
시각화로 데이터 탐색
일변량 시각화 탐색
선 그래프
days_left별 가격의 변화를 선 그래프로 나타내려변 다음과 같이 작성한다.
import pandas as pd
import matplotlib.pyplot as plt
df = pd.read_csv('/content/drive/MyDrive/Colab Notebooks/Clean_Dataset.csv', encoding='cp949')
# 남은 일자별 수치데이터들의 평균
days_left = df.groupby('days_left').mean()
# 시각화 영역 지정
plt.figure()
# 해당 데이터의 특정 속성에 대한 그래프 만들기
plt.plot(days_left['price'])
# x축 이름
plt.xlabel('Days_left')
# y축 이름
plt.ylabel('Price')
# 그래프 그리기
plt.show()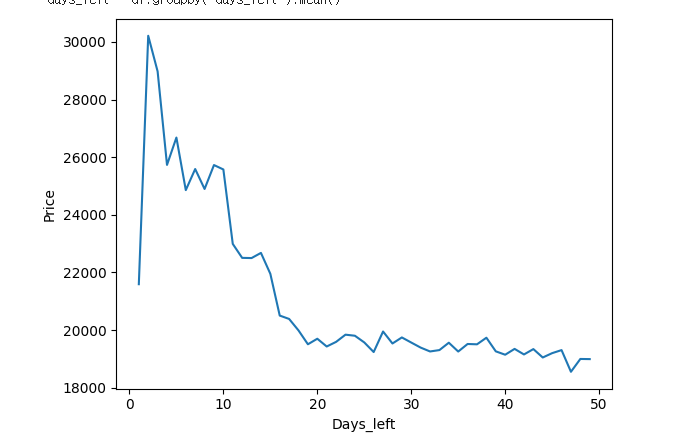
막대 그래프
범주에 대한 통계 데이터나 양을 막대 모양으로 나타내는 그래프
import pandas as pd
import matplotlib.pyplot as plt
df = pd.read_csv('/content/drive/MyDrive/Colab Notebooks/Clean_Dataset.csv', encoding = 'cp949')
airline = df.groupby(['airline']).mean()
# 데이터프레임의 인덱스를 label 변수에 저장
label = airline.index
plt.figure()
plt.bar(label, airline['price'])
plt.xlabel('Airline')
plt.ylabel('Price')
plt.show()
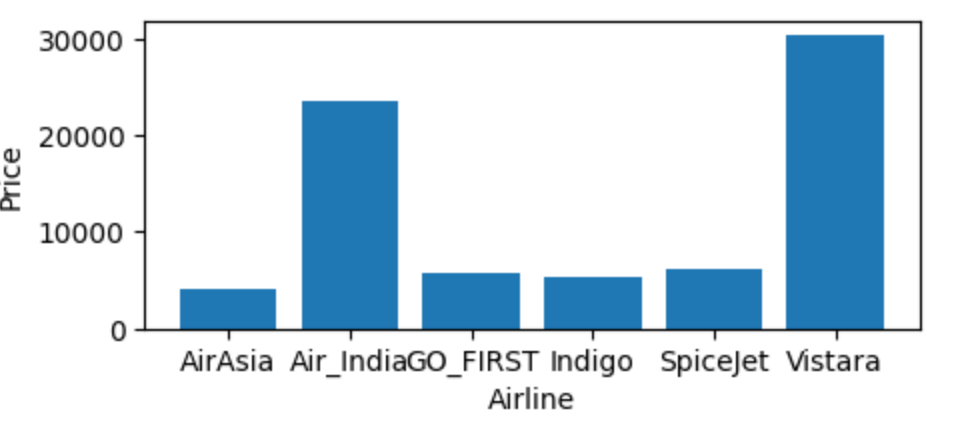
파이그래프
전체 100으로 놓고 각각의 비율대로 나누어 표기
데이터를 빈도수로 맞추고 데이터 라벨을 생성하여 그래프를 만든다.
