
빅데이터의 이해
빅데이터
정형(데이터베이스, 사무정보)과 비정형(멀티미디어, SNS) 데이터 모두를 포함하여 데이터에서 가치를 추출하기 위한 분석 기술
3V + 2V
- Volume(규모)
- 데이터는 인터넷과 모바일 시대의 등장으로 Exa Byte에서 Zetta Byte 시대로 진입했다.
- Variety(다양성)
- 로그기록, 소셜 데이터, 위치정보, 소비, 현실데이터 등 데이터 종류 증가
- 텍스트 외 멀티미디어와 같은 비정형 데이터의 증가
- Velocity(속도)
- 센서, 사물정보, 스트리밍 정보 등 실시간 정보 증가에 따라 대규모 데이터 처리, 가치 있는 정보의 적시 활용을 위한 데이터 분석속도가 중요해졌다.
- Veracity(정확성)
- 방대한 데이터를 분석할 때 질 높은 데이터를 활용해야 분석의 정확도가 높아진다.
- Value(가치)
- 빅데이터는 사용자에게 가치있는 정보를 창출해야 한다.
전통적데이터와 빅데이터의 차이
| 구분 | 전통적 데이터 | 빅데이터 |
|---|---|---|
| 데이터 크기 | 기가바이트 | 테라, 페타, 제타 바이트 |
| 데이터 속도 | 시간, 일 단위 데이터 | 실시간 데이터 |
| 데이터 구조 | 정형화된 구조 데이터 | 반구조 및 비정형 데이터 |
| 데이터 원천 | 중앙집중형 데이터베이스 | 분산 데이터베이스 |
| 데이터 통합 | 쉬움 | 어려움 |
| 데이터 저장 | RDB(Relation DataBase) | HDFS, NOSQL |
빅데이터의 미래
미래의 데이터는 지속적으로 구축되는 데이터를 활용하여 인공지능, 머신러닝, 딥러닝 형태로 발전할 것이다.
빅데이터를 구축하고 분석, 운영하기 위해서는 기본적인 7가지 테크닉이 필요하다.
7가지 기본 테크닉
- 연관규칙 학습
- 어떤 변수들간의 관련성을 분석한다.
- 유형분석
- 문서를 분류하거나 조직을 그룹화한다.
- 기계학습
- 데이터를 학습하여 알려진 특성을 활용하여 예측한다.
- 유전 알고리즘
- 대량의 유전자 데이터를 분석을 통하여 특정 알고리즘을 도출하고 활용한다.
- 회귀분석
- 독립변수와 종속변수 간의 어떤 관계가 있는지 분석한다.
- 감성분석
- 특정 주제에 대해서 말을 하거나 글을 쓴 사람의 감정을 분석한다.
- 소셜 네트워크 분석
- 특정인과 다른 사람의 관계를 파악하고 영향력 있는 사람을 분석한다.
빅데이터의 가치와 영향
빅데이터 활용을 위한 3대 요소
빅데이터 활용을 위한 3대 요소는 자원, 기술, 인력으로 구분된다.
- 자원
- 데이터 자원을 확보하고 데이터 품질을 관리
- 기술
- 빅데이터 플랫폼을 사용해서 데이터 저장, 관리, 분석시각화
- 인력
- 데이터 사이언스는 수학, 공학 등의 능력으로 데이터를 분석하고 해석한다.
- 전문가를 말한다.
