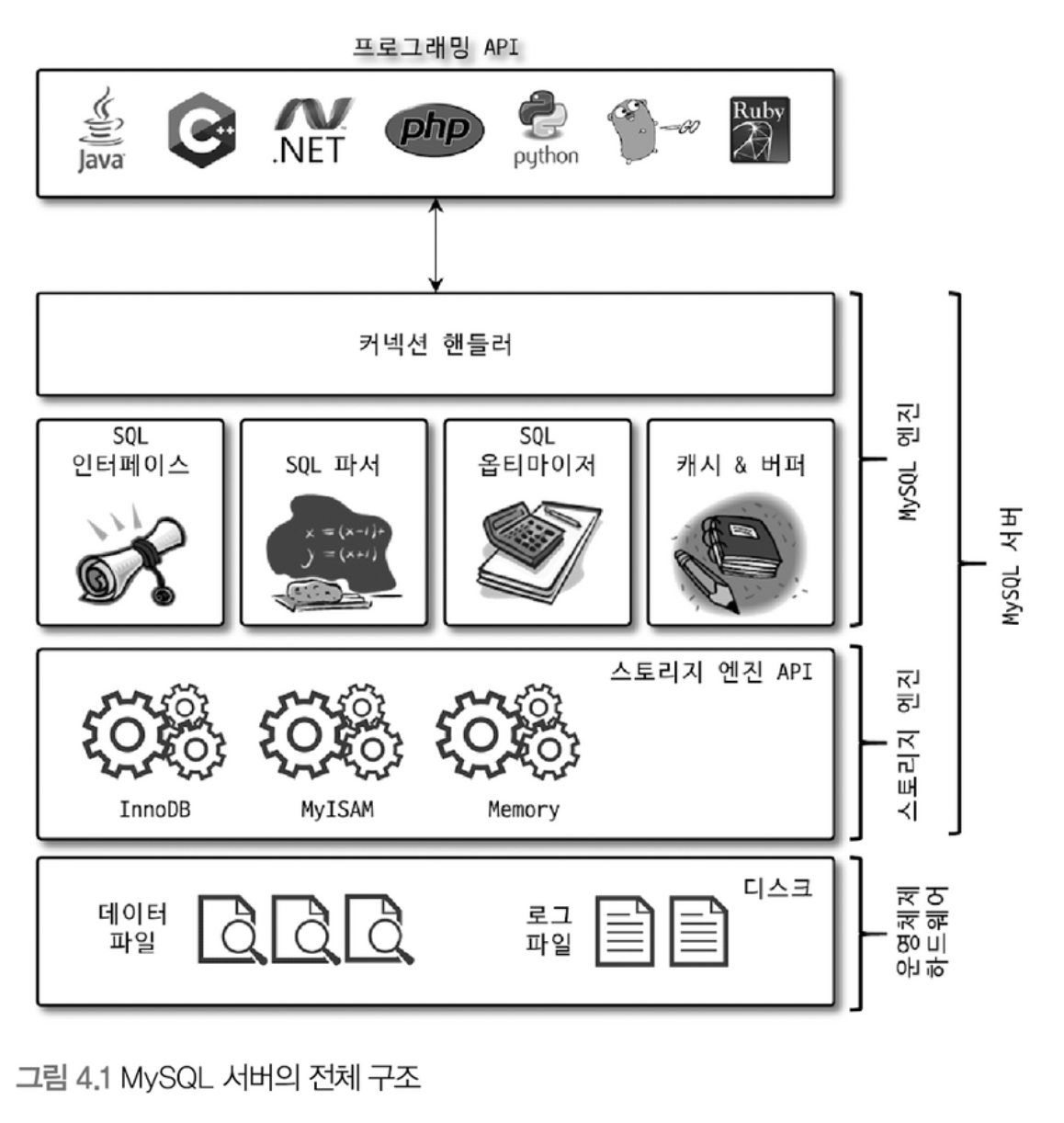
- MySQL은 크게…
- MySQL 엔진: 요청된 SQL 문장을 분석/최적화 하고, 연결을 관리함.
- 커넥션 핸들러: 클라이언트로부터의 접속 및 쿼리 요청
- SQL 파서 및 전처리기
- 옵티마이저: 쿼리의 최적화된 실행을 위한 최적화기
- 스토리지 엔진: 실제 데이터를 스토리지에 저장하고, 읽어옴.
-
MySQL 엔진은 하나지만, 스토리지 엔진은 필요에 따라 여러 가지를 바꿔 쓸 수 있음.
-
각 스토리지 엔진은 성능 향상을 위해 키 캐시나 버퍼 풀 같은 기능을 내장함.
CREATE TABLE test_table (fd1 INT, fd2 INT) ENGINE=INNODB; -
MySQL 엔진의 쿼리 실행기에서 실 데이터를 읽어야 할 땐, 핸들러 API를 이용해 스토리지 엔진에 실제 I/O를 요청함.
-
- 이렇게 둘을 합쳐서 그냥 MySQL로 뭉뜽그려 부름
- MySQL 엔진: 요청된 SQL 문장을 분석/최적화 하고, 연결을 관리함.
MySQL 엔진 아키텍쳐
MySQL 전체 구조
MySQL 스레딩 구조
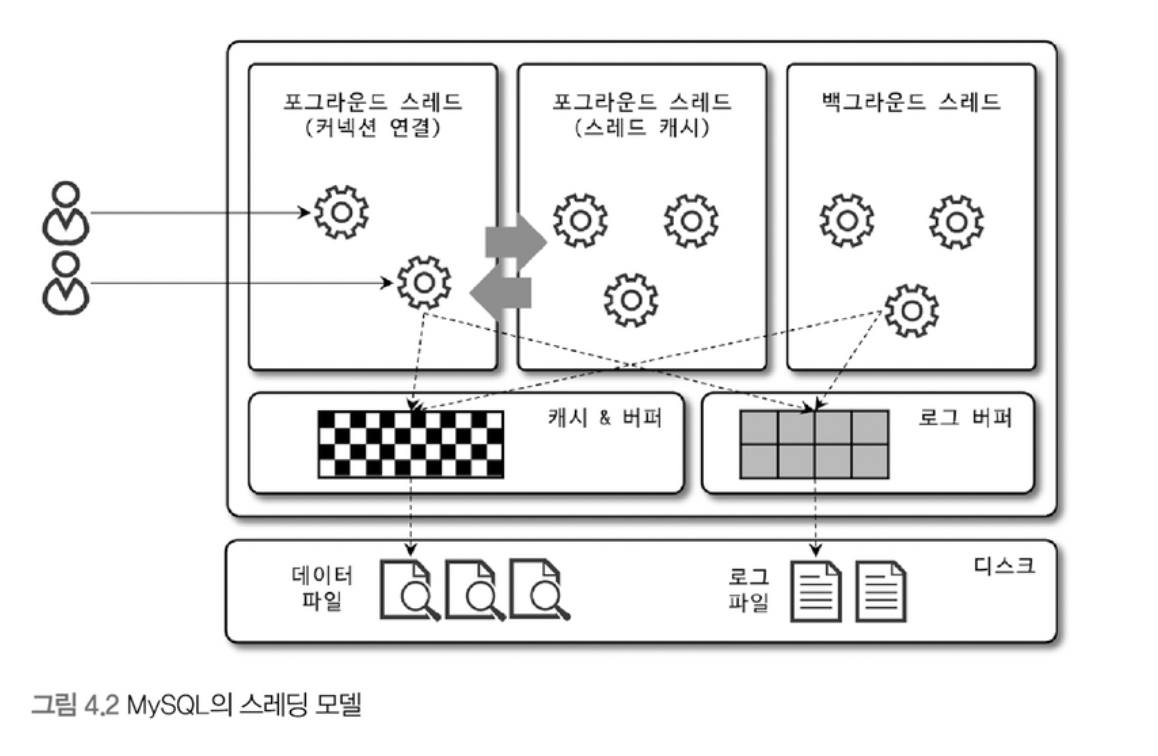
- MySQL 서버는 프로세스 기반이 아니라 스레드 기반으로 동작하며, 포/백그라운드 스레드로 구분된다.
- 다음과 같은 쿼리를 통해 스레드의 동작을 확인할 수 있다.