import pandas as pd
import matplotlib.pyplot as plt
df = pd.read_csv('/content/drive/MyDrive/Colab Notebooks/Clean_Dataset.csv', encoding = 'cp949')
# 해당 속성의 빈도수
departure_time = df['departure_time'].value_counts()
plt.figure(figsize=(5,4))
plt.pie(departure_time, labels=departure_time.index, autopct='%.1f%%')
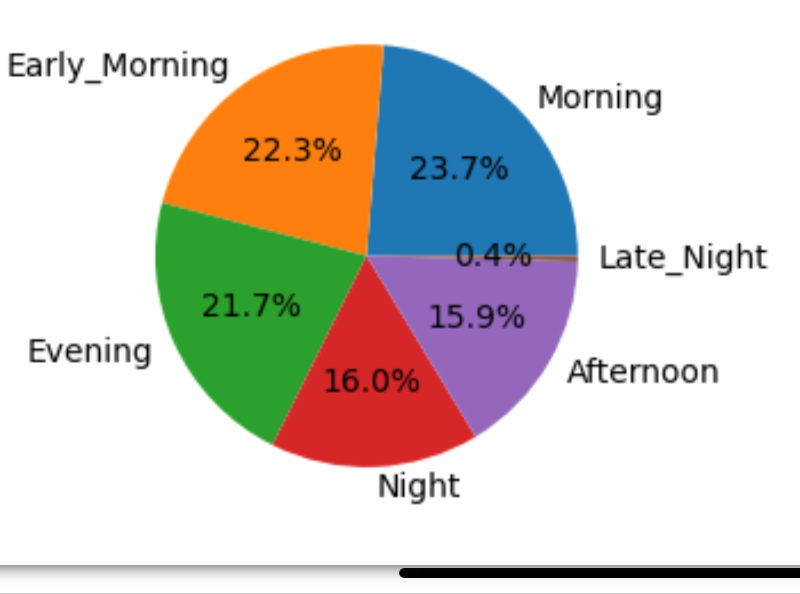
히스토그램
데이터의 특성과 분포를 파악하는 역할을 하며 빈도, 빈도밀도, 확률 등의 분포를 그릴 때 사용
import pandas as pd
import matplotlib.pyplot as plt
df = pd.read_csv('/content/drive/MyDrive/Colab Notebooks/Clean_Dataset.csv', encoding = 'cp949')
plt.figure(figsize=(5,3))
# duration을 10개의 구간으로 나눠서 히스토그램 그리기
plt.hist(df['duration'], bins=10)
# duration을 20개의 구간으로 나눠서 히스토그램 그리기
plt.hist(df['duration'], bins=30)
plt.xlabel('Duration')
plt.ylabel('Flights')
# 우측 상단에 범례를 만듦
plt.legend(('Bins 10', 'Bins 30'))
plt.show()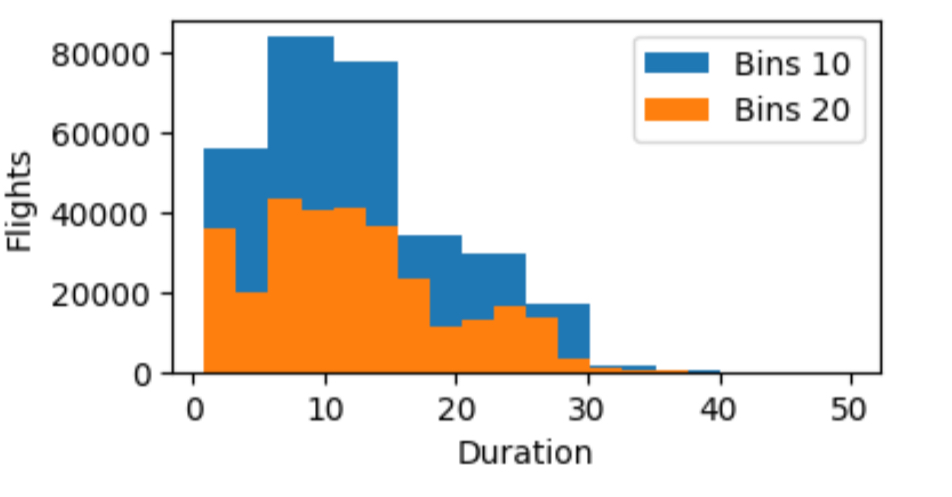
상자 그래프
사분위수를 중심으로 수치적 요약 통계자료를 시각화하는 그래프
import pandas as pd
import matplotlib.pyplot as plt
df = pd.read_csv('/content/drive/MyDrive/Colab Notebooks/Clean_Dataset.csv', encoding = 'cp949')
plt.figure(figsize=(4,2))
# price를 list화 하여 상자 그래프로 만듦
plt.boxplot(list(df['price']))
plt.ylabel('Price')
plt.show()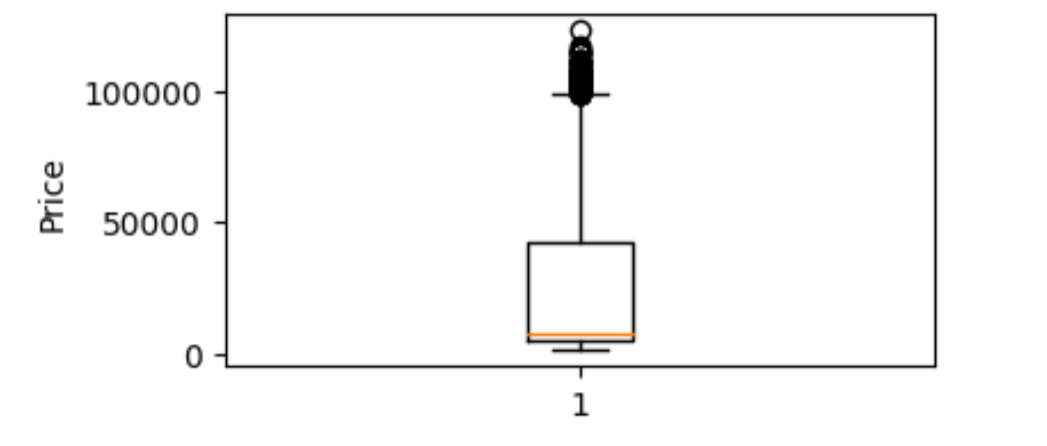

AllTimeDevelop