빅데이터 처리 프로세스
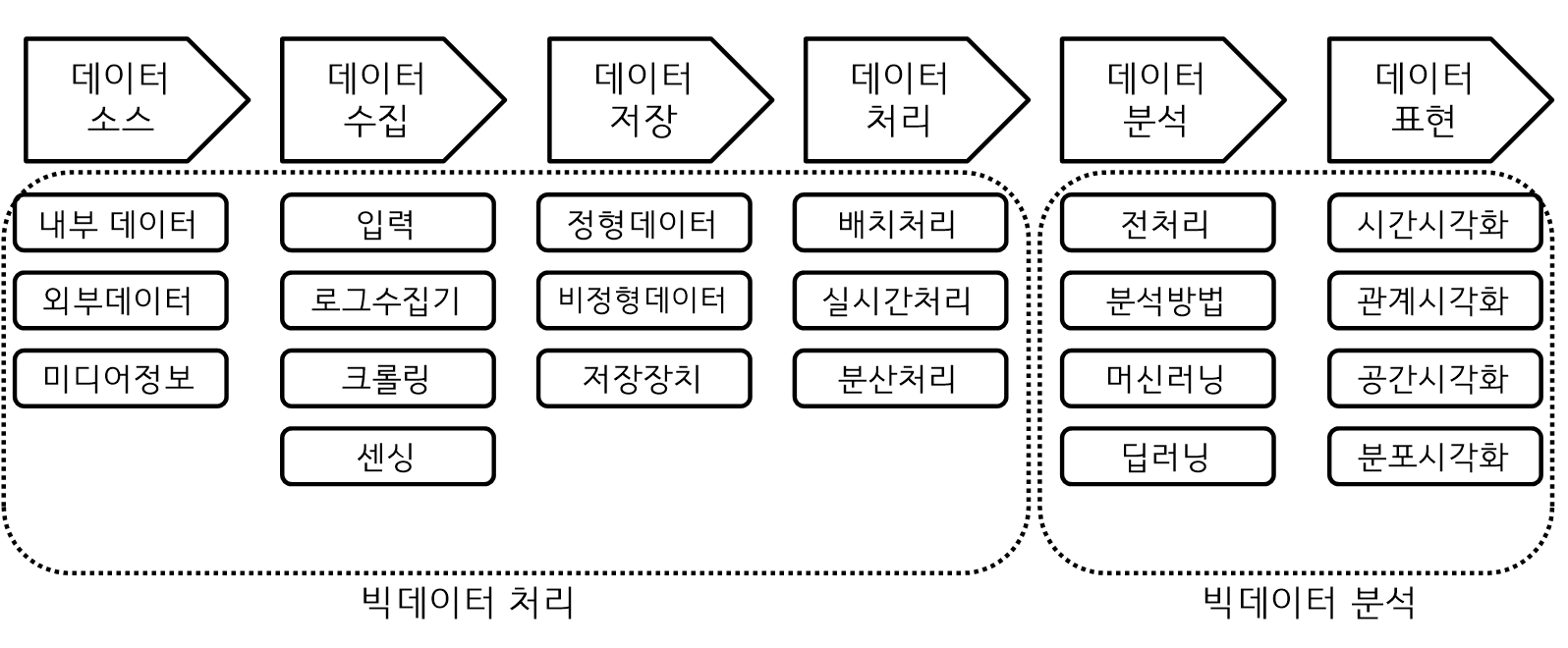
위 프로세스 중 처리와 저장이 핵심 저장은 관계형데이터베이스, 문서단위, 컬럼단위 저장을 위한 하둡이 있다.
- 센싱 : 감지하는것, 보통 센서가 부착된 상품으로부터 발생되는 데이터이다.
- 크롤링 : 웹사이트를 방문해서 웹 페이지의 정보를 수집한다.
빅데이터 비즈니스 모델
빅데이터 서비스 모델
- 전력 빅데이터
- 한국전력은 보유하고 있는 에너지 빅데이터를 이용해서 사용자에게 에너지 사용 정보와 에너지 절약방법을 제공한다.
- 보건 및 의료 빅데이터
- 빅데이터를 활용하여 치료 중심에서 예방 및 건강관리 서비스를 제공한다.
- 질병 발생 가능성 예측, 개인 맞춤형 의료 서비스 제공한다.
- 유통 빅데이터
- 유통 빅데이터를 사용해서 발주량을 결정하거나 적극적인 매장관리 기법을 데이터에 기반하여 가이드한다.
- 매출데이터와 기상 데이터, 인구 데이터 등을 연계해서 새로운 서비스를 제공한다.
- 관광 빅데이터
- 시간 및 기간별 관광객 분석, 지역별 관광객 분석, 관광객 소비패턴 분석, 내국인 소비패턴을 분석해서 맞춤형 관광 서비스를 제공한다.
- 관광 정보를 모바일 정보 서비스 및 웹 정보 서비스로 제공한다.
- 블록별 매출분석 및 연계지역 분석
- 지역경제 활성화를 위해 ㅇㅇ마을 일대의 핵심상권 매출을 분석한다.
- ㅇㅇ마을 핵식 상권 정보와 인근 지역 체류 정보를 연계하여 ㅇㅇ시에서 어떻게 이동하는지를 분석한다.
