데이터프레임 변형하기
그룹화하기
groupby 활용하기
import pandas as pd
flight = pd.read_csv('/content/drive/MyDrive/Colab Notebooks/Clean_Dataset.csv', encoding = 'cp949')
# flight를 airline으로 그룹화하여 변수에 저장함.
airline_group = flight.groupby('airline')
# 저장된 변수의 groups를 봄
airline_group.groups
위 groups로 출력한 결과 값은 가독성이 좋지 않다.
따라서 다음과 같은 메소드를 활용한다.
- count : 데이터 갯수
- size : 집단별 크기
- sum : 데이터의 합
- mean, std, var : 평균, 표준편차, 분산
- min, max : 최솟값, 최댓값
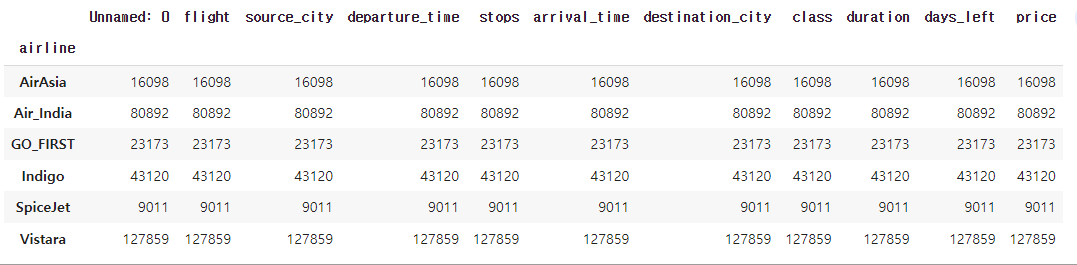
airline_group.count()아래와 같이 airline별 데이터 개수를 볼 수 있다.
# 최소값
airline_group.min()
#평균값 확인
airline_group.mean()
# 특정 칼럼 값만 확인하기
airline_group.min()[['price']]데이터프레임의 복수 개의 칼럼을 기준으로 그룹을 활용하면 다중 인덱싱을 설정 할 수 있다.
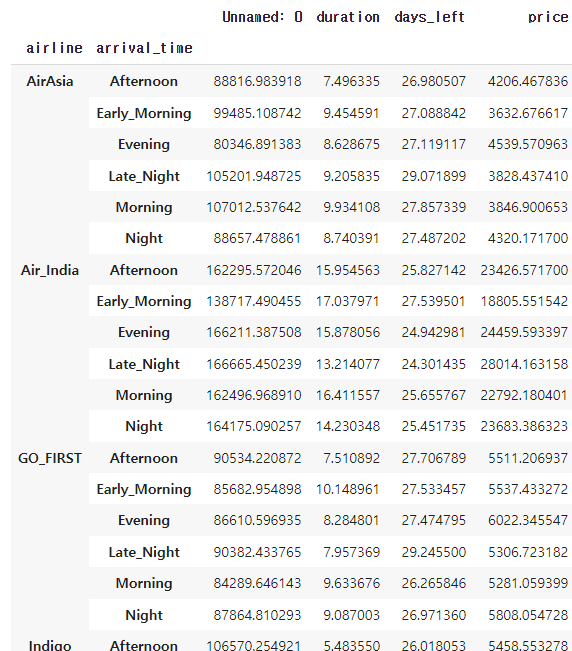
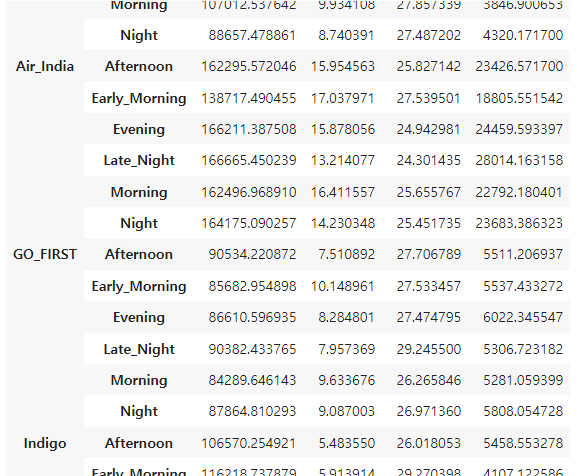
flight.groupby(['airline', 'arrival_time']).mean()airline별 arrival_time을 확인 할 수 있다.
