
수치형 데이터 정제하기
이상치와 결측지
- 결측지
- 결측지란 값이 없는 것을 의미(null)
- 수집 누락, 데이터 유실 등으로 인한 결측지 발생
- 이상치
- 보통 관측된 데이터의 범위에서 많이 벗어난 아주 작은 값이 나 큰 값(outlier)
결측지 파악하기
import pandas as pd
import numpy as np
# 랜덤 수를 불러오기 위한 import
import random
df = pd.read_csv('/content/drive/MyDrive/Colab Notebooks/Clean_Dataset.csv',encoding='cp949')
# 지정인덱스 제거
df.drop([df.columns[0]], axis=1, inplace=True)
# 같은 결과 출력을 위해 시드 고정
random.seed(2023)
np.random.seed(2023)
# 랜덤한 위치에 결측치 5000개를 포함한 데이터 df_na 생성, 5000개의 결측치 생성
df_na = df.copy()
for i in range(0,5000) :
df_na.iloc[random.randint(0,300152), random.randint(0,10)] = np.nan
# 결측치 처리 여부 확인을 위한 1번 3번 인덱스 전체 결측치 처리하기
df_na.iloc[1] = np.nan
df_na.iloc[3] = np.nan
#결측지가 아닌 값 확인
df_na.info()결측치를 확인하려면 다음과 같이 입력한다.
df_na.isnull().sum(axis=0)결측지 처리하기
결측치는 데이터를 분석할 때 반드시 처리해야한다.
성능이 좋은 분석 모델을 만드는 데 중요한 요소로 추가 조사나 정확한 예측으로 결측치를 채우는 것이 좋다.
결측치 삭제하기
결측치를 쉽게 처리 할 수 있으나 데이터의 손실이 생겨 데이터 특성 모두 반영하지 못하는 문제가 발생할 수 있으므로 결측치의 비중이 적을 때 사용하는 것이 좋다.
# 결측치를 하나라도 가지는 행 모두 삭제
df_na = df_na.dropna()
df_na.info()# 모든 데이터가 결측치인 행만 삭제하기
df_na = df_na.dropna(how='all')
df_na.info()칼럼 제거하기
칼럼을 제거하였을 때 데이터 손실을 감안하는 것은 좋은 선택이 아니지만 고려해볼 만 하다.
# 결측치가 있는 칼럼 삭제
df_na = df_na.drop(['stops','flight'], axis = 1)
df_na.info()결측치 대체하기
가장 무난하고 많이 사용하는 방법으로 평균값, 중간값, 최빈값을 가장 많이 사용하지만 어떤 값을 사용해도 정확한 값과 같지는 않기 때문에 데이터의 오차가 발생 할 수 있다. 또한 너무 많은 데이터를 같은 값으로 대체하면 데이터의 편향이 발생 할 수 있으므로 주의한다.
# 평균값으로 대체
df_na = df_na.fillna(df_na.mean())
df_na.info()이전, 이후 값 사용하기
- fillna 옵션
- ffill : 이전 인덱스에 있는 값을 사용해서 결측치 채움
- bfill : 다음 인덱스에 있는 값을 사용해서 결측치 채움
# 다음 인덱스에 있는 값으로 결측치 채움
df_na = df_na.fillna(method = 'bfill')
df_na.info()이상치 파악하기
Z-score로 확인하기
Z-score = (Xi -X의 평균) / X의 표준편차
# z-score로 이상치 확인하기 : z = (Xi - X의 평균)/X의 표준편차
df[(abs((df['price']-df['price'].mean()/ df['price'].std())))>1.96]
위 그림과 같이 1.96 이상의 수치를 이상치로 가정한다면 해당 데이터는 이상치로 검출된 것이다.
IQR로 확인하기
IQR은 제 3사분위수에서 제 1사분위수를 뺀 값을 나타내는 것으로 제 1사분위 수에서 IQR의 1.5배만큼을 뺀 값보다 작거나, 제 3사분위수에서 IQR의 1.5배 만큼을 더한 값보다 큰 경우 이상치로 판단한다.