SELECT thread_id, name, type, processlist_user, processlist_host
FROM performance_schema.threads ORDER BY type, thread_id;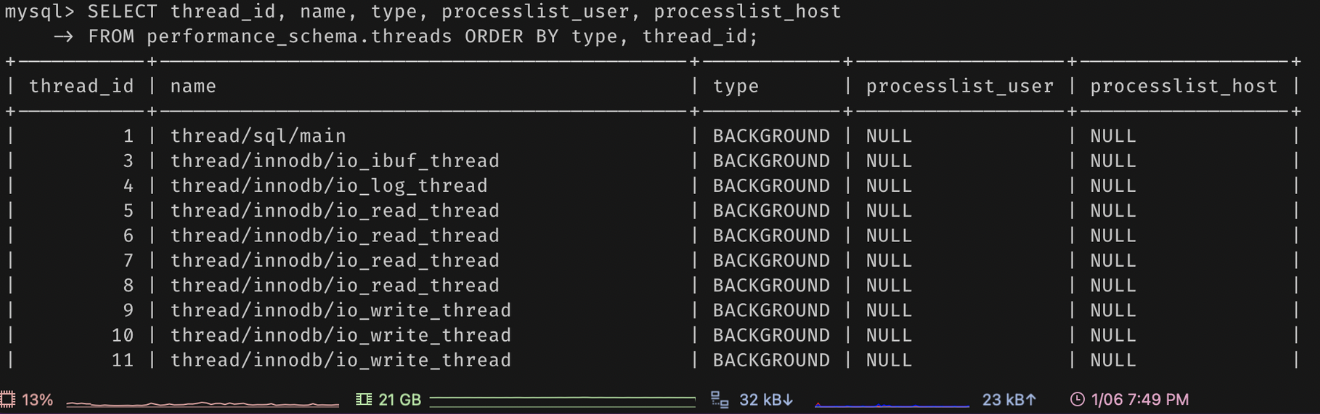
- 동일한 이름의 스레드가 2개 이상 있다면, 서버의 설정하에 여러 스레드가 병렬 처리하는 것을 의미함.
- foreground 스레드의 최소 수는 MySQL 서버에 접속된 클라이언트의 수이며, 주로 쿼리 문장을 처리함.
- 커넥션을 종료한다고 바로 스레드가 사라지는 것은 아니며, 스레드 캐시에 최근에 연결이 종료된 몇개의 스레드를 위치시킴.
- 데이터를 버퍼나 캐시로부터 가져오고, 없다면 직접 디스크의 데이터나 인덱스 파일에서 읽어옴.
- MyISAM일 경우 디스크 쓰기 작업까지 foreground가 처리하나, InnoDB는 이를 백그라운드로 위임시킴.
- background 스레드의 경우, (InnoDB의 경우) 다양한 작업들이 백그라운드로 처리된다.
- 이 중 Log Thread, Write Thread (버퍼의 데이터를 디스크에 씀) 는 정말 중요함.
- 사용자의 요청을 처리할 때, 쓰기 작업은 지연 처리가 가능하나 읽기는 불가능함.
- 따라서, 일반적으로 쓰기 연산은 버퍼링하여 일괄 처리를 진행하고, InnoDB 또한 그러함.
- 다만 MyISAM은 foreground 스레드가 쓰기 작업까지 함께 처리함.
메모리 할당 및 사용 구조

- MySQL 에서 사용되는 메모리 공간은 크게 글로벌 메모리 영역과 로컬 메모리 영역으로 구분할 수 있음.
- 글로벌 메모리 영역
- MySQL 서버가 시작되면서 운영체제로부터 할당됨.
- 필요에 따라 2개 이상의 메모리 공간을 할당받을 수 있지만, 일반적으로는 하나만 할당됨.
- 글로벌 영역이 많더라도 모든 스레드에 의해 공유됨.
- 대표적인 영역은 다음과 같음.
- 테이블 캐시
- InnoDB 버퍼 풀
- InnoDB 어댑티브 해시 인덱스
- InnoDB 리두 로그 버퍼
- 로컬 메모리 영역
- 세션 메모리 영역이라고 하며, 서버상에서 존재하는 클라이언트 스레드가 쿼리를 처리하는데 사용함.
- 클라이언트가 MySQL 서버에 접속하면 MySQL 서버에서는 클라이언트 커넷션으로부터의 요청을 처리하기 위해 스레드를 할당함.
- 절대 공유되어 사용되지 않음.
- 메모리 공간을 크게 신경 쓰지 않고 설정됨.
- 쿼리의 용도에 따라 필요할 때만 할당되며, 상황에 따라 용량이 아예 할당되지 않을 수도 있음.
- 대표적인 영역은 다음과 같음
- 정렬 버퍼
- 조인 버퍼
- 바이너리 로그 캐시
- 네트워크 버퍼
플러그인 스토리지 엔진 모델

- 플러그인 모델을 갖고 있으며, 인증 및 검색어 파서등이 플러그인 형태로 개발되어 있다.
- MySQL에서 쿼리가 실행되는 과정을 정리하면 대부분의 작업이 MySQL 엔진에서 처리되며, 마지막 데이터 읽기/쓰기 작업만 스토리지 엔진에 의해 처리됨.
- SQL 파서 → SQL 옵티마이저 → SQL 실행기 순으로 MySQL 엔진에서 처리되고, 이후 데이터 읽기/쓰기만 스토리지 엔진에서 처리된다고 보면 됨.
- 대부분의 데이터 읽기/쓰기 작업은 대부분 1건의 레코드 단위로 처리됨.
- 스토리지 엔진을 변경한다고 해서 작업의 결과물이 바뀌는 것은 아니며, 처리 방법의 차이만 있을 뿐임.
- 실질적으로 복잡한 연산인 GROUP BY나 ORDER BY 등의 처리는 MySQL 엔진의 처리 영역인 쿼리 실행기에서 처리됨.
- 일단 여기선 MySQL 엔진 영역과 스토리지 엔진 영역에서 어떤 일이 진행되는지 간략하게만 이해하자.
SHOW ENGINE을 사용하면, 현재 설치된 서버가 지원하는 스토리지 엔진을 확인할 수 있다.
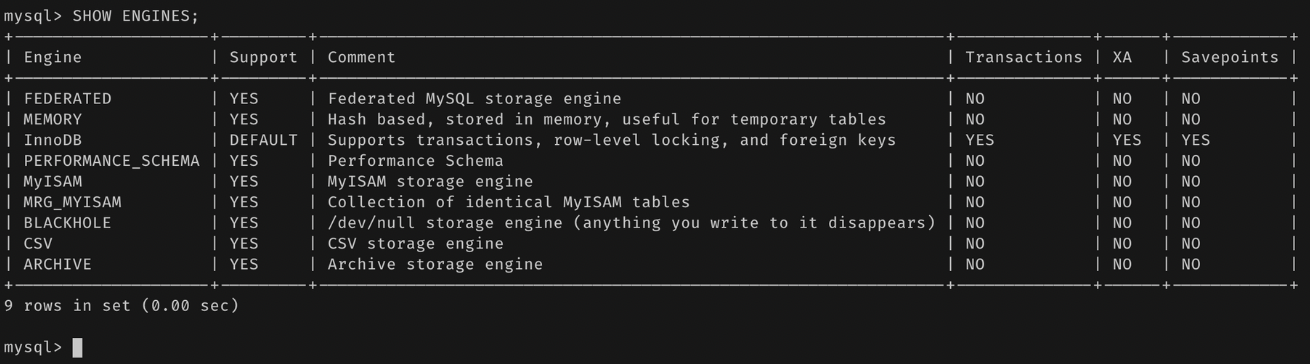
- 여기선 다 YES 아니면 DEFAULT 지만…
- NO: 현재 서버에 포함되어 있지 않음
- DISABLED: 현재 서버에는 포함되어 있지만 파라미터에 의해 비활성화 됨.
- 포함되지 않은 엔진을 사용하려면 재컴파일 해야 함.
- 하지만 서버가 잘 준비되어 있다면, 플러그인 형태의 스토리지 엔진을 받아 끼워넣을 수 있다.