여러 개의 칼럼을 기준으로 groupby한 경우 loc을 이용하여 인덱스의 데이터만 가져올 수 있다.
AirAsia의 Evening 정보만 확인하는 예제
flight.groupby(['airline','arrival_tiem']).mean().loc[['AirAsia','Evening']]
인덱스로 그룹화하기
#다중 인덱스 세팅 후 인덱스 기준으로 groupby 하기
flight.set_index(['airline','arrival_time']).groupby(level=[0]).mean()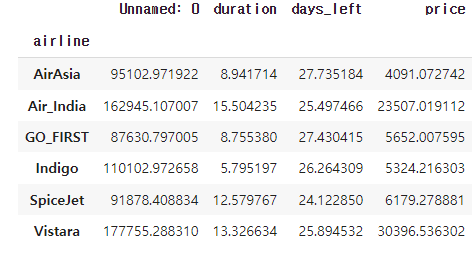
모든 인덱스를 기준으로 groupby하기
flight.set_index(['airline','arrival_time']).groupby(level=[0,1]).mean()
Aggregate로 집계하기
Aggregate로 집계하면 데이터프레임의 값을 다양하게 한 번에 볼 수 있다.
flight.set_index(['airline','arrival_time']).groupby(level=[0,1]).aggregate([np.mean, np.max])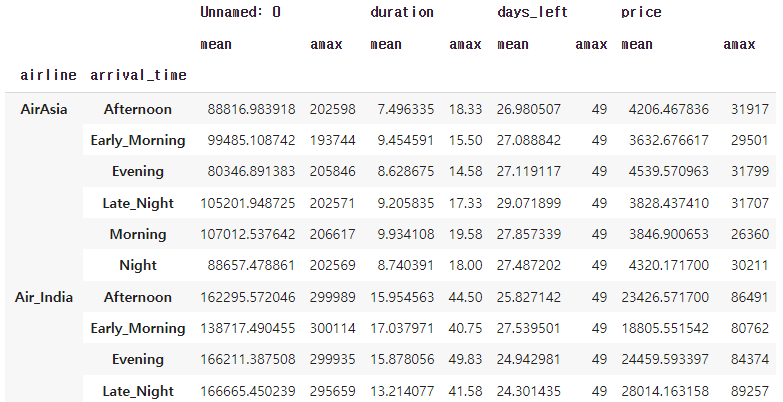
위와 같이 mean과 max를 한번에 볼 수 있다.
피벗테이블 생성하기
피벗테이블이란 회전한다는 사전적 의미처럼 pivot과 pivot_table 메소드는 행 데이터를 열 데이터로 회전할 수 있다.
import numpy as np
import pandas as pd
#데이터프레임 생성
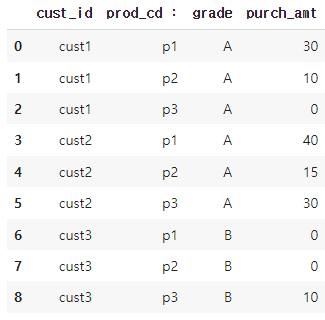
pivot_data = pd.DataFrame({
'cust_id':['cust1','cust1','cust1','cust2','cust2','cust2','cust3','cust3','cust3'],
'prod_cd :' : ['p1','p2','p3','p1','p2','p3','p1','p2','p3'],
'grade' : ['A','A','A','A','A','A','B','B','B'],
'purch_amt' : [30,10,0,40,15,30,0,0,10]
})
pivot_data데이터프레임 생성 결과
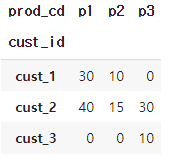
pivot_data.pivot(columns='prod_cd', index='cust_id', values='purch_amt')위와 같이 pivot을 설정하면 다음과 같이 prod_cd로 칼럼을 생성하고 index는 cust_id를 기준으로 생성된다. value는 purch_amt로 설정되어 테이블을 형성한다.
