
키
-
조건에 맞는 데이터를 찾기 위한 식별자
-
관계형 데이터베이슨 테이블처럼 데이터를 관리
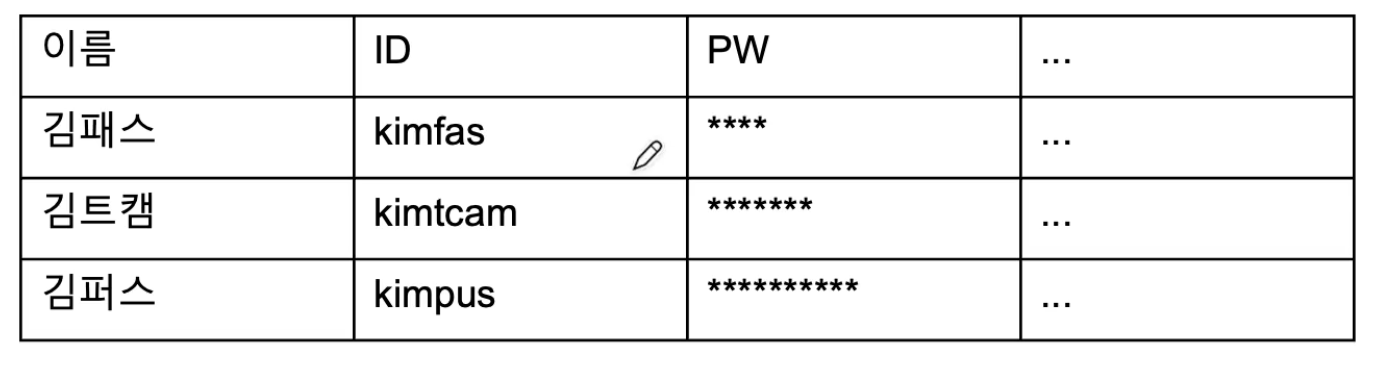
-
각각의 행들을 특정 지을 수 있는 속성 == 기본 키
-
중복되어서는 안되고 고유, Null 이어서는 안된다. 때로는 여러 열을 묶어 하나의 기본 키로 삼기도 한다.
외래키
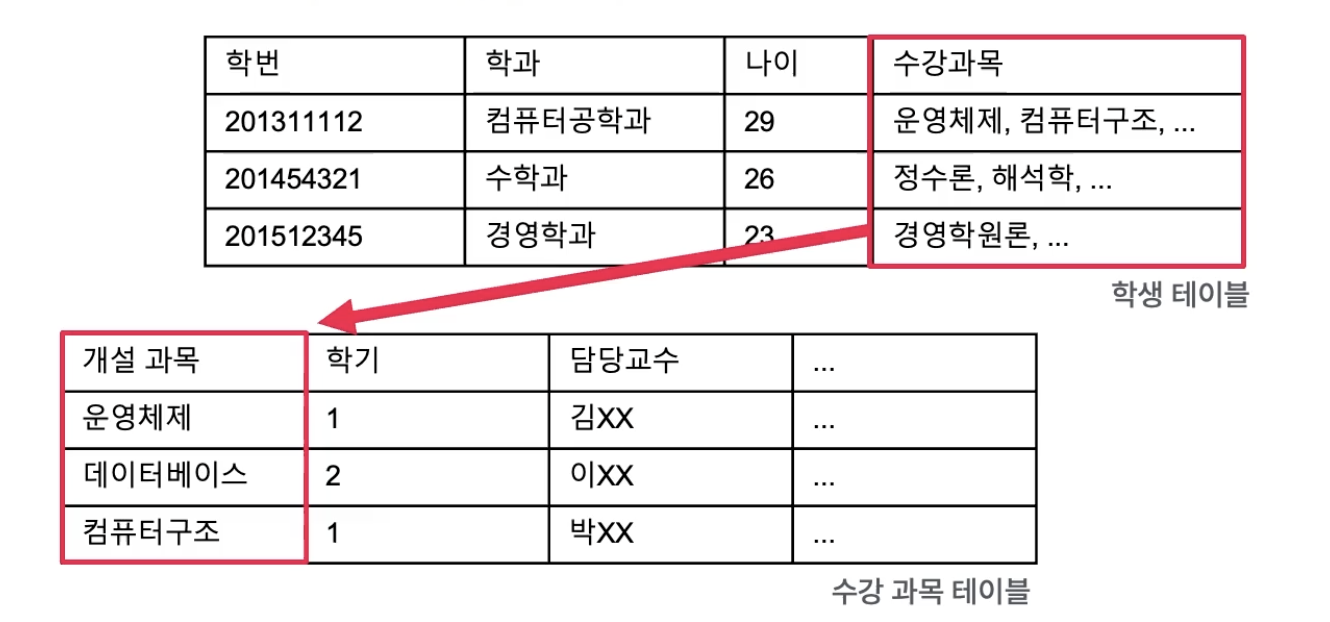
두 테이블을 연관시키는 것
- SET NULL : 전부 Null값으로 채워라
- CASCADE : 함께 변경해라
- RESTRICT : 업데이트 삭제를 제한
데이터베이스와 테이블 생성하기
CREATE DATABASE my_database;
SHOW SCHEMAS;
# 또는
SHOW DATABASES;
USE my_database; # 해당 데이터 베이스를 사용해야 데이터베이스에 테이블 생성이 가능데이터베이스 제거
DROP DATABASE my_database;테이블 생성
CREATE TABLE users (
id INT AUTO_INCREMENT PRIMARY KEY, -- 고유 ID (자동 증가)
username VARCHAR(50) NOT NULL, -- 사용자명 (필수 입력)
email VARCHAR(100) NOT NULL, -- 이메일 (필수 입력)
password VARCHAR(100) NOT NULL, -- 비밀번호 (필수 입력)
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP -- 생성 시간 (기본값 현재 시간)
);
데이터 타입
숫자형 데이터 타입
- 정수형 (Integer Types)
- TINYINT: -128에서 127까지의 작은 정수 저장 (UNSIGNED: 0 ~ 255).
- SMALLINT: -32,768에서 32,767까지의 중간 크기 정수 저장 (UNSIGNED: 0 ~ 65,535).
- MEDIUMINT: -8,388,608에서 8,388,607까지의 정수 저장 (UNSIGNED: 0 ~ 16,777,215).