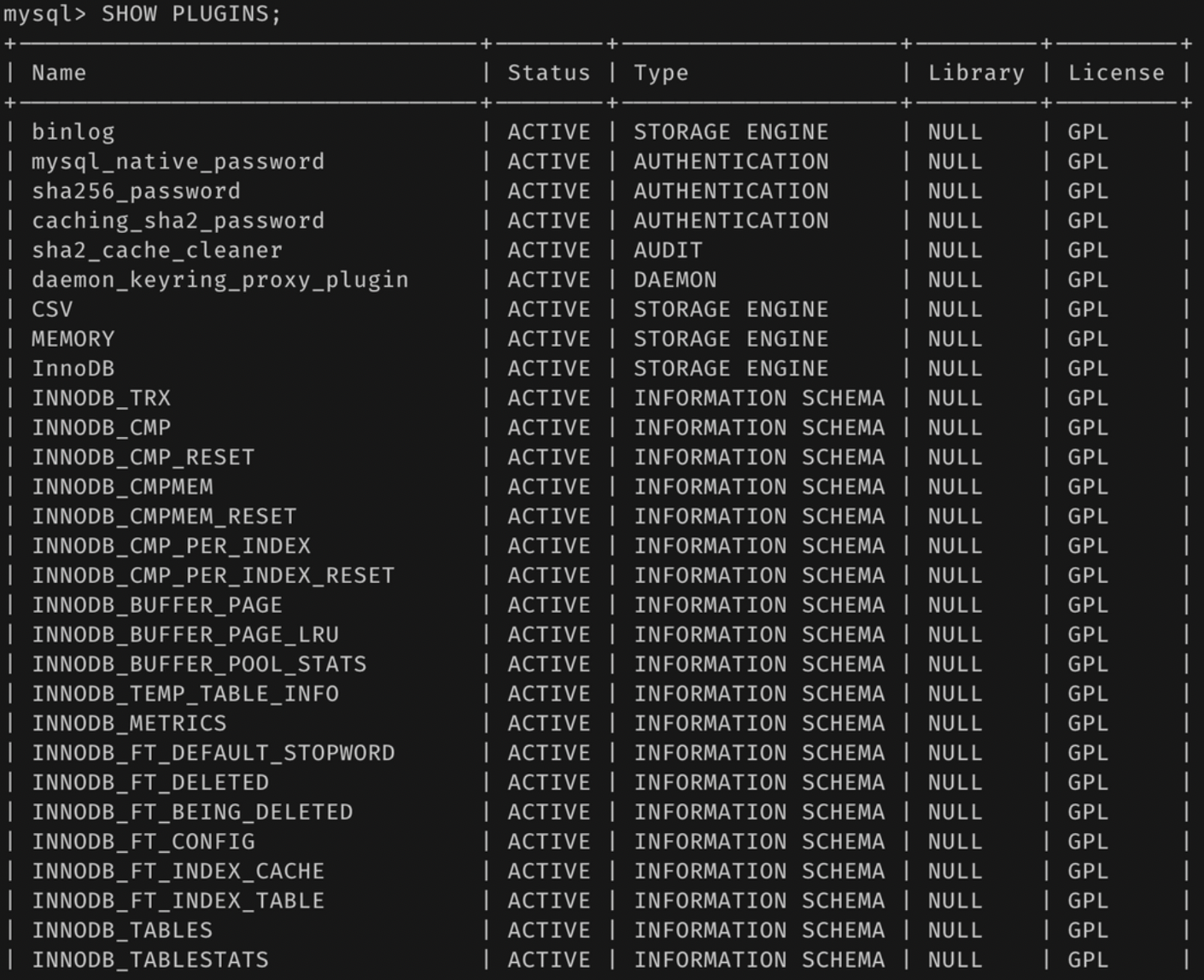
- 플러그인에는 스토리지 엔진 뿐만 아니라 다양한 기능들을 제공하고 있음.
컴포넌트
- 플러그인 구조는 좋지만, 일부 단점이 있음.
- 플러그인은 오직 MySQL 서버와만 소통 가능하며, 플러그인끼리는 통신할 수 없음
- 플러그인은 MySQL 서버의 변수나 함수를 직접 호출하기 때문에 안전하지 않음 (캡슐화 X)
- 플러그인의 상호 의존 관계 설정이 불가능하여 초기화가 어려움
- 8.0 부터 컴포넌트 구조가 나오면서, 앞에서 설명한 비밀번호 검증 기능등이 컴포넌트로 변경됨.
쿼리 실행 구조
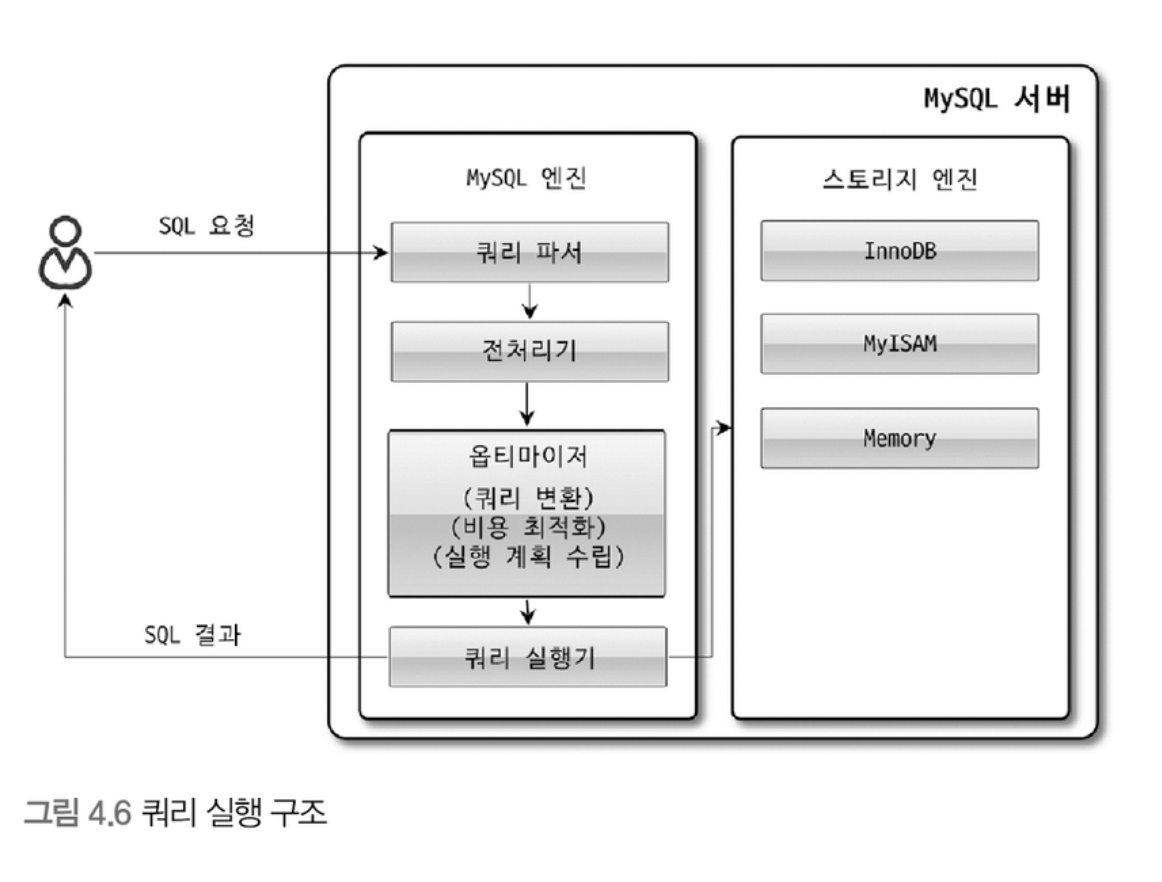
- 쿼리 파서: 사용자 요청으로 들어온 쿼리 문장을 토큰으로 분리해 트리 형태의 구조로 만들어냄.
- 기본 문법 오류는 이 단계에서 발견되어 오류 메시지를 전달함.
- 전처리기: 파서 과정에서 만들어진 파서 트리를 기반으로 구조적인 문제가 있는지 확인함.
