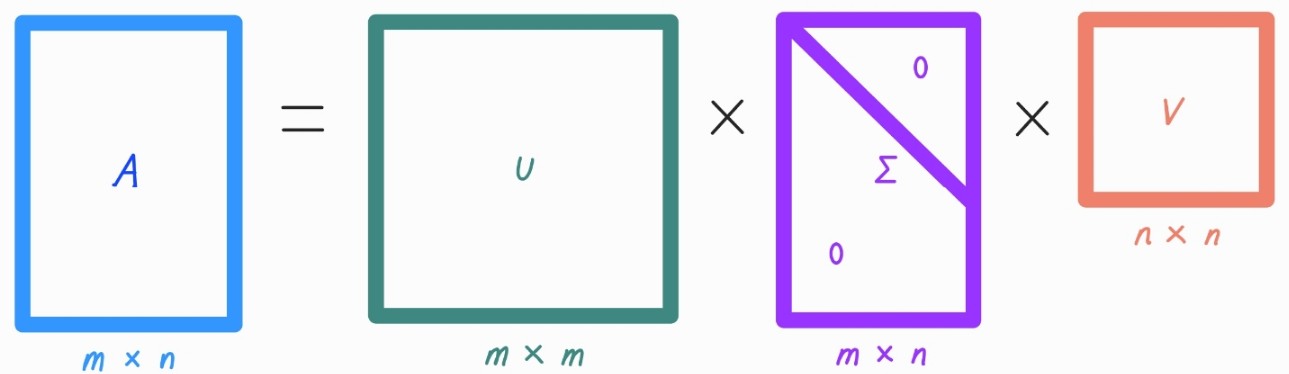
1. 차원 축소
차원 축소 개요
-
정의
- 매우 많은 피처로 구성된 다차원 데이터셋의 차원을 축소해 새로운 차원의 데이터셋을 생성하는 것. -
차원 축소를 하는 이유
- 차원이 증가할수록, 데이터 포인트 간의 거리가 멀어지고 희소한 구조를 가짐.
- 수백개 이상의 피처로 구성된 데이터의 경우, 상대적으로 적은 차원에서 학습된 모델보다 예측 신뢰도가 떨어짐
- 피처가 많을 경우 개별 피처 간에 상관관계가 높을 가능성이 큼.
- 다중 공산성 문제
-
장점
- 더 직관적으로 데이터를 해석 가능.
- 학습 데이터의 크기가 줄어서 학습에 필요한 처리 능력도 줄일 수 있음.
- 이미지 분류 등 분류 수행 시 과적합 영향력이 작아져서 오히려 원본 데이터로 예측하는 것보다 예측 성능을 더 끌어올릴 수 있음.
-
차원 축소 구분
- 피처 선택 : 특정 피처에 종속성이 강한 불필요 피처는 아예 제거, 데이터의 특징을 잘 나타내는 주요 피처만 선택
- 피처 추출 : 기존 피처를 저차원의 중요 피처로 압출해서 추출.
-> 새롭게 추출된 중요 특성은 기존의 피처가 압축된 것이므로 완전 다른 값이 됨.💡 피처 추출 추가 설명
- 단순 압축이 아닌, 함축적으로 더 잘 설명할 수 있는 또다른 공간으로 매핑해 추출하는 것.
📍 함축적인 특성 추출 : 기존 피처가 인지하지 못했던 잠재적인 요소를 추출.
형광펜 치기
- 단순 압축이 아닌, 함축적으로 더 잘 설명할 수 있는 또다른 공간으로 매핑해 추출하는 것.
차원 축소를 통해 더 데이터를 잘 설명할 수 있는 잠재적인 요소를 추출하는 것에 있음
2. PCA - Principal Component Analysis
날라감
3. LDA - Linear Discriminant Analysis
LDA 개요
- 선형 판별 분석법으로 불리며, 입력 데이터셋을 저차원 공간에 투영해 차원을 축소하는 기법
LDA 특성
- 지도학습의 분류에서 사용하기 쉽도록 개별 클래스를 분별할 수 있는 기준을 최대한 유지하면서 축소함.
- 특정 공간상에서 클래스 분리를 최대화하는 축을 찾기 위해 클래스 간 분산과 클래스 내부 분산의 비율을 최대화하는 방식으로 차원축소함.
- 즉, 클래스 간 분산은 최대한 크게, 클래스 내부 분산은 최대한 작게
💡 PCA와 LDA의 차이?
PCA - 비지도학습, 입력 데이터의 변동성의 가장 큰 축을 찾음.
LDA - 지도학습, 입력 데이터의 결정값 클래스를 최대한 분리할 수 있는 축을 찾음. 클래스의 결정값이 변환시에 필요.
4. SVD - Singular Value Decomposition
SVD 개요
- 특이값 분해로 불리며, 행렬 U와 V에 속한 벡터는 특이벡터임.(모든 특이벡터는 서로 직교함)
- ∑는 대각행렬임. 행렬의 대각에 위치한 값만 0이 아니며, 나머지 위치의 값은 모두 0임. ∑의 대각원소값이 바로 행렬 A의 특이값임.
- A의 특이값은 AAt 혹은 AtA의 고유값의 루트(Square Root) 값과 동일.
💡 참고 지식
행렬 A를 선형변환으로 봤을 때, 선형변환 A에 의한 변환 결과가 자기 자신의 상수배가 되는 0이 아닌 벡터를 고유벡터라 하고 이 상수배 값을 고유값이라고 한다.
SVD는 m×n 크기의 행렬 A를 다음과 같이 분해함.