- INT 또는 INTEGER: -2,147,483,648에서 2,147,483,647까지의 정수 저장 (UNSIGNED: 0 ~ 4,294,967,295).
- BIGINT: -9,223,372,036,854,775,808에서 9,223,372,036,854,775,807까지의 큰 정수 저장 (UNSIGNED: 0 ~ 18,446,744,073,709,551,615).
- 실수형 (Floating-Point and Fixed-Point Types)
- FLOAT(M, D): 소수점 아래 D 자리까지 M 자리의 부동 소수점 숫자를 저장 (4바이트).
- DOUBLE(M, D): 소수점 아래 D 자리까지 M 자리의 부동 소수점 숫자를 저장 (8바이트).
- DECIMAL(M, D) 또는 NUMERIC(M, D): 정확한 소수점 계산이 필요한 경우 사용되는 고정 소수점 숫자. M은 전체 자릿수, D는 소수 자릿수를 의미.
문자형 데이터 타입
- CHAR(M): 고정 길이 문자열. M은 최대 길이(0~255). 길이가 고정되어 있을 때 사용.
- VARCHAR(M): 가변 길이 문자열. M은 최대 길이(0~65,535). 문자열의 길이가 가변적일 때 사용.
- TEXT: 큰 텍스트 데이터를 저장할 때 사용 (최대 65,535자).
- TINYTEXT: 작은 텍스트를 저장할 때 사용 (최대 255자).
- MEDIUMTEXT: 중간 크기의 텍스트를 저장할 때 사용 (최대 16,777,215자).
- LONGTEXT: 매우 큰 텍스트를 저장할 때 사용 (최대 4,294,967,295자).
날짜 및 시간형 데이터 타입
- DATE: YYYY-MM-DD 형식의 날짜를 저장 (예: 2023-09-23).
- TIME: HH:MM
- 형식의 시간을 저장 (예: 13:45:30).
- DATETIME: YYYY-MM-DD HH:MM
형식의 날짜와 시간을 저장 (예: 2023-09-23 13:45:30). - TIMESTAMP: UNIX 타임스탬프 형식으로 날짜와 시간을 저장. 자동으로 현재 시간으로 설정되며, UTC 기준으로 저장.
- YEAR: 연도를 저장. 2자리 또는 4자리로 표현 가능 (예: 2024).