- 또한, 토큰을 실제 이름 및 개체등과 매핑해 객체의 존재 여부와 접근 권한등을 확인함.
- 옵티마이저: 쿼리 문장을 저렴한 비용으로 가장 빠르게 처리할 수 있도록 결정함.
- 이 책의 상당수 내용은 옵티마이저와 관련되어 있음.
- 실행 엔진: 실제 동작과 관련 있음.
- 예를 들어, 옵티마이저가 GROUP BY를 처리하기 위해 임시 테이블을 사용한다면,
- 실행 엔진이 핸들러에게 임시 테이블을 만들라고 요청
- 실행 엔진은 그와 동시에 WHERE 절과 일치하는 레코드를 가져오라고 핸들러에게 요청
- 읽어온 레코드들을 1번에서 준비한 테이블에 저장하라고 핸들러에게 요청
- 데이터가 준비된 임시 테이블에서 필요한 방식으로 데이터를 읽어오라고 핸들러에게 요청
- 최종적으로 실행 엔진은 결과를 사용자나 다른 모듈로 넘김
- 예를 들어, 옵티마이저가 GROUP BY를 처리하기 위해 임시 테이블을 사용한다면,
- 핸들러: MySQL 서버의 가장 밑단에서 MySQL 실행 엔진의 요청에 따라 데이터를 디스크로 저장하고 읽어 오는 역할을 함 → 사실상 스토리지 엔진!
스레드 풀
- 정작 커뮤니티 에디션엔 없음
- 일반적인 서버에서의 스레드 풀과 유사함
트랜잭션 지원 메타데이터
- 데이터베이스 서버에서 테이블의 구조 정보와 Stored Program 등의 정보를 데이터 딕셔너리/메타데이터라고 함.
- 5.7 까지는 구조를 FRM 파일에 저장하고 일부 Stored Program 의 정보 또한 파일로 저장함.
- 다만, 이런 구조는 트랜잭션을 지원하지 않았기에 생성 도중에 문제가 생기면 정합성에 문제가 생김
- 8.0 부터는 테이블의 구조 정보나 Stored Program의 코드 관련 정보를 모두 InnoDB의 테이블에 저장하도록 개선됨.
- 시스템 테이블과 데이터 딕셔너리 정보를 모두 모아서 mysql 이라는 이름의 DB에 저장하며, 이 DB의 정보는 mysql.ibd 라는 이름의 테이블 스페이스에 저장됨.
- 그렇기에 해당 파일은 잘 관리해야 함!
- 참고로, 데이터 딕셔너리는 저장은 되지만 사용자의 임의 수정을 막기 위해 테이블을 보여주지 않으며, 대신 information_schema DB의 TABLES/COLUMNS 등과 같은 뷰를 통해서 조회할 수 있도록 함.

- 또한 테이블에 대해 접근을 시도하면 권한이 없다고 뜸
- 물론 InnoDB를 사용한다고 해도, 다른 스토리지 엔진의 메타 정보는 다른데다 저장해야 함.
- MySQL 서버는 InnoDB 엔진 이외의 스토리지 엔진을 사용하는 테이블을 위해 SDI (Serialized Dictionary Information) 파일을 사용하는데, 이는 기존의 FRM 파일과 동일한 역할을 함.
InnoDB 스토리지 엔진 아키텍쳐
- InnoDB는 MySQL에서 사용할 수 있는 스토리지 엔진 중 거의 유일하게 레코드 기반의 잠금을 제공함.
- 따라서, 높은 동시성 처리가 가능함.
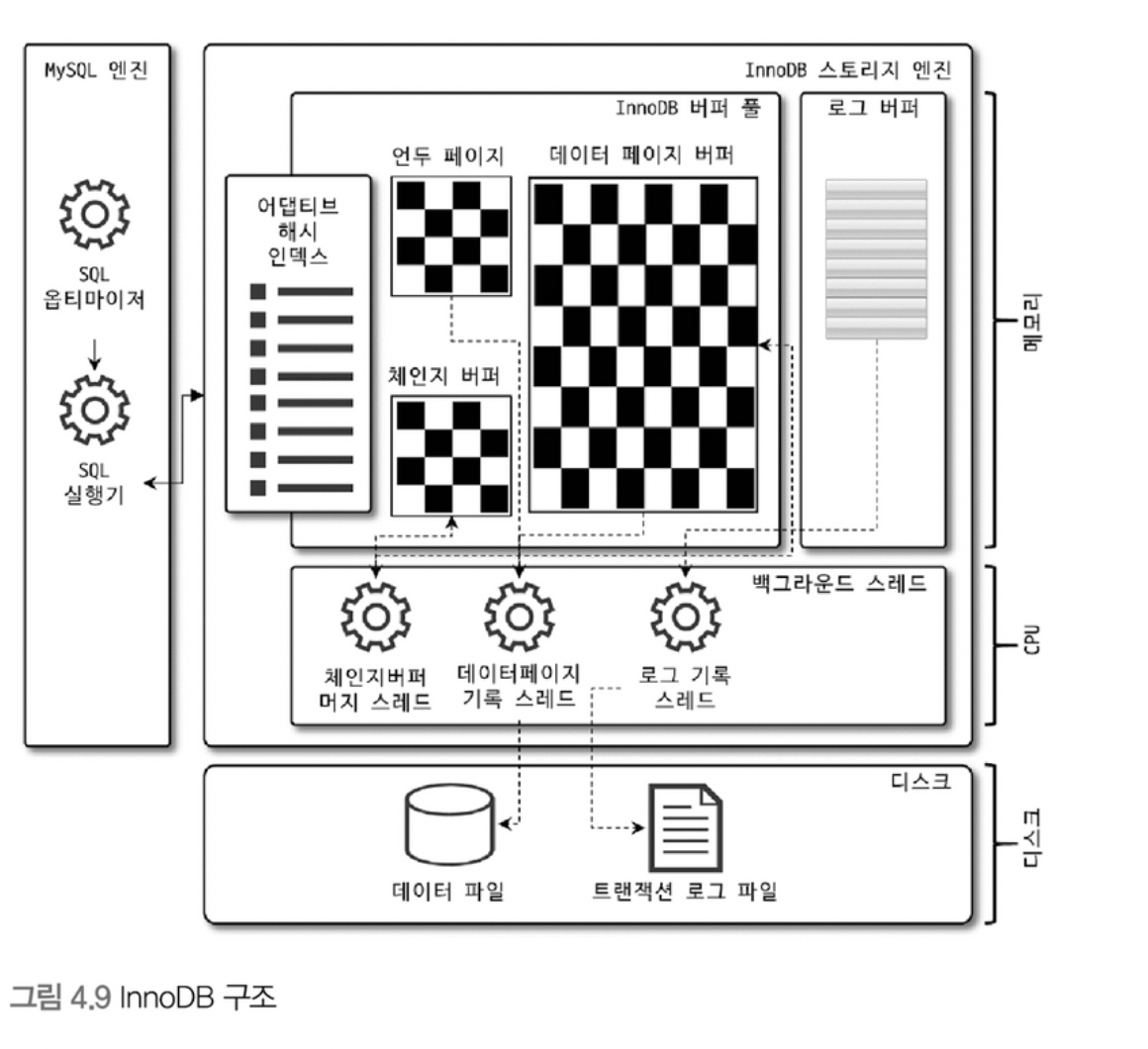
Primary 키에 의한 클러스터링
- InnoDB의 모든 테이블은 기본적으로 프라이머리 키를 기준으로 클러스터링 되어 있음.
- 프라이머리 키를 기준으로 순서대로 디스크에 저장됨.
- 모든 세컨더리 인덱스는 프라이머리 키의 값을 논리적인 주소로 사용함.
- 그러다보니, 프라이머리 키를 이용한 Range Scan 은 빠르게 처리 될 수 있음.
- MyISAM 스토리지 엔진에서는 클러스터링 키를 지원하지 않음.
- 따라서, 프라이머리 키와 세컨더리 인덱스는 구조적으로 차이가 없음.
- 클러스터링?
- 어떤 정해진 컬럼 값을 기준으로 동일한 값을 가진 하나 이상의 테이블의 레코드를 같은 장소에 저장하는 물리적인 기법
- 즉, 여기서는 PK 값에 의해 특정 레코드의 물리적인 저장 위치가 정해진다고 보면 됨.
