
명령어 파이프라이닝
CPU의 성능은 컴퓨터시스템의 프로그램 처리 시간에 직접 영향을 주기 때문에 속도를 향상시키기 위하여 여러 가지 방법들이 사용되고 있다. 가장 간단하면서 분명한 효과를 보는 방법이 명령어 파이프라이닝이다. 명령어 파이프라이닝은 명령어 실행에 사용하는 하드웨어를 여러 단계로 분할해서 처리 속도를 높여주는 기술이다. 동시에 명령어를 처리하게 해서 CPU의 성능을 높여준다.
2-단계 명령어 파이프라인
명령어 사이클은 인출 사이클과 실행 사이클로 나뉘는데 이는 서로 독립적인 모듈로 구성한다면 각 모듈이 서로 다른 명령어를 동시에 처리할 수 있다. 명령어를 실행하는 하드웨어를 인출 단계와 실행 단계로 분리하여 구성할 수 있다.
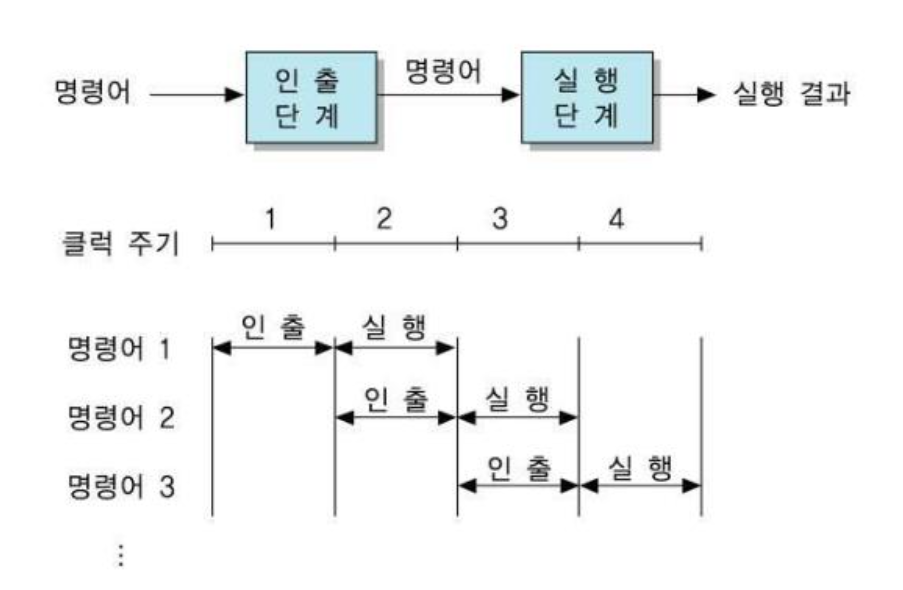
이렇게 명령어 실행 하드웨어를 두 단계로 나눈것을 2-단계 명령어 파이프라인이라고 한다.
- 첫 번째 클록 주기 : 인출단계가 첫 번째 명령어를 인출한다.
- 두 번째 클록 주기 : 인출 단계는 두 번째 명령어를 인출하고 실행 단계는 첫 번째 클록 주기에서 인출한 명령어를 처리한다.
이를 보면 실행 단계에서 처리할 명령어를 이전 클록에서 미리 인출한다. 다음에 실행될 명령어를 미리 인출하는 것을 명령어 선인출이라고 한다.
3개의 명령어를 실행하는 데는 4클록이 걸린다. 2-단계 명령어 파이프라인을 사용하지 않았을 때는 6클록이 걸리므로 성능 향상은 1.5배이다. 더 많은 명령어를 실행시킬 수록 성능 향상은 2배에 근접한다.
하지만 2배에 근접하는 속도 향상은 인출 단계와 실행 단계가 같은 시간이 소요되는 경우에만 가능하다. 일반적으로 실행 단계가 더 복잡한 연산을 수행하는 경우가 있어 인출 단계에 비해 시간이 더 소요된다. 인출 단계는 명령어를 인출하고 다음 명령어를 인출하지 못하고 실행 단계의 동작이 끝날 때까지 기다려한다. 따라서 실제로는 두배만큼 빨라지지 못한다.