원시 데이터 구성 및 보관 방식
- 데이터 레이크(Data Lakes)
- 데이터 레이크는 막대한 원시 데이터를 본연의 형식 그대로 저장
- 다양한 리소스에서 발생하는 방대한 양의 데이터를 수집, 보관
- 수많은 사물로부터 데이터를 수집하는 사물인터넷에서 데이터 레이크의 중요성 증가
- (사물인터넷에서 발생하는 데이터 중 센싱도 중요성이 커지는 구나)
- 데이터레이크 보호방식
- 접근 및 권한부여에 대한 적절한 통제
- 강력한 ID관리
- 감사 프로세스
- 충분히 테스트하고 치밀한 사고 대응계획 수립
- 데이터 암호화 구현
- 빅데이터 저장방식
- 빅데이터 처리과정에서 확보된 데이터를 체계적으로 구성하고 안전하게 보관해야 한다.
- 빅데이터 저장계획을 수립하고 빅데이터 품질관리를 해야한다.
저장방식 특징 제품 RDB(관계형데이터베이스) 관계형 데이터베이스에 저장하므로 SQL을 사용해서 쉽고 편리하게 관리 가능 Oracle, MySQL, MS-SQL 등 NoSQL Not Only SQL, KEY-VALUE, CLOUMN 기반으로 사용한다. MongoDB. HBase 등 분산 파일 시스템 분산 서버를 상요해서 여러 서버에 분산하여 저장한다.
대규모 저장소를 제공, 성능 향상HDFS
(Hadoop Distributed File System)
위기요인과 통제방안
빅데이터 위기요인과 통제
빅데이터 위기요인 및 통제방안
- 사생활 침입 : 특정 데이터가 본래 목적 외로 가공, 2차, 3차 목적으로 활용 가능성 증가
- 개인정보를 사용해서 분하는 분석자가 책임을 진다.
- 책임원칙 훼손 : 분석대상이 되는 사람들은 예측 알고리즘으로 희생양이 될 가능성이 증가
- 책임원칙을 강화한다.
- 데이터 오용 : 데이터에 대해서 잘못된 인사이트를 얻어서 비즈니스에 손실을 불러 온다.
- 데이터 알고리즘에 대한 접근권한 허용, 객관적인 인증방안을 도입
개인정보 가이드라인
- 개인정보를 통계작성 및 학술연구 외의 용도로 이용하거나 이를 제3자에게 비식별화 처리하여 제공하는 경우로 한정하고 개인을 알아볼 수 없는 형태로 개인정보를 가명처리, 총계처리, 데이터 값 삭제, 범주화, 데이터 마스킹 등을 하여 개인정보를 제공한다.
비식별화와 익명 데이터
- 비식별화
- 데이터셋에서 개인을 식별할 수 있는 요소들의 전부 혹은 일부를 삭제하거나 대체하는 과정
- 익명 데이터
- 정보 수집단계에서 근원적으로 개인을 식별할 수 없는 형태로 수집
비식별화 조치
비식별화 조치방법
가명처리
- 개인정보 중 주요 식별요소를 다른 값으로 대체 개인 식별을 곤란하게 한다.
ex) 홍길동, 30세, 서울거주, 서울대 졸업 -> 홍달길달동달, 30세, 서울거주, 서울대 졸업 - 다른 값을 대체하는 규칙이 노출되어 역을 개인이 쉽게 식별할 수 있어서는 안된다.
총계처리 또는 평균값 대체
- 데이터의 총합 값을 보임으로써 개별 데이터의 값을 보이지 않도록 한다.
- 특정 속성을 지닌 개인으로 구성된 단체의 속성 정보를 공개하는 것은 그 집단에 속한 개인의 정보를 공개하는 것과 마찬가지임으로 비식별화라고 볼 수 없다.
데이터 값(value) 삭제
- 데이터 공유 개방 목적에 따라 데이터셋에 구성된 값 중 필요 없는 값 또는 개인식별에 중요한 값을 삭제
ex) 홍길동, 930101-1132324 ->90년대생, 남자
범주화
- 데이터의 값을 범주의 값으로 명확한 값을 감춘다.
ex) 홍길동, 30 ~ 40세
데이터 마스킹
- 개인식별자가 보이지 않도록 처리하여 개인을 식별하지 못하도록한다.
ex) 홍**

AllTimeDevelop