기타 데이터 타입
- ENUM: 열거형. 미리 정의된 값 중 하나만 저장할 수 있는 문자열 데이터 타입. 예: ENUM('small', 'medium', 'large').
- SET: 하나 이상의 미리 정의된 값들을 저장할 수 있는 문자열 데이터 타입. 예: SET('a', 'b', 'c').
- BLOB: 바이너리 데이터를 저장할 때 사용 (최대 65,535바이트).
- TINYBLOB, MEDIUMBLOB, LONGBLOB: 각각의 크기에 따라 다른 용량의 바이너리 데이터를 저장.
테이블 조회, 변경
SHOW TABLES;
DESCRIBE table_name; # 테이블 구조 조회
RENAME TABLE old_table_name TO new_table_name; # 테이블 이름 변경ALTER
# 컬럼 추가
ALTER TABLE table_name
ADD COLUMN new_column_name VARCHAR(100) NOT NULL;
#컬럼 수정
ALTER TABLE table_name
MODIFY COLUMN column_name new_data_type;
#컬럼 타입 변경
ALTER TABLE table_name
CHANGE COLUMN old_column_name new_column_name new_data_type;
# 컬럼 삭제
ALTER TABLE table_name
DROP COLUMN column_name;
# 컬럼에 키 추가
ALTER TABLE table_name
ADD PRIMARY KEY (column_name);
# 컬럼에 인덱스 추가
ALTER TABLE table_name
ADD INDEX index_name (column_name);
#컬럼에 인덱스 삭제
ALTER TABLE table_name
DROP INDEX index_name;
# 테이블 이름 변경
ALTER TABLE old_table_name
RENAME TO new_table_name;테이블 삭제
# 구조는 남기고 내용 모두 삭제
TRUNCATE TABLE table_name;
# 구조까지 완전삭제
DROP TABLE table_name;INSERT
INSERT INTO table_name (column1, column2, ...)
VALUES (value1, value2, ...);- Not Null 제약이 걸린 컬럼을 넣지 않고 insert 요청하면 에러 발생
SELCET
SELECT column1, column2, ...
FROM table_name
WHERE condition
ORDER BY column1 ASC|DESC
LIMIT number;연산 및 집계 함수
SELECT COUNT(*) FROM users; # 행의 갯수
SELECT SUM(salary) FROM employees; # 특정 열의 행들의 합
SELECT AVG(salary) FROM employees;
SELECT MAX(salary) FROM employees;
SELECT MIN(salary) FROM employees;LIKE를 이용한 패턴 검색
SELECT * FROM users
WHERE name LIKE 'A%'; # A로 시작하는 데이터
SELECT * FROM users
WHERE name LIKE '_a%'; # 두번째 문자가 a로 시작하는 데이터
SELECT * FROM users
WHERE email LIKE '%@example.com'; # @example.com 으로 끝나는 데이터
GROUP BY & HAVING
SELECT column1, AGGREGATE_FUNCTION(column2)
FROM table_name
GROUP BY column1;
#부서별로 직원 수를 계산:
SELECT department, COUNT(*)
FROM employees
GROUP BY department;
SELECT column1, AGGREGATE_FUNCTION(column2)
FROM table_name
GROUP BY column1
HAVING AGGREGATE_FUNCTION(column2) condition;
#직원이 10명 이상인 부서만 조회:
SELECT department, COUNT(*)
FROM employees
GROUP BY department
HAVING COUNT(*) >= 10;서브 쿼리
#orders 테이블에서 total_amount가 모든 order_amount보다 큰 고객 찾기:
SELECT customer_id
FROM customers
WHERE total_amount > (SELECT MAX(order_amount) FROM orders);
#departments 테이블에 존재하지 않는 부서의 employees 데이터 찾기:
SELECT name
FROM employees
WHERE department_id NOT IN (SELECT id FROM departments);
UPDATE
UPDATE table_name
SET column1 = value1, column2 = value2, ...
WHERE condition;
#users 테이블에서 id가 1인 사용자의 email을 수정:
UPDATE users
SET email = 'new_email@example.com'
WHERE id = 1;주의사항

DELETE
DELETE FROM table_name
WHERE condition;
# age가 18 이하인 사용자 삭제
DELETE FROM users
WHERE age <= 18;주의사항


AllTimeDevelop