Abstract
자연어이해는 원문함의, 질의응답(Question Answering), 의미 유사성 평가, 문서분류 등 넓은 범위의 과제로 이루어져 있다. unlabeled data들은 많긴 하지만, 특정 task들에 맞는 labelded data는 부족하고, 이는 모델이 적절히 수행하도록 만드는 것을 어렵게 한다.
이 논문에서는 언어모델을 다양한 unlabeled data로 생성적 사전학습(generative pre-training)을 시킨 후 각 특정 과제에 맞춘 fine-tuning 과정을 거쳐 성능향상을 이끌어냈다.
이 논문에서 task에 대한 사전 지식이 없는(task-agnostic) 모델은 특정과제에 특화된 모델 성능을 뛰어넘는다. 테스트된 12개의 tasks 중 9개에서 SOTA를 달성하였다.
1. Introduction
raw text를 효과적으로 학습하는 능력은 NLP에서 지도학습에 대한 의존도를 낮추는 데 있어 매우 중요하다. 대부분의 딥러닝 방법은 충분한 혹은 차고넘칠정도의 labeled data를 필요로 하는데, 이는 분류된 자원의 부족으로 인한 많은 도메인으로의 응용이 힘들어진다. 이러한 상황에서 unlabeled data로부터 언어적 정보를 얻어낼 수 있는 모델은 힘들게 labeled data를 만드는 것의 훌륭한 대안이 될 뿐만 아니라, 괜찮은 지도 방법이 있다 하더라도 비지도학습이 더 좋은 결과를 얻기도 한다.
그러나 unlabeled text에서 단어 수준 정보 이상의 것을 얻는 것은 두 가지 이유로 어렵다.
1. 어떤 최적화 목적함수가 전이(transfer)에 유용한 텍스트 표현(representation)을 배우는 데 효과적인지 불분명하다.
2. 학습된 representation을 다른 과제로 전이하는 가장 효과적인 방법에 대한 일치된 의견이 없다.
이 논문에서는 unsupervised pre-training과 supervised fine-tuning을 합친 준 지도학습 방식을 제안한다. labeled data를 가지고 바로 정보를 얻어내기 보다, unlabeled data로 생성적 사전학습(generative pre-training)을 시킨 후 각 특정 과제에 맞춘 fine-tuning 을 하는것이 더 도움이 된다는 것이다.
이 학습은 크게 2단계를 거친다.
- 모델의 초기 parameter를 학습하기 위해 unlabled data에 대한 목적함수(objective function)를 사용한다.
- 학습된 parameter를 사용하여 목표 task별 supervised objective로 fine-tuning을 진행한다.
그리고 모델 구성시 Transformer를 사용한다. 이 모델은 RNN 등에 비해 장거리 의존성을 다루는 데 뛰어나 더 많은 구조화된 memory를 쓸 수 있게 한다.
2. Related Work
Semi-supervised learning for NLP
본 논문의 모델은 semi-supervised learning에 속하며 이 분야는 sequence labeling이나 text classification과 같은 task에 잘 적용된다.
초기의 연구는 나중에 pre-trained model의 특징으로 사용될, 단어수준이나 구 수준의 통계를 계산하기 위해 unlabedled data를 사용했다. 지난 몇 년간 연구자들은 unlabeled corpora로부터 학습된 단어 embedding의 장점(다양한 과제에서의 성능 향상 가능성)을 발견했다. 그러나 이 접근법은 주로 단어 수준 표현을 학습할 뿐이다. 최근의 연구는 미분류 데이터로부터 단어수준 이상의 정보를 학습하려 하고 있다
Unsupervised pre-training
GPT와 유사한 연구는 신경망을 언어모델링 목적함수를 사용하여 사전학습시키고 지도 하에 목표 Task에 맞춰 fine-tuning하는 것을 포함한다. 그러나 어떤 언어적 정보를 포착하는 데 있어 LSTM의 사용은 이를 좁은 범위에 한정시킨다. 하지만 Transformer를 사용함으로써 넓은 범위에 걸친 언어적 구조와 정보를 학습할 수 있게 하였고 나아가 다양한 과제에 사용할 수 있게 되었다.
Auxiliary training objectives
보조 학습 목적함수를 추가하는 것은 준지도학습의 대안중 하나이다.
과거에는 POS tagging, chunking, named entity recognition, language modeling 등을 이용해서 semantic role labeling의 성능을 향상시킨 사례가 있다. 이번 논문에서도 보조적인 objective를 사용한다.
3. Framework
학습과정이 2단계로 이뤄진다.