- B-Tree 구조를 채택하지 않고, 루트 노드 - 리프 노드 구조로만 구성되어 있음.
- PK 값을 수정하게 되면 데이터의 물리적인 위치가 바뀌게 되므로, 절대 그러지 말자!
- 정확히는 DELETE 후 INSERT 진행함.
외래 키 지원
- 놀랍게도 외래 키에 대한 지원은 스토리지 엔진 레벨에서 진행 됨.
- 즉, MyISAM 이나 다른 스토리지 엔진에는 지원하지 않을 수도 있음!
- 다만 InnoDB 기준, 외래 키는 부모 및 자식 테이블 모두 해당 칼럼에 인덱스 생성이 필요하고, 변경 과정에서 양쪽을 모두 확인하는 과정을 거치기 때문에 여러 테이블에 Lock이 전파될 위험이 있음.
- 만약 시스템 적으로 긴급한 조치가 필요할 경우,
foreign_key_checks라는 시스템 변수를 OFF로 설정하여 체크 작업을 멈출 수 있음.- 이런 처리를 할 경우 부가적인 체크가 필요하지 않기 때문에 빠르게 처리할 수 있으나, 부모 및 자식 테이블의 정합성 또한 수동으로 처리해야 한다.
- ON DELETE CASCADE 또한 해제되기 때문에, 더더욱 수동으로 관리해야 함.
- 만약 시스템 적으로 긴급한 조치가 필요할 경우,
MVCC (Multi-Version Concurrent Control)
- MVCC의 가장 큰 목적은 Lock을 사용하지 않는 일관된 읽기를 제공하는 것.
- InnoDB는 Undo Log를 이용해 이 기능을 구현함.
- READ COMMITED 상태의 Isolation Level을 보인다고 가정해보자.
- 이게 디폴트
- UPDATE 문장이 실행되면 커밋 실행 여부와 관계없이 InnoDB의 버퍼 풀은 새로운 값으로 업데이트 됨.

- 다만, 디스크의 데이터 파일에는 새로운 값으로 업데이트가 될 수도 있고… 아닐 수도 있고…
- 이 상황에서, (즉 COMMIT/ROLLBACK 이 되지 않은 상태) 다른 사용자가 조회를 하려고 한다면…
- 결과적으로는 Isolation Level 에 따라 다름
- READ_UNCOMMITED 라면 InnoDB의 버퍼 풀이 갖고 있는 데이터를 반환함.
- 이외의 경우엔 Undo 영역에 있는 값을 반환함.
- 현재는 데이터가 1개지만, 트랜잭션이 길어지면 Undo 영역이 갖고 있는 데이터가 점점 길어지게 됨.
- 용량 문제가 발생할 수도!
- 참고로, COMMIT 이 된다고 Undo 영역의 데이터가 바로 삭제되는것은 아니고, 해당 영역이 필요한 트랜잭션이 더 없을 때 삭제 됨.
Non Locking Consistent Read
- InnoDB는 MVCC를 활용하여 Lock을 사용하지 않고 읽기 작업을 수행함.
- 격리 수준이 SERIALIZABLE이 아니면 SELECT의 경우 다른 트랜잭션과 별개로 Lock을 기다리지 않음.
- 이 것을 Non Locking Consistent Read라고 함.
- InnoDB에서는 Undo 영역을 사용
- 트랜잭션이 너무 오래 활성화 되어 있다면 서버가 느려지거나 문제가 발생할 수 있으므로, 트랜잭션이 실행되었다면 커밋이나 롤백을 빨리 하는게 좋음.
자동 데드락 감지
- InnoDB는 Lock 대기 목록을 Wait-For List로 관리함.
- 데드락 감지 스레드가 주기적으로 이 그래프를 검사하고, Deadlock에 빠지게 되면 하나를 강제 종료함.
- Undo 로그의 양이 적은 트랜잭션이 대부분 그 대상이 됨.
- 일반적으로는 성능적인 이슈가 발생하지 않으나, 동시 처리 스레드가 매우 많아지거나 각 트랜잭션이 가진 Lock의 개수가 많아지게 되면 데드락 감지 스레드의 속도가 느려짐.
- 이런 상황에선, innodb_deadlock_detect 시스템 변수의 값을 OFF로 설정하여 해당 스레드를 꺼버릴 수 있다.
- 다만 이 경우, 데드락이 발생하면 무한 대기에 놓이게 된다.
- innodb_lock_wait_timeout 시스템 변수의 값을 수정하여 잠금을 획득하지 못한 트랜잭션을 일정 시간 후에 종료시키는 방법을 사용할 수 있다.
- 기본값은 50초이지만, innodb_deadlock_detect를 끈다면 낮추는걸 권장함.
자동화된 장애 복구
- 일반적으로 InnoDB는 데이터 파일이 손상되거나 서버가 시작되지 못하는 경우는 거의 없다.
- 하지만 HW 이슈로 자동으로 복구하지 못하는 경우도 있음.
- 일반적으로 부팅과 동시에 자동 복구를 시도하나, 이에 실패하게 되면 서버가 종료된다.
- 이런 경우에는 innodb_force_recovery 시스템 변수를 설정하여 검사 과정을 선별적으로 진행하도록 할 수 있다.
InnoDB 버퍼 풀
- InnoDB 스토리지 엔진의 가장 핵심적인 부분으로, 디스크의 데이터 파일이나 인덱스 정보를 메모리에 캐시해 두는 곳
- 쓰기 작업에 대한 버퍼 역할도 함
- 일반적인 애플리케이션에서, 데이터를 변경하는 쿼리는 데이터 파일의 흩어져있는 레코드의 값을 변경하므로 Random Disk I/O를 발생시킴
- 버퍼풀이 이러한 데이터를 모아서 처리하면 그 횟수를 줄일 수 있음.
- 버퍼 풀의 크기는 OS와 스레드의 메모리를 고려하여 설정해야 함.
- 레코드 버퍼라고 하여 클라이언트 세션에서 레코드를 읽고 쓸 때 버퍼로 사용하는 공간이 있는데, 커넥션과 테이블의 수가 많아지면 해당 공간이 많이 필요하게 될 수 있음.
- 다만, 레코드 버퍼 공간은 별도로 설정할 수 없으므로, 정확한 메모리 공간의 크기를 알 수 없다.
- MySQL 5.7 부터, InnoDB 버퍼 풀의 크기를 동적으로 조정할 수 있음.
- innodb_buffer_pool_size 시스템 변수로 크기를 설정할 수 있으며, 동적으로 버퍼풀의 크기를 확장할 수 있음.
- 다만 크리티컬한 변경이므로, 한가할 때 변경하거나 그냥 하지 말자… (특히 줄이는 작업은 더더욱)
- 기존에는 Semaphore를 사용하여 버퍼 풀의 Lock을 관리했는데, 현재는 하나의 큰 버퍼 풀을 여러 개로 쪼개면서 각 Semaphore에 대한 경쟁을 줄였다.
버퍼 풀의 구조
- 간단하게 말해서 페이징 구조를 갖고 있다고 생각하면 됨.
- 페이지 조각을 관리하기 위해서, LRU 리스트, Flush 리스트, Free 리스트를 관리함.