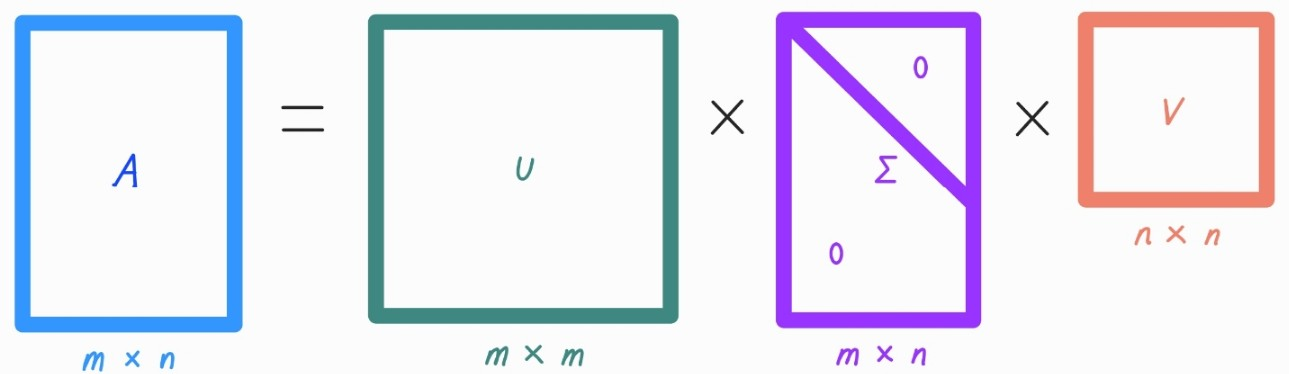
- m×n 크기의 행렬 A는 m×m크기의 행렬 U와 m×n크기의 ∑, 그리고 n×n크기의 로 나뉨.
를 하나하나 살펴보면 아래와 같음.
-> U는 를 고유값 분해해서 얻은 직교 행렬이며, V는 를 고유값 분해해서 얻은 직교 행렬임. (U와 V는 모두 직교 행렬)
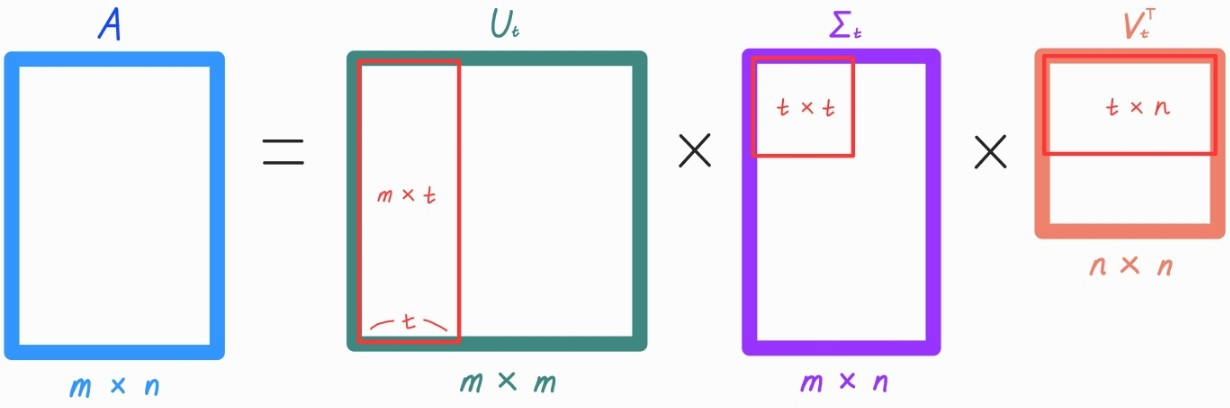
📍 But, 일반적으로 Full SVD보다 Truncated SVD를 자주 사용함.
Truncated SVD
- ∑의 대각 원소 중 상위 몇 개만 추출하고 여기에 대응하는 U와 V의 원소도 함께 제거해 차원축소함.
- ∑의 대각 원소 중 상위 t개만 추출한다고 하면 아래와 같이 분해됨.
5. NMF - Non-negative Matrix Factorization
NMF의 개요
- NMF는 Truncated SVD와 같이 낮은 랭크를 통한 행렬근사방식의 변형임.
- 많은 피처 데이터를 가진 고차원 행렬을 두 개의 저차원 행렬로 분리하는 행렬 분해 기법.
- NMF는 SVD와 유사하게 차원 축소를 통한 잠재 요소 도출로 이미지 변환 및 압축 텍스트의 토픽도출 등의 영역에서 사용됨.
- NMF는 원본 행렬 내의 모든 원소 값이 모두 양수라는 것이 보장되면 다음과 같이 더 간단하게 두 개의 기반 양수 행렬로 분해될 수 있음.

‣ 4×6 원본 행렬 V는 4×2 행렬 W와 2×6 행렬 H로 근사히 분해 가능.
분해된 행렬은 잠재 요소를 특성으로 가지게 됨.
- 분해 행렬 W : 원본 행에 대해서 이 잠재 요소의 값이 얼마나 되는지
- 분해 행렬 H : 잠재 요소가 원본 열(원본 속성)로 어떻게 구성이 됐는지
💡 NMF의 적용 사례
추천 영역(Recommendations) - 영화 추천 등
- 사용자의 상품 평가 데이터셋인 사용자-평가순위 데이터셋을 행렬 분해 기법을 통해 분해하면서 사용자가 평가하지 않은 상품에 대한 잠재적인 요소를 추출해 이를 통해 평가 순위를 예측하고 높은 순위로 예측된 상품을 추천해줌.
= 잠재 요소 기반의 추천방식

2023년은 나의 해