4-단계 명령어 파이프라인
파이프라인 단계의 처리 시간이 동일하지 않아 발생하는 성능 저하는 방지 시키는 방법으로 처리 시간이 긴 파이프라인으로 여러 단계로 더 분할하는 것이다.
-
명령어 인출(IF)
명령어를 기억장치로부터 인출한다. -
명령어 해독(ID)
해독기를 이용하여 명령어를 해석한다. -
오퍼랜드 인출(OF)
기억장치로부터 오퍼랜드를 인출한다. -
실행(EX)
지정된 연산을 수행하고 결과를 저장한다.
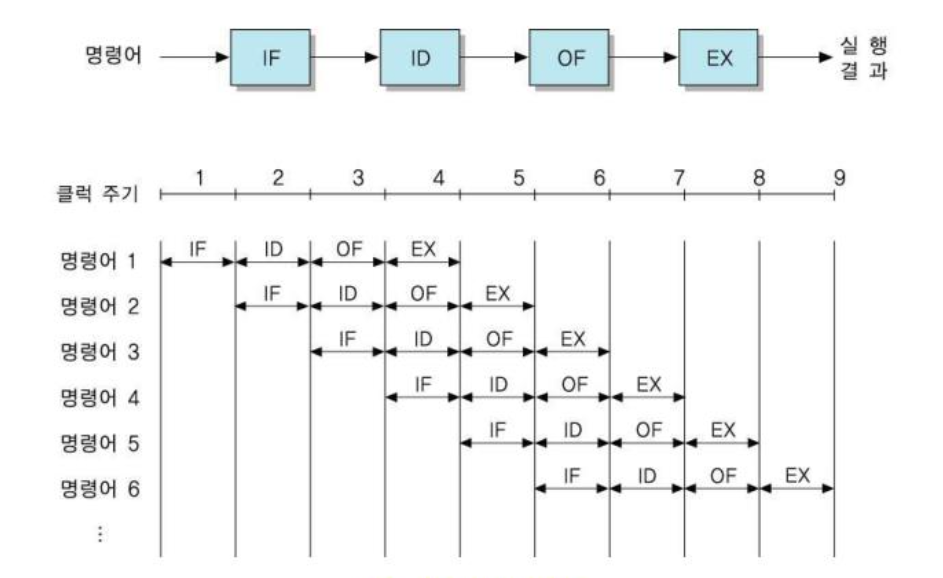
4-단계 명령어 파이프라인을 사용하면 명령어가 많을 수록 4배에 근접하게 된다. 이와 같이 k-단계 명령어 파이프라인을 사용하면 k배의 속도 향샹을 얻을 수 있다.
하지만 문제점이 있다.
-
문제 1
모든 명령들이 네 개의 파이프라인 단계들을 모두 거치지 않는 경우이다. 어떤 명령어는 실행과정에서 오퍼랜드를 인출할 필요가 없어 OF단계를 수행하지 않아도 된다. 결과적으로 OF단계를 수행하는 데 걸리는 시간이 불필요하게 소모된다. -
문제 2
파이프라인 클록은 처리 시간이 가장 오래 걸리는 단계를 기준으로 정해져야 한다. 나머지 단계는 기다려야 한다. 이를 해결하는 방법은 단계를 더 작게 분할하는 슈퍼파이프라이닝으로 보완한다. -
문제 3
지금가지 기억장치의 충돌이 없다고 가정했는데 실제로는 IF단계와 OF단계는 기억장치를 엑세스한다. 하지만 하나의 기억장치 모듈은 동시에 엑세스할 수 없어 둘 중 하나는 지연될 수밖에 없다. 이 문제를 해결하기 위해서는 IF단계와 OF단계가 직접 엑세스하는 CPU내부 캐시를 명령어 캐시와 데이터 캐시로 분리시키는 방법이 사용된다. (나중에 더 자세히) -
문제 4
조건 분기 명령어가 실행된다면 미리 인출되어 처리되고 있던 명령어들이 무효화될 수 있다. 사이클이 낭비되는 것이다. 이 문제를 완전히 해결할 수는 없지만 성능 저하를 최소화 시키는 방법이 존재한다. 분기 예측, 분기 목적지 선인출, 루프 버퍼, 지연 분기등의 방법을 사용한다. ( 이부분은 나중에 정리 )
조건 분기 명령어가 사용하는 조건들은 CPU 내부의 상태 레지스터에 저장되어 있다. 각각의 비트를 플래그라고 하는데 이들을 모아둔 곳이 상태 레지스터이다.
