
else
largest = i
if (r <= heap-size(A) and A[r] > A[largest]
then largest = r
if largest != i
then exchange A[i] with A[largest]
Max_Heapify(A, largest)max_heapify 의 time complexity 는 O(lg n) 이다. why?
(Hint: the worst case는 heap tree의 root에서 max_heapify 를 수행하는 것)
max_heapify 를 이해했으니 이제 build_max_heap 의 pseduo code 를 살펴보자.
build_max_heap
Converts A[1...n] to a max heap
Buld_Max_Heap(A):
for i = n/2 downto 1
do Max_Heapify(A, i)형태는 매우 간단하다. 하지만 살펴볼 점들이 몇 가지 있다.
- 왜 n/2에서 loop 를 시작할까?
- build_max_heap 의 time complexity 는 어떻게 될까? 단순 분석으로 n/2 * lg n 을 해서
O(n lg n) 으로 보인다. 과연 그럴까? 결론부터 말하자면 O(n) 이다.
첫 번째로, heap tree 를 자세히 관찰해보면 tree 의 n/2+1, n/2+2, ... ,n 번째 node 들은 모두 leaf nodes 인 것을 알 수 있다. 전체 크기가 10 heap 에서 6, 7, ..., 10 번째 node 들이 leaf node 인 것을 확인해보자.
leaf node 들에 대해서는 max_heapify 를 수행할 필요가 없기 때문에 n/2 부터 시작해서 1 까지만 수행하면 된다.
cf) 증명은 어렵지 않지만 여기에서는 직관적으로만 이해하자.
두 번째 주의점을 주의깊게 이해 해보자. 사실 이를 잘 이해하기 위해서 매우 많은 시간을 쏟았다. 하지만 여기에서는 너무 엄밀하게는 들어가지 않겠다. 추후 글을 보충할때 결함이 있는 증명(공부한 출처에 따르면..)을 글 마지막에 소개하겠다..
핵심적인 관찰은 max_heapify 가 수행되는 node 마다 height 가 다르다는 것이다. 다시 말하면, 해당 node 의 height 에 따라 key 가 자식 node 들의 key 와 교환되는 횟수가 다르다는 말과 같다. height가 낮은 node 일 수록 max_heapify 수행 횟수가 획기적으로 감소한다!
편의를 위해 자식 node 들이 거의 모두 존재하는 binary tree를 가정하자. 그렇다면 leaves 의 숫자는 n/2 에 가깝다. (엄밀히는 celling of (n/2): n/2 보다 큰 정수) 편의상 n/2의 leaves가 있다고 하자. leaf node 들에서는 max_heapify 를 수행하지 않는 것이 자명하다.
맨 왼쪽부터 연속적인 두 개의 leaf node 들은 공통의 parent node를 갖는다. 그렇다면 leaf node 들의 parent node 의 개수는 n/2 * 1/2 = n/4 이다.
이 node들은 height가 1이므로 max_heapify가 수행된다면 단 한번만 swap이 일어난다. 이러한 방식으로 height가 2인 node들은 n/8개, 2번 swap 이 되는 규칙을 갖는다. height가 h(tree의 전체 height)인 node의 개수는 n/2^(h+1) 인데 root node 이므로 당연히 1 개와 같다. max_heapify 가 수행되면 key 는 h 또는 lg(n)번 swap 된다.
element 를 swap 하는 cost 를 상수 c 라고 가정하고 최악의 경우 leaf node들을 제외한 모든 node들에서 max_heapify 를 수행할 때, time complexity of build_max_heap 은 다음의 식을 푸는 것과 같다.
시그마 항에서 분모가 밑을 2 로 갖으면서 지수적으로 커지는 것을 확인하자. 자연스럽게 분자보다 훨씬 빠르게 숫자가 커지므로, tree 가 계속해서 커져도 이 항은 특정 수로 수렴될 것이다. 따라서, time complexity는 O(n)과 같다! (엄밀하게 분석하는 풀이는 다음에 증명과 함께 보충..)
마지막으로 heap_sort 를 알아보자. 앞 개념들을 모두 이해했다면 heap_sort 를 이해하는 것은 어렵지 않다.
Heap-Sort 전략:
step 1) 정렬되지 않은 array 와 build_max_heap 로 max_heap을 만든다.
step 2) 가장 큰 key 를 갖는 node 를 찾는다. 당연히 A[1]
step 3) A[n] 과 A[1] 를 swap 한다. 이제 가장 큰 key 의 node 는 heap의 마지막에 있게 된다!
step 4) heap 에서 n 번째 node 를 제거한다. (heap_size가 줄어듦)
step 5) 새로운 root node 는 max_heap_propert 를 위반할 것이지만, 그의 모든 자식 node 들은 max heap 일 것이다. max_heapify 로 이를 수정
step 6) 2 번째 step 으로 돌아간다. 위 과정을 heap 이 empty 가 될 때까지 반복한다.
Heap-Sort의 Time complexity = O(n + nlogn) = O(nlogn)
Continue...
proof) The number of leaves with height h of a heap is equal to the celling of (n/2) :
flawd proof) The number of nodes at height h of a tree is at most the celling of (n/2^(h+1)) :