다음과 같이 설정명을 생략할 수 있다.
단 index, columns, values 순으로 작성
pivot_data.pivot('cust_id','prod_cd', 'purch_amt')pivot vs pivot_table
pivot_table은 addfunc을 사용하여 추가 연산된 결과를 가져올 수 있다.
또한 pivot_table은 index가 중복되어도 사용할 수 있고 pivot은 index 중복 시 오류가 발생한다.
인덱스 및 칼럼 레벨 변경하기
데이터프레임 만들기
import numpy as np
import pandas as pd
stack_data = pd.DataFrame({
'Location':['Seoul','Seoul','Seoul','kyounggi','kyounggi','Busan','Seoul','Seoul','Busan','kyounggi','kyounggi','kyounggi'],
'Day':['Mon','Tue','Wed','Mon','Tue','Mon','Thu','Fri','Tue','Wed','Thu','Fri'],
'Rainfall':[100,80,1000,200,200,100,50,100,200,100,50,100],
'Rainfall_precipitation':[80,70,90,10,20,30,50,90,20,80,50,10],
'Temp':[32,27,32,31,30,28,27,25,26,33,34,31]
})
stack_data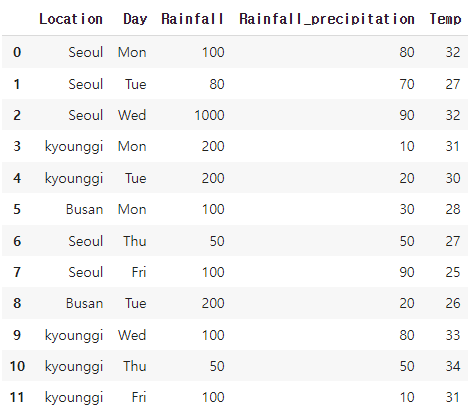
인덱스 변경하기
new_stack_data = stack_data.set_index(['Location','Day'])
new_stack_data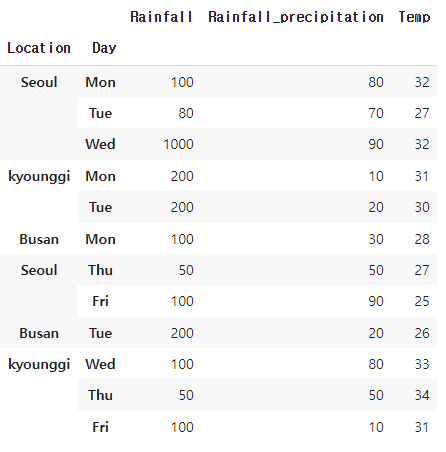
현재 인덱스는 2개가 존재한다. unstack하여 인덱스를 위로 올릴 수 있다.
new_stack_data = stack_data.set_index(['Location','Day'])
# 0은 Location, 1은 Day가 된다.
new_stack_data.unstack(0)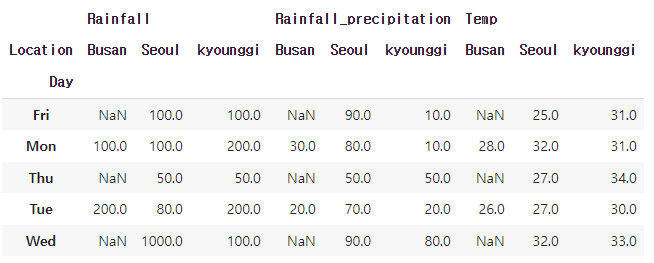
unstack하여 인덱스를 위로 올린 것을 다시 stack으로 되돌릴 수 있다.
new_stack_data = stack_data.set_index(['Location','Day'])
new_stack_data2 = new_stack_data.unstack(1)
new_stack_data2.stack(1)