-
부호(S) 플래그
직전에 수행한 산술 연산 결과값의 부호비트로 세트된다. (0 = 양수, 1 = 음수 의미) -
제로(Z) 플래그
연산 결과값이 0이면 1로 세트된다. -
올림수(C) 플래그
뎃셈이나 뺄셈에서 올림수나 빌림수가 발생된 경우 세트된다. -
동등(E) 플래그
두 수를 비교한 결과가 동일하면 세트된다. -
오버플로우(V) 플래그
산술 연산 과정에서 오버플로우가 발생된 경우 세트된다. -
인터럽트(I) 플래그
인터럽트 가능 상태면 1, 인터럽트 불가능 상태면 0으로 세트된다. -
슈퍼바이저(P) 플래그
CPU가 슈퍼바이저 모드와 사용자 모드 중에 어느 모드에서 프로그램을 실행하고 있는지 나타낸다. 슈퍼바이저 모드는 시스템 프로그램을 수행하는 모드이고 사용자 모드는 사용자 프로그램 혹은 프로그램이 수행되는 모드이다. 유저 모드에서는 이 플래그를 건들지 못한다.
슈퍼스칼라
슈퍼 스칼라는 CPU의 처리 속도를 더 높이기 위해 내부에 두 개 혹은 그 이상의 명령어 파이프라인을 포함시킨 구조이다. 여러개의 명령어 파이프라인이 별로의 명령어를 인출하여 동시에 실행할 수 있다. 이론적으로 처리 속도는 파이프라인의 수만큼 높아질 수 있다.
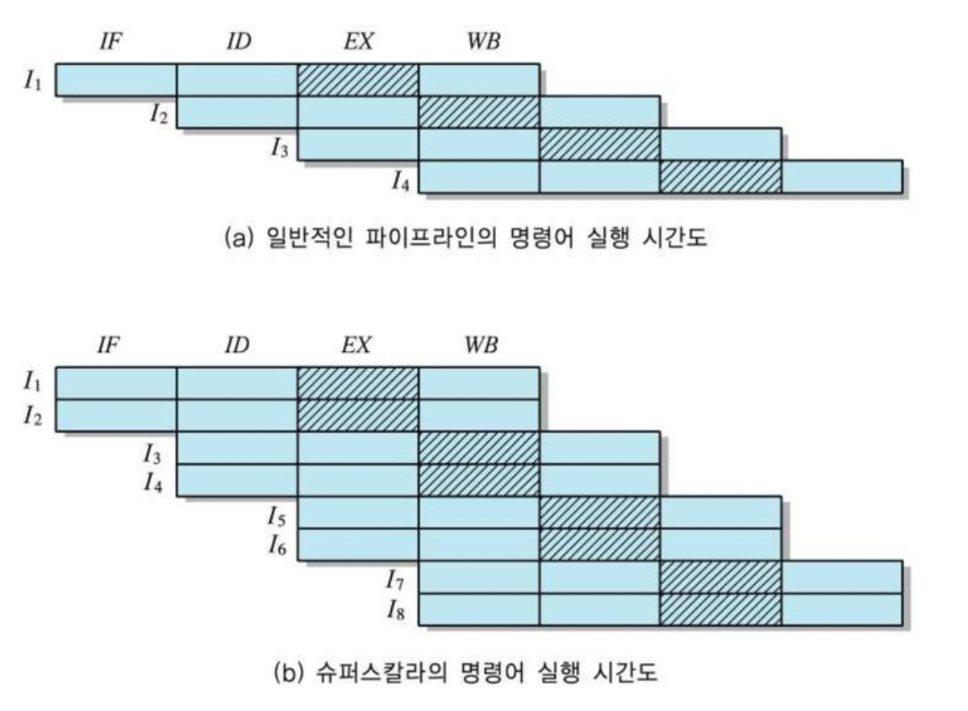
(b)는 (a)와 동일한 파이프라인 구조를 2개 가지고 있다. 이 처럼 두 개의 파이프라인으로 이루어진 구조를 2-way슈퍼스칼라라고 부른다. 매 주기마다 명령어가 두 개씩 인줄되어 동시에 처리된다. 2-way슈퍼스칼라에서 유의해야 할 점은 동시에 처리하는 명령어들이 서로 간에 영향을 받지 않고 독립적으로 처리될 수 있어야 한다는 것이다. 다른 말로 데이터 의존성이 존재하지 않아야 한다. 데이터 의존성은 한 명령어를 실행한 다음에 그 결과를 이용해야 다음 명령어의 실행이 가능한 관계를 의미한다.
