프로세스 주소 공간
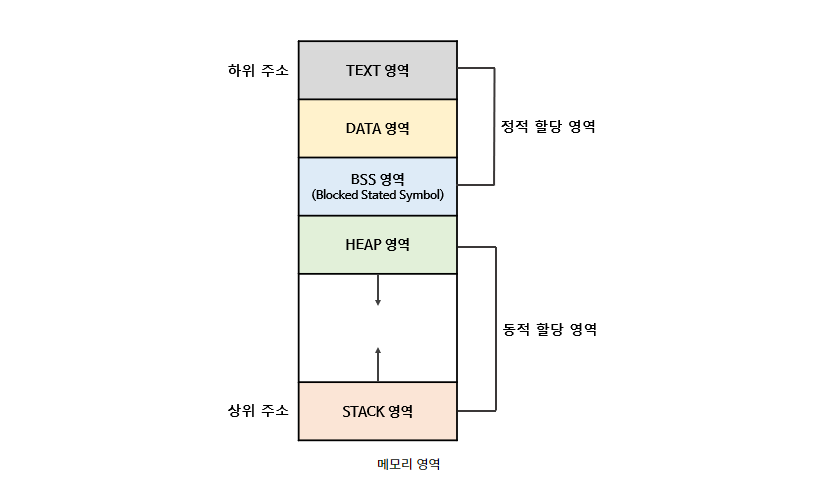
프로그램이 실행되면 프로세스 주소 공간이 메모리에 할당된다.
프로세스 주소 공간에는 아래와 같은 영역이 존재한다.
Code
실행할 프로그램의 소스코드가 들어가는 부분이다. 텍스트 영역이라고도 한다.
컴파일 타임에 결정되고 중간에 코드를 바꿀 수 없도록 Read-Only로 지정되어 있다.
Data
프로그램의 초기값 있는 전역 변수, 배열, 정적 변수가 저장되는 영역이다.
즉 프로그램이 구동되는 동안 항상 접근 가능한 변수가 저장되는 영역이다.
프로그램의 시작과 함께 할당되며 프로그램이 종료되면 소멸한다.
실행 도중 전역변수가 변경될 수 있으므로 Read-Write로 지정되어 있다.
BSS(Block Stated Symbol)
초기값 없는 전역변수, 배열, 정적 변수가 저장되는 영역이다.
즉 초기화 된 데이터는 Data영역에 저장되고, 초기화 되지 않은 데이터는 BSS에 저장된다.
초기화되지 않은 변수는 프로그램이 실행할 때 영역만 잡아주면 되지만 초기화 된 변수는 그 값도 저장하고 있어야 하기 때문이다.
Stack
함수의 호출과 관계있는 지역 변수와 매개변수가 저장되는 영역이다.
함수의 호출과 함께 할당되며, 함수의 호출이 완료되면 소멸한다.
메모리의 높은 주소에서 낮은 주소의 방향으로 할당된다.
컴파일 타임에 크기가 결정되기 때문에 무한히 할당할 수 없다. 따라서 재귀함수가 너무 깊게 호출되거나 함수가 지역 변수를 너무 많이 가지고 있어 stack영역을 초과하면 stack overflow 에러가 발생한다.
Heap
런타임에 크기가 결정되는 메모리 영역이다.
사용자에 의해 메모리 공간이 동적으로 할당되고 해제된다
메모리의 낮은 주소에서 높은 주소의 방향으로 할당 된다.
heap과 stack영역은 사실 같은 공간을 공유한다.
heap이 메모리 위쪽 주소부터 할당되면 stack은 아래쪽부터 할당되는 식이다. 그래서 각 영역이 상대 공간을 침범하는 일이 발생할 수 있는데 이를 각각 heap overflow, stack overflow 라고 칭한다.
Code 부분을 따로 둔 이유 ?
최대한 데이터를 공유하여 메모리 사용량을 줄이기 위함이다.
code는 같은 프로그램 자체에서는 모두 같은 내용이기 때문에 따로 관리하여 공유한다.
Stack과 Data부분을 나눈 이유?
Stack 은 선입선출의 구조를 가지고 있어 데이터를 임의로 꺼낼 수 없다.
하지만 전역 변수는 어떤 함수에서도 접근할 수 있어야 하기 때문에 Data로 따로 관리해준다.
Reference
https://dar0m.tistory.com/258