- Unsupervised pre-training
- 큰 규모의 텍스트를 기반으로 대용량 언어 모델을 학습
- Supervised fine-tuning
- fine-tuning을 거쳐 레이블이 지정된 데이터를 사용하여 모델을 각 Task에 적용
Unsupervised pre-training
unlabeled된 많은 corpus를 가진 Text로 높은 수용력을 가진 모델을 학습하는 과정이다.
unsipervised corpus of tokens인 ={}이 주어질 때, 다음 우도(likelihood)를 최대화하도록 표준언어모델링 목적함수를 사용한다
위 수식이 GPT-1의 pre-training을 나타내는 수식이다.
k는 window size이고 P는 조건부확률을 의미한다. i번째 단어 를 예측해나가기 위해 이전 k개의 단어를 활용하며, 확률적 경사하강법을 이용해 학습한다. 또한 해당 objective는 Transformer decoder layer를 여러 층 쌓아서 사용한다. 입력 Token에 multi-headed self-attention을 적용한 후, 목표 token에 대한 출력분포를 얻기 위해 position-wise feedforward layer를 적용한다
여기서
- : token들의 context vector
- n: the number of layers
- : token embedding matrix
- : position embedding matrix
Supervised fine-tuning
윗단계에서 를 따라 모델학습을 한뒤, parameter를 목표 Task에 맞춰 fine-tuning을 진행한다.
첫번째 식은 m개의 token으로 이뤄진 sequence가 주어져있고 y라는 정답이 주어졌을 때, transformer_block을 통과한 값을 linear layer와 softmax를 적용해 확률값을 계산해낸다.
두번째 식은 Supervised fine-tuning을 나타내는 수식이다. 주어져있는 토큰의 시퀀스에 따라 정답이 무엇인지에대한 확률값을 최대화하는 것이다. 여기서 는 labeled dataset을 의미한다.
추가적으로 저자들이 Unsupervised pre-training 단계에서 unsupervised corpus를 가지고 목적함수를 pre-training하는데서 그치지 않고, 우리가 현재 보유하고있는 supervised용 corpus()에 대한 language model도 함께 update를 해주면(보조 목적(auxiliary objective)로써 language model을 추가) 두가지 장점이 있다고 주장한다.
1. 일반화 능력 향상
2. 수렴속도 향상
구체적으로, weight 에 대해 목적함수를 최적화한다
결국 fine-tuning시에 추가된 parameter는 linear layer의 가중치행렬인 밖에 없다.
Task-specific Input Transformation
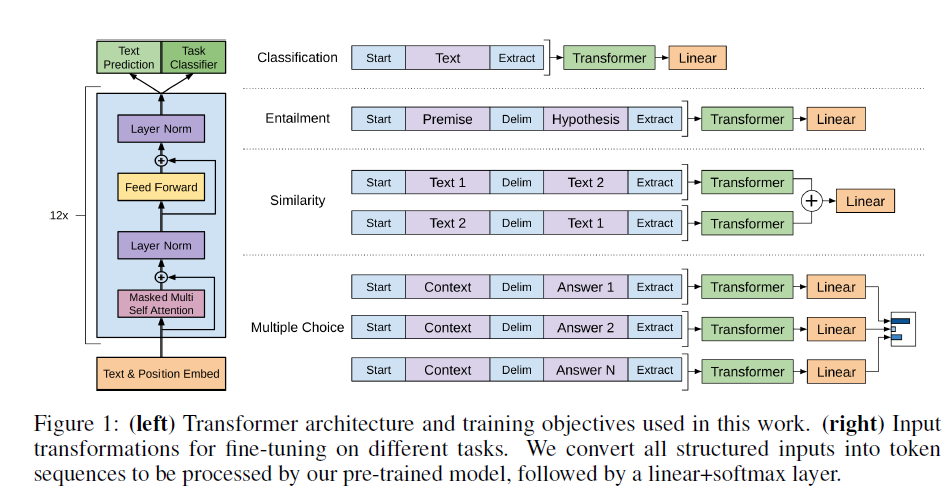
위 그림은 목표 Task별 달라지는 input을 나타낸 것이다. 모두 동일하게 start token으로 시작해서 Extract token으로 끝나는 구조로 이줘져 있고, 여러문장이 들어오는 경우에만 중간에 Delimeter token을 삽입한다.
similarity task가 잘 이해가 되지 않는데 Entailment task와 동일하게 넣어도 유사도는 구할 수 있지 않나 싶다. 아마 저자가 실험을하면서 저런 구조가 더 효과적인것이라고 한걸까 싶다.
4. Experiments
언어모델을 학습하기 위한 dataset으로 7천 개의 다양한 분야의 미출판 책에 대한 내용을 포함하는 BooksCorpus를 사용한다.
실험시 사용 dataset은 아래와 같다.