import pandas as pd
import matplotlib.pyplot as plt
df = pd.read_csv('/content/drive/MyDrive/Colab Notebooks/Clean_Dataset.csv', encoding='cp949')
#df[(abs((df['price'] - df['price'].mean()) / df['price'].std()))> 1.96]
# IQR 기준 이상치를 확인하는 함수
def findOutliers(df, column):
#제 1사분위수 q1 구하기
q1 = df[column].quantile(0.25)
#제 3사분위수 q3 구하기
q3 = df[column].quantile(0.75)
#IQR의 1.5배 IQR 구하기
iqr = 1.5 *(q3 - q1)
# 제 3사분위수에서 IQR의 1.5배보다 크거나 제 1사분위수에서 IQR의 1.5배보다 작은 값만 저장한 데이터 outlier만들기(이상치 outlier)
outlier = df[(df[column] > (q3 + iqr)) | (df[column] < (q1 - iqr))]
#이상치 갯수를 리턴 시키기
return len(outlier)
# price, duration, days_left에 대하여 이상치 개수 확인하기
print('Price IQR Outliers : ', findOutliers(df, 'price'))
print('duration IQR Outliers : ', findOutliers(df, 'duration'))
print('days_left IQR Outliers : ', findOutliers(df, 'days_left'))
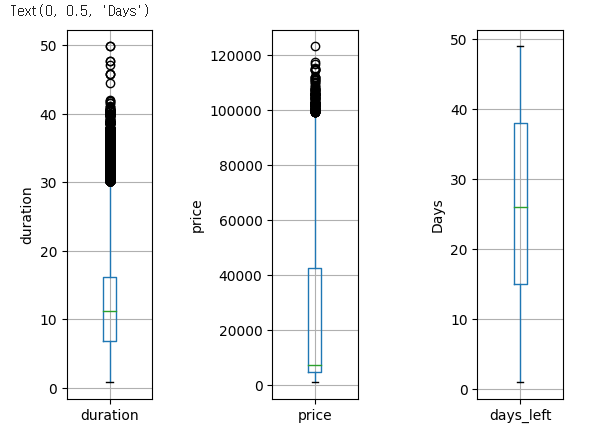
다음과 같이 시각화를 위해 작성할 수도 있다.
plt.figure()
# subplot 시각화창에서 보여주는 위치를 결정한다.
#첫 번째 subplot : 1행 5열을 나눈 영역에서 첫 번째 영역
plt.subplot(151)
df[['duration']].boxplot()
plt.ylabel('duration')
#두 번째 subplot : 1행 5열을 나눈 영역에서 세 번째 영역
plt.subplot(153)
df[['price']].boxplot()
plt.ylabel('price')
#세 번째 subplot : 1행 5열을 나눈 영역에서 다섯 번째 영역
plt.subplot(155)
df[['days_left']].boxplot()
plt.ylabel('Days')
이상치 처리하기
이상치 데이터 삭제하기
z-score를 통해 발견된 이상치를 제거하기 위해서는 다음과 같이 처리한다.
1. z-score의 값의 인덱스 리스트를 변수에 저장한다.
2. 데이터를 drop하여 저장한다.
import pandas as pd
import matplotlib.pyplot as plt
df = pd.read_csv('/content/drive/MyDrive/Colab Notebooks/Clean_Dataset.csv', encoding='cp949')
# 원본의 데이터를 손상하지 않기위해 복사를 한다.
df_copy = df.copy()
#인덱스를 추출하여 변수에 저장하기
outlier = df[(abs((df['price'] - df['price'].mean()) / df['price'].std()))> 1.96].index
#저장된 인덱스를 이용하여 이상치 데이터 삭제하기
df_copy = df_copy.drop(outlier)
df_copy.info()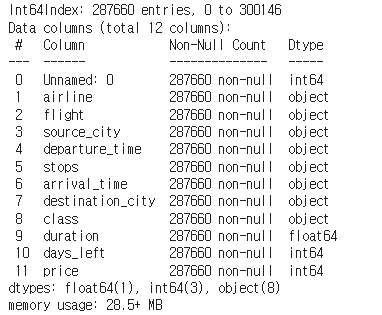
위와 같이 이상치 데이터를 제외하고 데이터가 저장되었다.
df_copy[['price']].boxplot()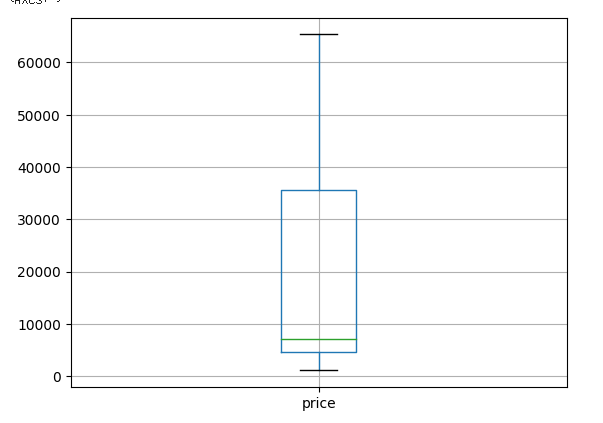
또한 boxplot으로 확인한 데이터에서도 이상치가 발견되지 않았다.