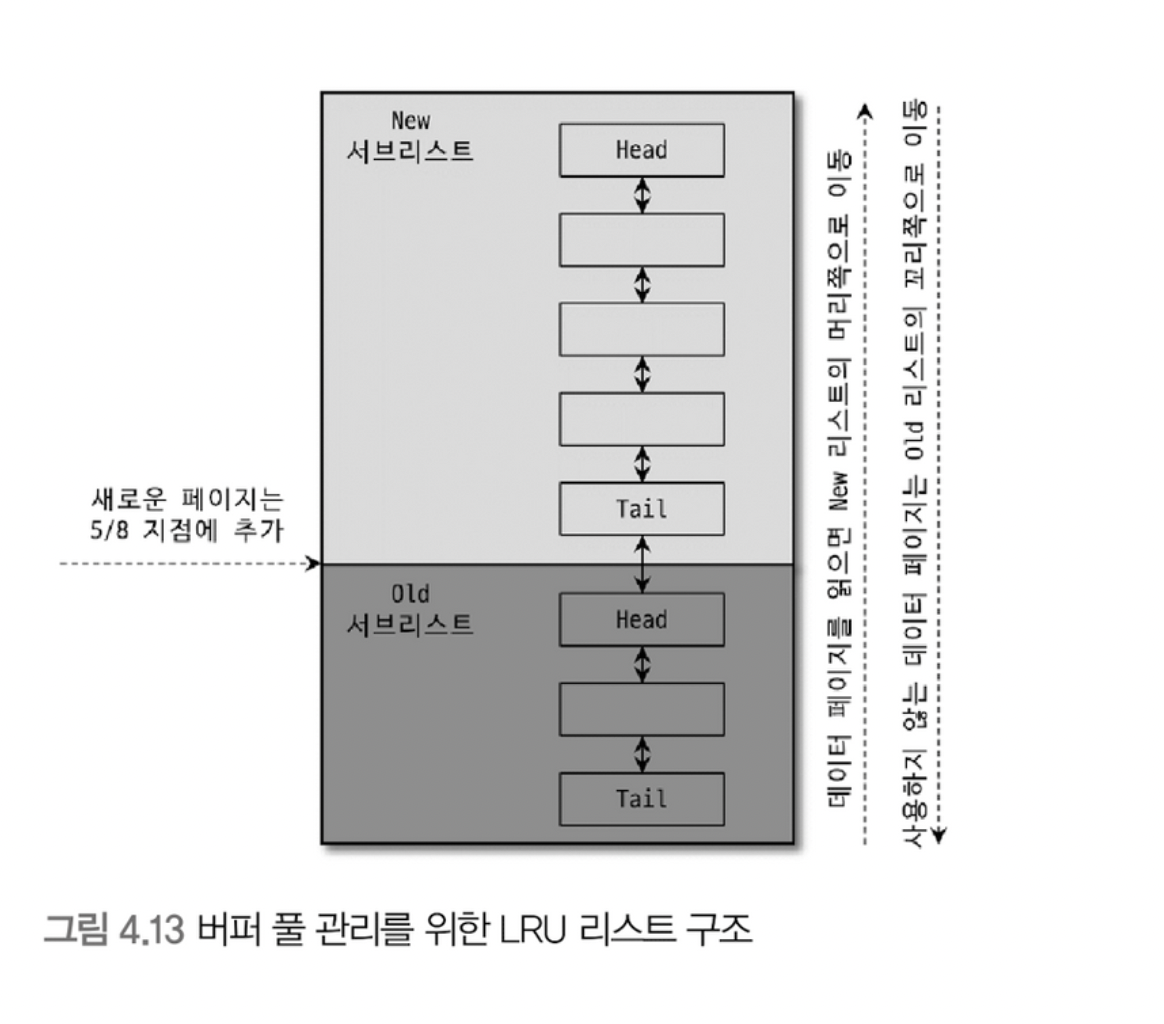
- 과정은 다음과 같음
- 필요한 레코드가 저장된 데이터 페이지가 버퍼 풀에 있는지 검사
- InnoDB Adaptive Hash Index를 사용
- 해당 테이블의 인덱스를 이용해 버퍼 풀에서 페이지 검색
- 버퍼 풀에 데이터 페이지가 있다면 해당 페이지의 포인터를 MRU 방향으로 승급
- 디스크에서 필요한 데이터 페이지를 버퍼 풀에 적재하고, 적재된 페이지에 대한 포인터를 LRU 헤더에 추가
- LRU에 적재된 데이터 페이지가 실제로 읽히면 MRU 헤더로 이동
- 버퍼 풀에 상주하는 데이터 페이지는 사용자 쿼리가 얼마나 최근에 접근했냐에 따라 Age가 부여되고, 쿼리에서 오랫동안 사용되지 않으면 데이터 페이지에 부여된 나이가 오래되고 버퍼 풀에서 페이지가 제거 됨
- 필요한 데이터가 자주 접근되면 해당 페이지의 인덱스 키를 Adaptive Hash Index에 추가
- 필요한 레코드가 저장된 데이터 페이지가 버퍼 풀에 있는지 검사
- Flush 리스트는 디스크로 동기화되지 않은 데이터 페이지 (Dirty Page)의 변경 시점 기준의 페이지 목록을 관리함.
- 데이터가 변경되면 InnoDB는 변경 내용을 Redo 로그에 기록하고 버퍼 풀의 데이터 페이지에도 변경 내용을 반영함.
- 체크포인트를 발동시켜, 디스크의 Redo 로그와 데이터 페이지의 상태를 동기화 시킴
버퍼 풀과 Redo 로그
- InnoDB의 버퍼 풀은 서버의 메모리가 허용하는 만큼 크게 할 수록 쿼리의 성능이 올라감
- 하지만 버퍼 풀의 기능은 데이터 캐시와 쓰기 버퍼링이 있는 만큼, 크기를 올리는 것은 전자의 성능만 올라감 → 쓰기 버퍼링의 성능을 올리려면 Redo 로그를 이해할 필요가 있음.

- 버퍼 풀의 데이터는…
- 디스크에서 읽은 상태로 변경되지 않은 데이터인 Clean Page
- INSERT, UPDATE, DELETE 명령으로 변경된 데이터인 Dirty Page
- 하지만 Dirty Page는 버퍼 풀에 무한정 머무를 수 없음.
- Redo 로그는 1개 이상의 고정 크기 파일을 연결하여 순환 고리처럼 사용하고, 결국 언젠가는 기존 로그가 덮어씌어짐.
- 그러다보니, 재사용 가능한 공간과 그렇지 않은 공간을 표시해야 할 필요가 있음.
- 재사용 불가능한 공간을 Active Redo Log 라고 함.
- 예를 들어 위에 있는 그림에서 화살표를 갖는 엔트리들
- 재사용 되어도 매번 기록될 때 마다 로그 포지션을 증가된 값을 갖는데, 이를 LSN (Log Sequence Number) 라고 함.
- InnoDB는 주기적으로 체크포인트 이벤트를 발생시켜 Redo 로그와 Dirty Page를 디스크로 동기화 하는데, 이때 가장 최근 체크포인트 지점의 LSN이 활성 Redo 로그 공간의 시작점이 된다고 할 수 있음.
- 체크포인트가 발생하면 체크포인트 LSN 보다 작은 Redo 로그 엔트리와 관련된 Dirty Page는 모두 동기화가 된다고 할 수 있음.
- 결국 버퍼 풀의 크기가 커봤자, Redo 로그 파일의 크기가 작게되면 체크포인트 간의 간격 (즉, 활성 Redo 공간의 크기)는 결국 파일의 크기를 따라가게 되므로, 버퍼 성능이 그렇게 좋아지진 않음.
Buffer Pool Flush
- 버퍼 풀에서 아직 디스크로 기록되지 않은 더티 페이지들을 성능상의 악영향 없이 디스크에 동기화하기 위해 다음과 같이 2개의 플러시 기능을 백그라운드로 실행함.
- Flush_list Flush
- 플러시 리스트에서 오래전에 변경된 데이터 페이지 순서대로 디스크에 동기화 함
- 얼마나 많은 Dirty Page를 한 번에 기록하냐가 성능에 영향을 미칠 수 있음,
- InnoDB에서 Dirty Page를 디스크로 동기화하는 스레드를 클리너 스레드라고 하는데, 이는 변수 값을 통해 조정 가능함.
- 또한, 기본적으로 전체 버퍼 풀이 가진 페이지의 90%까지 Dirty Page를 가질 수 있는데 이 또한 조정 가능함.
- 하지만 너무 Dirty Page의 수가 많아지면 Disk I/O Burst가 발생할 수 있음. → 설정을 변경하여 일정 수준 이상의 더티 페이지가 발생하면 조금씩 기록하도록 할수도 있음.
- Adaptive Flush 기능을 사용하면, InnoDB는 Redo 로그의 증가 속도를 분석하여 적절한 수준의 Dirty Page가 버퍼 풀에 유지될 수 있도록 디스크 쓰기를 실행한다.