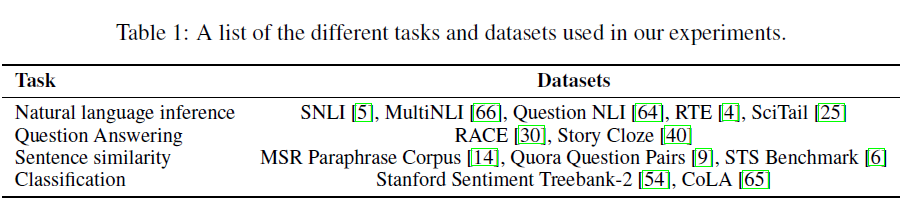
Natural Language Inference
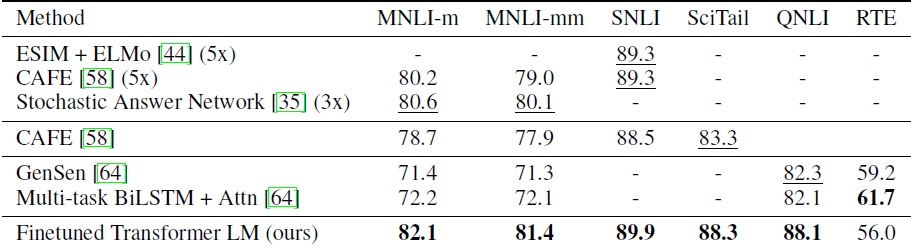
Question Answering
Semantic Similarity & Classification
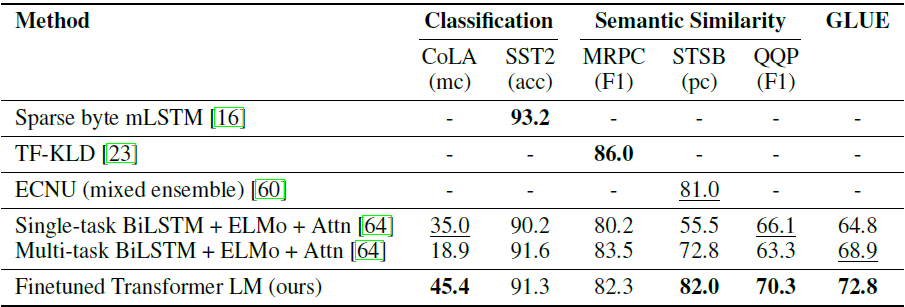
5. Analysis(Ablation Study)
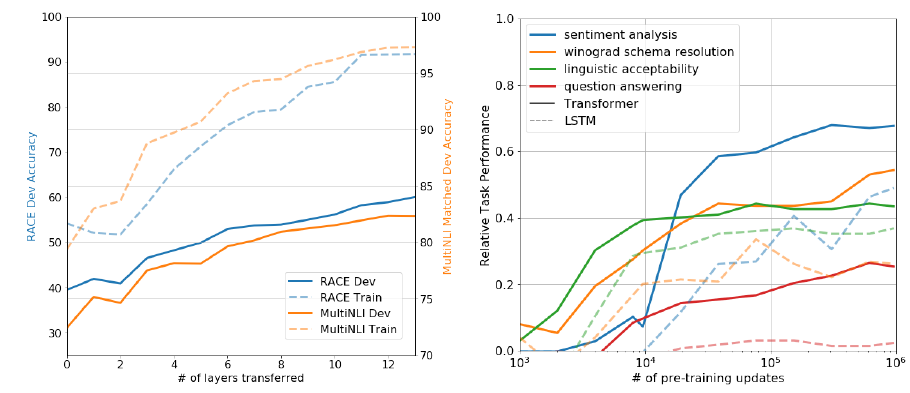
왼쪽 그래프는 decoding block개수에 따른 성능을 보여주고 있다. 오른쪽은 zero-shot관련하여 보여주는거같은데 당장은 이해가 안간다.(추후 게시)
ablation study
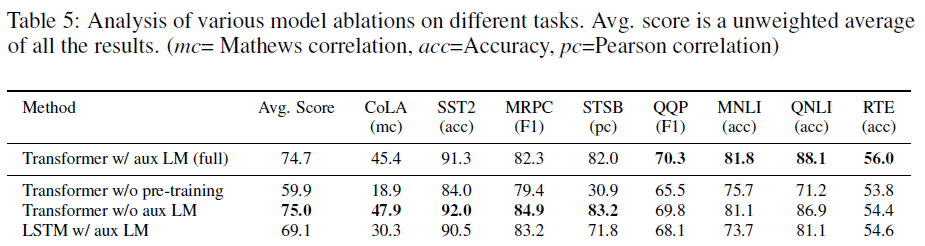
맨위는 GPT-1모델을 의미하고 밑에는 아래와 같다.
1. Pre-training없이 Supervised learning 목적함수로 사용
2. Fine-tuning 단계에서 Auxiliary objective없이 진행(논문에서는 )
3. Transformer 대신 LSTM으로 사용
- 대용량 dataset은 auxiliary objective이 도움이 되지만, dataset이 작을때는 corpus-specific한 language model을 fine-tuning하지 않는것이 오히려 성능이 좋다.