이상치 데이터 대체하기
이상치 데이터를 대체할 때 함수를 만들어서 대체 할 수 있다.
import pandas as pd
import matplotlib.pyplot as plt
df = pd.read_csv('/content/drive/MyDrive/Colab Notebooks/Clean_Dataset.csv', encoding='cp949')
# IQR 기준 이상치를 대체하는 함수 만들기
def changeOutliers(df, column) :
# 제 1사분위수 q1
q1 = df[column].quantile(0.25)
# 제 3사분위수 q3
q3 = df[column].quantile(0.75)
#IQR의 1.5배 IQR 구하기
iqr = 1.5 * (q3-q1)
#이상치를 대체하는 Min, Max 값 설정
Min = (q1 - iqr)
Max = q3 + iqr
# Max 보다 큰 값은 Max로 Min보다 작은 값은 Min으로 대체하기
df.loc[df[column] > Max , column] = Max
df.loc[df[column] < Min , column] = Min
return(df)
# 이상치를 대체하는 함수를 사용하여 이상치가 없는 copy_df를 만든다.
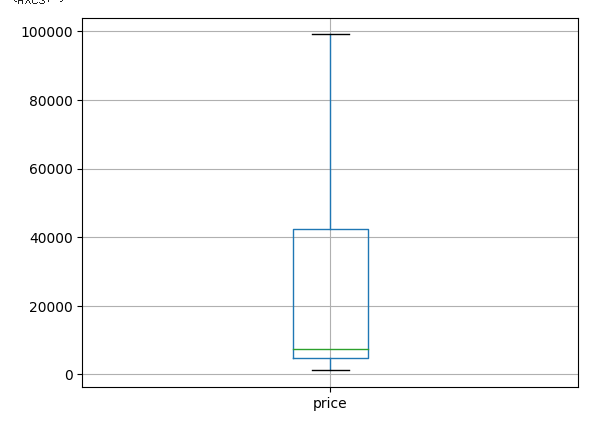
copy_df = changeOutliers(df, 'price')
copy_df[['price']].boxplot()다음과 같이 price에는 이상치가 존재하지 않는다.
info() 함수로 살펴보았을 때 데이터의 갯수는 원본과 동일하다.
구간화 하기
구간화(binning)는 연속형 데이터를 특정 구간으로 나누어 범주형 또는 순위형으로 변환하는 방법이다. 예를 들어 수능 점수를 등급으로 변환하거나, 나이를 세대로 나누는 것을 말한다. 구간화하면 이상치로 발ㅇ생 가능한 문제를 줄이고, 결과에 대한 해석이 쉬어질 수 있다.
동일 길이로 구간화하기
동일 길이로 사용자가 구간 값을 직접 입력하여 구간화 시킬 수 있다.
구간화는 다음과 같이 사용한다.
pandas.cut(구간화 할 속성, bins = [정수1, 정수2, 정수3....], labels = [구간의 명칭])정수1 ~ 정수2, 정수2 ~ 정수3과 같이 구간화 되며 순서대로 구간의 명칭이 적용된다.
import pandas as pd
df = pd.read_csv('/content/drive/MyDrive/Colab Notebooks/Clean_Dataset.csv', encoding='cp949')
# 비행시간을 0 ~ 5, 5 ~ 10, 10 이상의 3개 구간으로 나누어 거리 칼럼 생성하기
df['distance'] = pd.cut(df['duration'], bins = [0,5,10, df['duration'].max()], labels=['short', 'medium', 'long'])
df[['duration', 'distance']]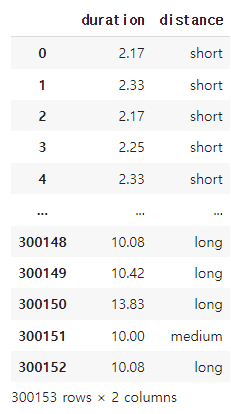
동일 개수로 구간화하기
총 개수에서 동일 개수로 구간화시킬 수 있다.
구간화는 다음과 같다.
pandas.qcut(구간화할 속성, 구간 갯수, labels =[구간별 명칭])
# 항공권 가격(price)을 3개 구간으로 동일하게 나누어 항공권 가격 비율 칼럼 생성하기
df['price_rate'] = pd.qcut(df['price'], 3, labels = ['cheap', 'nomal', 'expensive'])
df[['price_rate']].value_counts()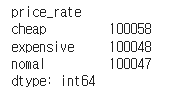
다음과 같이 3개의 구간별로 데이터가 나누어졌다.

감사합니다. 이런 정보를 나눠주셔서 좋아요.