듀얼-코어 및 멀티-코어
CPU 코어란 CPU칩의 내부회로 중에서 명령에 실행에 반드시 필요한 핵심 부분들로 이루어진 하드웨어 모듈을 말한다. 이러한 CPU 코어 여러 개를 하나의 칩에 넣은 것을 멀티-코어 프로세서라고 한다. 2개의 CPU코어를 넣은 것은 듀얼-코어 프로세서, 네 개를 포함 시킨 것은 쿼드-코어 프로세서라고 부른다. 각 코어는 슈퍼스칼라 구조로 구성되어 있어 더 빨라진다.
하나의 프로그램에 포함된 명령어들을 명령어 파이프라인의 수만큼 인출하여 동시에 실행하는 슈퍼스칼라 프로세서와 달리 듀얼-코어 프로세서에서는 독립적인 처리가 가능한 태스크 프로그램들응 동시에 처리된다. 이와 같이 프로그램을 동시에 처리하는 기술을 멀티-태스킹이라고 하는데 멀티-스레딩이라고도 부른다. 멀티-스레딩은 더 자세히 말하면 하나의 CPU 코어가 다수의 스레드들을 동시에 실행하는 기법이다. 스레드란 독립적으로 실행될 수 있는 최소 크기의 프로그램 단위를 의미한다.
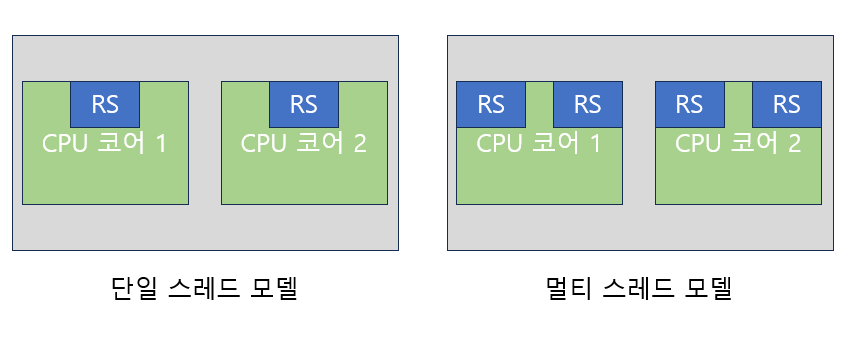
왼쪽은 한 코어가 한개의 스레드만 실행되는 모델이고 오른쪽은 한 코어가 두개의 스레드를 동시에 실행하는 모델이다. 프로그램 카운터, 스택 포인터, 상태 레지스터, 데이터 레지스터, 주소 레지스터 등으로 이루어진 레지스터 세스(RS)의 차이가 있다. 각 스레드의 상태가 이 RS에 저장된다. 오른쪽은 각 코어에 두 개의 RS가 존재해 두 개의 스레드를 동시에 처리하는 멀티-스레딩 기법을 지원하는 것이다. 오른쪽 사진을 두개의 물리적 프로세서들이 네개의 논리적 프로세서들로 구성되어 있다고 정의하기도 한다.