- LRU_list Flush
- LRU 리스트에서 사용 빈도가 낮은 데이터 페이지들을 제거해서 새로운 페이지들을 읽어올 공간을 만들어야 함.
- LRU 리스트를 스캔하면서 Dirty Page는 동기화하고, Clean Page는 Free 리스트로 페이지를 옮김.
- Flush_list Flush
버퍼 풀 상태 백업 및 복구
- 앞에서 언급했듯이 버퍼 풀은 성능에 큰 영향을 줌
- 그렇기에, 디스크의 데이터를 미리 버퍼 풀에 적재 (Warming Up) 함으로써 성능을 수십배 올릴 수 있기도 함.
- MySQL 5.5의 경우, 서비스를 오픈하기 전에 강제 Warming Up을 위해 주요 테이블과 인덱스에 대해 Full Scan 을 한 번씩 하고 서비스를 기동했음.
- MySQL 5.6 부터 버퍼 풀 덤프 및 로드 기능이 도입되어 이를 활용할 수 있음.
버퍼 풀의 적재 내용 확인
- 5.6 부터
information_schema데이터베이스의inno_db_buffer테이블을 이용해 어떤 테이블의 페이지들이 적재되어 있는지 확인할 수 있었음.- 다만 버퍼 풀이 크다면 이 테이블 조회 자체가 큰 부하를 일으킴으로써 서비스 쿼리가 느려지는 문제가 있었음.
- 8.0 부터는
information_schema데이터베이스에innodb_cached_indexed가 추가되어, 테이블의 인덱스별로 얼마나 버퍼 풀에 적재되어있는지 확인할 수 있음.
Double Write Buffer
- InnoDB의 Redo 로그는 공간의 낭비를 막기 위해 페이지의 변경된 내용만 기록함.
- 이로 인해 Dirty Page를 디스크로 플러싱할 때 일부만 기록되는 문제가 발생하면 페이지의 내용을 복구할 수 없을 수도 있음.
- Partial-Page 또는 Torn-Page 라고 부름.
- 이런 문제를 방지하기 위해, Double-Write 기법을 사용함.
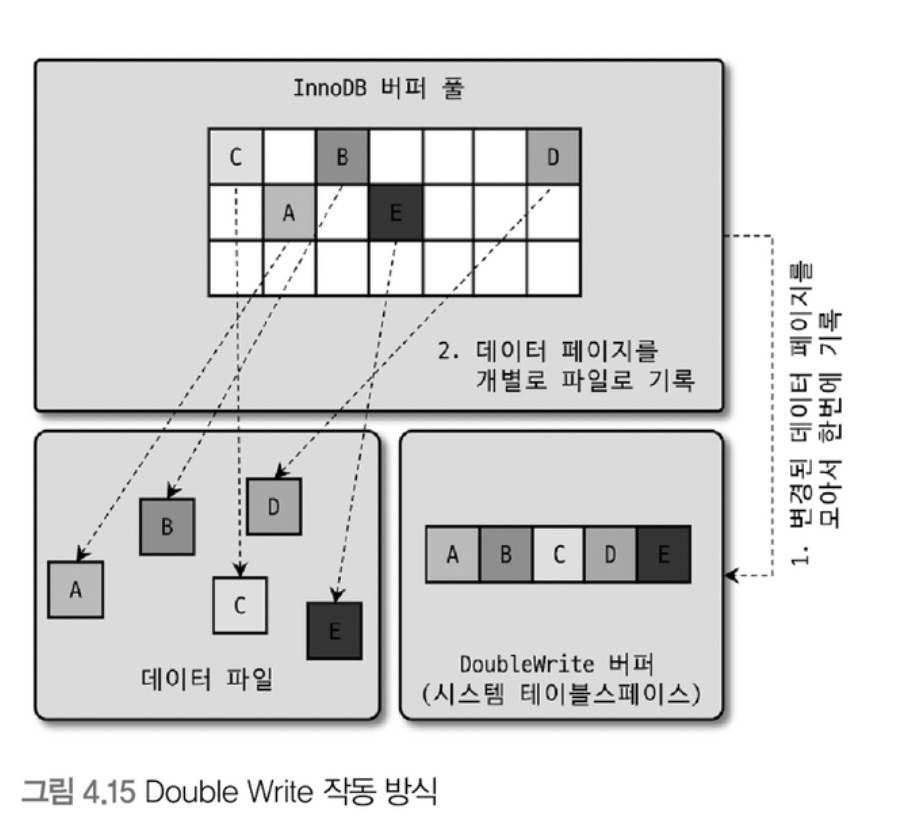
- InnoDB는 실제 데이터 파일에 변경 내용을 기록하기 전, ‘A’ ~ ‘E’ 까지의 Dirty Page를 묶어서 한 번의 Disk Write로 DoubleWrite 버퍼에 기록함.
- 이후에 쓰기 진행- DoubleWrite 버퍼 공간에 기록된 내용은 실제 데이터 파일의 쓰기가 실패할 때만 사용됨.
- InnoDB는 재시작 될 때 DoubleWrite 버퍼의 내용과 데이터 파일의 페이지들을 모두 비교하여 다른 내용을 담고 있는 페이지가 있다면 DoubleWrite 버퍼의 내용을 데이터 파일의 페이지로 복사함.
Undo 로그
- Transaction Isolation 보장을 위해, DML (INSERT, UPDATE, DELETE) 로 변경되기 전 이전 버전의 데이터를 별도로 백업함. → Undo 로그
- 중요한 역할을 하지만, 관리 비용도 많이 필요함.
Undo 로그 레코드 모니터링
- Undo 영역은 트랜잭션의 롤백 대비용/격리 수준 유지하면서 높은 동시성 제공이 목적
- MySQL 5.5 이전엔 한 번 증가한 Undo 로그 공간은 다시 작아지지 않았음.
- 결국, 대용량의 데이터가 적재된 테이블이나, 트랜잭션의 기간이 긴 경우엔 로그 공간이 비대하게 커지게 됨.
- 이 경우엔 서버를 새로 구축하지 않는 한 줄일 수가 없었고, Undo 로그의 크기로 인해 백업시에도 오버헤드가 과도하게 커지게 됨.
- MySQL 5.7과 MySQL 8.0 부터 이 문제는 해결됨
- 특히, MySQL 8.0 부터는 Undo 로그를 순차적으로 사용함으로써 디스크 공간 사용량 자체를 줄여버림.
- 그럼에도 활성 상태의 트랜잭션이 장기간 유지되는 것은 좋진 않음.
- SHOW ENGINE INNODB STATUS \G 를 통해 모니터링 가능
Undo 테이블스페이스 관리
- Undo 로그가 저장되는 공간을 Undo 테이블스페이스라고 함.
- 기존에는 시스템 테이블스페이스에 저장했으나, 해당 구역은 서버 초기화때 생성되므로 한계가 있었음.
- 현재는 별도의 파일로 관리함.
- 다음과 같이 언두 테이블스페이스는 1~128개의 롤백 세그먼트를 가지며, 각각의 롤백 세그먼트는 1개 이상의 Undo Slot을 가짐
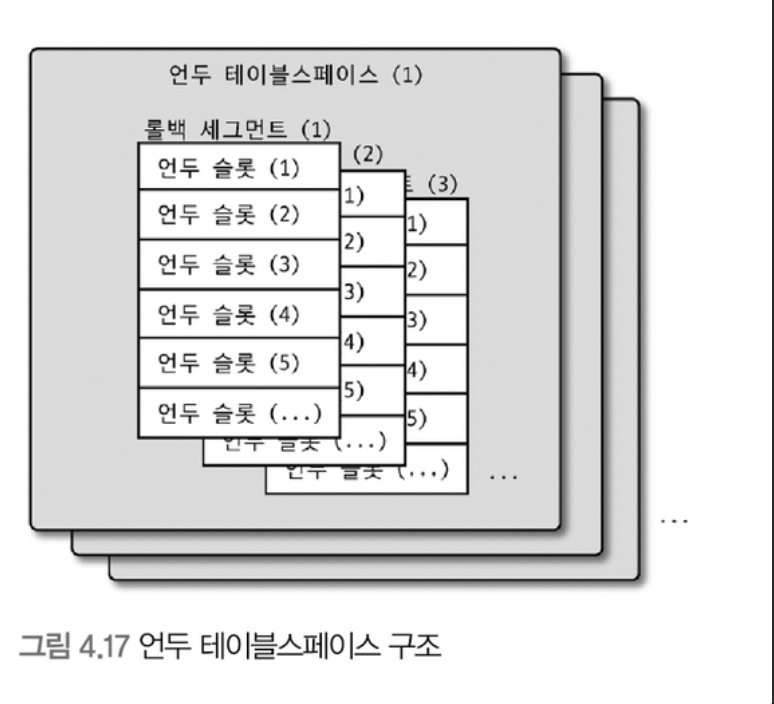
- 하나의 트랜잭션은 실행하는 INSERT, UPDATE, DELETE 문장의 특성에 따라 최대 4개까지 Undo Slot 을 사용함.
