사이킷런은 BaseEstimator를 상속받으면 Customized 형태의 Estimator를 개발자가 생성할 수 있다.
생성할 MyDummyClassifier 클래스 : 학습을 수행하는 fit() 함수는 아무것도 수행하지 않으며, 예측을 수행하는 predict() 함수는 단순히 성별이 1이면 0, 그렇지 않으면 1로 예측하는 매우 단순한 Classifier.
위의 MyDummyClassifier은 sklearn의 Classifier(분류모델) 구현을 흉내낸 것임.
<설명> FrameWork란 특정 프로그램을 개발하기 위한 여러 요소들과 매뉴얼인 룰을 제공하는 프로그램을 말한다. sklearn FrameWork은 분류를 위한 수행 객체로 Classifier을 가진다. Classifier은 DR, RF등 다양한 분류 알고리즘을 구현한다. 보통 이 Classifier객체들은 Regressor(회귀)객체와 함께 Estimator이라고 불린다.
이 Estimator은 sklearn FW에서 GridSearchCV, cross_val_score()등 다양한 utility class와 결합 가능.
그런데 이걸 적용하려면 모든 Estimator들은 BaseEstimator라는 것을 상속받아야 함.
- 그래서 MyDummyClassifier에서 BaseEstimator을 상속받는 것임.
1. 정확도 - Accuracy
정확도는 예측 결과와 실제 값이 동일한 건수/ 전체 데이터 수 = (TN+TP)/(TN+FN+FP+TP)
정확도는 불균형한(imbalanced) 레이블 값 분포에서 ML모델의 성능을 판단할 경우, 적합한 평가 지표가 아니다.
왜? 100개의 데이터 중 90개의 데이터 레이블이 0이고 10개만의 데이터 레이블이 1일때 무조건 0으로만 예측하는 ML모델의 경우에도 정확도는 90%이기 때문.
오늘 안 사실
numpy array는 count 함수를 가지지 않음.
이때 몇 개인지 세고 싶으면 collection 라이브러리를 사용한다.
예제
import collections
a = digits.target
-
a의 결과는 output으로 array([0, 1, 2, ..., 8, 9, 8])가 반환됨.
collections.Counter(a)[7] -
위의 결과로 179가 나옴. 즉 a array 안에 숫자 7이 179개가 있다는 뜻.
numpy.nparray는 value_counts()를 가지지 않는다.
predict()의 결과를 np.zeros()로 모두 0값으로 반환했는데 450개의 테스트 데이터 세트에 수행한 예측 결과의 정확도는 90%임.
이처럼 정확도 평가 지표는 불균형한 레이블 데이터 세트에서는 성능 수치로 이용하면 안됨.
-> 정확도가 가지는 분류 평가 지표로서 이 한계점을 극복하기 위해 여러가지 분류지표와 함께 적용해야 한다.
2. 오차행렬 - Confusion Matrix
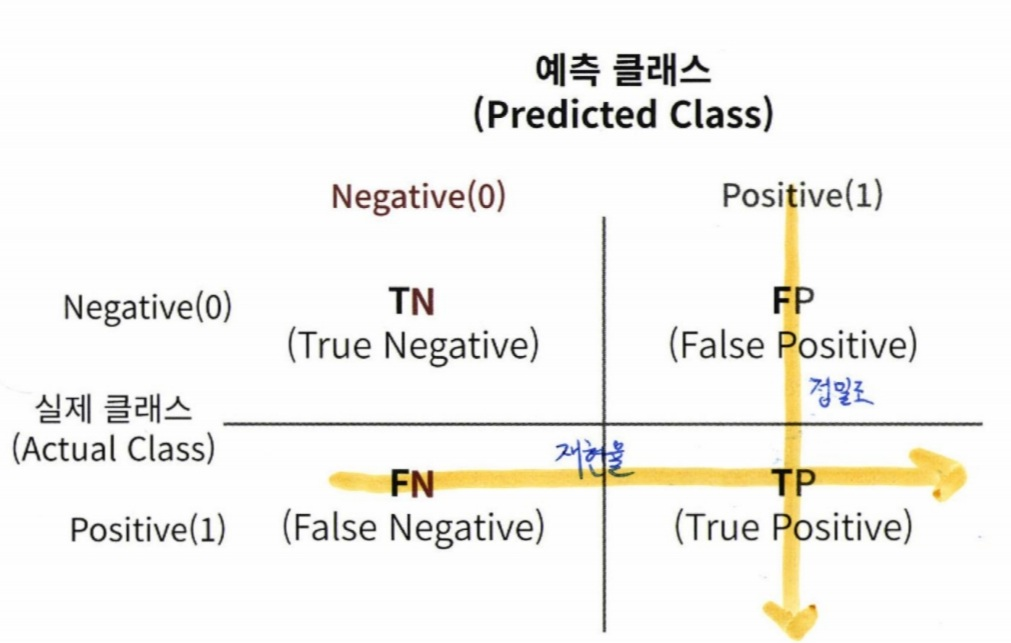

3. 정밀도와 재현율
불균형한 데이터셋에서 정확도보다 선호되는 평가지표 = 정밀도, 재현율 (Precision, Recall)
정밀도 = TP/(FP+TP) # precision_score()
재현율 = TP/(FN+TP) # recall_score()
- 재현율이 비교적 더 중요한 지표일 경우 : 실제 양성인 데이터 예측을 Negative라고 잘못 판단하면 큰 화를 입는 경우
- 정밀도가 비교적 더 중요한 지표일 경우 : 실제 음성인 데이터 예측을 Positive라고 잘못 판단하면 큰 화를 입는 경우
4. F1 Score
F1 스코어 - 정밀도와 재현율을 결합한 지표.
F1 스코어는 정밀도와 재현율이 어느 한 쪽으로 치우치지 않는 수치를 나타낼 때 상대적으로 높은 값을 가짐
F1 = 2 (precisionrecall)/(precision+recall)
5. ROC 곡선과 AUC
ROC (Receiver Operation Characteristic Curve) - 수신자 판단 곡선
-> 머신러닝의 이진 분류 모델의 예측 성능을 판단하는 중요한 평가 지표
: ROC 곡선은 FPR(False Positive Rate)가 변할 때 TPR(True Positive Rate, 재현율)가 어떻게 변하는지 나타내는 곡선
제공 API - roc_curve()
민감도(TPR) : 실제값 Positive가 정확히 예측돼야 하는 수준을 나타냄. -> 질병이 있는 사람은 질병 있다고 양성판정.
특이성(TNR) : 실제값 Negative가 정확히 예측돼야 하는 수준을 나타냄. -> 질병이 없는 건강한 사람은 질병 없다고 음성 판정
TNR = TN / (FP + TN)
FPR = FP / (FP + TN) = 1 - TNR = 1 - 특이성
- 임계값이 1에 가까운 값에서 점점 작아지면서 FPR이 점점 커짐.
- FPR이 조금씩 커질때 TPR은 가파르게 커짐.

안녕하세요! 우리 이웃 해요 *^____^*