- 공간이 남는건 문제가 되지 않지만, 슬롯이 부족한 경우에는 트랜잭션을 시작하지 못 할수도 있음.
- 물론 일반적인 설정 (16KB → 약 131072 개의 트랜잭션 처리 가능) 기준으로도 웬만하면 큰 문제 없음.
- MySQL 8.0 부터 필요한 경우
CREATE UNDO TABLESPACE나DROP TABLESPACE같은 명령으로 새로운 언두 테이블 스페이스를 동적으로 추가 및 삭제할 수 있음.- 또한, 불필요한 Undo 테이블스페이스를 OS에 반납할 수 있는데, 이는 자동 모드/수동 모드 모두 가능함.
- 자세한 동작 방법은 생략
- 또한, 불필요한 Undo 테이블스페이스를 OS에 반납할 수 있는데, 이는 자동 모드/수동 모드 모두 가능함.
체인지 버퍼
- 레코드가 INSERT 및 UPDATE가 될 경우에는 해당 테이블에 포함된 인덱스를 업데이트 작업 또한 필요함.
- 이 작업 또한 랜덤한 디스크 읽기가 수반되므로 상황에 따라 많은 자원을 소비해야 할 수도 있음.
- InnoDB는 변경해야 할 인덱스 페이지가 버퍼 풀에 있다면 바로 업데이트를 진행하지만, 그렇지 않다면 이를 바로 실행하지 않고 체인지 버퍼에 저장함.
- 결과를 전달하기 전 중복 여부를 체크해야 하는 Unique Index는 체인지 버퍼를 사용할 수 없음.
- 임시로 저장된 인덱스 레코드 조각은 이후 체인지 버퍼 머지 스레드라는 백그라운드 스레드에 의해 병합됨.
- MySQL 8.0 이전까지는 INSERT 에서만 가능함.
- 상황에 따라 innodb_change_buffering 시스템 변수를 변경하여 특정 상황에 대해서만 수행하도록 할 수 있음.
- 기본적으로 InnoDB 버퍼 풀로 설정된 메모리 공간의 25%까지 사용할 수 있음.
- 이 또한 시스템 변수 값을 수정함으로써 변경 가능.
Redo 로그 및 로그 버퍼
- HW/SW 문제로 인해 서버가 비정상적으로 종료되었을 때 데이터 파일에 기록되지 못한 데이터를 유지시켜주는 안전장치임.
- 마치 ACID의 D 라고 할 수 있음.
- 대부분의 DBMS는 데이터 변경 내용을 로그로 먼저 기록함.
- 왜? → 상당수의 DBMS는 쓰기보다 읽기에 최적화 되어 있으며, 그렇기에 쓰기 연산은 상당한 비효율 (ex. 랜덤 I/O) 를 보임 → 그렇기에 쓰기 비용이 낮은 자료구조를 갖는 Redo 로그를 활용함.
- 마찬가지로, Redo 로그를 버퍼링할 수 있는 로그 버퍼와 같은 자료구조도 있음.
- 시나리오를 설정해보자.
- 커밋되었지만 데이터 파일에 기록되지 않은 데이터
- Redo 로그에 저장된 데이터를 붙여넣기만 하면 됨.
- 롤백했지만 데이터 파일에 이미 기록된 데이터
- 어떤 변경이 커밋/롤백 되었는지, 아니면 트랜잭션 실행 중인지 확인하는데 쓰임.
- 커밋되었지만 데이터 파일에 기록되지 않은 데이터
- Redo 로그는 트랜잭션이 커밋되면 바로 디스크에 기록되도록 시스템 변수를 설정하는 것이 권장됨.
- innodb_flush_log_at_trx_commit 변수 활용
- Redo 로그의 전체 크기는 InnoDB 버퍼 풀의 효율성을 결정하므로 신중하게 정해야 함.
- 기본값은 16mb 이나, blob 타입이나 text 타입 같은 큰 데이터를 다루게 되면 더 크게 설정하는 것이 좋음.
Redo 로그 아카이빙
- MySQL 8.0 부터 Redo 로그를 아카이빙 할 수 있음.
- 원래는 엔터프라이즈 에디션이나 서드 파티 툴을 사용했지만, 대부분 스냅샷 형식이기에 데이터가 너무 빠르게 변해 그 전에 Redo 로그가 덮어씌워지게 되면 의미가 없을 수도 있음.
- 자세한 과정은 생략
Adaptive Hash Index
- 일반적으로 인덱스라고 하면 B-Tree 형식의 테이블 인덱스를 떠올림.
- Adaptive Hash Index는 InnoDB에서 사용자가 자주 요청하는 데이터에 대해 자동으로 생성하는 인덱스
- B-Tree는 빠른 편이지만, 결국 속도는 상대적이고 스레드의 수가 늘게 되면 엄청난 성능의 영향을 받음.
- 왜? 스케쥴링…
- Adaptive Hash Index를 사용하면, 자주 읽히는 데이터 페이지의 키 값을 활용해 해시 인덱스를 생성하고, 이에 접근하면 즉시 데이터 페이지로 찾아갈 수 있음.
- 인덱스 키 값은 B-Tree 인덱스의 고유번호 (Id) 와 B-Tree 인덱스의 실제 키 값 조합이다.
- 결국 엔진 전체에 Adaptive Hash Index 는 하나이기 때문에 인덱스의 고유번호가 필요함.
- 자주 접근하는 페이지를 다뤄야 하므로, 버퍼 풀에 올려진 데이터 페이지에 대해서만 관리하고, 사라지면 같이 없앰.
- 다만 이런 기능임에도 불구하고 이전에는 Semaphore의 경쟁이 있었기에 정체가 발생했었지만, MySQL 8.0 부터는 파티션 기능을 추가함.
- innodb_adaptive_hash_index_parts 시스템 변수 사용
- 하지만 실제로는 비활성화 하는 경우도 많은데…
- 도움이 되지 않은 경우
- 디스크 읽기가 많은 경우
- 특정 패턴의 쿼리 (LIKE나 조인 같은) 가 많은 경우
- 매우 큰 데이터를 가진 테이블의 레코드를 폭넓게 읽는 경우
- 도움이 되는 경우
- 디스크의 데이터가 InnoDB 버퍼 풀 크기와 큰 차이가 없는 경우
- 동등 조건 검색 (IN이나 비교 같은) 이 많은 경우
- 쿼리가 데이터 중에서 일부 데이터에만 집중되는 경우
- 도움이 되지 않은 경우
- 결국 똑같은 메모리를 사용하기 때문에, 사용하지 않을 경우 제거하는 것이 맞음.
SHOW ENGINE INNODB STATUS\G를 사용하면 다양한 로그를 확인할 수 있는데, 여기서 Hash를 사용한 검색과 사용하지 못한 검색의 비율을 비교할 수 있음.
InnoDB vs MyISAM vs MEMORY
- MySQL 5.5 부터 InnoDB 스토리지 엔진이 기본 스토리지 엔진으로 채택되었고, 이전에는 MyISAM을 사용했었음.
- 그럼에도 불구하고 수많은 시스템 테이블은 MyISAM 이었음
- MySQL 8.0 부턴 모든 시스템 테이블이 InnoDB로 교체되었음.
- 설명이 길지만 결과적으론 뒤 두개는 도태되었고, 상황에 따라 삭제될 수 있으므로 과감히 잊어버리자.

아직 많이 공부 중...